
融合注意力机制的恶意代码家族分类研究
2021-05-14 03:42王润正杨梦岐
计算机与生活 2021年5期
王润正,高 见,2+,仝 鑫,杨梦岐
1.中国人民公安大学信息网络安全学院,北京100038
2.安全防范与风险评估公安部重点实验室,北京102623
目前,随着黑客技术以及隐蔽技术的多样化和复杂化,网络安全状况愈加严峻。恶意软件安全威胁呈指数级增长,各类新型病毒层出不穷,反检测技术不断更新。在各类恶意软件中,攻击性广告软件、特洛伊木马和黑客工具位居首位,勒索病毒打击事件高频发生,各行各业遭到不同程度的恶意攻击,其中传统企业、教育、医疗、政府机构遭受攻击最为严重,因此加强安全防护,抵御病毒攻击刻不容缓。
在恶意代码家族分类研究中,研究人员往往从静态或者动态的角度对恶意样本进行有效的特征提取,本文对各类恶意样本进行静态分析,深度剖析PE(portable executable)文件的结构组成,将二进制文件进行区段划分,研究不同区段的特征对恶意代码家族分类的影响,同时在改进传统的神经网络模型基础上,融合注意力机制来识别恶意代码家族。
1 相关工作
恶意代码特征提取方法主要分为静态方法和动态方法。研究人员采用静态分析的方法,在不运行恶意样本的情况下,使用逆向工具获取二进制数据、操作码、函数调用等静态信息,进而构建静态特征序列;采用动态分析的方法,在真机或者沙箱中运行恶意样本,一定程度上可以抵御加壳或者混淆等对抗技术,获取样本的API(application programming interface)、流量等动态信息。Jeon等人[1]提取恶意软件的操作码序列,使用操作码级卷积自动编码器将长操作码序列转换为较短的压缩序列,使用动态递归神经网络检测恶意软件。Kakisim 等人[2]提出了一种基于高级引擎签名的变种恶意软件识别方法,为每个变种恶意样本构造co-opcode 图,从图中提取引擎特定的操作码模式,然后用二进制矢量表示提取的操作码模式来生成属于每个家族的高级签名。Zhang 等人[3]通过二元模型来表示操作码,并通过频率向量来表示API调用,使用卷积神经网络和BP(back propagation)神经网络检测恶意代码。Lu 等人[4]提出了一种新的深度学习和机器学习相结合的模型,在功能级别上分析了API 调用序列中的依赖关系,使用随机森林(random forest,RF)算法进行分类,同时采用双向残差神经网络研究API 序列并通过冗余信息预处理发现恶意软件。Amer等人[5]对恶意软件API调用序列建模,生成语义转换矩阵描述API 函数之间的关系,使用马尔可夫链对恶意软件进行检测和预测。Huang等人[6]提取恶意样本的动态API 序列,使用最长频繁序列挖掘算法挖掘多个类别的最长频繁序列集合,从而根据词袋模型将API 序列转化为向量,使用随机森林算法检测恶意代码。Zheng 等人[7]对恶意软件的前后API 调用概率关系进行了建模,并通过随机插入API 序列的方式构造模拟对抗样本来测试原始参数模型的分类性能,使用双向LSTM(long short-term memory)对恶意软件家族分类。Zhao 等人[8]在基于真机的沙箱中提取恶意代码的API 序列,根据渐近均分性提取语义信息丰富的API,以构建API 依赖图,利用平均对数分支因子和直方图bin 方法来构建特征空间,采用集成学习算法-随机森林进行恶意代码分类。Zhang 等人[9]在沙盒环境下运行恶意软件获取其动态调用序列,并通过滑动窗口划分得到窗口子序列,引入多示例学习和注意力机制来构建层次化特征抽取的深度神经网络,使用循环神经网络抽取API 特征,结合两个注意力机制分别抽取窗口特征和序列特征,并使用序列特征检测恶意软件。静态分析和动态分析相互结合、相互补充,共同对抗恶意代码的规避和反调试技术。
