
零样本图像分类综述
2021-05-14 03:41刘靖祎史彩娟涂冬景
计算机与生活 2021年5期
刘靖祎,史彩娟+,涂冬景,刘 帅
1.华北理工大学人工智能学院,河北唐山063210
2.深圳大学电子与信息工程学院,广东深圳518060
深度学习的飞速发展得益于丰富的人工标注数据,监督式学习与深度学习相结合的方法在图像分类等领域效果突出,许多基于深度学习的监督学习模型被提出,如ResNet[1]、DenseNet[2]、ArcFace[3]等。然而,现实中大量样本是没有标签的,标注训练样本需要昂贵的人工成本;有些场景很难获取样本,仅有少量训练样本甚至没有训练样本。
研究发现人类可以辨识大概30 000 个对象类别的信息[4],同时人类拥有知识迁移能力,在学习新事物时可以将过去学习存储的知识迁移到新事物。因此,人们提出了零样本学习(zero-shot learning,ZSL)概念。零样本,即无训练样本,零样本学习旨在让深度学习模型能够识别没有训练过的新类别[5]。2008年Larochelle 等人[6]针对字符学习提出了一种零样本学习方法。2009 年Palatucci 等人[7]正式提出了零样本学习(ZSL)概念。Lampert 等人[8]提出了基于属性的类间迁移学习的经典零样本学习算法和广泛应用于零样本学习的AWA(animals with attributes)数据集。Chao 等人[9]认为零样本学习在测试阶段不应当只区分不可见类,应该将训练过程中学习到的可见类与不可见类一同进行识别,因此,提出了广义零样本学习(generalized zero-shot learning,GZSL)。不同于零样本学习方法,广义零样本学习设置了一个更贴近现实的场景,在测试时测试样本包含了可见类和不可见类。由于可见类和不可见类之间类别不平衡以及零样本学习模型在分类时存在将不可见类归为可见类的可能性,广义零样本学习为零样本学习带来了新的挑战。
近年,基于零样本学习的图像分类得到广泛研究,有效克服了没有标注训练样本的局限,取得了很好的分类性能。零样本图像分类指的是训练集和测试集互不包含的情况下进行分类[10]。目前,零样本图像分类主要包括基于空间嵌入的方法和基于生成模型的方法。基于空间嵌入的零样本图像分类方法根据嵌入空间的不同又分为基于语义空间嵌入、基于视觉空间嵌入和基于公共空间嵌入三种方法。基于生成模型的零样本图像分类方法利用生成对抗网络(generative adversarial networks,GAN)、变分自编码器(variational auto-encoder,VAE)和基于流的生成模型(flow-based generative model)生成不可见类特征,从而将零样本图像分类问题转换为传统的基于监督学习的图像分类问题。
1 零样本学习
零样本学习依赖于有标签的可见类别,以及不可见类别与可见类别相关联的语义信息。可见类别和不可见类别通常在一个高维向量空间(语义空间)中相关,将可见类属性特征迁移到不可见类中。
零样本学习中,设可见类为S={(x,y,c(y))|x∈X,y∈YS,c(y)∈C},其中x为视觉特征,y是其对应的标签,c(y)是对应的类嵌入;U={(u,c(u))|u∈YU,c(u)∈c}表示不可见类,其中u是不可见类标签,C(U)={(c(u1),c(u2),…,c(uL))}为不可见类的嵌入,且Ys⋂Yu=∅。零样本学习的目的是fZSL:X→YU,对于广义零样本学习,测试时包含训练样本,即fGZSL:X→YS⋃YU。
零样本学习通过属性迁移的方式,将可见类学习到的属性迁移到不可见类上,建立可见类与不可见类的耦合关系,从而实现在没有学习不可见类标签样本的前提下完成对不可见类的分类。零样本学习框图如图1 所示。
