
基于深度学习的短文本情感倾向分析综述
2021-05-14 03:41汤凌燕熊聪聪周宇博赵子健
计算机与生活 2021年5期
汤凌燕,熊聪聪,王 嫄,2+,周宇博,赵子健
1.天津科技大学人工智能学院,天津300457
2.普迈康(天津)精准医疗科技有限公司,天津300000
随着Web2.0 时代的到来,互联网中涌现大规模带有用户主观情感的、内容短小且语义信息丰富的短文本,这些海量数据是用户意识和观点的综合呈现和重要体现,影响着网民对事物的看法态度和判断决策。具体地,网民在购物平台上选择商品时往往会先参考商品下已购买者提供的评论,然后做出是否购买该商品的决定。短文本包括但不仅限于社交平台[1-2](如微博、微信、Twitter、Facebook)文字信息、产品评论[3]、电影评论[4]、视频弹幕与字幕[5]等。如何准确高效地利用计算机技术从海量短文本中自动分析情感信息,这对于产品分析、话题监控、舆情监测、用户建模、观点分析等有着重要意义。
情感倾向分析是文本情感分析的核心工作,是指对包含主观信息的文本进行情感倾向判断。根据情感类别数可将情感倾向分析任务划分为二分类(正面/积极、负面/消极)、三分类(积极、消极、中性)和多分类(高兴、激动、悲哀、愤怒等)任务;根据研究对象的粒度可将其分为篇章句子级的粗粒度情感倾向分析任务,以及目标/方面级的细粒度情感倾向分析任务。由于目标/方面级的细粒度情感倾向分析需准确分析出文本中所提及所有方面的情感倾向,能提供更全面、更细致的情感信息,故是短文本情感倾向分析的研究热点和未来趋势。
短文本情感倾向分析过程概括为三步:文本表示与特征提取、模型训练、结果分析。由于短文本的随意性、高歧义性、简短性等特点,导致文本表示与特征提取过程中出现特征不密集、噪声多、上下文不独立等问题,从而无法提取到准确特征,得不到更具上下文语义的文本表示。传统方法将文本表示与特征提取和模型训练完全分开,其工作重点主要集中在文本表示与特征提取上。传统方法中文本表示与特征提取采用启发式方法,经典的如手工构建情感词典(包括中文情感词典[6-7]、英文情感词典[8])或特征规则(包括句法特征[9]、情感词典特征[10]、TF-IDF(term frequency-inverse document frequency)特征[11]等)。这种先采用启发式方法获取文本特征,再结合机器学习分类器进行分类的传统方法[12]高度依赖启发式方法和专家知识的构建,需人工干涉,极大降低了工作效率,限制了大数据的使用。
本文在总结和评述前人工作的基础上,对基于深度学习的篇章句子级粗粒度情感倾向分析和目标/方面级细粒度情感倾向分析进行了综述。基于研究趋势,本文重点阐述了基于深度学习的短文本细粒度情感倾向分析方法,并根据短文本细粒度情感倾向分析所面临的挑战,将基于深度学习的细粒度情感倾向分析方法进行了分类和比较。
1 深度学习相关技术
基于深度学习的短文本情感倾向分析一般流程(如图1 所示)可分为五阶段:文本预处理、初始词向量表示、特征提取与上下文语义表示、深度学习模型训练与测试、实验结果分析与评估。
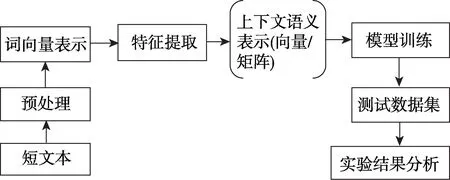
Fig.1 Workflow of deep learning-based short text sentiment tendency analysis图1 基于深度学习的短文本情感倾向分析流程图
1.1 词向量
基于深度学习思想解决自然语言处理任务时,需将文本结构化和数字化,表示成词向量,方便计算机处理。早期基于词袋模型的词向量表示是高维度、高稀疏的,其特征表达能力很弱,不利于特征提取。
基于词嵌入(word embedding)的分布式表示方式的提出,使得深度学习方法用于短文本情感倾向分析成为可能。词嵌入技术通过对大量语料的学习,将短文本映射成低维实向量。词向量再输入深度神经网络中,自动提取上下文特征,得到的最终文本表示用于情感倾向分析。词嵌入技术仍在不断发展,一些用于度量词与词间相似性的预训练语言模型被提出。2013 年提出了Word2Vec[13],2014 年提出了GloVe[14],2016 年提出了OpenAI GPT[15],2018 年提出了ELMo(embeddings from language models)[16]和BERT(bidirectional encoder representation from transformers)[17],2019 年提出了基于Transformers[18]架构的Transformer-XL[19]和XLNet[20]。常用于短文本情感倾向分析的预训练模型包括Word2Vec、GloVe和BERT。
1.2 深度学习模型组件
常用于短文本情感倾向分析的深度学习模型组件包括:长短时记忆网络(long-short term memory network,LSTM)、卷积神经网络(convolutional neural network,CNN)、记忆网络(memory network,MN)、胶囊网络(capsule networks,CapsNets)、图卷积神经网络(graph convolutional network,GCN)以及注意力机制(attention mechanism)[21]。