为区别传统的特征提取方法,减少特征工程的复杂度,研究人员将恶意样本进行可视化,在静态或动态分析的基础上,采用图像的方法对恶意代码进行研究。Nataraj 等人[10]首次提出将恶意样本的二进制文件转换成灰度图的方法,利用图像纹理的相似性对恶意软件进行分类。Vasan 等人[11]将原始恶意软件二进制文件转换为彩色图像,通过微调后的神经网络模型对恶意软件进行检测和识别。Fu 等人[12]将恶意软件可视化为RGB彩色图像,并从图像中提取全局特征,并选择灰度共生矩阵(gray-level co-occurrence matrix,GLCM)和颜色矩分别描述全局纹理特征和颜色特征,产生低维特征数据以减少训练模型的复杂性。同时从恶意软件的代码部分和数据部分中提取了一系列特殊字节序列,并由Simhash 作为局部特征将其处理为特征向量。最后合并全局特征和局部特征,以使用随机森林、K最邻近分类算法(K-nearest neighbor,KNN)和支持向量机(support vector machine,SVM)对恶意软件进行分类。Yakura等人[13]将二进制数据转换为图像,利用带有注意力机制的卷积神经网络计算注意力图,根据区域的重要性从二进制数据中提取恶意家族特有的特征字节序列,以便手动分析恶意软件样本。Lu 等人[14]将恶意代码映射为灰度图,将灰度图转为固定大小后,采用方向梯度直方图提取灰度图的特征,使用深度森林对恶意代码分类。Xiao 等人[15]提出了一种基于恶意软件可视化和自动特征提取的有效恶意软件分类框架(MalFCS),将恶意样本可视化为熵图,采用深度神经网络作为特征提取器,自动从熵图中提取共有的特征,最后使用支持向量机分类器对恶意软件进行分类。Yuan 等人[16]根据字节传输概率矩阵将恶意软件二进制文件转换为Markov 图像,然后将深度卷积神经网络用于马尔可夫图像分类。上述研究说明可视化技术对恶意代码分析具有可行性,能够有效地对恶意代码家族及其变种进行检测与分类。
随着恶意代码形态的多样化,针对传统的静态或者动态检测方法的对抗技术不断发展,加大了特征提取的难度,同时基于动态特征提取方法耗费资源较多,不利于对大批量样本的检测。为缓解上述问题,本文借鉴可视化思想,兼顾二进制程序静态文件结构,提出一种基于区段特征融合的可视化方法,相比于动态分析,该方法具有快速、资源消耗少的特点,可以在一定程度上规避恶意代码的混淆、反调试等对抗手段,使特征更具鲁棒性。
2 恶意代码家族分类模型
在恶意代码家族分类研究中,恶意代码以其功能行为特征划分家族类别。同类恶意代码家族普遍存在代码复用的现象,其二进制可执行文件在可视化中存在相似的纹理特征,但不同的恶意家族往往执行不同的恶意行为,组成不同恶意行为的操作码可视化所形成的纹理特征不同。在恶意代码家族数据预处理中,将恶意样本可视化后,为了有效地表征各恶意家族的特征,研究人员采用灰度共生矩阵、通用搜索树(generalized search trees,GIST)、局部二值模式(local binary patterns,LBP)、尺度不变特征变换(scale-invariant feature transform,SIFT)、颜色矩等方法提取全局或者局部的图像纹理特征,进而将产生低维度的特征数据输入分类检测模型。本文采取深度学习的方法使模型自主学习图像中的纹理特征信息,减少人工提取纹理特征的复杂度。在恶意代码家族分类判定过程中,传统的神经网络模型无法关注特征中的关键信息,为了更加有效地区分不同恶意代码家族形成不同的纹理特征,本文在恶意代码家族分类模型中采用深度可分离卷积[17]提取特征信息的基础上,引入由通道域和空间域注意力组成混合域注意力机制来模拟人对重要信息的关注,使神经网络通过训练自主学习特征图的权重分布,从不同的维度提取区段中的关键信息,从而使模型深度挖掘出显著的纹理特征,忽略无关的特征信息,提高模型的分类准确率。同时,注意力机制在提升神经网络分类效果的过程中,增加的参数量和计算量相对较少,与轻量化网络结合,保证了模型的分类效率。
融合注意力机制的恶意代码家族分类模型结构如图1 所示,主要分为数据预处理模块和基于混合域注意力机制的深度可分离卷积网络模型(depthwise separable convolution model with attention mechanism,DSCAM)。其中,DSCAM 包括深度可分离卷积模块(separableconv block)和混合域注意力模块(attention block)。模型采用深度可分离卷积模块从通道和空间维度上学习恶意样本的纹理特征;混合域注意力模块提取全局和局部的核心特征,进行特征细化;使用残差连接每个子模块,加速模型收敛,提升模型的判别能力。与传统的神经网络相比,该网络将通道和空间分离,更加关注于特征图的权重信息,有利于区分恶意家族间的差异性,便于对恶意家族进行同源性分析。
2.1 数据预处理