由图1 可知,零样本学习建立可见类和不可见类的耦合关系依赖于一个嵌入空间。零样本学习通过提取给定图像的视觉特征来构造视觉空间,通过提取对应类别的语义向量构造语义空间,然后通过特征-语义之间的映射关系来构造嵌入空间。在训练阶段,首先学习可见类图像特征和对应标签,找到图像特征与对应类别之间的关系,然后利用该关系对不可见类样本进行分类,即首先利用图像的视觉特征预测对应的语义特征,然后语义特征匹配所对应类别。
零样本学习的表达式可以写成如下形式:

其中,函数f表示将图像视觉特征x映射到嵌入空间k中,函数g表示通过度量(比如欧氏距离)来确定图像所对应的标签。
根据训练阶段是否使用不可见类样本的无标记数据,零样本学习可以分为直推式零样本学习和归纳式零样本学习两类。
1.1 直推式零样本学习
2012 年,Fu 等人[11]提出直推式零样本学习方法,在训练阶段通过使用不可见类的无标记样本来提升零样本学习测试阶段图像分类的精度,这些无标记样本可以提高函数f在不可见类上的泛化能力和迁移能力。直推式零样本学习框图如图2所示。直推式零样本学习方法在训练时会使用不可见类的无标记样本,导致零样本学习模型在训练时具有一定的局限性。

Fig.2 Framework of transductive zero-shot learning图2 直推式零样本学习框图
1.2 归纳式零样本学习
与直推式零样本学习方法不同,归纳式零样本学习方法在训练阶段只训练可见类样本,即函数f只学习可见类样本。在预测阶段,函数g以并行的方式对不可见类样本进行类标签预测,在此过程中每个标签的预测是相互独立的。归纳式零样本学习方法更加灵活,有较强的可延伸性,是目前零样本图像分类中较为常用的方法。归纳式零样本学习框图如图3 所示。
2009 年,Lampert 等人[8]提出了经典的归纳式零样本学习模型DAP(direct attribute prediction)和IAP(indirect attribute prediction)。DAP 模型是直接预测模型,首先使用训练数据直接学习图片特征到属性特征的映射关系,然后通过对应的属性特征进行不可见类图像分类。IAP 模型是间接预测模型,通过学习可见类所对应的标签间接学习图片特征到属性特征的映射关系,首先学习可见类图片特征到可见类的映射,然后学习公共属性与对应类别之间的映射,最后利用公共属性预测不可见类图像。DAP 和IAP两个模型的框图如图4 所示。
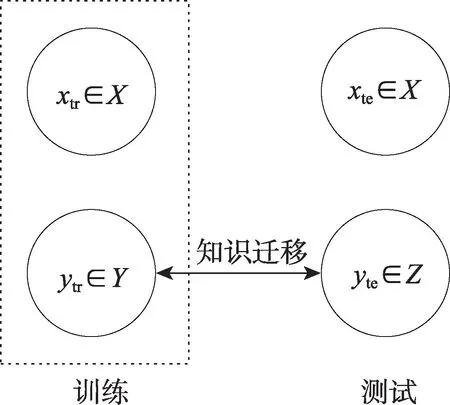
Fig.3 Framework of inductive zero-shot learning图3 归纳式零样本学习框图

Fig.4 DAP model and IAP model图4 DAP 模型和IAP 模型
2 零样本图像分类
现有的零样本图像分类方法主要分为两类:基于空间嵌入的零样本图像分类方法和基于生成模型的零样本图像分类方法。基于空间嵌入的方法依赖于一个嵌入空间,利用视觉和语义之间的映射关系完成分类,而基于生成模型的方法通过生成不可见类的特征完成分类。
2.1 基于空间嵌入的零样本图像分类方法
获得图像的视觉特征和语义特征后,通常可以通过两个步骤解决零样本图像分类问题:首先学习一个嵌入空间,然后在嵌入空间中进行最近邻搜索,将图像视觉特征与不可见类原型进行匹配。基于空间嵌入的零样本图像分类方法利用可见类和不可见类的特征在嵌入空间中的相关性来完成可见类向不可见类的属性迁移。根据所选择嵌入空间的不同,基于空间嵌入的零样本图像分类方法分为基于语义空间嵌入的方法、基于视觉空间嵌入的方法和基于公共空间嵌入的方法,三种方法的结构框图如图5所示。

Fig.5 Framework of zero-shot image classification based on space embedding图5 基于空间嵌入的零样本图像分类框图
2.1.1 基于语义空间嵌入的零样本图像分类
基于语义空间嵌入的零样本图像分类方法将图像的视觉特征嵌入到语义空间中。
