
基于频繁模式挖掘的接触网故障关联规则推荐模型
2021-05-10 07:41宇占军
电气化铁道 2021年2期
宇占军
0 引言
近年来,我国电气化铁路飞速发展,成为支撑国民经济的重要基础,为民众日常出行提供了便利。截至2019年年底,我国铁路营业里程已达13.9万公里[1]。接触网作为电气化铁路牵引供电系统的重要组成部分,是电力机车的动力来源,其服役安全是保障铁路高效运行的关键[2]。然而,接触网是一种沿路轨架设的特殊供电线路,无备用且结构复杂,工作环境恶劣[3],随着服役时间的增加,接触网性能势必逐渐退化,发生故障的可能性逐渐提高。因此,如何有针对性地对接触网进行维修是目前亟需解决的问题。
在接触网系统中,故障之间并不是完全互相独立的随机事件,其通常存在着关联性,即一个故障的发生往往会诱发另一个故障。随着检测监测与诊断评估技术的不断提升,各铁路局建立的接触网故障数据库中积累了大量的相关数据,其包含了由6C系统检测到的故障和人工定期巡检得到的数据,这为从数据挖掘角度进行相关研究提供了较好的数据支持。
频繁模式挖掘(Frequent Itemset Mining,FIM)是关联分析技术的一种,其通过挖掘数据库中频繁出现的模式,进而探究模式之间的关联性。FIM技术最早由Agrawal R.于1993年提出[4],目前已广泛应用于医疗、工业、交通等领域[5~7]。其核心是通过扫描数据库生成潜在的候选模式,并根据设定的阈值验证其最终是否频繁。其中,向下封闭原则[8](Downward Closure Property)对某些模式进行了预筛选,减少了需要验证模式的数量,从而提升算法效率。
目前,已经有学者将频繁模式挖掘应用于接触网故障数据分析,并得到了一些实用的关联规则。文献[9]根据逐条记录的接触网故障数据结构以及数据上存在的稀疏性提出了多维信息分类模型,实现了对故障数据的有效聚类,完成了条目数据结构向事务型数据库(Transaction Database)的转变。但由于其在时间维度上对数据的划分仅依据自然年月,会破坏某些数据间的内在联系,从而使得到的关联规则失去作用。文献[10]基于挖掘得到的关联规则建立了故障关系网络,并采用复杂网络中的指标对规则进行使用。上述方法在规则数量较少时才能方便运用,当规则数量增加后,整个网络会变得过于复杂,从而降低了对规则使用的效率。
本文基于Apriori算法框架,提出根据实际故障维修周期划分故障数据的分类模型,保证数据间既有的关联性不被破坏;并采用熵权法对挖掘算法常用的几个参数进行综合评价,得到对可能出现大量关联规则的快速推荐模型。此外,为了避免多次扫描数据库,提高算法效率,应用布尔映射矩阵,仅需单次扫描数据库即可实现挖掘算法。