长短时记忆网络常用于捕获短文本全局语义;卷积神经网络的卷积、池化操作用于提取短文本局部特征;记忆网络通过增加额外的存储单元,能更好地解决长时记忆问题;胶囊网络以动态路由方式学习词间语义关系,减少信息丢失;借助图卷积神经网络可将短文本中的特征信息和结构信息进行融合;结合注意力机制主要为解决深度神经网络对短文本中关键语义不敏感问题。
1.3 深度学习方法与传统方法比较
在短文本情感倾向分析的研究中,基于深度学习的方法较传统方法的优点可总结为以下三点:
(1)对文本特征的提取更准确高效。人工构建特征工程提取到的是短文本的浅层表征,相比较而言,深度学习网络可以实现在不同层次上自动挖掘短文本的隐含特征,故得到的文本表示更丰富。
(2)对文本复杂语义关系的建模能力更强。深度学习方法利用位置编码、图神经网络、预训练模型等手段实现对词序、语法、语义相似性等复杂关系进行建模。
(3)深度学习算法可延伸性更强。短文本是大规模、内容丰富且千变万化的,深度学习方法通过对数据分布相似性或不同任务的相似性建模,实现算法在不同领域或任务上的移植。
2 基于深度学习的篇章句子级粗粒度情感倾向分析
2.1 篇章级的粗粒度情感倾向分析
篇章级情感倾向分析的研究对象是关于产品、服务或事件的带主观情感描述的文章或段落。篇章级情感倾向分析的情感标签有积极、消极和中性。目前,篇章级情感倾向分析所面临的最大挑战是文章或段落中包含的句子可能并不相关,即所描述的可能不是同一个实体,导致特征提取不准确。因此,主/客观句子判断在篇章级的粗粒度情感倾向分析中至关重要,不相关的句子需删除,不重要的特征需过滤。
情感倾向分析常被看作一项分类任务。Pang等[22]将篇章级情感倾向分析视为三分类任务,利用标注文档训练情感分类器,早期这类基于机器学习分类器的方法高度依赖数据特征的选择,对提升情感倾向分析效率有局限性。Kiritchenko 等[23]借助神经网络自动从大量训练文档中学习可区分特征,该利用神经网络学习文本表示的方法较传统方法取得了明显成功,但只考虑了文本浅层语义,忽略了用户偏好和产品特征等客观因素对篇章情感极性的影响。Tang 等[24]利用CNN 学习篇章中用户-产品的关联语义特征,融入到文本表示中。除增加外部关联特征外,考虑到文档内部存在多层次的多粒度特征,即单词特征构成句子,句子特征构成文档。Yang 等[25]则通过改进模型内部结构,提出多层注意力网络(hierarchical attention network,HAN),不同的注意力层捕捉文档的不同粒度特征,该方法为后期更细粒度的情感倾向分析任务提供了很好的思路。
2.2 句子级的粗粒度情感倾向分析
句子级情感倾向分析根据句子所给出的观点信息计算整个句子的情感倾向,句子通常是关于一个产品或服务的评论。主观句子中所包含的观点信息可以帮助判断实体的情感倾向。
句子级的短文本情感信息标注相对篇章级的更耗时耗力,为降低人工数据标注成本,Wu 等[26]提出一种弱监督法,用篇章级和词级的标注数据训练句子级的情感分类器。但实际上,词级的标注数据比句子级的更难获取;另外,人工标注的数据存在主观判断差异等问题,会有噪音,Wang 等[27]则提出双层CNN框架,第一层CNN 通过学习带噪音的标签数据实现对输入数据去噪,第二层CNN 将上层得到的“干净”数据用于句子级情感倾向分析,从而降低数据噪音影响。不同情感标签之间也存在相互影响,特别是中性情感标签,会影响对其他情感标签的判断。该现象不仅在句子级情感倾向分析中存在,细粒度情感倾向分析中也存在。针对上述问题,Wang 等[28]提出RNN(recurrent neural network)胶囊模型,为每类情感标签单独建立胶囊,根据胶囊内的状态激活条件判断当前输入句子的情感倾向。实验结果还证明了即使未用到精心训练好的词/句向量,也能获得好的分类效果。
3 基于深度学习的目标/方面级细粒度情感倾向分析
相比较于篇章句子级的粗粒度情感倾向分析,当短文本中存在多个不同情感倾向的实体时,整个句子的情感倾向是无法准确判断的,但目标/方面级的情感倾向分析可以实现对短文本中所提及所有实体判断其情感倾向,是细粒度的情感倾向分析任务,提供的是针对明确对象的主观信息。目标/方面级的细粒度情感倾向分析(aspect-based sentiment analysis,ABSA)的研究对象是短文本中所提及的所有方面。方面包括方面实体(又称目标[29])和方面类别,例如短文本“餐厅的三文鱼很美味,但服务员不友好”中“三文鱼”是一个方面实体,同时属于“食物”类;另一个方面实体“服务员”属于“服务”类,短文本中对餐厅的两个不同方面所表达的情感倾向分别是“正面/积极”和“负面/消极”。
基于短文本的特点,以及目标/方面级情感倾向分析所面临的挑战,将基于深度学习的细粒度情感倾向分析方法归为三大类:基于单任务的方法、基于多任务联合学习的方法和基于迁移学习的方法。
3.1 基于单任务的方法
处理目标/方面级的细粒度情感倾向分析任务的关键是在上下文中准确找到用于描述目标/方面的观点词或情感信息。基于单任务的方法通过增改神经网络模型内部结构,或融入外部知识的方式扩展词向量[30],例如融入情感常识[31]、图谱知识[32]、社会关系[33]、引入句法信息[34]等,旨在提升模型的上下文复杂语义建模能力,同时解决词向量的情感语义表达不准确、不深刻的问题。
