
SFExt-PGAbs:两阶段长文档摘要模型
2021-05-14 03:42周伟枭蓝雯飞许智明朱容波
计算机与生活 2021年5期
周伟枭,蓝雯飞+,许智明,朱容波
1.中南民族大学计算机科学学院,武汉430074
2.福州大学机械工程及自动化学院,福州350108
互联网技术的发展导致文本信息规模快速增长,数据过载问题日益严重,对蕴含重要信息的文档进行“降维”处理显得尤为关键。文本摘要(text summarization)是自然语言处理(natural language processing,NLP)、自然语言生成(natural language generation,NLG)的重要分支,其目的[1]是使用抽取或生成的方式获取一个或多个文档的简短版本,同时保留原始文档的显著信息。
以与原始文档关系作为分类依据,摘要任务分为抽取式摘要(extractive summarization,Ext)[2]和生成式摘要(abstractive summarization,Abs)[3];以摘要对象作为分类依据,分为单文档摘要(single document summarization)[4]和多文档摘要(multi-document summarization)[5]。
抽取式摘要直接从原始文档中提取句子组成摘要,具体表现为对句子重要性评分并选取Top-N个重要句子[6],优势在于能够得到语义和语法正确的摘要,因为句子信息均来源于原始文档。此类方法的缺陷也十分明显:摘要长度限制会严重影响抽取出句子之间的流畅性、连贯性,导致可读性较差,在长文档中抽取摘要时,该缺陷会被进一步放大。
生成式摘要通过重新组织原始文档主要内容形成摘要,形式上更类似于人工撰写。文献[7]指出,大量针对生成式摘要的研究工作所提出的模型本质上都是基于序列到序列(sequence to sequence,Seq2Seq)架构的,此类模型生成的摘要连贯性、流畅性较好,但是准确性较低,无法很好地反映原始文档的事实细节,甚至与原始文档中心思想相悖。特别地,由于特征提取器(feature extractor)长短时记忆网络(long shortterm memory,LSTM)[8]、门控循环单元(gated recurrent unit,GRU)[9]对长文档编码性能较弱以及常见的摘要数据集对句子位置存在偏见(bias)[10],部分研究工作[11-12]对长文档进行截断后再编码。本文认为,截断操作虽然提高了编码性能且加快了训练速度,但是丢失了原始文档中后部重要句子信息。同时,直接截断获得的文本存在冗余的句子干扰模型的泛化能力,进一步加剧摘要准确性低的缺陷。
针对上述问题,本文提出一种两阶段长文档摘要模型SFExt-PGAbs,由次模函数抽取式摘要(submodular function for extractive summarization,SFExt)[13-14]、指针生成器生成式摘要(pointer generator for abstractive summarization,PGAbs)[11]组成。
提出SFExt-PGAbs的动机在于:
(1)本文对大量摘要样本分析后认为,人类在对长文档进行摘要时,倾向于先挑选出重要的句子作为参考,并重新组织参考句以获取流畅的摘要。
(2)抽取式摘要与生成式摘要的优缺点互补。
传统SFExt 的目标增益函数(objective gain function)只关注两个子方面:覆盖性、冗余性。本文拓展出两个新的子方面,位置重要性和准确性。引入雅卡尔指数(Jaccard index)进一步去除冗余句,同时设计新的贪心算法(greedy algorithm)进行句子抽取。
本文在PGAbs中应用两种循环神经网络(recurrent neural network,RNN)并研究不同组件对生成摘要质量的影响。实验结果表明,SFExt-PGAbs 生成的摘要同时满足准确性、流畅性特点,相较于基线模型在ROUGE(recall-oriented understudy for gisting evaluation)指标上的性能有较大提升。同时,子方面拓展后的SFExt也能抽取得到更准确的摘要。
1 相关工作
1.1 抽取式摘要
早期文摘领域研究人员主要关注无监督抽取式摘要(unsupervised extractive summarization),侧重于从单个文档或一组文档中识别出有代表性的句子组成摘要。Lin 等人[13-14]首次将文摘任务与次模函数性质相关联,从理论和实验两方面证明了贪心算法可以近似最优地求解预算次模极大值问题。Tixier 等人[15]改进了文献[13]的覆盖度项,并为单词分配有意义的分数。Mihalcea 等人[16]提出基于TextRank 的自然语言文本图的排序模型,并将其应用到关键词抽取(keywords extraction)、句子抽取(sentence extraction)任务中。TextRank 是一种性能优越的无监督算法,本文在SFExt 中引入准确性子方面时应用了该算法。