早期方法注重视觉特征嵌入到语义空间的方式[12-13]以及语义空间的选取[14],如Akata 等人[12]提出的ALE(attribute label embedding)模型把每个类别的视觉特征都嵌入语义空间中,将零样本图像分类问题看作标签嵌入问题,通过测量输入和输出与目标函数之间的兼容性来预测不可见类图像的类别;Frome等人[13]提出一种深度视觉-语义嵌入模型(deep visual-semantic embedding model,DeViSE),使用标记的图像数据和未经标注的文本中收集的语义信息训练模型,从而完成零样本图像分类任务;Socher 等人[14]将不可见类图像的视觉特征映射到一个低维的语义空间(该语义空间由文本中的词向量构造),利用无监督语义词向量对其进行分类。但是早期方法视觉特征嵌入的方式和类别比较单一,并且语义空间选取的不同容易导致匹配标签出现困难,进而影响零样本图像分类的准确率。
近年,为了克服以上问题,一些新的基于语义空间嵌入的方法被提出。Xie 等人[15]考虑到将图像特征直接嵌入到语义空间进行训练,模型无法很好地学习单个图像中不同区域间视觉特征的关系,提出了一种区域图嵌入网络(region graph embedding network,RGEN),将基于区域的关系推理融入到嵌入空间学习,利用转移损失和平衡损失来进行零样本图像分类模型端到端的训练。Huynh 等人[16]认为模型经过训练后,在匹配不可见类标签时容易忽视一些区域内的标签,提出一种基于共享多注意机制的多标签框架MLZSL(multi-label zero-shot learning)识别图像中的多个不可见标签,并找到每个标签的相关区域生成多个注意力特征,利用每个标签的语义向量选择最合适特征来计算标签的预测得分。Song 等人[17]考虑到有些类别间的特征差异十分微妙(如酒店的房间和家里的卧室),常用的语义特征不能描述场景的复杂性,无法将非常相似的类别进行有效分类,因此在语义空间中将相似类别的多个语义特征来源进行整合,得到更具有区分性的语义特征。上述方法使语义特征与视觉特征更好地匹配,但是仍然存在枢纽点问题,影响分类的准确性。
此外,图卷积神经网络和知识图谱为基于语义空间嵌入的方法提供了新思路。Wang 等人[18]利用语义特征构建知识图谱,将每一条语义特征的嵌入都用一个节点表示,并根据对应关系进行连接,通过图卷积神经网络进行训练,得到不同类别的分类器。但是该方法中由于较远节点间关联程度较低,使用较多层图卷积神经网络不利于节点嵌入语义特征的分类。为此,Kampffmeyer 等人[19]提出了密集图传播模型(dense graph propagation,DGP),在2 层的图卷积神经网络中可以让较远节点直接相关联,通过加权的方式学习节点间距离的权重,提升了分类准确性;Liu 等人[20]提出了一种属性传播网络(attribute propagation network,APNet),利用嵌入的语义特征生成相关的知识图谱,然后利用KNN 最近邻方法进行预测。与文献[18]工作相比,DGP 和APNet 提升了模型在零样本图像分类中的性能,但是在图卷积神经网络的优化以及知识图谱的构建方面仍需要进一步改进,如在多层图卷积神经网络中保持较远节点的关联性和如何构建更全面的知识图谱等。
2.1.2 基于视觉空间嵌入的零样本图像分类
基于视觉空间嵌入的零样本图像分类方法将视觉空间作为嵌入空间,语义特征被映射到视觉空间中。