Fig.1 Malicious family classification model图1 恶意代码家族分类模型
目前,恶意代码家族陆续产生一些变种,致使同类恶意代码家族间存在差异性,降低分类模型的准确率。由于同类恶意代码家族所执行的恶意功能相同或者相似,PE 头、代码、数据等片段可能存在相似性。PE 头中包含着恶意样本执行时的相关信息。PE节区中包含着组成恶意程序的汇编代码、源代码中声明的全局变量以及程序加载的图片、文档等资源,其中“.text”包含可执行的代码段,“.data”包含程序的全局变量和静态变量,“.idata”通常存储导入函数信息,“.edata”通常存储导出函数信息,“.rdata”包含程序中全局可访问的只读数据,“.rsrc”存储可执行程序所需要的资源等。恶意代码的特征信息存在于各区段中,不同恶意代码家族在不同区段所执行的恶意功能存在差异,具有不同的特征码,因此对各区段分析可以有效地帮助分类模型对各恶意代码家族作出准确的判断。
PE 文件各部分所在位置与其数据结构位置顺序一致,程序加载到内存中时,大部分位置保持不变,而内存状态不同时,各节区加载的顺序往往不同。为了方便提取各区段的数据,本文使用Python 结合IDApython 插件自动提取恶意样本的区段特征。通过IDA Pro 对恶意样本进行反汇编,使用SegName()函数获取各段名称,调用SegStart()和SegEnd()函数来获取段的开始到结束范围,使用Segments()函数对整个数据进行遍历,以获取所有的区段信息,最后提取各区段的字节码作为特征信息。同时使用PeFile提取PE header 中的DOS_HEADER、NT_HEADER、FILE_HEADER、OPTIONAL_HEADER 等字段作为恶意代码家族补充特征。
在恶意代码家族分类任务中,本文将静态提取的特征可视化后,使用图像特征对恶意样本进行分类。在传统的恶意代码可视化方法中,因恶意样本的大小不一,相关研究人员将生成的图像采用缩放、裁剪等图像处理方法以适应深度学习模型的输入,这会导致一些重要的信息丢失,如在一些恶意代码家族中,“.data”“.rsrc”段中会存有部分恶意代码伪装特征,因此无法进行有效的检测分类。对恶意样本进行灰度图转化过程中,不会有效区分样本的代码段和数据段特征,数据段中的某些相似特征可能被识别为代码段中关键的特征码,从而导致某些恶意样本无法进行正确的分类。针对上述情况,本文将代码段和数据段分离,再进行可视化,分别研究其对分类模型的影响,同时将各区段分成三部分,对特征进行融合,按照R、G、B 三个通道转化为彩色图,如图2 所示。