3.1.1 经典神经网络模型
不同的神经网络组件提取的上下文语义不尽相同,基于经典网络模型增改模型内部组件,是一种最常见的深度学习方法,更多的是结合注意力机制[35-36]。
早期Tang 等[37]为充分考虑目标与上下文的关联语义,将句子按目标词分成左右两个子句,TD-LSTM(target-dependent LSTM)算法中目标是两个LSTM的最后一个输入单元,最后隐层输出拼接作为最终的文本表示,该方法未充分考虑到上下文。现存大多数基于LSTM 和注意力机制的双通道混合模型[38](如图2 所示),经过LSTM 层得到初始上下文表示和目标表示,注意力层用于提取对输入目标而言更重要的上下文信息,得到更高效的文本特征表示,最后输入情感分类器中判断输入目标的情感倾向。相关算法有ATAE-LSTM(attention-based LSTM with aspect embedding)[39]、IAN(interactive attention network)[40]和RAM(recurrent attention on memory)[41]等,主要区别在于目标与上下文的语义关联计算方式不同。IAN通过两个并行注意力层实现目标与上下文的双通道交互式关联度计算,RAM则通过在双向LSTM和多层注意力之间增加记忆块实现远距离的语义关联计算。
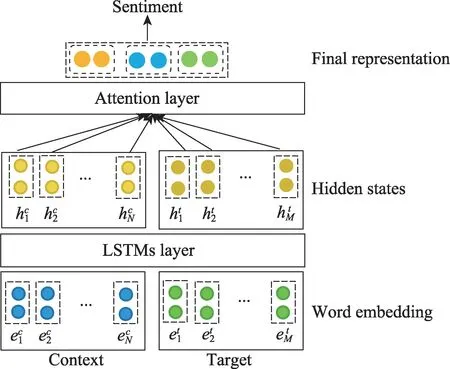
Fig.2 Classic structure of LSTM with attention mechanism图2 基于LSTM 和注意力机制的经典模型
注意力机制可能导致短文本中多个方面与观点词的错误匹配,从而降低模型预测性能;另外,CNN无词序依赖性,可实现并行计算,故在模型训练的时间复杂度上具有一定优势。基于CNN 的情感倾向分析模型(如图3 所示)通过设计不同的门控机制,根据输入方面实体提取短文本内的局部情感特征,达到方面与短文本内观点词高效匹配的目的。Xue等[42]提出基于方面的门控卷积神经网络(gated convolutional network with aspect embedding,GCAE),设计Tanh-ReLU 门控单元实现信息过滤,即根据当前输入的方面实体选择性地输出文本特征,更好地利用了方面实体信息,较于LSTM 结合注意力的模型,该模型结构更简洁,模型计算在训练中更能实现并行化。然而,对于含多个词的方面实体中存在词的重要性不同的问题,例如方面实体“佳能相机”中“相机”应比“佳能”更重要,大部分方法采用池化或简单拼接方式得到方面向量表示,但这两种处理方式都容易丢失关键语义。Huang 等[43]则提出参数化池化(parameterized filters,PF-CNN)和参数化门控(parameterized gated,PG-CNN)两种结构,对方面实体进行卷积操作提取关键词,再与上下文一起输入参数化层。实验结果证明这种卷积处理方法,极大提高了细粒度情感倾向分析模型性能,甚至超越了一些经典循环神经网络模型。

Fig.3 Classic structure of CNN-based aspect-level sentiment tendency analysis图3 基于CNN 的方面级情感倾向分析经典模型
LSTM 和CNN 的隐层状态以及注意力机制的记忆存储能力十分有限,长距离建模过程中容易导致部分语义信息的丢失。记忆网络结合注意力机制的方法(如图4 所示)为上下文中除目标词外的每个词单独构建额外的记忆块,注意力层用于捕获记忆块中对于判断不同目标的情感倾向较为重要的信息。上下文与目标词间的位置关系十分重要,一般来说距离目标越近的上下文越重要。早期Tang 等[44]将目标与上下文的绝对位置关系编码成注意力权重融入记忆块中,为获得上下文与目标间的更多抽象特征,还设计了多层共享参数计算单元,该算法极大提高了模型计算速度。但对于结构复杂的短文本而言,记忆网络并不善分析局部语义,Fan 等[45]则对记忆网络进行了改进,在记忆网络中增加卷积操作,这类方法将具有特定功能的神经网络组件进行多层次组合,实现多功能和多特征的融合,为后期深度学习方法提供一条新思路。
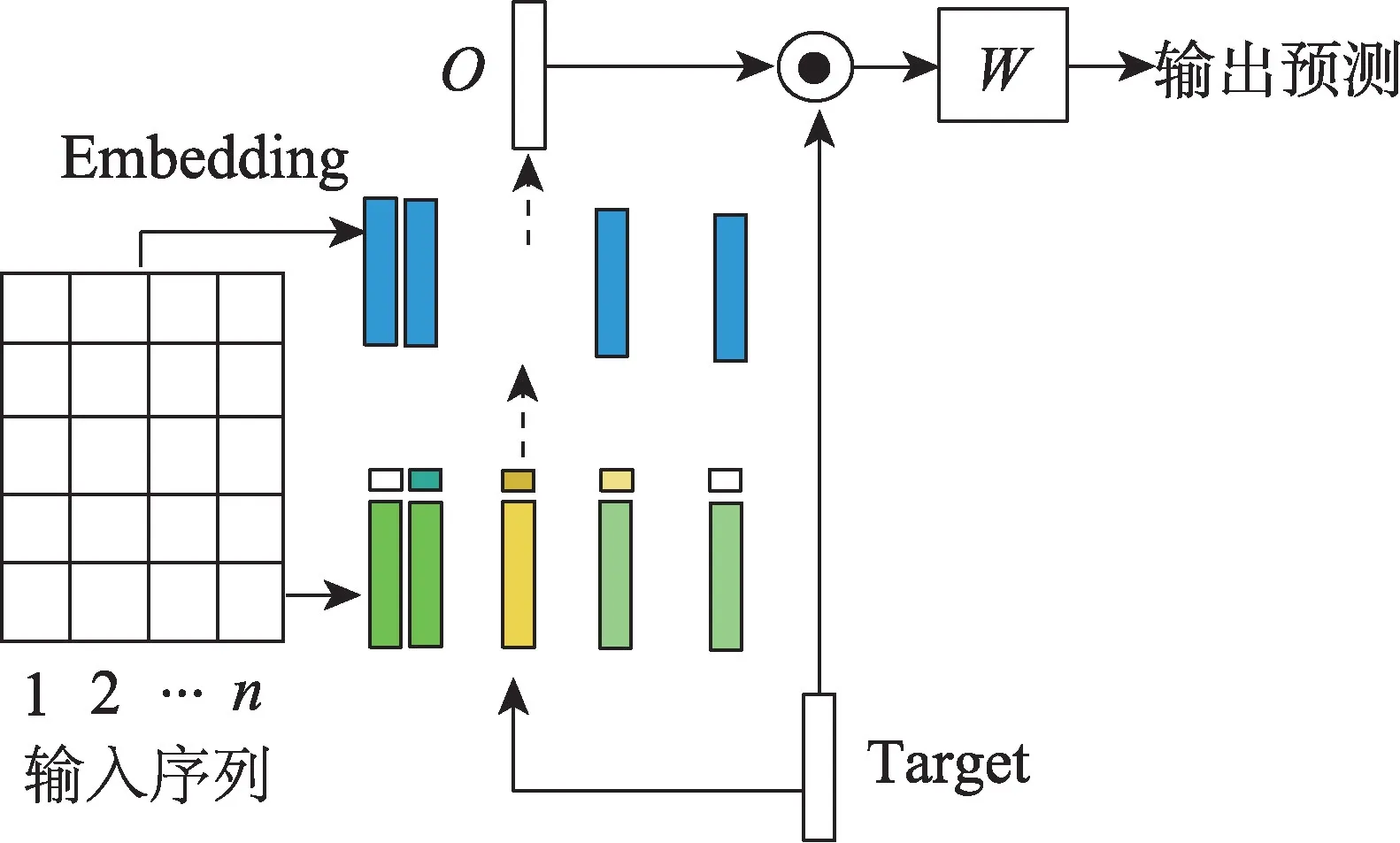
Fig.4 Structure of MN-based target-dependent sentiment tendency analysis图4 基于记忆网络的目标级情感倾向分析模型
除了增改神经网络内部结构外,许多工作还研究了不同预训练语言模型对整个深度学习模型情感倾向分析结果的影响。利用不同预训练语言模型对输入数据进行预训练,得到不同的初始词向量表示,这类方法只改变模型输入部分,其他层不变。Song等[46]提出注意力编码网络(attentional encoder network,AEN),词嵌入层分别采用BERT 和GloVe 两种预训练语言模型,实验结果分析发现基于BERT 的AEN模型比基于GloVe 的AEN 模型在准确率上最多高出0.06,这充分说明不同预训练语言模型会影响情感倾向分析深度神经网络模型的性能。表1 中对提高上下文语义建模能力的算法进行了总结归类,并综合比较了算法优缺点,针对算法缺点给出了改进意见。