1 相关基础
1.1 基本概念
假设有一组项目集合I= {i1,i2, …in},集合I的任意非空子集被称为项集,记为X,通常项集X中包含的项目个数被称为项集的长度,同时项集也根据其长度k被称为k阶项集。事务记录通常用一个二元组〈tid,X〉来表示,其中tid是该事务记录的唯一标识。所有的事务记录共同组成了事务数据库,记为TDB,如表1所示。对于一个项集X和一条事务记录〈tid,Y〉而言,如果X⊆Y,则称项集X被包含在该事务记录中。

表1 事务型数据库
1.2 相关参数
在挖掘关联规则的过程中,需要设置支持度和置信度的阈值,在有些研究中,还需要涉及提升度和相似度等参数。这些参数的定义如下:
定义1(支持度):对于一个给定的事务型数据库TDB,项集X的支持度(记为sup(X))为数据库中包含项集X的事务记录数占比,反映了项集X在数据库中出现的频繁程度,其计算式为
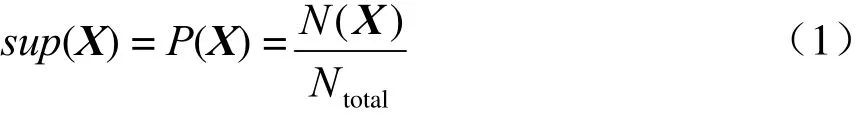
定义2(置信度):置信度是评价关联规则可信程度的指标。对于生成的关联规则“A→B”,其置信度(记为conf(A→B))为在项集A发生的条件下,项集B发生的条件概率。其具体计算式为
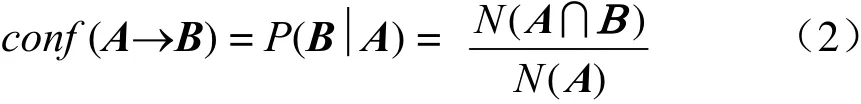
定义3(提升度):提升度(记为lift(A→B))是描述项集A对项集B影响程度的参数,其反映了在项集A发生的条件下,项集B发生的条件概率与非条件概率的提升情况。当提升度大于1时,说明项集A的发生对项集B有促进作用。其计算式为
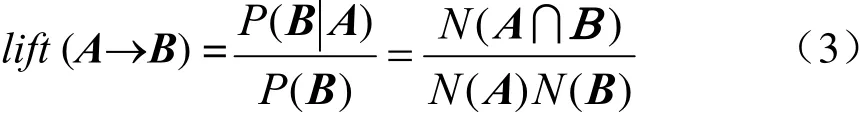
定义4(相似度):相似度能够反映2个研究对象之间的相似程度,有着多种计算方式,其中以余弦相似度最为常用。将项集A和B在每个事务记录中出现与否的情况用向量表示,则可计算出其相似度,即
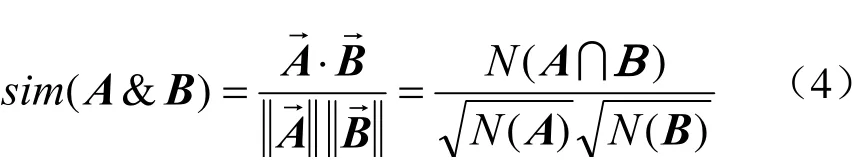
1.3 A priori算法框架
目前,频繁模式挖掘算法可以根据算法框架分为3大类,Apriori算法框架[11]则是其中之一,通过对数据库进行广度优先遍历,以实现整个算法。算法具体过程如下:算法将整个数据库的数据和设置的最小阈值(支持度和置信度)作为参数;数据库中出现的项目均被视为1阶候选项集,通过扫描数据库对候选集的频繁程度进行评估,算法删去了不符合阈值的项集,并根据先验规则[4]合并生成2阶候选项集;通过再一次扫描数据库,对当前候选项集进行验证,根据剩余的频繁项集生成高阶候选集;该过程被不断重复,直至无法生成候选集,此时所有满足阈值的频繁模式均被遍历并验证。