Fig.2 Visualization method图2 可视化方法
本文研究对象为Windows PE 文件,样本均来源于VirusShare,因为样本库存在各类平台的文件,所以本文根据PE 文件结构对样本库进行筛选,选取满足条件的恶意样本进行处理,并对加壳样本进行脱壳处理,进而提取各区段特征,按照可视化规则读取各区段数据,生成RGB 彩色图像。图3 所示依次为DownloadGuide、Emotet、Softcnapp、Zbot 家族的可视化图像。可以看出,不同的恶意代码家族的纹理特征不同,不同恶意样本恶意信息存在不同的区段,其中,图(a)、(b)大量信息存在于代码段,图(c)存在红色条纹,经过溯源发现该恶意样本存在“.giats”“.tls”“.gfids”段,图(d)大量信息存在于数据段。由此可见,对于恶意代码家族分类需要对各区段进行全面分析,各区段特征在一定程度上可以表现出各类恶意代码家族的差异性,该方法能够提升分类效果。

Fig.3 Malicious sample图3 恶意样本
2.2 深度可分离卷积
在卷积神经网络中,卷积是一种局部操作,通过一定大小的卷积核作用于局部图像区域获取图像的局部信息。本文恶意代码家族分类模型采用深度可分离卷积代替标准卷积操作,在减少模型参数量的同时,实现了通道与空间的分离。深度可分离卷积[18](depthwise separable convolution)可将卷积核分成两个单独的卷积核,这两个卷积核进行两个卷积:深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。
恶意样本可视化后经过神经网络产生的特征图(feature map)尺寸为(DF,DF,M),采用标准的卷积K为(DK,DK,M,N)。经卷积操作后,计算公式如式(1)所示,输出的特征图G大小为(DG,DG,N)。其中,M为输入的通道数,N为输出的通道数。

将标准卷积分成深度卷积和逐点卷积。深度卷积的一个卷积核只有一个通道,尺寸为(DK,DK,1,M),输出尺寸为(DG,DG,M);逐点卷积对上一特征图在深度方向上进行加权组合,尺寸为(1,1,M,N),输出尺寸为(DG,DG,N)。相比于标准卷积,深度可分离卷积计算量减少了Δ,计算如式(2)所示。

本文恶意代码家族分类模型深度可分离卷积模块结构组成如图4 所示。每一个模块中包含两个深度可分离卷积层,一个最大池化层,最后通过shortcut进行残差连接。每个深度可分离卷积层先进行3×3的深度卷积,再进行1×1 的逐点卷积,卷积后经过BN(batch normalization)层,最后使用ReLU 进行非线性激活。

Fig.4 SeparableConv Block图4 深度可分离卷积模块
2.3 混合域注意力机制
在计算机视觉中,注意力机制应用于视觉信息的处理,其基本思想是使得神经网络具备专注于输入特征的某些局部信息的能力,能够忽略无关信息而更多地关注重点信息。以注意力关注的域可以分为通道域、空间域、层域、混合域和时间域注意力机制,从不同的维度学习特征图的权重分布,提升神经网络的分类性能。
通道域注意力机制解决恶意代码家族关键纹理特征“是什么”的问题,空间域注意力机制解决核心纹理特征“在哪里”的问题。其中单一注意力机制不足以完全表征关键特征,如忽视空间域注意力,对于特征定位会产生影响,从而忽略局部纹理信息。因此,为提升恶意代码家族关键区域的特征表达,本文采用混合域注意力机制,即同时引入通道域和空间域注意力机制,从通道和空间两个维度提取更关键、重要的深层特征,两者结合进一步增强特征表示,使恶意代码家族分类模型关注于重要的区域,做出更准确的判断。
2.3.1 通道域注意力机制
通道域注意力机制使神经网络模型通过训练获取每个特征通道的重要程度,以使模型更加关注权重高的通道并抑制权重低的通道。在恶意代码分类模型中引入通道域注意力机制[19],提高分类模型对全局纹理特征的提取能力,如图5 所示。
首先,将各类恶意样本的H×W×C三维特征图x,分别输入全局平均池化和最大池化层,从不同的角度提取特征信息,得到两个1×1×C的特征信息。其次,将特征信息输入一个多层感知机MLP 中,经过两层神经网络,得到两个1×1×C的通道特征图,计算公式如式(3)所示,其中σ为Sigmoid 激活函数,W0和W1为多层感知机的两层参数。最后,将得到的两个特征相加后经过Sigmod 激活函数得到相应的权重,再与原特征进行相乘得到新特征。