3.1.2 融入外部先验知识的方法
Tang 等[37]证明了细粒度情感倾向分析中建立上下文与方面之间的语义联系的重要性。目前短文本细粒度情感倾向分析存在只关注方面与上下文间的语义关联的问题。本小节将介绍如何结合先验知识,达到增强或扩展词向量对情感信息和上下文背景的语义表达能力,同时解决短文本中存在的信息缺失和歧义等问题。
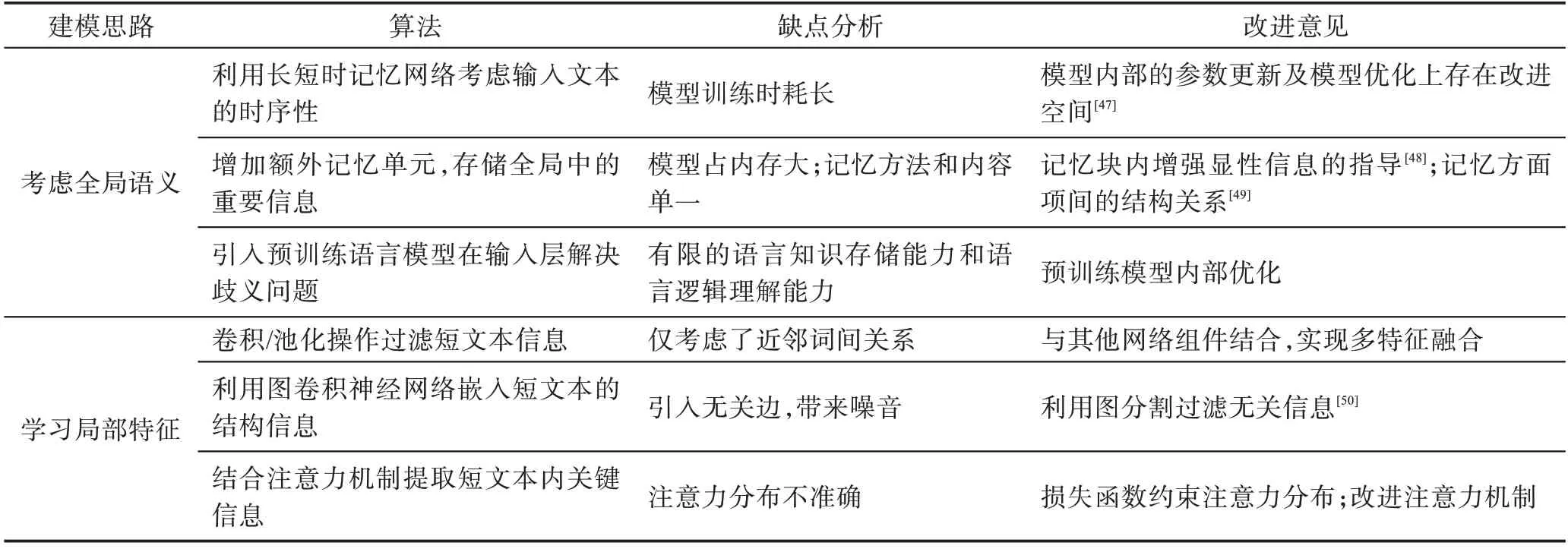
Table 1 Comprehensive comparison of algorithms to improve context semantic modeling capabilities表1 提高上下文语义建模能力的算法综合比较
概率语言模型根据语料中的词间共现关系、词性、语义相似度等训练得到词向量表示,但往往忽略了情感相似度,比如形容词“好的”和“坏的”常一起用于对比两个事物,根据共现关系和词性相似度,它们的词向量余弦相似度很高,但对于情感判断而言,它们的相似度为零。段敏敏[31]利用领域情感词典生成情感词向量,将情感词向量与传统词向量拼接融合,构成一个既包含语义信息,又包含情感特征的扩展词向量,解决了同一个词在不同领域可能表现不同情感倾向的问题。Sentic-LSTM[51]则未采用简单拼接的方式,而是将从SenticNet 情感语料库中得到的情感信息映射为特征向量,嵌入LSTM 的记忆单元,作为LSTM 的一部分,进而增强LSTM 隐层输出的情感表达能力。这类通过额外增加情感特征的方法在一定程度上提高了文本表示的情感表达能力。
短文本篇幅短且结构紧密,所含的信息量大但背景知识不足;另外,同一个词在不同的语境下可能表达出不同语义。针对以上问题,常见方法是结合知识图谱(如图5 所示[51]),将短文本中每个词关联到知识图谱的节点上,根据图谱中节点与节点间的语义相似关系、隶属关系等扩充短文本的背景知识,达到增强情感常识知识[52]或短文本背景知识的目的。林世平等[32]提出一种融合知识图谱的文本表示方法,将图谱知识与隐状态向量结合得到知识感知状态向量,通过设计双通道结构并结合注意力机制选择性地融入用户偏好信息和产品特征信息,作为商品评论短文本的背景知识,用于判断句中词的真实语境。除用户/产品信息的融入外,将社会理论知识应用于情感倾向分析逐渐成为了流行方法,例如将弱社会依赖关系作为微博情感倾向分析的社会背景[53]。该类方法不仅扩展了可用于方面级情感倾向分析的图谱知识,还表明了情感倾向分析可应用于社会舆情控制。
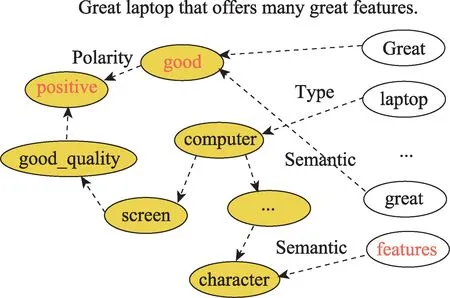
Fig.5 Knowledge graph-based aspect-level sentiment tendency analysis图5 融入图谱知识的方面级情感倾向分析
句法依赖性结构不仅可以解决面向方面的情感倾向分析的长距离多词依赖性问题,利用直接依赖关系还能帮助解决歧义问题。常用句法关系包括依存解析(dependency parse)关系和成分解析(constituency parse)关系,如图6 所示,GCN 将句法关系映射成邻接矩阵,图节点表示即为词向量表示,再根据邻接矩阵更新所有图节点表示,这样便将句法信息融入了文本表示中。经典模型有AS-GCN(aspect-specific graph convolutional network)[54]、R-GAT(relational graph attention network)[55]和SK-GCN(syntax and knowledge via GCN)[56]等,主要区别在于为明确给出的方面构建依赖树时采用了不同的机制。AS-GCN 通过在句法依存树上应用多层GCN,并在其顶部强加一个特定于方面的掩码层,用来获得面向方面的特征;R-GAT为充分考虑特定方面、注意力和句法三者间的关系,采用剪枝算法删除间接关联边,只留下与特定方面有直接关联的句法依赖边,并借助图注意力网络(graph attention network,GAT)[57],使注意力只关注与特定方面在句法上有直接依赖关系的上下文上,该模型在三个标准数据集上取得了最好的实验结果;SK-GCN 则通过合并由句法关系和图谱连接关系映射成的两个邻接矩阵,对短文本的句法信息和背景知识进行了融合,有效解决了信息缺失和歧义问题,进而帮助提升方面级情感分析的准确率。
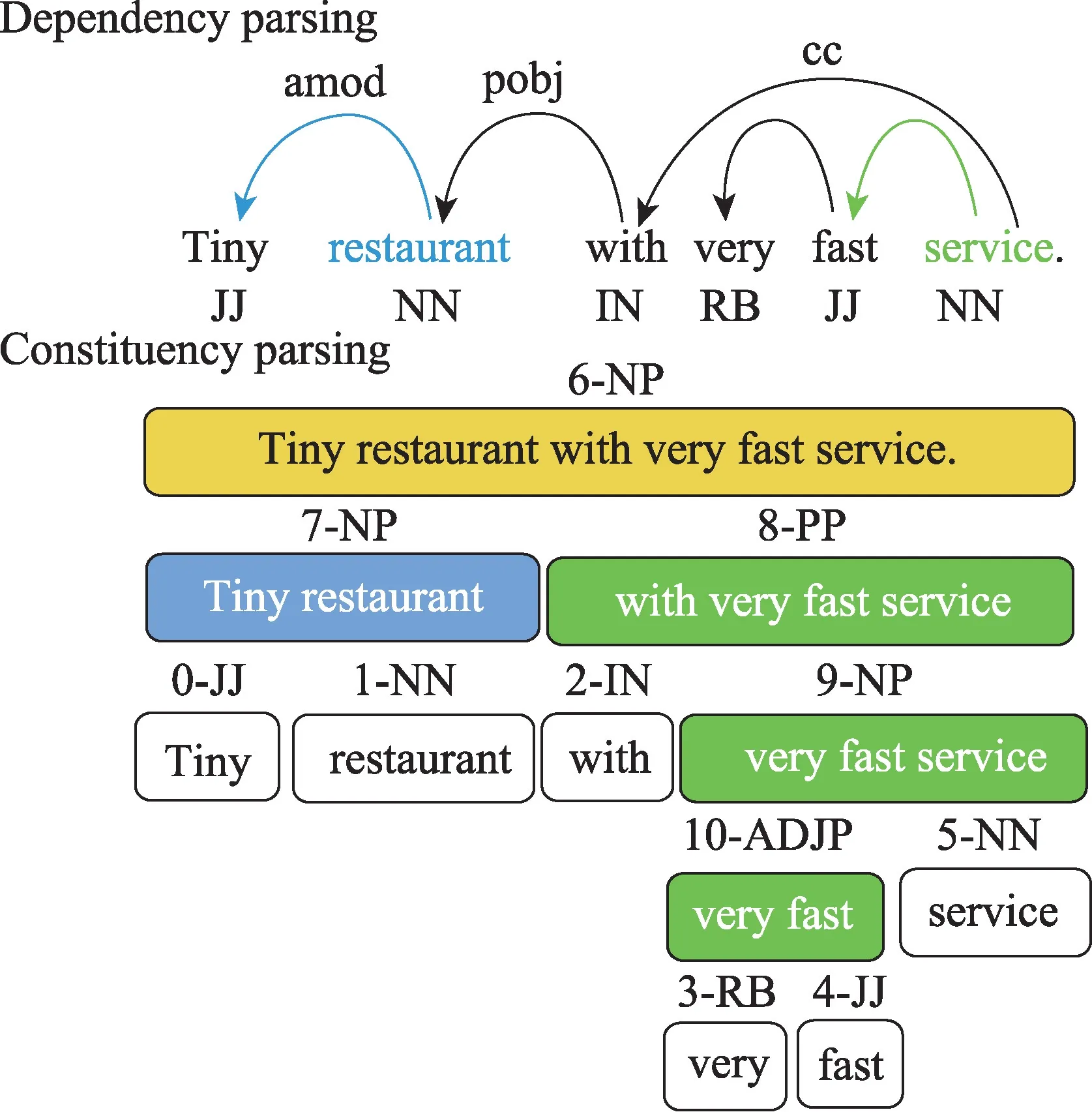
Fig.6 Syntax-aware aspect-level sentiment tendency analysis图6 基于句法关系的方面级情感倾向分析
3.2 基于多任务联合学习的方法
多任务学习方法将方面级的情感倾向分析任务与其他相关但不相同的任务进行联合训练,通过反向传播过程中的信息流动学习任务间的可共享隐层特征,而这样的特征在单任务学习网络中往往不容易学到,如联合学习粗粒度情感特征构成多粒度情感倾向分析[58],共享学习多模态数据特征构成多模态情感倾向分析[59],该类方法可以有效缓解短文本细粒度情感倾向分析的低可用资源问题。
根据目标/方面级情感倾向分析中研究的三个对象,可将其划分成五个子任务:方面实体提取、方面类别判定、观点词提取、方面实体情感倾向分析和方面类别情感倾向分析。通常将方面实体情感倾向分析作为主任务,其他子任务或自然语言处理领域其他非情感分析任务作为辅助任务。