2 模型构建
2.1 基于维修周期的故障分类模型
文献[9]提出的多维信息分类模型通过灵活地选择时间和空间尺度,有效地实现了对故障数据的聚类和事务型数据库的构建,但由于时间尺度的划分过于刻板,破坏了故障数据间原本的内在联系。为了解决这一问题,本文提出基于维修周期的故障分类模型。
对于同一空间尺度下的故障数据,可按其检测时间顺序排列成对应的时间序列。为保证构建的事务型数据库中每一条事务记录的项目享有共同的物理和逻辑联系,对于接触网系统来说,只有发生在同一维修周期内的故障数据才具有这种特性。图1展示了基于维修周期的故障分类模型示意图,在由故障数据构成的时间序列下方增加了维修记录管理的序列,并将其作为划分故障数据的依据。
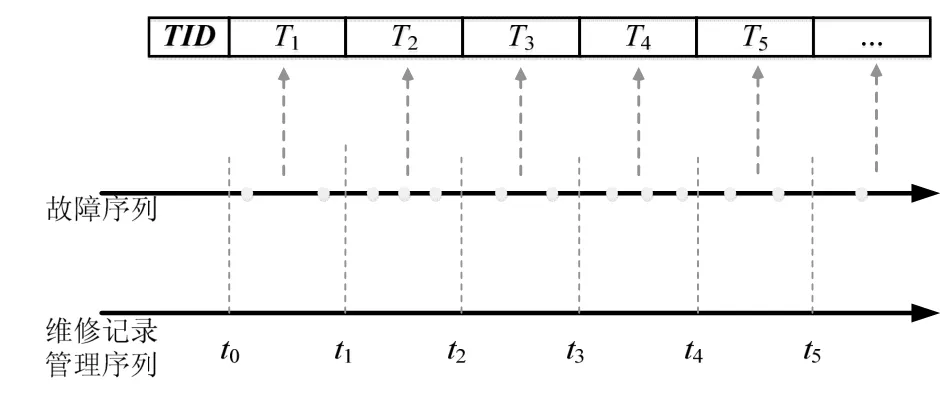
图1 基于维修周期的故障分类模型示意图
维修记录管理的序列作为无限时间序列,可以根据其序列上的n个结点,将其划分成对应的区间,记为IM= {(ti-1,ti)|i≤n}。同时,故障序列上的数据IF= {fm|m≥1}将根据IM生成事务记录,记为Ts={∪fm|fm∈IF,fm∈(ts-1,ts)}。借助这一分类模型,可以在生成事务型数据库时良好地保留故障数据间的内在联系。
2.2 布尔映射矩阵
Apriori算法框架在每次验证当前阶数的候选集时需要扫描一次数据库,多次扫描数据库将耗费大量运算成本,为了避免这种重复扫描,本文提出采用布尔映射矩阵存储事务型数据库的数据,并对候选集进行批量计算。
定义5(布尔映射矩阵):矩阵中的元素根据其行列所对应的信息,用“1”或“0”表示是否出现的具有映射关系的矩阵称为布尔映射矩阵。
对于挖掘接触网的频繁模式而言,矩阵的每一行对应事务型数据库中的每一条事务记录,矩阵的每一列对应一个项目或项集。矩阵内的元素确定规则如下:

性质1(列交运算):设矩阵Am×n为事务型数据库TDB的布尔映射矩阵,AT×A=Bn×n,则矩阵B称为矩阵A的列交矩阵。矩阵B的主对角线上的元素反映了各项目在数据库中出现的次数,则每个项目的支持度可表示为

2.3 基于熵权法的推荐模型