早期方法将图像的全局特征作为视觉特征,然后将不同形式的语义特征嵌入到视觉空间中,利用相似性度量完成分类。如Zhang 等人[21]设计了一种基于多模态融合的神经网络模型,将用户定义的属性和词向量等语义特征映射到视觉空间中,采用RNN(recurrent neural network)实现对语义表示的端到端学习。Sung 等人[22]提出一个双分支关系网络模型,采用MLP(multi-layer perceptron networks)网络将用户定义的属性(语义特征)嵌入到视觉空间中,然后将视觉特征和语义特征进行拼接后输入到关系网络中,通过比较图像视觉特征和语义特征的相似性得分来匹配不可见类图像的类别。虽然将图像全局特征作为视觉特征输入取得了一定的效果,但是图片中过多的复杂背景导致全局特征中存在太多的冗余和干扰,影响了图像分类性能。
为此,一些方法将图片中判别性区域特征作为视觉特征来提升零样本图像分类性能。Li 等人[23]提出了一种可自动发现判别性区域的零样本图像分类模型(latent discriminative features,LDF),将图像的全局特征和判别性区域特征进行联合学习,提升了零样本图像分类的准确率;Xie 等人[24]提出一种注意力区域嵌入网络模型(attentive region embedding network,AREN),在不经过检测或者注释的情况下利用注意力机制自动发现目标区域,使分类模型准确区分具有相似特征的类别(如山猫和豹子)。虽然LDF和AREN 考虑了判别性区域特征的重要性,但是判别性区域定位存在不准确的情况,且跨模态映射时在视觉空间进行语义匹配中存在语义一致性问题。
针对语义一致性问题,一些方法提出的模型能够更好地匹配语义特征。Li 等人[25]将视觉原型学习和稀疏图学习统一为一个过程,在学习视觉原型的同时,在视觉空间和语义空间之间保持语义一致性,以处理语义不一致问题。Wan 等人[26]提出一种视觉中心自适应(visual center adaptation method,VCAM)方法,在视觉空间中对目标类别进行结构对齐,从而让模型更好地匹配语义特征,大幅度缓解了语义一致性问题。Demirel 等人[27]将单词的表示形式转换为与视觉特征更具有关联性的语义特征,以端到端的方式学习与视觉特征更一致的词向量和标签嵌入模型,有效地将属性进行迁移。Huynh 等人[28]提出一种属性嵌入技术,首先使每个属性集中在最相关的图像区域,从而获得基于属性的视觉特征,然后将基于属性的视觉特征与其对应的语义向量对齐,最后训练分类器。
2.1.3 基于公共空间嵌入的零样本图像分类
基于公共空间嵌入的零样本图像分类方法将图像视觉特征和语义特征映射到同一公共空间。
早期方法,如Akata 等人[29]提出了一种联合嵌入模型SJE(structured joint embedding),使用多种辅助信息作为语义表示(如词向量等),通过公共空间嵌入的方式完成零样本图像分类任务。但是早期方法没有使用深度学习模型,性能较差。
随着深度学习的发展,许多工作将深度学习与基于公共空间嵌入的方法结合来提升分类性能。Wang 等人[30]提出一种基于多层感知器的方法,在公共空间中直接学习特征原型并优化特征结构,学习更具体的视觉特征;Min 等人[31]考虑到跨模态映射过程中的偏差问题,提出了一种特定的领域嵌入网络模型(domain-specific embedding network,DSEN),考虑了语义一致性的问题,防止嵌入空间中语义关系被破坏。但是以上方法在嵌入空间中将视觉特征和语义特征相关联的方式较为单一,且没有考虑图像中判别性区域特征的影响。
此外,还有一些基于公共空间嵌入方法的研究,Liu 等人[32]提出了一种标签激活框架(label activating framework,LAF),将原始标签空间作为公共空间,将不可见类的标签看作可见类标签的线性组合,此时可见类和不可见类的标签在公共空间中定义且原始标签具有特定的含义,经过训练后能达到更好的分类效果。Zhang 等人[33]提出了一个双分支网络将图像的语义描述和视觉表示映射到一个公共空间中,并通过回归项最小化视觉样本的嵌入和其对应类级语义描述之间的绝对距离,利用辅助分类器来区分所嵌入语义信息的交叉类别。