3.2.1 基于多任务学习的序列标注方法
基于序列标注的细粒度情感倾向分析[60]采用联合方面信息标注任务和情感信息标注任务的方式,重新定义目标/方面级的细粒度情感倾向分析任务。基于多任务学习的序列标注方法按照模型结构可分为流水线式和联合式,流水线式是指先做短文本的方面信息标注任务,再基于上一步的结果做情感信息标注任务;联合式是指同时标注出短文本的方面信息及其对应的情感倾向。序列标注方法实现对文本中所提及所有方面的位置信息及其情感信息进行标注(如图7 所示)。位置标注方式包括BIESO 方式(BIE 用于标注含多个词的方面的位置信息,S 表示只含单个词的方面,O 表示非方面词)和TO 方式(T 表示是方面词,O 表示非方面词);三分类的情感倾向标注方式为POS/NEU/NEG,即积极/中性/消极。

Fig.7 Fine-grained sentiment tendency analysis based on sequence labeling图7 基于序列标注的细粒度情感倾向分析
实际上,方面信息的提取任务与情感倾向的判别任务并不相互独立,且后者依赖于前者。Akhtar等[61]提出端到端的多任务学习模型,序列标注模型由双向LSTM 层和自注意力层构成,情感倾向的判别过程中只将方面信息标注正确的句子作为分类模型的输入,分类模型有卷积层和掩码层,掩码层用于屏蔽非方面词,使得误差反向传播时只传B/I 标签下情感分类错误的梯度,这种方式可以有效减少O 标签的影响。He 等[62]联合了篇章级粗粒度任务和方面级细粒度任务,引入消息传递机制显式建模粗/细任务的交互过程,实验设计和对比了流水线式和联合式两种模型,结果表明流水线式比联合式情感倾向分析模型性能更好。这种粗细多任务学习方法既扩展了短文本粗粒度特征,又解决了细粒度情感倾向分析中数据短缺问题。
采用信息抽取方式可以获取更全面、更具体的短文本信息,如方面/观点词、观点持有者、情感极性和原因等。信息抽取方式将细粒度情感分析转化为二元组或三元组的信息抽取任务(如图8 所示)等。Wan 等[63]将方面实体情感倾向分析和方面类别情感倾向分析合为一个任务,进行实体-类别-情感(targetaspect-sentiment,TAS)三元组抽取任务,TAS 模型将BERT 作为编码层用于捕获全局语义,全连接层、Softmax 层和CRF(conditional random fields)[64]层为解码层,分别用于分类和信息标注,针对输入的方面类别和情感极性,第一个输出用于判断句中是否有显式的方面,第二个输出用于标注句中的显式方面,实验结果证明了方面情感的判断并不单独取决于具体实体或其类别,而由实体及其类别共同决定。类似方法还有Wang 等[65]提出基于方面类别进行方面-观点二元组的抽取任务,对抽取出的方面词和观点词直接进行方面级的情感倾向分析。

Fig.8 Information extraction in fine-grained sentiment tendency analysis图8 细粒度情感倾向分析中的信息抽取
3.2.2 多方面多情感倾向分析
对于句中存在多个不同情感倾向的不同方面的多方面多情感(multi-aspect-based multi-sentiment,MAMS)倾向分析问题,上述面向单方面的情感倾向分析方法的处理方式是将句子拆分成只标注一个方面信息的多个句子,然后只对句中标注的单个方面进行情感倾向分析,这类方法未考虑不同方面间的相互影响,容易导致分类错误。多方面多情感倾向分析实现同时对文本中所提及所有方面的情感倾向判别,这类任务比单方面单情感倾向分析更加复杂,但可以看作是多个单方面单情感倾向分析任务的联合学习。
结合注意力机制计算上下文权重时,受其他方面的影响,容易将注意力分配到其他不相关的观点词上,Hu 等[66]提出约束注意力机制神经网络(constrained attention network,CAN),通过在注意力上增加约束性的损失函数实现不同方面的注意力分布尽量正交,但每个方面的上下文注意力分布尽量离散,实验证明这种约束上下文注意力分布的方法在MAMS 中取得了很好效果。不同于CAN,Li 等[67]设计交互式损失函数约束每个类别判定的概率输出只能判别当前类,另一点不同是借助GAT 学习句中成分解析关系,即根据词与词构成的短语成分关系搜索短文本中与当前输入的方面所对应的情感信息。多方面多情感倾向分析的难点在于如何同时获取不同方面的可区分特征表示,减少方面间的相互影响,从而准确高效地进行多方面级的多情感判断。当短文本中只包含一个方面时,目标/方面级的细粒度情感倾向分析任务便退化成句子级的粗粒度情感倾向分析任务。
3.2.3 联合学习非情感倾向分析任务
传统多任务学习方法中多个任务通过共享隐层相互学习,仅仅通过错误反向传播相互影响,这种相互作用往往是不可控的,且缺乏可解释性。联合学习情感倾向分析相关任务或其他非情感倾向分析任务时,通过在模型内部设计多任务交互模块,显式地建模任务间的互相学习过程,进而提高多任务学习模型的可解释性,成为了近几年短文本细粒度情感分析的研究热点。