2.3.2 空间域注意力机制
空间域注意力机制使神经网络模型通过训练获取特征图不同位置的重要程度,以使模型更加关注于关键的局部特征。本文恶意代码家族分类模型在通道域注意力机制的基础上,加入空间域注意力机制[19],从空间维度提取特征,提高分类模型对局部纹理特征的提取能力,如图6 所示。
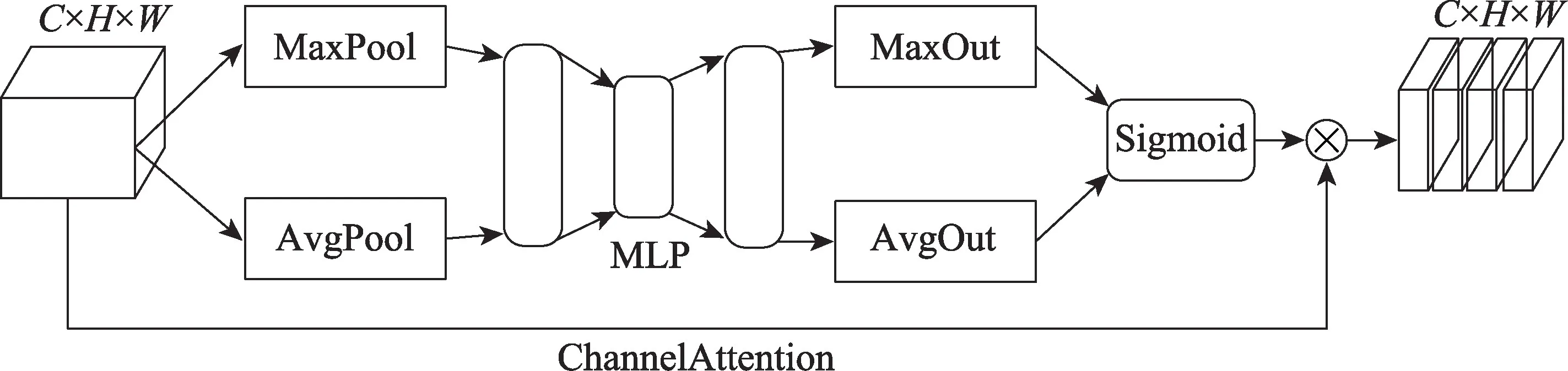
Fig.5 Channel attention图5 通道域注意力

Fig.6 Spatial attention图6 空间域注意力
将H×W×C三维特征图分别输入最大池化和平均池化层,得到两个H×W×1的特征信息,并将这两种特征信息拼接在一起,经过卷积操作后,通过Sigmod激活函数得到相应的权重,再与原特征进行相乘得到新特征,计算公式如式(4)所示。

3 实验结果与分析
3.1 数据集
为了有效地评估本文方法,实验采用VirusShare.com 公开的恶意样本数据集,样本选取的时间范围以2019 年和2020 年为主。恶意代码变种及混淆对抗手段不断加强,单一检测引擎难以对各类恶意家族进行准确的标注。为了合理地取得恶意样本的标签数据,本文借助AVclass[20]对恶意样本进行标定,标注方法为对VirusTotal.com 报告的各检测引擎的家族标签数据进行综合考虑,并且根据统计结果对恶意样本进行标签化。最终,选取了6 464 个样本作为实验数据集。数据集中各类恶意代码家族分布情况如表1所示。
3.2 评价指标
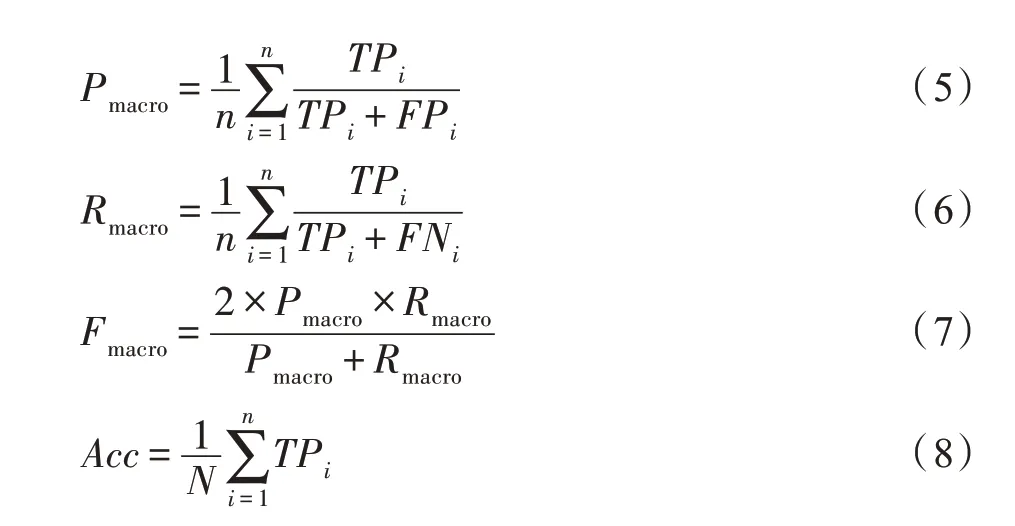
本文对各类恶意代码家族进行衡量的指标为:TP,将正类预测为正类的样本数;FN,将正类预测为负类的样本数;FP,将负类预测为正类的样本数;TN,将负类预测为负类的样本数。由于恶意代码家族分类属于多分类问题,为了更好地衡量模型对恶意代码家族分类的效果,对每一类恶意代码家族的精确率(Precision)、召回率(Recall)、F1 值(F1-score)、准确率(Accuracy),取其算数平均值作为最后模型性能衡量的标准。四个评价指标的计算公式如下,其中,N为总样本数。