Erkan 等人[17]提出基于特征向量中心性概念的句子重要性计算方法LexPageRank,通过构造句子连接矩阵实现句子抽取。Sripada 等人[18]提出KL 算法,通过衡量摘要概率分布与原始文档概率分布之间的KL散度(Kullback-Leibler divergence)选取句子。Gong等人[19]使用浅层语义分析(latent semantic analysis,LSA)描述词与词之间的潜在共现关系从而进行摘要。Tsarev 等人[20]提出一种利用非负矩阵因子分解(nonnegative matrix factorization,NMF)来估计句子相关性的泛型文本摘要方法。与TextRank、LexPageRank、KL、LSA、NMF 相比,SFExt 性能更优且直接对摘要所蕴含的信息量以及句子间冗余建模,保证抽取的句子是准确且冗余较低的。本文使用SFExt 作为第一阶段的基础模型。
近年来,大量研究工作应用神经网络实现抽取式摘要,通常表现为有监督学习(supervised learning)的形式。部分研究人员重新关注无监督抽取式摘要,Zheng 等人[21]建立了有向边图,认为任意两个节点对各自中心性的贡献受到它们在文档中的相对位置的影响。Dong 等人[22]基于语篇结构的位置信息和层次信息来增强文档图的层次性和方向性。
1.2 生成式摘要
由于深度学习(deep learning,DL)的快速发展,许多基于Seq2Seq 的生成式摘要模型被提出。Rush等人[23]首次将Seq2Seq 模型应用于文摘任务,并引入注意力机制(attention mechanism)[24]。Nallapati等人[25]进一步拓展了基于RNN 的生成式摘要模型。Vinyals等人[26]提出指针网络(pointer network)。Gu 等人[27]结合Seq2Seq 模型与指针网络提出CopyNet,将解码器中固定规模的词典推广到动态规模。同时,Gulcehre等人[28]也成功应用了指针网络。上述研究人员提出的模型通过生成单词序列一定程度上解决了生成式摘要任务,但是还存在重复生成、摘要准确性低的问题。
与机器翻译(machine translation,MT)任务不同,摘要数据集中原始文档长度相较于参考摘要(ground truth eference summary)更长,导致Seq2Seq 模型与CopyNet 无法对两者进行对齐(align),从而出现生成冗余单词或句子的现象[29]。Tu 等人[29]维护一个覆盖度向量(coverage vector)一定程度上解决了该问题。See等人[11]结合文献[25]、文献[27]、文献[29]提出指针生成器网络(pointer generator network),本文第二阶段的PGAbs与之类似。
部分研究工作通过融合多源信息提高摘要模型的生成能力。Guo 等人[30]提出多层编码器-解码器架构,引入文本蕴含、问题生成任务提高模型的生成能力。Zhu 等人[31]建议使用翻译任务提高摘要模型的语言学习能力。Mishra 等人[32]在模型中学习词性和句法信息来提高摘要模型预测文档情绪的能力。Zhu 等人[33-34]提出基于指针生成器网络的多模态生成式摘要模型。与上述工作不同,本文没有引入外部知识,而是通过输入更准确的文档表示来提高摘要模型的生成性能。
个别研究人员通过对原始文档重要信息的识别来提高生成摘要的准确性。Gehrmann 等人[12]通过判断原始文档中的关键词是否包含在摘要中来提高摘要的准确性,本文在SFExt 中引入的准确性子方面同样来源于关键词的识别。
针对长文档摘要,Celikyilmaz 等人[35]将编码器划分为多个协作编码器,每个协作编码器单独编码一段文本,从而避免LSTM、GRU对长文档编码性能较弱的问题。与文献[35]不同,本文首先在长文档中抽取出重要句子,并对这些重要句组成的文档进行编码。Transformer[36]对长文档的编码能力、并行处理能力相较于LSTM、GRU更强,该模型逐渐被应用在文摘领域。
2 两阶段长文档摘要模型
2.1 总体架构
两阶段长文档摘要模型SFExt-PGAbs 获取摘要时,首先使用SFExt 获取长文档的过渡文档(transitional document),过渡文档的序列长度处于原始文档与参考摘要之间,保留了大部分原始文档的重要信息。随后,PGAbs 接收过渡文档进行编码(encode)、解码(decode)、生成长文档对应的摘要。图1 所示为SFExt-PGAbs总体架构。
与截断文档(truncated document)相比,过渡文档更加准确地阐述了原始长文档的中心思想(没有损失长文档中后部句子重要信息且冗余较低),从而提高PGAbs的生成性能。
与全文档(full document)相比,过渡文档的训练时间大幅减少,并且其较短的性质避免了“长距离依赖”问题的产生,使PGAbs对其编码性能更强。