对短文本先进行主题聚类[68],用于辅助情感倾向分析。Gui等[69]提出基于多任务学习思想的互相学习法(multi-task learning with mutual learning,MTL-ML),将主题模型(topic models)和情感倾向分析模型用一个共享权重单元关联起来,训练过程中通过最大化主题权重分布和情感语义注意力分布之间的相似性,实现两任务间的互相学习。Qin 等[70]则认为对话行为识别(dialog act recognition)和情感倾向分析两个任务在捕捉人的说话意图上具有相似性,即对话行为和情感倾向分别表示说话人的明示意图和隐含意图,设计深层交互关系网络(deep co-interactive relation network,DCR-Net)用于两个任务之间的多步骤交互,不仅可以逐步建模和捕获深层交互关系,还能更好地传递知识。这类多任务学习方法将不同任务的相似或相关的部分单独提出来学习,既降低了不同任务模型训练过程中无关特征间的相互干扰,又显式地建模了任务间的交互关系,进而提升了多任务学习模型的可解释性。
3.3 基于迁移学习的方法
3.3.1 迁移学习方法简介
现存深度学习网络模型大多数是基于数据驱动的方法,需要大量的标注数据训练模型参数,且分类模型的效果对训练数据集的数量和质量较敏感。针对上述问题,基于迁移学习的情感倾向分析方法(如图9 所示),先利用源领域标注数据和目标领域少量甚至无标注的数据训练网络模型,再输入目标领域测试集对模型进行微调以适应目标领域的目标任务。迁移学习方法常用于跨任务[71]、跨领域[72]和跨语言[73]的细粒度情感倾向分析,其关键是找到源任务和目标任务之间的相似性。
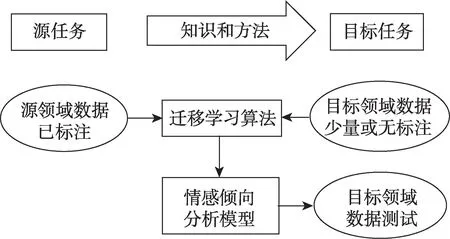
Fig.9 Framework of transfer learning-based sentiment tendency analysis图9 基于迁移学习的情感倾向分析框架
3.3.2 基于迁移学习的细粒度情感倾向分析
基于迁移学习的细粒度情感倾向分析方法可归纳出迁移什么、如何迁移和何时迁移三个基本问题。重用模型内部部分语义结构是最常见的迁移学习方式。王源[74]将在机器翻译任务中训练好的编码器用于情感倾向分析,为解决任务间的特征差异问题,还增加特征提取层,实现基于特征迁移的跨任务情感倾向分析。针对迁移什么和如何迁移两个基本问题,Li等[75]设计双内存交互(dual memory interaction,DMI)模块,用于捕获方面与观点词之间的语义关联,并结合选择对抗学习(selective adversarial learning,SAL)解决跨领域知识迁移过程中领域数据特征分布差异问题,同时尝试解决了领域低资源问题。鉴于数据的领域依赖性问题,很多情感倾向分析深度学习方法并不适用于当数据来自不同领域或所用语言不同的情况。Lambert[76]使用受限翻译工具将源语言翻译成目标语言,只迁移短文本中与给出方面实体对应的观点词部分,实现跨语言的方面级情感倾向分析。这类基于迁移学习的方法通过共享模型部分参数方式,或共享模型部分语义层和部分特征的方式,提升模型泛化学习能力,进而提高模型的实际可用性。
基于深度学习的细粒度情感倾向分析方法如表2 所示。
4 情感倾向分析数据集
数据集对于深度学习模型的训练来说至关重要,有效的数据集能帮助验证基于深度学习的情感倾向分析方法的效能。本章以情感倾向分析任务为背景,分别收集了中文数据集(如表3 所示)和外文数据集(如表4 所示),并对各数据集的情感标签、数据量以及适用任务进行了简单描述。
4.1 中文情感倾向分析数据集
(1)ChnSentiCorp_htl_all(中文情感分析酒店语料)[77]:由中科院谭松波收集整理的一个较大规模的酒店评论语料,共10 000 条评论,正面评论有7 000条,负面评论有3 000 条,分为4 个子数据集。情感标签只包括正面和负面,一般用于篇章句子级的粗粒度情感倾向分析。
(2)COAE(中文观点倾向性分析测评)[78]:COAE2014的任务4 提供的微博数据集共计40 000 条微博,已标注数据有10 000 条,带情绪的数据有7 000 条。训练集数据来自同一话题,正负面情绪数据分别有1 003条和1 171 条;测试集数据来自手机、保险、翡翠3 个不同话题,正负面情绪数据分别有3 776条和3 224条。
(3)NLPCC(自然语言处理会议)[79]:2014 年的数据集中训练集含10 000 条中文产品评论数据,测试集中正面和负面标签的数据评论各1 250 条,可用于句子级的粗粒度情感倾向分析。
(4)新闻点评(Chinese news comments)[43]:收集了大量包括政治和娱乐两方面的中文新闻评论,专用于方面级的细粒度情感倾向分析,情感标签有3类:积极、消极和中性。训练集中3 类情感标签数据量分别为5 633、6 001 和8 403。
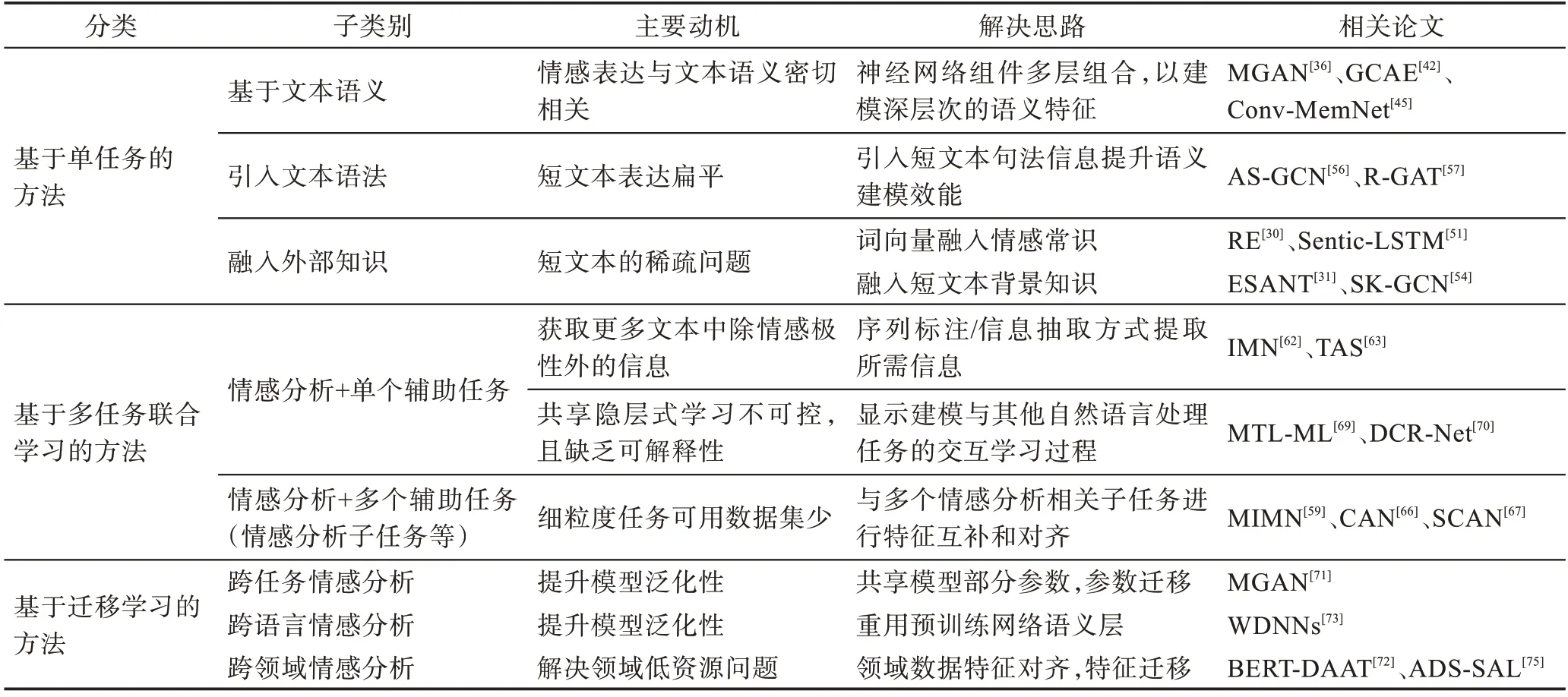
Table 2 Summary of deep-learning methods for fine-grained sentiment tendency analysis表2 基于深度学习的细粒度情感倾向分析方法总结
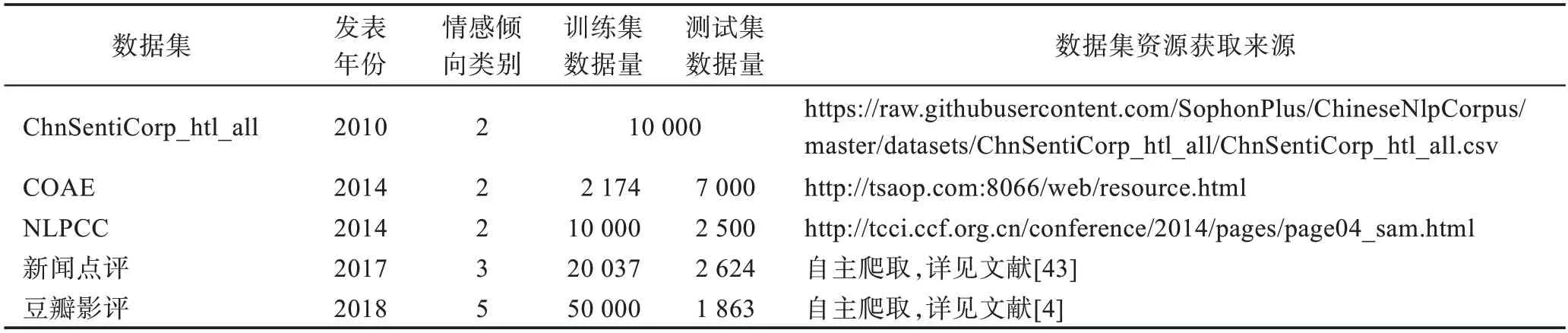
