
多阶段推荐算法在校园交易平台中的应用研究
2021-05-12 07:08:56张若萱马嘉骏张钊铭吴梦歌潘韵竹刘海龙
信息记录材料 2021年3期
张若萱,董 晨,马嘉骏,张钊铭,吴梦歌,潘韵竹,刘海龙
(天津理工大学计算机科学与工程学院 天津 300384)
1 引言
大学校园交易平台为学生学习、生活带来便利,建立大学校园交易平台成为新的应用需求,但面对海量商品,如何快速、精准的为买家匹配到心仪商品,推荐算法成为关键。本文针对校园交易不同阶段使用多阶段推荐算法,实现个性化商品推荐。第一阶段用户和商品数量少,基于用户注册信息,使用XGBoost算法实现商品推荐。第二阶段用户和商品数量较大,采用基于物品和用户的协同过滤实现个性化商品推荐。第三阶段随着交易增多和交流圈建立,信息与数据变得更为庞大,文本型数据较多,加入自然语言处理算法,使商品推荐更加精确高效。
2 多阶段推荐算法设计
多阶段推荐算法流程见图1。
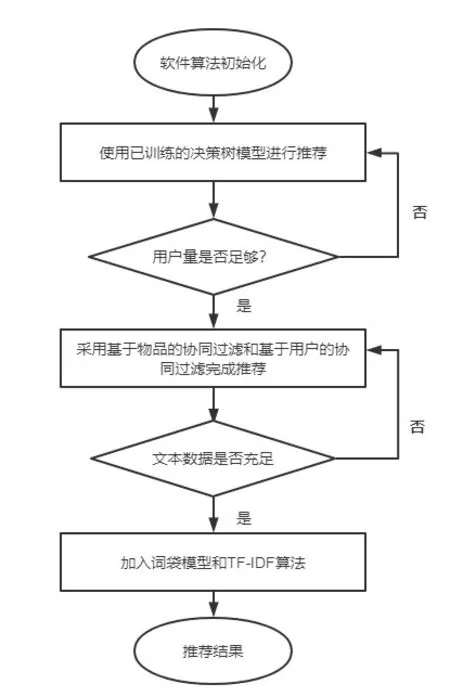
图1 多阶段推荐算法流程
2.1 第一阶段推荐算法设计
这一阶段处于交易平台的起步,用户和商品数据较少,需要解决用户冷启动,物品冷启动,系统冷启动问题[1]。为了提高商品推荐的准确度,基于注册用户的信息和兴趣标签训练决策树模型,设计初步的用户画像。使用XGBoost算法对数据集进行预测,Boosting是一种非常有效的集成学习算法,采用Boosting算法将弱分类器转化为强分类器,解决各类冷启动问题,流程如下。
(1)初始化模型为常数

(2)计算错误率

(3)计算αm= log((1-errm) /errm)
根据迭代结果,输出用户和商品关系矩阵,矩阵元素(用0,1表示)表示此用户是否会对该产品感兴趣。
2.2 第二阶段推荐算法设计
第二阶段交易平台中用户和商品数据量较大,采用基于物品的协同过滤和基于用户的协同过滤算法实现商品推荐。
2.2.1 基于物品的协同过滤算法
在交易平台中,很多学生会多次购买具有相似特征的商品,根据这一特点,采用基于物品的协同过滤算法进行推荐[2]。
(1)相似度计算
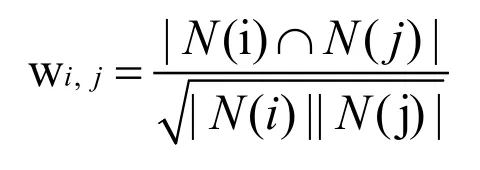
为了减小活跃用户对结果的影响,考虑IUF(即用户活跃度对数的倒数),这时认为活跃用户对物品相似度的贡献应该小于不活跃用户。
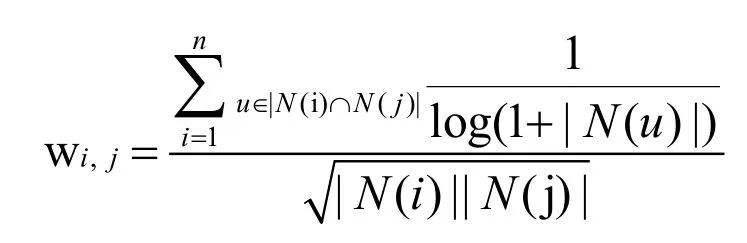
为方便计算和训练,进一步将相似度矩阵归一化:
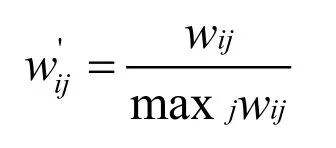
(2)根据预测值计算
根据以下公式:

pu,j表示u对物品j的兴趣,N(u)表示用户喜欢的物品集合,S(j,k)表示和物品j最相似的K个物品集合(j是这个集合中的某一个物品),Wji表示物品j和物品i的相似度,rui表示用户u对物品i的兴趣(对于隐反馈数据集,如果用户u对物品i有过行为,rui都等于1。
2.2.2 基于用户的协同过滤算法
大学校园中很多学生偏好相同,会出现购买商品相似度较高的情况。基于这一特点,采用基于用户的协同过滤算法能够较好地实现精准推荐。
(1)发现兴趣相似的用户
通常用Jaccard公式或者余弦相似度计算两个用户之间的相似度。设N(u)为用户u喜欢的物品集合,N(v)为用户v喜欢的物品集合,Jaccard公式:
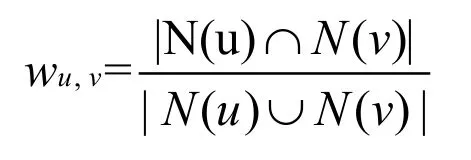
余弦相似度:
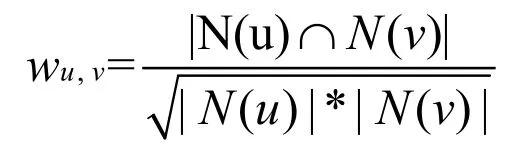
通过建立“物品-用户”倒排表,可计算出两个用户之间的相似度。
(2)推荐商品
(3)输出推荐结果
将以上两个推荐算法结果进行加权评分,得到用户偏好的商品列表并排名,直接进行推荐。
2.3 第三阶段推荐算法设计
随着交易圈的扩大,平台用户数量和商品信息量骤增,文本数据较多,为发挥文本数据作用,使预测更加准确,引入自然语言处理词袋模型和TF-IDF算法。
(1)词袋模型
使用词袋模型表示文本,将文本转化为文档中单词出现次数的矩阵,主要步骤如下:
1)文本分词:使用jieba分词器将文本数据分词。
2)构建词汇表:将文本语料库中的所有单词进行标号,存储在本地数据库中,并建立索引加快查找速度。
3)词向量表示:每个单词都表示为一个n维向量,在词汇索引位置为1,其他为0。
4)统计频次:统计每个文本中单词出现的频次,用向量的形式表示文本关键字。
(2)运用TF-IDF算法评估关键字
在得到文本的向量表示后,希望将文档中出现频繁却不是关键字的词语权重降低,采用TF-IDF算法,即:
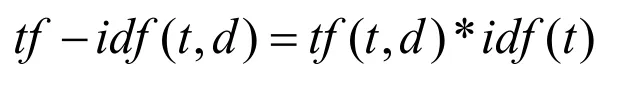
(3)训练模型
此时可以采用第二阶段设计方法,在训练数据集中加入处理后的文本关键字,比如用户评论,交友圈的文本内容,得到更为准确的商品推荐结果。
3 结论
本实验主要基于交易平台中的3000名用户数据进行测试,分别使用协同过滤算法和多阶段推荐算法进行商品推荐,如果用户对推荐结果满意则打分1,不满意打分0,将打分总数/打分人数计算准确率,图2为推荐结果准确率比较。
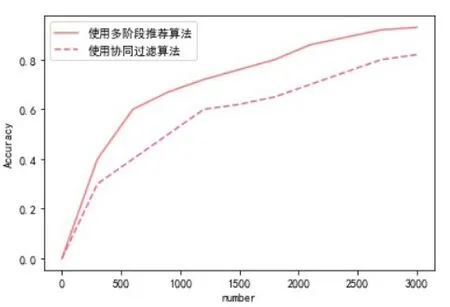
图2 推荐算法准确率比较
从图2可以看出,在平台交易的不同阶段,使用多阶段推荐算法,准确率都比仅使用协同过滤算法高,表明多阶段推荐算法更适合校园交易流程。
猜你喜欢
重庆大学学报(2022年6期)2022-06-23 07:32:50
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
客联(2021年2期)2021-09-10 07:22:44
现代企业(2021年2期)2021-07-20 07:57:30
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
艺术品鉴证.中国艺术金融(2018年12期)2018-01-28 00:23:53
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:39
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
中国卫生(2014年2期)2014-11-12 13:00:12