Fig.1 Overall structure of SFExt-PGAbs图1 SFExt-PGAbs总体架构
2.2 第一阶段:SFExt
2.2.1 次模函数性质
次模函数(submodular function,SF)最初由边际效益递减(diminishing marginal utility)现象演变而来,是一个集合函数,随着向集合中不断添加元素,函数增量的差异逐渐减小[13]。
给定集合函数f:2V→R,将有限集V的一个子集S⊆V映射为一个实数。若对于任意S,T⊆V,满足:

则称f(·)为次模函数。从边际效益递减的角度考虑,次模函数的另一种等价定义为:若对于任意的R⊆S⊆V,且有s∈VS,满足:

则称f(·)为次模函数。
式(2)指出,当集合愈来愈大,s的价值将逐渐减小,这与抽取式摘要的思想是极为契合的。在摘要过程中,总是先选择当前价值最高的句子进入集合。
2.2.2 抽取式摘要任务转化
抽取式摘要任务可以形式化为一个预算约束(budget constraint)下的次模函数最大化的问题[13]:

其中,V表示原始文档中所有句子的集合;S(S⊆V)表示从V中提取出的摘要句子集合;csi为非负实数,表示摘要句子si对应的代价(cost);B表示预算约束,即所有选中的摘要句子对应的代价和不能超过B;次模函数f(·)对摘要质量进行打分。在抽取式摘要中,预算约束B是天然存在的,通常设定为摘要长度限制、摘要句数量限制。
2.2.3 目标次模函数设计
本文结合文献[14]定义的覆盖度项和文献[13]定义的冗余项来阐述覆盖性和冗余性这两个子方面,目标次模函数f(·)建模为:

f(·)展开公式为:

式(4)中L(S)表示从原始文档D={s1,s2,…,sn}中选取的摘要句子集合S的覆盖度项,被解释为度量摘要集S与原始文档D相似性的集合函数,R(S)表示S的冗余项,避免冗余的句子进入摘要句子集合S,λ≥0 为权衡系数。
式(5)中Ci:2V→R 是一个次模函数,表示摘要句子集合S与句子si的相似度,Ci(V)是Ci(S)所能达到的最大值,因为S⊆V。0 ≤α≤1 表示阈值系数,当α设置为1 时,式(5)衰减为式(6)。
式(6)~(9)中wi,j表示句子对(si,sj)的向量表示(vi,vj)之间的余弦相似度(cosine similarity)。本文没有使用预训练词向量(pre-training word vector),而是计算句子的TF-ISF(term frequency-inverse sentence frequency)向量表示。
式(3)所描述的目标次模函数f(·)的最大化是一个NP-hard 问题,使用贪心算法依次寻找使得目标增益函数F(·) 最大的句子在最差的条件下可以达到(1-1/e)f(Sopt)(f(Sopt)表示最优解)的解[13],F(·)定义如下:

结合式(4)有如下等价定义:

式(12)中f(·)表示目标次模函数,S表示已选摘要句子集合,si表示贪心算法中参与计算的句子,为si的单词数,表示长度惩罚(length penalty)项,r>0 为比例因子。
2.2.4 位置重要性子方面融合
式(13)建立的目标增益函数只考虑覆盖性和冗余性,不足以代表数据集的原始整体特征。文献[10]指出,在大量摘要数据集中,句子在原始文档中的位置是常见的偏见。虽然数据集的偏见为直接截断提供了理论依据,但是截断获取的文档头部信息并不能完全替代文档中后部句子蕴含的重要信息。
受文献[10]对摘要数据集偏见分析的启发,本文在SFExt中引入位置重要性子方面。给定原始文档D={s1,s2,…,sn},对每个句子si分配重要性度量(importance measure)ωi,ωi计算公式为:

式(16)是以e 为常数的指数函数,当x∈(0,1)时,E(x)展现出非线性下降趋势的性质。|D|为原始文档句子数量,表示句子si-1和si在D中相对位置的中值点。
本文对{ω1,ω2,…,ωn}进行等比缩放(ωn设定为1)后将ωi与式(13)中覆盖度增量Fl(S,si)进行乘积实现子方面的融合。式(13)改进为:

其中,ωi为si分配得到重要性度量。
为平衡位置重要性与覆盖性两个子方面,防止引入的重要性度量带来过拟合问题,本文设置了位置偏置权重(position bias weight)参数β:

其中,β用来减小或者增大ωi对覆盖度增量的影响,可根据数据集的性质进行调整。相较于式(13),应用式(19)的SFExt 能够提高抽取出处于重要位置句子的可能性。
图2 为只包含5 个句子的D={s1,s2,s3,s4,s5}分配得到经过等比缩放的{ω1,ω2,ω3,ω4,ω5}的取值,并且展示了β的取值对ω的整体影响。

Fig.2 Importance measure distribution图2 重要性度量分布
图2显示,当β=0 时,∀i∈{1,2,3,4,5},都有ωi=1.0,则式(19)衰减为式(13),表示不引入位置重要性子方面。同时,以β=0 为界限,β越趋向于+∞,则SFExt更倾向于抽取文档头部信息;反之,则SFExt更倾向于抽取文档中后部句子信息。通常,本文建议设置-1.0 <β<1.0。
本文分析后认为,融合位置重要性子方面的SFExt抽取出的句子同时满足以下性质:
(1)处于文档重要位置;
(2)处于文档非重要位置但包含突出信息;
(3)句子间冗余较低。
2.2.5 准确性子方面融合
文献[37]指出,关键词构成了句子的主体,是重要的句子选择指标,摘要撰写者倾向于关注包含关键词的句子以确保摘要的准确性。本文分析后认为,关键词和摘要都能在一定程度上反映原始文档的中心思想,只是使用了单词和句子两种不同粒度的表示方式,关键词是摘要更为抽象的表示,两者之间可以互相弥补信息缺失的问题。
本文在SFExt 中引入准确性子方面确保抽取出的句子包含更多的关键词。给定原始文档D={s1,s2,…,sn},使用TextRank[16]算法获取关键词k以及对应关键词权重g:

其中,TR表示TextRank 算法,M表示在文档D中抽取出的关键词总数。g的值反映k对于D的重要程度,g越高则对应k越重要。

式(21)中I为一个函数,表示获取句子si包含所有关键词k的索引,U为关键词索引集合。式(22)计算关键词索引对应权重的和。
准确性子方面融合后式(19)改进为:

同样,为防止过拟合以及适应不同数据集,本文设置了关键词影响程度(keywords influence degree)参数ρ:

其中,ρ用来减小或者增大γi对目标增益函数的影响,ρ=0 时,式(24)衰减为式(19),表示不引入准确性子方面。通常,本文建议设置0 <ρ<1。相较于式(19),应用式(24)的SFExt 能够进一步获得更准确的过渡文档或摘要。
2.2.6 贪心算法
本文设计了引入雅卡尔指数的贪心算法进一步过滤冗余句。
算法1最大化目标增益函数F(·)获取过渡文档或摘要的贪心算法


算法1 中,步骤3 表示找到使F(S,si)最大的句子sk,F(S,si) 可以选择式(13)、式(19)、式(24),不同F(S,si)引入不同参数α,λ,r,β,ρ。步骤4~5 表示若句子sk与S中任意一句话冗余或增量小于等于0,则转到步骤2 进行下一轮循环。步骤7~9 表示在不超过预算约束B的情况下将sk添加进S,并在D中将sk删除。预算约束B值的大小决定S中句子序列总长度,返回的S即为过渡文档或摘要句子集合。

其中,式(25)计算句子间单词交集,式(26)中|·|计算集合中单词数量,若Jac(sk,sj)大于冗余阈值δ,则表示句子对(sk,sj) 之间冗余。通常,本文建议设置δ∈{0.65,0.75}。
2.3 第二阶段:PGAbs
2.3.1 编码器
循环神经网络能够很好地处理时间序列数据,本文使用Bi-LSTM(bi-directional long short-term memory)和Bi-GRU(bi-directional gated recurrent unit)作为PGAbs的编码器(encoder)。相较于单向LSTM 和单向GRU,双向特征提取器能够更好地捕捉双向语义依赖。


Fig.3 Pointer generator for abstractive summarization图3 指针生成器生成式摘要
Bi-LSTM 前向传播公式:

在式(27)~(30)中,E[wt]表示单词wt的词嵌入(word embedding);t表示时刻;ht表示当前时刻隐藏状态(hidden state);ct表示当前时刻细胞状态(cell state)。在逻辑架构中,GRU 舍弃了细胞状态c,将隐藏状态h直接传递给下一个编码单元。