Table 3 Chinese sentiment tendency analysis dataset表3 中文情感倾向分析数据集
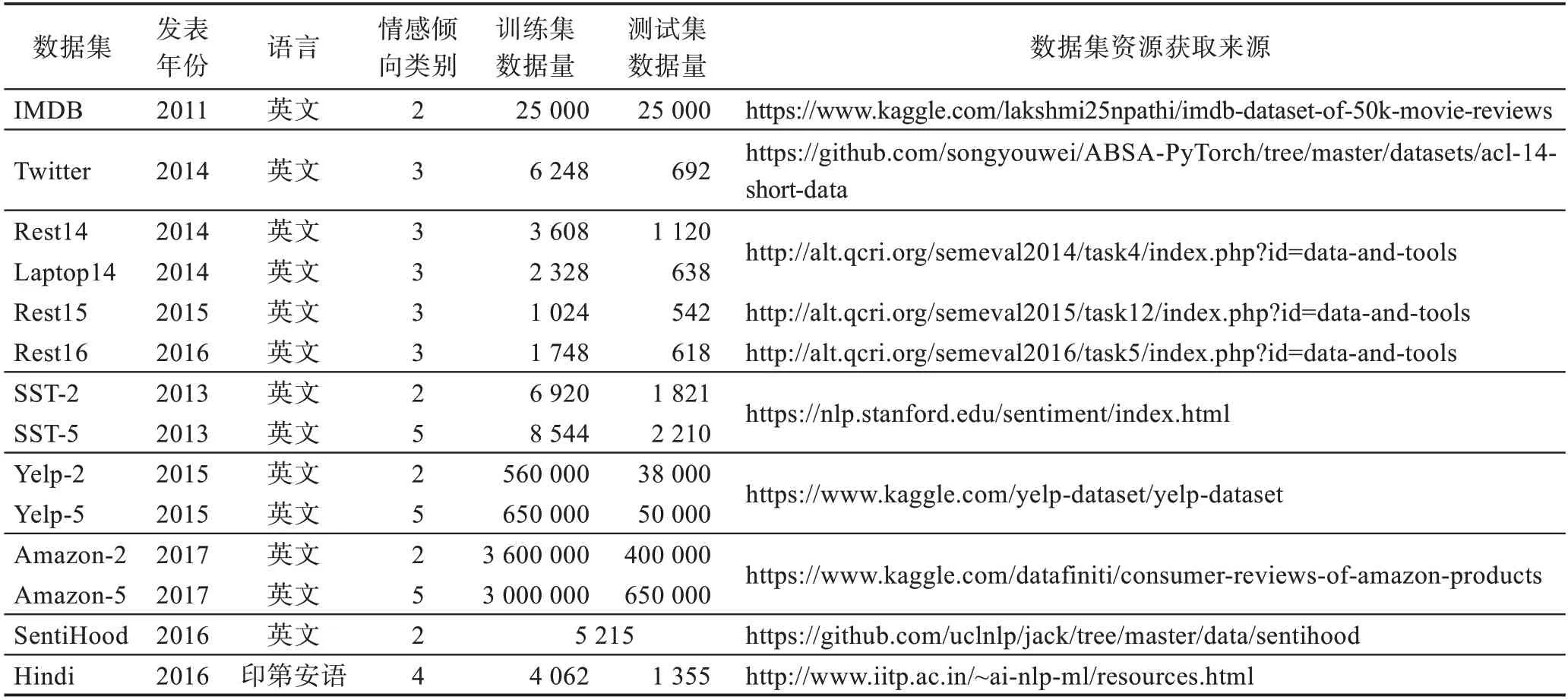
Table 4 Foreign sentiment tendency analysis dataset表4 外文情感倾向分析数据集
(5)豆瓣影评数据集[4]:利用网络爬虫技术,收集自国内影响较大的豆瓣电影网站数据。该数据集中电影评分划为5 个等级共10 分,2 分最差,6 分及格,8分好评。除表3 中训练集和测试集外,还有50 000 条验证集数据,情感倾向标签按等级分,该数据集粗细粒度的情感倾向分析都适用。
4.2 外文情感倾向分析数据集
(1)IMDB(Internet movie database)[80]:包含50 000条以情绪(正面/负面)标记的电影评论,内容涉及影片的演员、内容介绍、等级和评论等。Keras中已对评论文本进行了预处理,评论中的每个单词由一个对应整数代替。IMDB 数据集常用于篇章句子级的粗粒度情感倾向分析。
(2)SemEval(semantic evaluation):SemEval 是一项关于语义分析与评估的NLP 比赛,其中情感倾向分析相关任务主要包括SemEval2014 Task4、SemEval2015 Task12 和SemEval2016 Task5,该3 个任务均提供restaurant 数据集,即Rest14/Rest15/Rest16。SemEval2014 Task4 中还提供laptop 数据集,即Laptop14。SemEval的情感标签有3 类:积极、消极、中性。常用于目标/方面级的细粒度情感倾向分析。
(3)Twitter[81]:它是在社交平台推特的应用程序接口上通过搜索关键字爬取的tweets,情感标签分3类:积极、中性和消极。常用于目标/方面级的细粒度情感倾向分析,该数据集在表4 中资源获取来源地址参考自文献[46]。
(4)SST(Stanford sentiment treebank)[82]:该数据集收集的是电影文本,有两个版本可用,五分类(非常积极/积极/中性/消极/非常消极)的SST-1 和二分类的SST-2。除了表4 中的训练集和测试集,SST-1 验证集包含1 101 条数据,SST-2 验证集包含872 条数据。SST数据集常用于篇章句子级的粗粒度情感倾向分析。
(5)Yelp[25]:Yelp 是美国最大的一个点评网站。Yelp 数据集是一个涵盖用户、商家和点评数据的子集,收集的是波士顿、芝加哥、洛杉矶、纽约、旧金山5 个城市关于餐厅和食品的评论。Yelp 数据集分两类:一个是5 评分等级的Yelp-5;一个是正负情感极性的Yelp-2。常用于篇章句子级的粗粒度情感倾向分析。
(6)Amazon[25]:该数据集整理自亚马逊购物网站的商品评论,包括两个版本:用于二分类的Amazon-2以及五分类的Amazon-5。这两个数据集常用于篇章句子级的粗粒度情感倾向分析。
(7)SentiHood[83]:数据来源于Yahoo!的一个问答平台,内容是关于伦敦的城市社区评论。数据集中共含5 215 条问答形式的短评,该数据集常用于目标/方面级的细粒度情感倾向分析。
(8)Hindi[84]:是一个常用于目标/方面级细粒度情感倾向分析的印第安语数据集,其跨12 个领域共收集5 417 条评论,其中方面实体共有4 509 个,训练集中有3 385个方面实体,测试集中有1 124个方面实体。
5 实验评价指标和模型性能对比
性能评估是短文本情感倾向分析实验中的最后一步,短文本情感倾向分析中常用准确率和F1 测度评价深度学习模型的性能。
5.1 实验评价指标
5.1.1 准确率Accuracy
模型正确分类的样本数与总样本数的比值就是准确率,通常来说,准确率越高越好。公式描述如下(TN为真实情感为消极且预测正确的样本数,FN为真实情感为消极但预测错误的样本数,TP为真实情感为积极且预测正确的样本数,FP为真实情感为积极但预测错误的样本数):
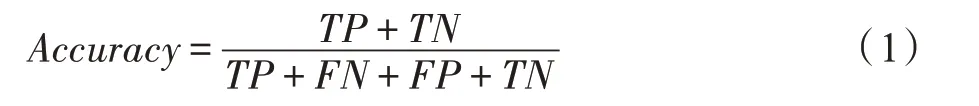
5.1.2 精准率Precision
精准率指的是在预测结果为积极的样本中,真实标签也是积极的样本所占比值。公式描述如下:

5.1.3 召回率Recall
召回率指的是真实情感为积极且预测正确的样本数占总样本数的比值。公式描述如下:

5.1.4 F1 测度
由于精准率和召回率两评价指标值间相互影响,不能同时达到最优。为对模型进行更好的整体评价,计算精准率和召回率两个指标的算术平均值得到新评价指标F1 测度。计算公式如下:

Macro-F1 先对每个类别单独计算F1 值,再取所有类别F1 值的算术平均值作为全局指标;Micro-F1不区分类别,直接用总样本的精准率和召回率计算F1 值。
5.1.5 均方误差MSE
该统计参数是预测数据和原始数据对应点误差的平方和求均值,其值越小越好。常用于评估多标签情感倾向分析模型性能。公式描述如下(n为总样本数,yi是真实情感标签,是预测值):

5.2 典型模型性能对比