基于空间嵌入的方法从2012 年沿用至今,是一种很有竞争力的零样本图像分类方法,随着卷积神经网络、残差网络[1]、密集网络[2]等神经网络的提出,基于空间嵌入的零样本图像分类性能将可以进一步得到提升。但是,由于可见类和不可见类之间的训练样本数量极度不平衡,现有的大多数方法仍存在很大的局限性。
2.2 基于生成模型的零样本图像分类方法
基于空间嵌入的零样本图像分类依赖于图像特征空间和类嵌入空间之间的交叉模态映射,泛化能力较差。生成模型的出现为这一问题提供了新的解决思路,基于生成模型的零样本图像分类方法利用生成模型直接生成不可见类的特征,将零样本图像分类转化为传统的基于监督学习的图像分类问题。目前用于零样本图像分类的主要生成模型包括生成对抗网络GAN、变分自编码器VAE 和基于流的生成模型FLOW。
2.2.1 基于GAN 的零样本图像分类
近年,生成式对抗网络(GAN)[34]的提出为解决可见类和不可见类之间的训练样本数量不平衡问题提供了新思路。GAN 包括判别器和生成器两部分,生成器利用随机噪声生成伪样本,判别器对生成的样本进行判别,最后生成新的样本来满足对不可见类样本的需要。
Xian 等人[35]将WGAN(Wasserstein GAN)[36]与一个分类损失配对,生成鉴别性不可见类视觉特征来训练Softmax 分类器,并综合了基于类级语义信息的CNN(convolutional neural networks)特征,提供了从类的语义描述直接到类条件特征分布的快捷方式。Sariyildiz 等人[37]为了用WGAN 学习生成更好的数据训练,提出梯度匹配网络(gradient matching network,GMN),利用梯度匹配损失作为分类损失的代理,引导生成器最小化综合实例驱动的分类模型的分类损失。然而,以上基于GAN 的方法不能保证生成样本的质量,影响了零样本图像分类的性能。
因此,为了保证生成样本的质量,一些工作对Xian 等人[35]和Sariyildiz 等人[37]所提方法进行了改进。Verma 等人[38]利用WGAN,提出了一种基于类属性条件设置的元学习方法ZSML(zero-shot metalearning),将生成器模块和带有分类器的判别器模块分别同元学习代理相关联,利用少量可见类样本的输入即可训练模型;Ma 等人[39]提出一种相似度保持损失,使GAN 的生成器减小生成样本与真实样本之间的距离,利用相似度消除异常的生成样本;Liu 等人[40]提出了一种双流生成式对抗网络合成具有语义一致性和明显类间差异的视觉样本,同时保留用于零样本学习的类内多样性。
除此之外,Felix 等人[41]将多模态循环一致约束添加到视觉特征生成的过程,重建原始语义特征,利用多模态循环一致的语义兼容性进行训练,生成更具有代表性的视觉特征。Li 等人[42]发现将GAN 用于零样本图像分类时,生成的不可见类视觉特征容易与可见类特征混淆,因此提出了一种环节特征混淆的生成式对抗网络AFC-GAN(alleviating feature confusion GAN),并提出特征混淆分数来评估特征混淆,生成更具有区分性特征。
基于GAN 的零样本图像分类方法在短短两年间飞速发展,但是GAN 本身存在生成特征不稳定问题,训练批次的不同也会影响特征生成效果。另外,学习训练过程中会出现模式崩塌[43]。
2.2.2 基于VAE 的零样本图像分类
相比于基于GAN 的零样本图像分类,基于变分自编码器(VAE)[44]的方法可以克服不稳定和模式崩塌等问题。变分自编码器为每个样本构造对应的正态分布,然后采样变量并进行重构,其结构图如图6所示。