频繁模式挖掘算法往往伴随着大量关联规则的返回,文献[10]采用复杂网络的知识对返回的关联规则进行了推荐,但随着规则数量的增加,网络的复杂度明显增加,大幅降低了对规则使用的效率。为了解决该问题,本文提出基于熵权法的推荐模型。熵权法[12,13]可以通过选取多个评价指标,利用数据中包含的有效信息量的大小来衡量各个指标对最终评价结果的影响。
熵权法的基本原理如下:假设有m个评价对象,选取了n个评价指标,所有数据构成的初始矩阵记为Xm×n;首先对各个指标的数据进行标准化处理,生成评价矩阵Y= [yij]m×n, 其中yij为第i个评价对象的第j个指标的归一化结果;然后计算同一个评价指标数据的信息熵Ej,其定义式为
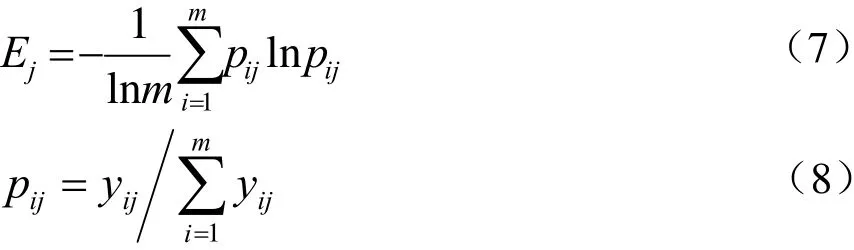
其中,当pij= 0时,习惯认为pijlnpij= 0。
从而,通过信息熵可以计算出各个评价指标所对应的权重Wj,即
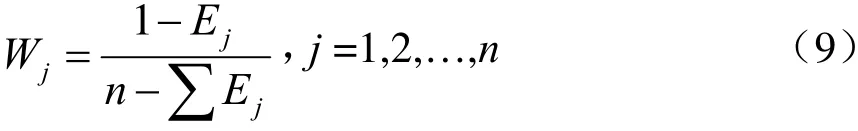
最终,根据指标的权重计算出每一条关联规则的评分Zi,并按降序推荐关联规则。评分的计算式为

3 算例研究
为了验证本文提出推荐模型的正确性,本节对某铁路局接触网故障数据库中的数据进行频繁模式挖掘,时间跨度为2016年1月—2018年4月,共计22 749条接触网故障数据。
在选择空间尺度为线路后,依据维修记录管理序列与同一空间尺度下的故障序列,将这些故障数据划分为137条事务记录,并将阈值设置为(25%,80%),即表示在事务型数据库中有25%的事务记录含有的项集被视为了频繁模式,且在这些频繁模式生成的关联规则中,只有置信度大于80%的规则(强关联规则)才被保留下来。最终,在该阈值设定下,频繁模式挖掘算法共挖掘得到689条强关联规则。这个数量的关联规则如果通过复杂网络理论对其进行推荐,整个过程将十分复杂。采用本文提出的基于熵权法的推荐模型,则可以轻松得到支持度(sup)、置信度(conf)、提升度(lift)、相似度(sim)4个评价指标的权重,如表2所示。可见,支持度的权重最高,贡献程度接近60%,其余3个指标的权重都在10%以上。

表2 基于熵权法的关联规则评价指标权重
表3展示了部分关联规则的推荐评分结果,表4给出了表3中涉及的故障项目和故障部件(类型)的对应关系。可以看出,本文提出的模型可以有梯度地对挖掘出的规则进行评分和推荐。用户可以根据自身的需求,对期望推荐的关联规则数量进行推荐,当推荐数量设置为10时,则排序前10的关联规则将被推荐给用户。
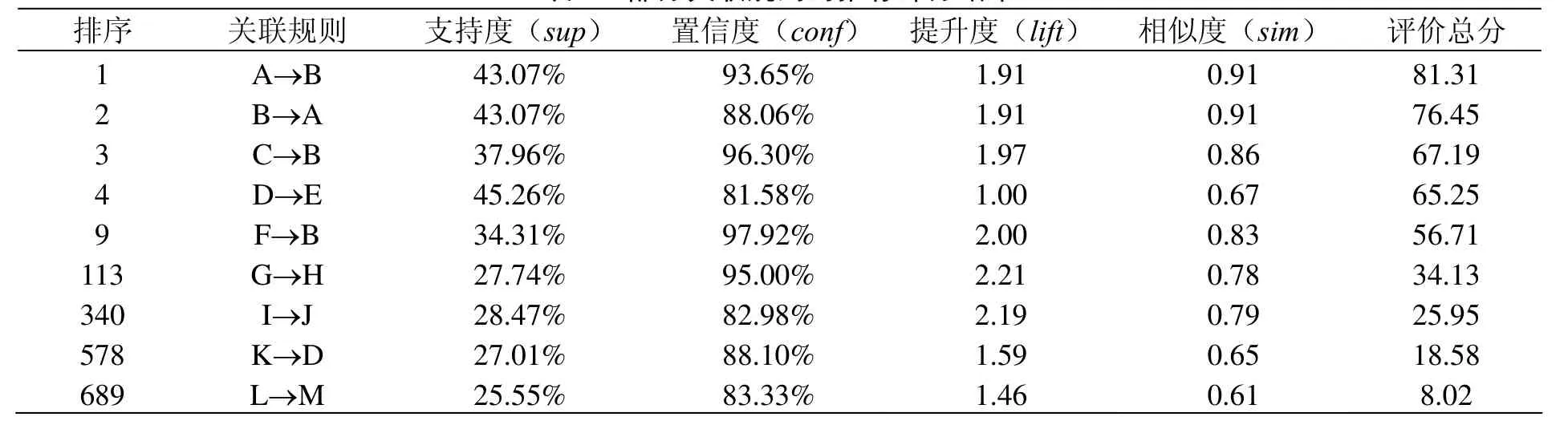
表3 部分关联规则的推荐评分结果
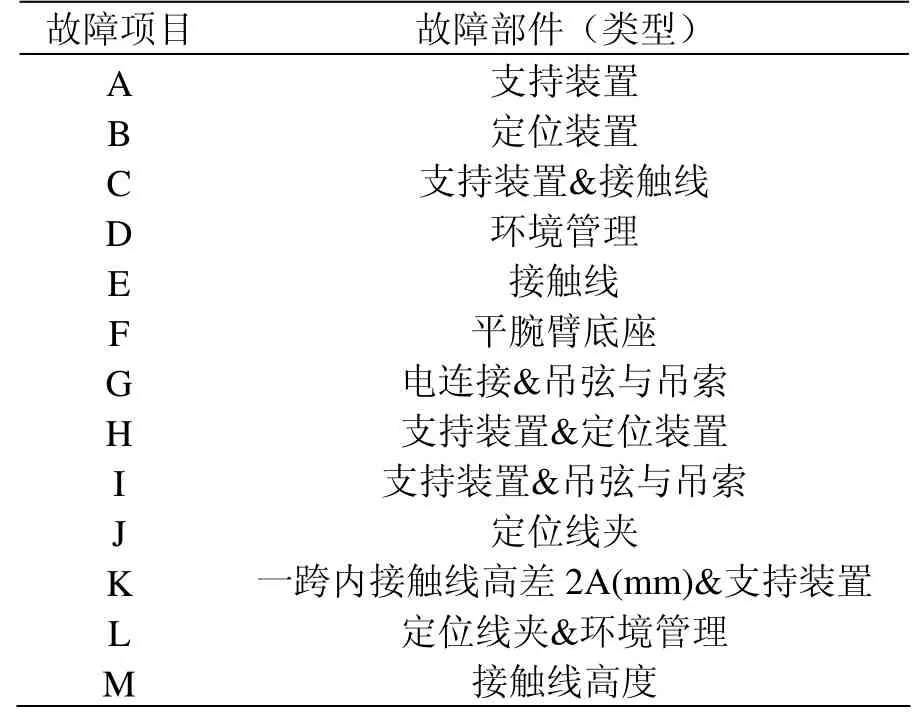