2.3.2 解码器
PGAbs解码器(decoder)[11]在传统Seq2Seq模型中混合了注意力机制、复制机制(copy mechanism)、覆盖度机制(coverage mechanism),生成的单词选择性来源于输入文档或词汇表,一定程度上解决了集外词(out of vocabulary,OOV)问题和重复生成相同单词的问题,本文使用PGAbs解码器作为摘要生成器。
图3 框外为解码器架构,本文使用单向LSTM 和单向GRU 作为解码器的基本逻辑单元。在时刻t,LSTM 或GRU 单元接收t-1 时刻预测输出单词(predicted output word)yt-1得到当前解码器状态(current decoder state)st。
t=0 时刻初始化解码器状态s0为:

其中,Wd为可学习参数,tanh 为非线性函数。
注意力机制计算注意力分数(attention scores)、注意力分布(attention distribution)at获取上下文向量(context vector)ct:

其中,v、Wh、Ws为可学习参数,注意力分布at可解释为输入文档单词的概率分布。

其中,covt表示t时刻前所有注意力分布ai的和,可解释为t时刻前单词被覆盖的程度。覆盖度机制通过回顾t时刻前的注意力机制避免重复注意相同的位置从而缓解重复生成的问题。
复制机制定义一个pg控制t时刻生成单词的来源,pg由当前解码器状态st、yt-1的词嵌入E[yt-1]、上下文向量ct决定:

其中,Wc、Ws、We为可学习参数,σ表示sigmoid函数。
词汇表概率分布Pfinal为:


其中,pg表示从词汇表Pvocab中生成单词的概率,(1-pg)表示从注意力分布at i中复制输入文档单词的概率。V*、V、b、b*为可学习的参数。复制机制通过拷贝部分输入文档的单词生成摘要,缓解了集外词问题。
2.3.3 训练与推理
给定输入文档与参考摘要,训练期间,使用导师驱动(teacher forcing)过程,解码器的输入为参考摘要单词而非前一时刻解码器输出,通过最小化损失函数训练模型参数。
不引入覆盖度机制的PGAbs 在t时刻损失函数定义为目标单词(target word)的负对数似然损失:

引入覆盖度机制的PGAbs 在t时刻损失函数定义为复合损失函数:

测试期间,解码器首先接收单词“
3 实验及结果分析
3.1 实验设置
本文实现了12 种摘要模型,其中,PGAbs 使用深度学习框架PyTorch 实现。各个模型基本架构及组件如表1 所示。表中,c、r、p、a 分别表示在SFExt中引入覆盖性(coverage)、冗余性(redundancy)、位置重要性(positional importance)、准确性(accuracy)子方面。LSTM、GRU 表示PGAbs 中应用的循环神经网络单元类型。copy、coverage 分别表示使用复制机制、覆盖度机制。
SFExt 参数设置如表2 所示。表中,|D|表示文档句子数量。仅使用SFExt 获取摘要时,B设置为120,使用SFExt 获取过渡文档时,B设置为400。B值的设定取决于数据集的性质,本文将在3.2 节中介绍使用的数据集并对其做全方位的统计数据分析。

Table 1 Basic architecture and components table of each model表1 各个模型基本架构及组件表

Table 2 SFExt parameters table表2 SFExt参数表
PGAbs参数设置如表3 所示。本文使用Adagrad[38]优化器对PGAbs 的参数进行优化,表3中学习率与累加器参数与Adagrad 优化器相关。所有PGAbs 均在GeForce GTX TITAN X 12 GB显存GPU上训练及测试。
3.2 数据集及统计数据分析
3.2.1 数据集
本文使用CNNDM[39](CNN/Daily Mail)作为实验数据集。CNNDM 是摘要领域的基准数据集,其中,原始文档来源于新闻文本,参考摘要来源于人工撰写,包含训练集287 226 对、测试集11 490 对、验证集13 368 对。

Table 3 PGAbs parameters table表3 PGAbs参数表
3.2.2 统计数据分析
本文对CNNDM 预处理后过滤掉部分原始数据,表4 为统计的CNNDM 原始文档基本信息。

Table 4 CNNDM original documents data statistics table表4 CNNDM 原始文档数据统计表
表4 显示,CNNDM 原始文档平均词数为775.53,属于长文档摘要数据集。本文遵循文献[11]的设置,在仅使用PGAbs 获取摘要时,对原始文档截断至400个单词以保证编码性能和训练速度。在使用SFExt-PGAbs获取摘要时制定如下处理策略:
(1)小于400 词的原始文档,保留全文后使用PGAbs训练与测试;
(2)介于400 词至500 词之间的原始文档,截断保留400 个单词后使用PGAbs训练与测试;
(3)大于500词的原始文档,使用SFExt获取预算约束B=400 的过渡文档后使用PGAbs训练与测试。
本文统计CNNDM 三种长度分布的原始文档数量来展现使用制定处理策略时需要被SFExt 处理的文档比例。统计结果如表5 所示,本文在实验中没有使用验证集。