2018 年,Mishra 等人[45]训练一个条件变分自编码器(conditional variational autoencoders for ZSL,CVAEZSL)来学习基于类嵌入向量的所对应图像特征的潜在概率分布,生成更稳定的视觉特征。Schonfeld 等人[46]通过VAE 编码和解码不同模式的特征,匹配参数化分布和强制跨模态重建标准来学习多个数据模式的共享的跨模态潜在表示,并使用学习到的潜在特征训练零样本图像分类器。虽然变分自编码器进行编码和解码操作后生成的特征较为稳定,但是很难生成高质量的特征。

Fig.6 Framework of VAE model图6 VAE 模型框图
为了提高生成视觉特征的质量,许多改进方法[45-47]被提出。Gao 等人[47]提出了一种结合变分自编码器和生成式对抗网络的联合生成模型用于生成高质量的不可见类特征,利用自训练策略并引入一个对抗性分类网络增强类级区分能力;Zhang 等人[48]提出了一种跨层自动编码器(cross-layer autoencoder,CLAE),利用不同的语义映射方式确保重建信息的准确性,并利用正则损失函数保留类别的局部流形,增加了特征生成效果;Yu 等人[49]使用多模态变分自编码器(multi-modal VAE,MMVAE),并利用期望最大化的方法,使模型生成不可见类特征的同时学习该特征,模型根据每一轮迭代生成的新特征进行网络权重的更新,并且编码器可以直接作用于分类,无需其他分类器。
VAE 给出的是生成样本概率的下界,虽然以上方法[45-47]一定程度上提高了生成特征质量,但是距生成高质量特征仍有一定差距。
2.2.3 基于FLOW 的零样本图像分类
研究发现[46,50],零样本图像分类的训练过程中仅涉及可见类样本,生成模型所生成的不可见类样本有时具有与可见类相同的分布。为了生成高质量视觉特征,基于FLOW 的零样本图像分类方法被提出。FLOW 模型框图如图7 所示。
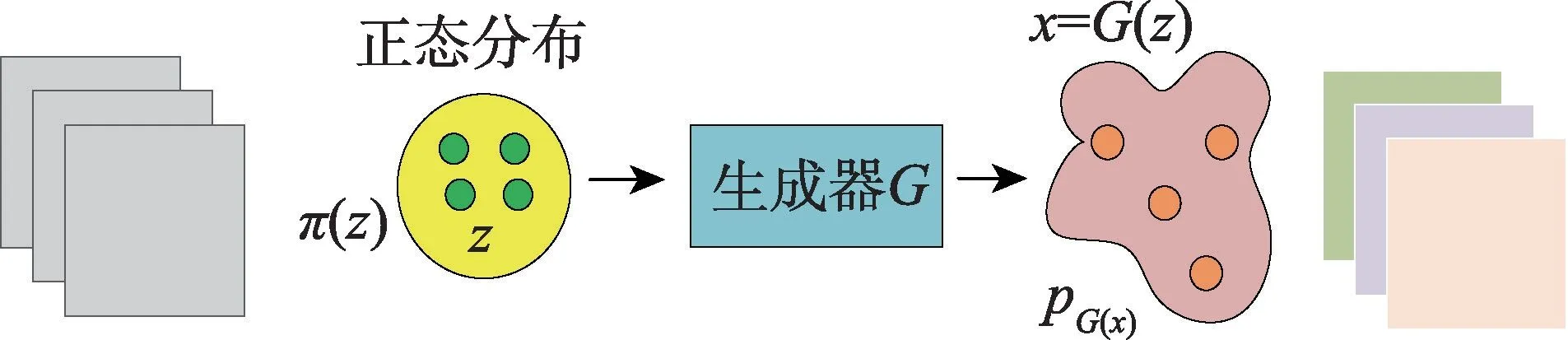
Fig.7 Framework of FLOW model图7 FLOW 模型框图
2020 年,受可逆神经网络(invertible neural networks,INNs)[51]的启发,Shen 等人[52]提出了一种基于流的生成模型IZF(invertible zero-shot flow)进行零样本图像分类,采用相同的参数集和内置网络进行编码(正向传递)和解码(反向传递)。
Gu 等人[53]将VAE 与FLOW 相结合,提出VAE 条件生成流模型(VAE-conditioned generative flow,VAEcFlow),利用VAE 将语义描述编码为可处理的潜在分布,然后利用FLOW 优化所观察到的视觉特征的精确对数似然性,更好地实现了零样本图像分类。基于FLOW 的生成模型直接给出了生成样本概率,使得零样本图像分类取得了很好的性能。但是,基于FLOW 的生成模型计算量大,消耗资源多。
表1 给出了现有零样本图像分类不同方法的比较,包括机制、优点、缺点及应用场景等。
3 性能评估
3.1 数据集介绍
零样本图像分类中常用以下5个数据集:AwA1[8]、AwA2[52]、CUB[54]、SUN[55-56]和aPY[57]。其中CUB 和SUN两个数据集为细粒度数据集,其余3 个数据集为粗粒度数据集,如表2 所示。
数据集AwA1[8]和AwA2[52](animal with attribute1 and 2)分别包含了50 类30 745 张和37 322 张动物图片,其中40 类作为训练类别,10 类作为测试类别,使用85 维的语义属性特征。
数据集CUB(Caltech-UCSD-Birds-200-2011)[54]为鸟类图片的细粒度数据集,包含了200 种鸟类共计11 788 张图片,其中150 类作为训练类别,50 类作为测试类别,使用312 维的语义特征。
数据集SUN(SUN Attribute Dataset)[54-55]涵盖了各种环境场景和内部图像的细粒度数据集,包含了717 类共计14 340 张图片,其中645 类作为训练类别,72 类作为测试类别,使用102 维语义特征。