为了进一步分析基于深度学习的细粒度情感倾向分析方法的性能,本节借助3个标准数据集SemEval的Rest14、Laptop14 和Twitter 数据集,以及两个通用评价指标对各经典模型性能进行客观评价和对比,其中准确率是情感倾向分析模型性能的最重要的评价指标,Macro-F1 是另一个有价值且重要的模型性能度量指标。以下实验结果整理自多篇论文(如表5所示)。
表5 中第一部分是传统基于机器学习和特征工程方法的实验结果;第二部分是基于LSTM 以及结合注意力机制方法的实验结果;第三部分是基于卷积神经网络和记忆网络模型的实验结果;第四部分是基于图卷积神经网络模型的实验结果。
对表5 进行纵向分析,首先可明显看到SemEval数据集的使用率最高,这可能由于SemEval数据集中数据量更大,标注的信息更全面且涵盖两个领域的标注数据,适用于更多任务;其次,从实验结果可以看出在Rest14 数据集上的准确率最高,Laptop14 数据集上的结果次之,Twitter 数据集上的准确率最低,且较于Rest14,Twitter 数据集上的结果最多降低了0.10的准确率,这是由于tweets 数据更口语化,语言表达更复杂,导致上下文语义更难准确捕获;最后,从结果上分析出广义F1 测度值比准确率低,且在Rest14数据集上表现得更明显,这可能由于在Rest14 数据集上容易将原本的积极类预测为消极类。
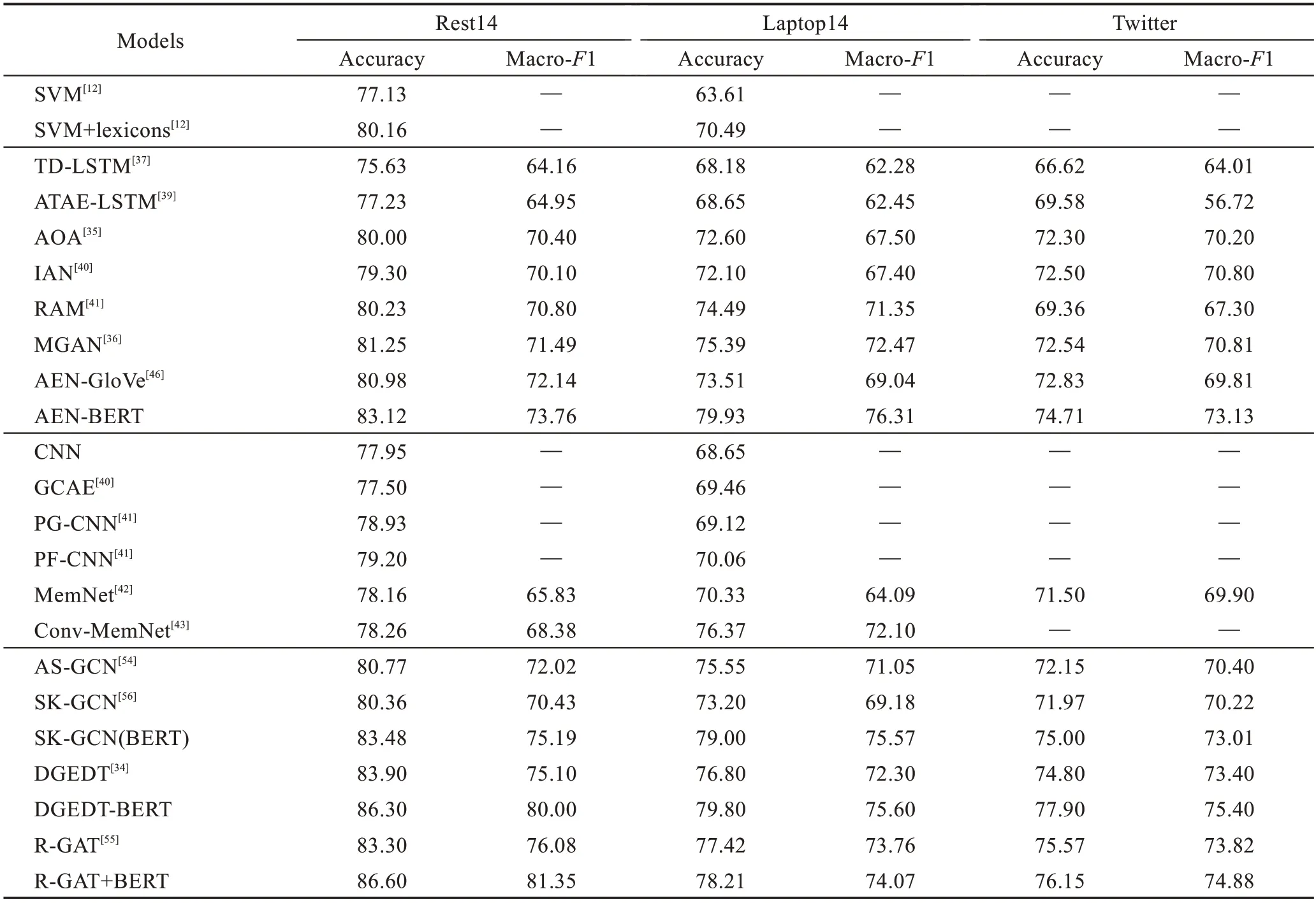
Table 5 Comparison of experimental results of target/aspect-level sentiment tendency analysis表5 目标/方面级情感倾向分析实验结果对比%
对表5 进行横向分析:(1)可看出结合语义词典的方法可以有效提升基于传统SVM(support vector machine)方法的性能,约提升了大于0.03 的准确率。(2)基于LSTM 结构的模型比传统机器学习方法提升了0.01~0.03的准确率,对比简单的LSTM 模型与结合注意力机制的LSTM 模型的实验结果发现,引入注意力机制可以极大提高情感倾向分析效率;其次,AEN中设计多头注意力层的使用进一步提升了模型效率。(3)目前利用图卷积神经网络融入基于方面的依存句法关系的方法取得了最好的效果,同时在模型输入部分利用预训练模型可以帮助进一步提高准确率。
6 总结与展望
短文本数据的简短性、歧义性等特点给情感倾向分析带来巨大挑战。近些年,深度学习技术凭借高效特征提取能力、丰富建模手段和可移植性在情感倾向分析任务中表现突出。结合深度学习思想构建更加准确有效的短文本情感倾向分析模型仍是自然语言处理领域的重点研究方向之一。
基于深度学习的短文本情感倾向分析方法在向分类效率更高、计算更快、不同任务与领域间更通用的方向发展,主要表现为:(1)引入预训练语言模型,初始化深度网络模型的输入,得到表达更高效的初始词向量;(2)结合一些机制,如注意力机制、门控机制和信息传递机制等,控制模型内部信息流动,增强上下文语义建模能力;(3)简化模型结构,减少内存占用率,结合可并行化训练的神经网络组件,提升模型训练速度;(4)联合其他任务进行多特征互补学习,不仅帮助缓解低可用资源问题,还可提升模型泛化能力。
结合短文本情感倾向分析所面临的挑战,提出以下三点未来研究方向:
(1)短文本长度过短,导致数据特征稀疏。结合外部先验特征,挖掘短文本内部表征及深层语义特征,一直是增强上下文语义建模能力的重要研究内容。如何利用从其他自然语言处理任务中获取的信息辅助情感倾向分析,是未来一个值得研究的重要方向。
(2)短文本表述不规范,结构复杂,导致歧义问题。常用方法是补充短文本的结构信息。中文短文本情感倾向分析受到分词准确率的约束。构建不同粒度的文本向量化方法,如字向量表示、词向量表示和短语向量表示等,再结合改进的注意力机制是一个值得研究的课题。
(3)短文本数据量大且内容复杂,领域可用标注资源少,且深度学习模型的跨领域可移植性差,导致更实用的任务无法进行。基于迁移学习的方法仍存在提升空间,如何将少样本学习和弱监督方法应用于短文本情感倾向分析值得未来进一步探讨。
7 结束语
本文对短文本情感倾向分析的研究背景和意义进行了综述,并重点阐述和讨论了深度学习方法对短文本细粒度情感倾向分析的重要贡献。此外,本工作基于三个标准数据集和两个重要评价指标,综合评估了用于细粒度情感倾向分析的经典深度学习网络模型性能。深度学习方法较传统方法得到了更高的准确率,但仍有若干问题待解决。最后,结合上述内容对短文本情感倾向分析研究中存在的开放问题给出了一些未来方向。期待未来有更多用于解决短文本情感倾向分析问题的新思路和新方法。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
导航定位学报(2022年4期)2022-08-15
小天使·三年级语数英综合(2022年4期)2022-04-28
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
汽车导报(2017年5期)2017-08-03
中学生数理化·高二版(2016年4期)2016-05-14
长江学术(2015年1期)2015-02-27
阅读与作文(英语高中版)(2013年12期)2013-12-11
阅读与作文(英语高中版)(2013年11期)2013-11-13