Table 5 The number of original documents in three length distributions of CNNDM表5 CNNDM 三种长度分布的原始文档数量
表5 显示,在使用SFExt-PGAbs 获取摘要时,训练期间,训练集中75.60%的原始文档需要获取其过渡文档;测试期间,测试集中72.04%的原始文档需要获取其过渡文档。
本文将CNNDM 原始文档均等划分为6 个域,统计截断操作、制定处理策略获取的截断文档、过渡文档的句子在原始文档中的总体分布,更清晰地展示SFExt的作用。表6 为总体分布统计结果。
表6 显示,制定处理策略得到的过渡文档相较于截断操作保留了长文档中后部位置的重要句子信息,后3 个域中句子数量更多。值得注意的是,制定处理策略得到的过渡文档句子总数相对较少,这是SFExt 倾向于抽取长句子导致的(通常长句子包含更丰富的信息)。

Table 6 CNNDM population distribution表6 CNNDM 总体分布表
3.3 结果分析
3.3.1 评价指标
本文使用文摘领域基准评价指标ROUGE[40]测评待测摘要(模型抽取或生成的摘要)的质量。其中,ROUGE-N(包括ROUGE-1、ROUGE-2)和ROUGE-L为重要指标。
ROUGE-N 计算公式如下:

其中,n为n-gram 长度,{RS}为参考摘要,Countmatch(gramn)为待测摘要与参考摘要之间相同的n-gram 数量,Count(gramn)为参考摘要中n-gram 数量。
ROUGE-L 计算公式如下:

其中,LCS(X,Y)为待测摘要与参考摘要的最长公共子序列长度,m为参考摘要长度。
3.3.2 基线模型
本文引用5 篇相关文献在CNNDM 测试集上报告的测试结果以及实现两种基于Transformer[36]架构的生成式摘要模型与表1中模型进行对比,具体如下:
SummaRuNNer:Nallapati 等人[6]在AAAI 2017 公开发表的一种有监督抽取式摘要方法。该模型通过对句子的内容、显著信息、偏置项等进行建模并抽取句子,是2017 年抽取式摘要的state-of-the-art。
Graph-Based Attention:Tan 等人[7]在ACL 2017 公开发表的一种引入Graph-Based Attention 机制的Seq2Seq 模型,提高了对句子显著性的适应能力。
Intra-Attention(ML):Paulus 等人[41]在ICLR 2018公开发表的一种引入Intra-Temporal Attention 机制的有监督生成式摘要模型。该模型对文档中获得较高权重的词进行惩罚,防止解码过程中再次赋予该词高权重。
Intra-Attention(MLRL):在Intra-Attention(ML)的基础上集成强化学习(reinforcement learning)。通过将模型预测的单词以及对应样本与参考摘要单词计算的ROUGE 指标作为奖励,同时根据奖励更新模型参数。该模型是2018年生成式摘要的state-of-the-art。
Key Information Guide Network:Li 等人[42]在NAACL 2018 公开发表的一种通过关键词指导摘要生成的模型。
PACSUM:Zheng 等人[21]在ACL 2019 公开发表的一种基于位置增强的无监督抽取式摘要方法。
Transformer(copy):本文实现的在基础Transformer[36]架构上引入复制机制的生成式摘要模型。编码器与解码器各4 层,词嵌入维度512,隐藏层维度512,前馈层维度1 024,多头自注意力机制(multi-head selfattention)设置为8,dropout 设置为0.2,长度惩罚项(length penalty)参数设置为0.9,标签平滑(label smoothing)参数设置为0.1。
Transformer(copycoverage):本文实现的在Transformer(copy)基础上引入覆盖度惩罚项的生成式摘要模型。
3.3.3 主要结果
本文使用files2rouge 包测评所有SFExt、PGAbs、SFExt-PGAbs、Transformer 获取的待测摘要在95%置信区间的ROUGE标准F1评分。测试文本为CNNDM测试集(11 489 对原始文档与参考摘要),表7 所示为对比结果。
表7 结果显示,本文实现的SFExt-PGAbs(c paLSTMcopycoverage)在ROUGE-1、ROUGE-2、ROUGE-3、ROUGE-SU4 指标上相较于基线模型拥有最佳的摘要性能。
对比表7 中4 种SFExt 模型,融合位置重要性子方面的SFExt(c p,B=120)相比SFExt(c ,B=120)在ROUGE 指标上分别提高了2.96、2.75、1.89、2.88、2.18 个百分点,融合准确性子方面的SFExt(c a,B=120)相比SFExt(c ,B=120)在各个ROUGE 指标上的提升约为0.20 个百分点。SFExt(c pa,B=120)达到了所有SFExt 的最佳性能,抽取出的摘要更能反映原始文档的中心思想。
对比表7 中SFExt 与其他模型,无监督抽取式摘要模型SFExt(c pa,B=120)摘要性能超过了有监督生成式摘要模型Graph-Based Attention、Intra-Attention(ML)、不带覆盖度机制的PGAbs 与SFExt-PGAbs、Transformer(copy)。同时,SFExt(c pa,B=120)摘要性能与同为无监督抽取式方法的PACSUM 相当,证明了子方面融合的有效性。
对比表7 中4 种PGAbs 模型,覆盖度机制的引入会极大地影响模型的生成性能。LSTM 作为特征提取器单元的生成性能略高于GRU,本文认为这是由于LSTM 的编码性能较强导致的。同样,对比表7 中4 种SFExt-PGAbs模型可得到相同的结论。
对比表7 中PGAbs 与SFExt-PGAbs,当PGAbs 配置相同的组件时,SFExt-PGAbs 生成的摘要在保证流畅性的前提下,同时提高了摘要的准确性,证明了两阶段长文档摘要模型的有效性。其中,SFExt-PGAbs(c paLSTMcopycoverage)相比模型PGAbs(LSTMcopycoverage)在ROUGE 指标上分别提高0.57、0.16、0.02、0.33、0.17 个百分点。