Table 1 Comparison of different types of zero-shot image classification表1 不同类型零样本图像分类方法比较

Table 2 Datasets for zero-shot image classification表2 零样本图像分类中常用数据集
数据集aPY(aPascal-aYahoo)[57]包含两部分:一部分由PASCAL VOC 2008 数据集中20 个类别12 695张图片组成,作为训练类别;另一部分则包含了Yahoo搜索引擎提供的12 个类别共计2 644 张图片,作为测试类别,使用64 维语义特征。
3.2 评价方法
在零样本图像分类中,采用每个类别top-1 精度的均值作为评价标准,其公式表示为:

其中,Y表示类别标签,||Y||表示类别总数。
对于广义零样本图像分类:给定样本特征x∈Xs⋃Xu,其中Xs为可见类样本特征,Xu为测试集中不可见类样本特征,且标签空间应包含已知类和未知类的全部测试标签,即Ys⋃Yu。在广义零样本图像分类中采用调和平均率(harmonic mean)作为评价标准,公式表示为:

其中,Accys和Accyu分别表示测试过程中已知类和未知类的平均top-1 准确率(为了方便书写,分别用S和U表示),H表示两者的调和平均率。
3.3 零样本图像分类方法性能比较
本文选取了几个经典零样本学习模型和现有最新模型分别在零样本图像分类和广义零样本图像分类设置下在4 个数据集(AwA1、AwA2、CUB 和SUN)上进行了比较。模型包括早期零样本图像分类模型DAP(direct attribute prediction)[8]、基于空间嵌入的模型CMT(cross-modal transfer)[14]、SSE(semantic similarity embedding)[58]、ESZSL(embarrassingly simple zeroshot learning)[59]、SAE(semantic auto encoder)[60]、ALE(attribute label embedding)[61]、RN(relation network)[22]和视觉特征生成模型f-CLSWGAN[35]、LisGAN(leveraging invariant side GAN)[62]、DLFZRL(discriminative latent features for zero-shot learning)[63]和IZF(invertible zero-shot flow)[52]。数据均来源于算法所对应公开发表文章或其他公开文章复现的结果,如表3(零样本图像分类)和表4(广义零样本图像分类)所示。

Table 3 Performance comparison of zero-shot image classification(Accy)表3 零样本图像分类性能比较(Accy)%
由表3 可以看出,在零样本图像分类设置下:(1)相比于早期模型,基于空间嵌入和生成模型的方法取得了更好的效果;(2)基于空间嵌入的方法在零样本图像分类任务中具有竞争力,部分模型所获得的结果相对接近于视觉生成模型;(3)相比较于CUB和SUN 两个细粒度数据集,表3 中的方法在AwA1 和AwA2 两个粗粒度数据集上的性能更加突出。
由表4 可以看出,在广义零样本图像分类设置下:(1)大多数零样本图像分类方法在广义零样本学习设置下得到的结果次于零样本图像分类结果,说明零样本图像分类设置具有一定的局限性;(2)基于空间嵌入的模型的性能明显偏向于可见类的识别,对不可见类的识别效果较差。基于生成模型的方法优于基于空间嵌入的方法,可以更为准确地识别不可见类,调和平均率提高效果非常明显。特别的,基于FLOW 的IZF 模型[52]相比较于其他生成模型达到了更好的性能。