Table 1 Dataset distribution表1 数据集分布情况
3.3 注意力机制分析
不同的注意力机制对模型会产生不同的效果,为了使恶意代码家族分类模型取得更好的分类效果,研究不同注意力模块以及注意力模块的位置对模型分类的影响,实验中设计了四种注意力模块,如图7 所示。
(1)SeparableConv Block。本模块为原始模型,不采用任何注意力机制,输入经过两个深度可分离卷积后直接进行最大池化层。如图4 所示。
(2)ChannelAttention Block。本模块在深度可分离卷积和最大池化层间加入通道域注意力机制,通过通道域注意力机制学习不同通道间的权重。如图7(a)所示。

Fig.7 Block structure图7 模块结构
(3)SpatialAttention Block。本模块在深度可分离卷积和最大池化层间加入空间域注意力机制,通过空间域注意力机制学习局部关键特征。如图7(b)所示。
(4)SplitAttention Block。本模块将深度可分离卷积后的特征图分别经过通道域和空间域注意力机制,再将各注意力机制的输出进行相加,形成新的特征图,输入最大池化层。如图7(c)所示。
(5)CSAttention Block。本模块将深度可分离卷积后的特征图经过混合域注意力机制,即先经过通道域注意力机制再经过空间域注意力机制,原特征图经过这两次注意力机制处理后,输入最大池化层。如图7(d)所示。
本文将各类恶意代码家族样本进行数据预处理后按照8∶2 的比例随机分为训练集和测试集。实验使用PyTorch 的transforms 方法对图像进行预处理,将图像统一进行标准化、归一化处理后,分别使用实验数据集对上述模块进行训练和测试。经训练后,五种模型对各类恶意代码家族分类准确率如图8 所示。
各模块组成的模型的准确率和参数量如表2所示。
经过实验发现,注意力机制模块提升了原始模型的分类效果,不同的注意力机制以及注意力机制的位置对模型具有一定的影响。其中,单一注意力机制忽视了某些关键特征,将通道域和空间域叠加组合能够获取更多有效的特征表达,使模型对各类恶意家族具有更好的识别率。因此,本文选取混合域注意力机制模块对原始模型进行加强,从而构建基于混合域注意力机制的深度可分离卷积网络模型,模型具体网络结构如表3 所示。

Fig.8 Accuracy of malicious family图8 各类恶意家族分类准确率

Table 2 Model accuracy and number of parameters表2 模型准确率和参数量
3.4 对比实验结果与分析
3.4.1 不同区段特征对比
由于PE 文件的段名之间存在差异性,本文选用IDA PRO 反汇编工具对样本进行区段提取,其中,“.text”统称为代码段,“.data”“.rdata”“.idata”“.edata”统称为数据段。实验中将恶意样本进行区段划分,对各区段进行可视化,从而研究数据段、代码段以及各区段融合特征对恶意代码家族分类的影响。三组不同区段特征下各类恶意代码家族的准确率、精确率、召回率和F1 值如图9 所示。