Table 7 ROUGE evaluation table(11 489 pairs of test data)表7 ROUGE 测评表(11 489 对测试数据)%

Table 8 ROUGE evaluation table(1754 pairs of test data)表8 ROUGE 测评表(1 754 对测试数据)%

Table 9 ROUGE evaluation table(2102 pairs of test data)表9 ROUGE 测评表(2 102 对测试数据)%
本文对测试集按长度属性进行划分,得到原始文档长度在800~1 000 单词之间的数据集(1 754 对测试数据)、1 000~1 500 单词之间的数据集(2 102 对测试数据)、1 500 单词以上的数据集(765 对测试数据),并使用PGAbs、SFExt-PGAbs、Transformer 对上述3 个测试子集进行测试。
表8所示为在800~1000单词原始文档上的测评结果。
表9 所示为在1 000~1 500 单词原始文档上的测评结果。
表10 所示为在超过1 500 单词原始文档上的测评结果。

Table 10 ROUGE evaluation table(765 pairs of test data)表10 ROUGE 测评表(765 对测试数据)%
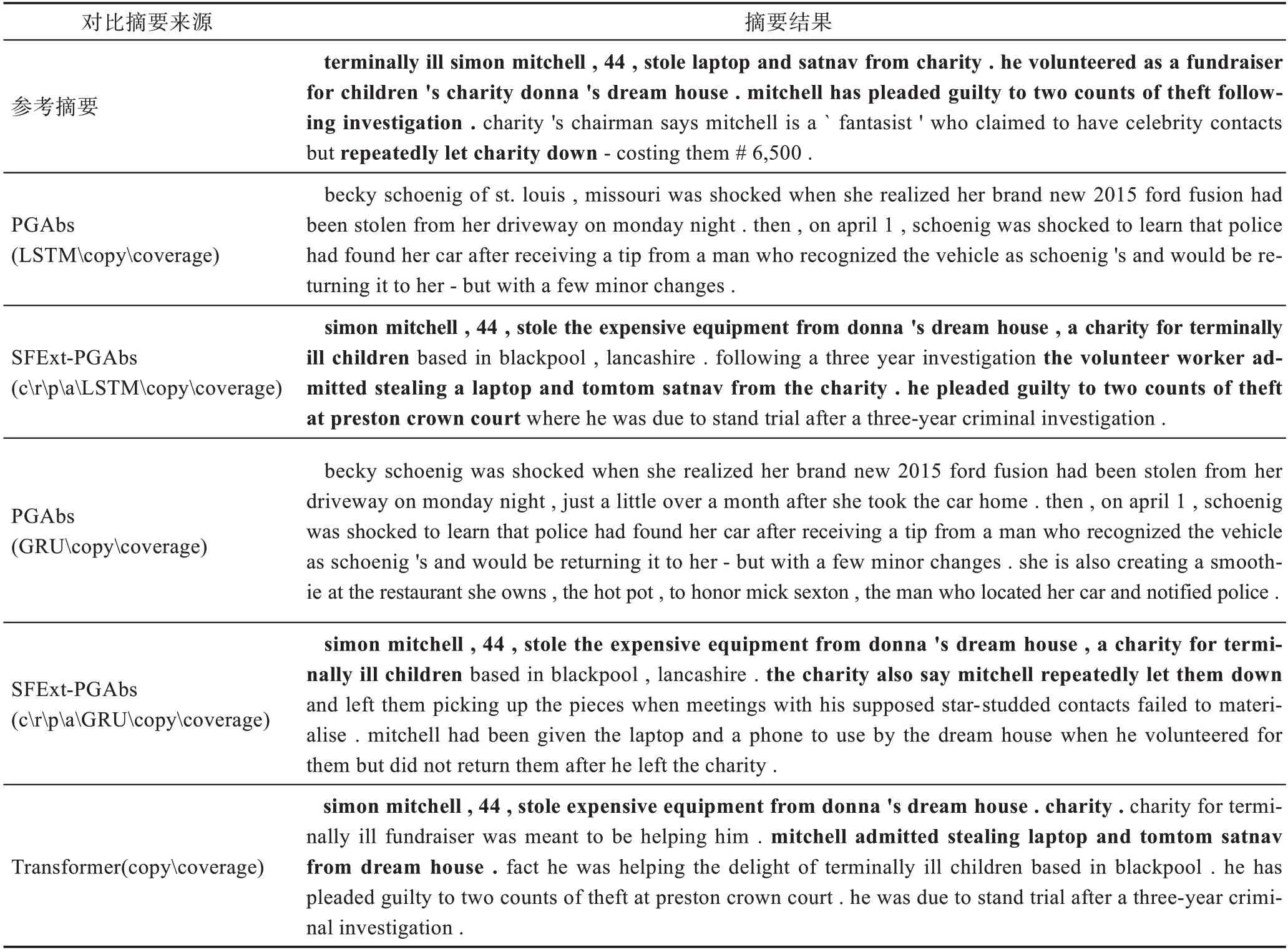
Table 11 Summaries case study table表11 摘要样例对比表
表8~表10 结果显示,针对长文档摘要,SFExt-PGAbs 的摘要性能远强于PGAbs,其主要原因是在训练和测试期间,过渡文档保留了长文档中后部句子重要信息,一定程度上解决了信息缺失问题。同时,当文档越长时,SFExt-PGAbs 相对于PGAbs 的性能提升逐步降低,这与本文预期是一致的,越长的文档获取其高质量摘要的难度越高,导致其性能提升的难度随之增高。