综合表3 和表4 可以看出,由于广义零样本学习设置更符合现实生活需求,广义零样本图像分类方法将会得到更多的研究。同时,基于生成模型方法更适用于零样本图像分类任务。
4 存在问题及解决方法
尽管零样本图像分类得到了广泛研究,但是现有方法中仍然存在领域漂移问题、枢纽点问题和语义鸿沟问题等。下面对这三个问题进行分析并给出一定的解决思路。
(1)领域漂移问题(domain shift problem)。由于零样本学习方法在训练时不能学习不可见类的标签,当训练集类别与测试集类别差异很大时,例如训练集都是鸟类,而测试集全是交通工具,利用鸟类的特征训练出来的模型很难正确识别交通工具,此时零样本图像分类效果会很不理想。为此,Kodirov 等人[60]提出了SAE 模型,在视觉特征向语义特征映射的过程中添加了约束条件,可以保证在映射时保留视觉特征中所包含的信息,很好地缓解了领域漂移问题。

Table 4 Performance comparison of generalized zero-shot image classification表4 广义零样本图像分类性能比较%
(2)枢纽点问题(hubness problem)。在高维空间中,某些点会成为大多数点的最邻近点,零样本图像分类方法通过KNN 算法进行分类时,枢纽点问题会影响最终的分类结果。基于生成模型(VAE、GAN 和FLOW)的方法将零样本图像分类问题转换成监督学习问题,为解决枢纽点问题提供了新思路。
(3)语义鸿沟问题(semantic gap)。样本的视觉表示往往采用卷积神经网络所提取的视觉特征,语义特征的表示与视觉特征表示不同,在视觉-语义特征进行映射的时候由于图像在视觉空间所构成的流形和语义特征在语义空间的流形不一致导致学习过程有困难。公共空间嵌入的方式缓解语义鸿沟问题,该方式也成为缓解语义鸿沟的主要方法。
5 发展趋势和研究热点
本文对现有零样本图像分类方法进行了详细介绍,下面对未来零样本图像分类的发展趋势和研究热点进行探讨,主要包括以下三方面。
(1)定位更准确的判别性区域,提取更具有区分性的特征。利用注意力机制等定位更准确的判别性区域,提取更具有区分性的特征,从而使模型能够更好地学习视觉特征与语义特征之间的关系,提升零样本图像分类准确率。
(2)利用新的生成模型生成高质量的不可见类视觉特征。基于FLOW 的方法进行零样本图像分类具有巨大的发展潜力;另外,Zhu 等人[64]提出一种新的生成模型,用于学习从类级语义特征以及遵循高斯噪声分布的实例级潜在因素到视觉特征的映射;Yu 等人[65]提出一种原型生成网络用于合成基于语义原型的类级视觉原型,并提出多模态交叉熵损失用于捕获判别性信息。
(3)广义零样本图像分类。零样本图像分类设置下,测试集不包含训练集,这是一个十分理想的状态,在现实生活中并不会存在这种情况。因此,测试集包含训练集的广义零样本图像分类,更贴近于现实,成为未来最有意义的研究热点。
6 结束语
本文对零样本图像分类进行了综述,详细介绍了现有的零样本图像分类方法,并对典型方法进行了性能比较,对零样本学习、常用数据库、评估方法等进行了介绍,同时对零样本图像分类存在问题、未来发展趋势和研究热点进行了分析。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
少儿画王(3-6岁)(2020年4期)2020-09-13
领导决策信息(2018年16期)2018-09-27
东方教育(2018年20期)2018-08-22
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
长江学术(2015年1期)2015-02-27
西南学林(2011年0期)2011-11-12
微型计算机(2009年4期)2009-12-23