Table 3 Network structure表3 网络结构

Fig.9 Features contrast of different sections图9 不同区段特征对比
由图9 可知,融合特征能够有效区分各类恶意代码家族,其准确率、精确率、召回率和F1 值均高于代码段特征和数据段特征,其中,融合特征对Ursnif、Zbot 家族识别效果更好,对于这些恶意家族,单一区段特征不能完全描述此类恶意家族的全部特征信息,不能进行准确的检测与分类。经测试,代码段和数据段均会影响模型对各恶意家族的同源判定,恶意样本不仅在代码段中描述其恶意功能,而且在数据段中存有相关恶意数据,部分恶意家族的PE 头信息以及其他区段也存在一定的恶意信息。因此,对于恶意代码家族多分类问题,要综合考虑各区段特征,基于区段特征融合的可视化方法可以在一定程度上解决因传统可视化方法导致的恶意家族数据缺失、文件结构破坏等问题。
3.4.2 不同模型对比
为进一步验证模型的准确率和泛化能力,选取恶意代码家族分类研究中常使用的机器学习和深度学习模型进行对比分析,如KNN、SVM、RF、VGG16、InceptionV2、ResNet50、MobileNetV2。八种分类模型在测试集上进行对比实验,各类恶意代码家族分类准确率如图10 所示。采用模型准确率、宏召回率、宏精确率和宏F1-score 作为模型性能评价的指标,模型的对比实验结果如表4 所示。

Fig.10 Accuracy of malicious family图10 各类恶意家族分类准确率
实验结果表明,机器学习和深度学习相关分类算法在本文数据集上均有不错的表现,证明了本文特征提取方法的可行性和有效性。该方法能够突显恶意家族的核心特征,有利于分类器对恶意样本进行同源判定。从图10 可知,本文提出的模型优于一些机器学习分类算法,对各类恶意家族分类效果较好。深度学习模型经过训练后,由标准卷积组成的神经网络模型分类准确率较高,而深度可分离卷积将空间特征和跨通道特征完全分开,采用深度卷积进行空间特征提取,逐点卷积进行跨通道特征提取,两者深度提取了丰富的特征信息,进一步提升了模型的判别能力。基于混合域注意力机制的深度可分离卷积网络模型的准确率、宏召回率、宏精确率和宏F1-score 均优于VGG16、InceptionV2、ResNet50、MobileNetV2 四种神经网络模型,说明混合域注意力机制从通道和空间两个维度学习不同的权重,多维度地提取恶意代码家族图像的深层纹理特征,加强模型提取关键特征的能力,从而提高模型的分类准确率。

Table 4 Comparison of model test results表4 模型测试结果对比
在本文实验中,模型主要分为数据预处理和恶意家族分类两部分。数据预处理阶段采用IDA Pro工具提取区段特征,按照规则进行可视化,该阶段时间开销取决于区段提取器的效率。本文实验环境为i7-9750H,2.60 GHz CPU,32 GB 内存。为测试数据预处理阶段的时间开销,从各类恶意家族中随机选取若干样本,计算特征提取所需时间,并取其算数平均值作为样本的平均时间开销。样本在数据预处理阶段中的平均时间开销如表5 所示。
在恶意家族分类阶段,相比于机器学习分类算法,深度学习分类模型需要训练神经网络获取性能优良的分类器。在表4 所述的分类模型中,本文提出的模型借鉴轻量化网络结构,参数量较少,在同等参数量的情况下可获得更高的分类性能,但在时间开销上,由于本文模型结构深而宽以及注意力机制的引入,相比于浅层神经网络增加了一定的计算时间,在保持对恶意家族的分类准确率的基准上,对每个样本的平均检测时间为1.13 s。

Table 5 Average time overhead of data preprocessing表5 数据预处理平均时间开销
4 结束语
本文采用恶意代码可视化的方法对恶意代码家族进行分类研究,针对传统可视化中数据损失、单一等问题,提出了一种基于区段特征融合的可视化的方法,即提取恶意样本的各区段特征以增加图像的信息量,使图像的不同通道代表不同的区段特征。同时借此探究了不同区段对恶意代码家族分类的影响,实验证明单一区段特征不足以表征恶意代码家族的全部特征信息,对各区段特征进行融合可以提高模型的判别能力。为了使分类模型有效地提取恶意样本的关键特征,融合注意力机制,提出了一种基于混合域注意力机制的深度可分离卷积网络。该模型从不同的维度获取不同的权重信息,提取恶意样本的核心特征,与传统的机器学习和深度学习方法相比,取得了较好的分类效果。
本文采取静态方法提取各区段特征,不可避免地需要处理一些加壳样本,加大了特征提取的复杂度。下一步将对特征工程进行优化,结合动态特征以对抗加壳混淆样本,提高恶意代码家族分类效率和鲁棒性,同时对恶意家族分类模型的网络结构进行调整优化,减少在实际环境中的时间开销。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
软件(2017年6期)2017-09-23