Transformer 相较PGAbs 对长文档的摘要性能更强,本文认为这是由于位置编码(positional encoding)与自注意力机制(self-attention)带来的优势所导致的。
3.3.4 样例分析
本文通过样例分析进一步验证SFExt-PGAbs 能够生成流畅且更准确的摘要,表11 所示为摘要样例对比表。
表11 结果显示,PGAbs 没有捕捉到文章重点内容,仅阐述了“物品被盗”及“警方发现车”等无关内容。Transformer 捕捉到了部分文章重点,包括“西蒙·米切尔偷走了昂贵的设备”等,但是第二句话存在事实错误,将“慈善机构”帮助对象错误地认为是盗窃者。SFExt-PGAbs 生成的摘要基本囊括参考摘要描述的所有基本事实(表中加粗段落)。
4 结束语
本文提出一种两阶段长文档摘要模型,通过结合抽取式方法与生成式方法来解决长文档摘要问题,实验结果证明了该模型的有效性。同时,本文在传统SFExt中拓展出位置重要性、准确性子方面,建立新的目标增益函数,相较于传统SFExt 性能更优,应用更灵活。本文分析后认为,对于抽取式摘要,如何识别数据集的特征是极为关键的,对于生成式摘要,如何获取更多的编码信息是影响摘要质量的关键因素。
本文未来工作主要关注如何提高生成式摘要模型的编码能力。通过构建大量回翻(back-translation)数据集对编码器进行预训练(pre-training),或直接将回翻任务纳入多任务学习[43]体系,进一步提升摘要模型的语言学习能力,从而生成质量更高的摘要。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
客联(2022年3期)2022-05-31
中国典型病例大全(2022年12期)2022-05-13
中国典型病例大全(2022年7期)2022-04-22
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
现代信息科技(2019年18期)2019-09-10
科技创新与应用(2017年26期)2017-09-12
电脑爱好者(2017年7期)2017-05-06
中国信息技术教育(2016年13期)2016-09-10