表4 故障项目和故障部件(类型)对照
图2展示了对689条关联规则构建故障关系网络的结果。可以看出,得到的网络十分复杂,涉及的结点数量众多,这对分析网络中各结点的中心度等必要信息造成了极大的影响,且很难对每一条关联规则分析其值得推荐的程度。
通过查看关联规则的评分结果可知,故障项目A(支持装置)容易引发故障项目B(定位装置),是最值得推荐的关联规则。其次,故障项目D(环境管理)会诱发故障项目E(接触线)、故障项目F(平腕臂底座)极可能造成故障项目B(定位装置)等也是十分值得关注的关联规则。

图2 689条关联规则挖掘结果构建的复杂网络
根据最终推荐的多条关联规则,对于算例研究中使用的故障数据,可以为该地区接触网运营维护提出如下建议:(1)支持装置故障和定位装置故障是2个频繁发生且会互相诱发的故障,需要对其进行严格防护和缩短维修周期;(2)除支持装置外,接触线故障、平腕臂底座故障等也容易诱发定位装置的故障,需要对上述多个故障进行监测,以防止定位装置频繁发生故障;(3)周遭环境和异物容易引发接触线故障,需要增加线网周围的巡查力度和对植被的修剪频次。
4 结论
本文针对近年来爆发式增长的接触网故障数据,提出采用频繁模式挖掘技术对其进行关联性分析。在现有多维信息分类模型的基础上,提出了维修周期故障分类的方法,实现了在生成事务型数据库时对故障数据内在联系的良好保留。针对Apriori算法框架在挖掘时需要多次扫描数据库的问题,提出了应用布尔映射矩阵的列交运算,实现了仅需对数据库进行单次扫描即可实现对候选集进行批量阈值验证。针对挖掘算法返回的大量关联规则,提出了用熵权法对各条规则进行评价打分,实现了对规则的有梯度推荐,相较原本基于复杂网络的规则使用,熵权法对大规模关联规则有着更好的实用性。
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
云南画报(2021年10期)2021-11-24
河南水利年鉴(2020年0期)2020-06-09
天津科技大学学报(2018年4期)2018-08-22
西南交通大学学报(2016年3期)2016-06-15
现代工业经济和信息化(2016年4期)2016-05-17
铁路技术创新(2015年3期)2015-12-21
长春大学学报(2013年8期)2013-06-21
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
网络安全与数据管理(2010年1期)2010-05-18
