
基于层次分类法的弥漫大B细胞淋巴瘤的疾病进展阶段多分类预测研究*
2021-05-08 05:54黄雪倩张岩波郑楚楚余红梅范双龙阳桢寰赵志强罗艳虹
中国卫生统计 2021年2期
黄雪倩 张岩波 王 蕾 郑楚楚 余红梅 范双龙 阳桢寰 邢 蒙 赵志强 罗艳虹Δ
【提 要】 目的 对山西省某医院2011-2017年确诊为弥漫大B细胞淋巴瘤(diffuse large B-cell lymphoma,DLBCL)患者进行疾病进展阶段多分类预测,为患者是否需要及时转为二线挽救治疗或放疗等治疗手段的选择提供参考。方法 用层次分类法将三分类的疾病进展阶段进行两层二分类,分别进行变量筛选后,用SMOTE过采样处理数据中的类别不平衡问题,然后使用SVM、BP神经网络、随机森林等单分类器模型与AdaBoost同型集成和Stacking异型集成方法分别构建两层疾病进展阶段的二分类预测模型,最后分别选择两层中分类性能最优的模型并结合在一起。结果 使用经SMOTE平衡后的数据构建的两层分类模型中的SVMboost集成模型,准确率分别为0.951和0.972,模型性能均为最优,因此两层二分类的基分类器均选择SVMboost。结论 本研究构建弥漫大B细胞淋巴瘤患者疾病进展阶段的层次多分类预测模型,其中两层分类模型中的SVMboost集成模型性能均为最优,将两层二分类的基分类器结合后,准确率为0.924,高于作为对比的直接多分类模型,为临床工作者的诊断与治疗方案选择提供一定参考。
弥漫大B细胞淋巴瘤(diffuse large B-cell lymphoma,DLBCL)是非霍奇金淋巴瘤(non-Hodgkinlymphoma,NHL)中最常见的亚型,占所有NHL的30%~40%[1],是一组具有高度异质性的恶性肿瘤,常呈进展性。目前利妥昔单抗+环磷酰胺、阿霉素、长春新碱和强的松(R-CHOP)是DLBCL的化疗首选方案,大部分患者经治疗后可以达到完全缓解(complete remission,CR)。但仍有部分患者在治疗中病情进展或缓解后早期复发(缓解期小于一年),且复发后治疗反应率较低,反应持续时间较短,最终转变为难治性DLBCL,成为DLBCL主要死亡原因[2-3]。针对复发性和难治性DLBCL,临床上研发了很多二线挽救治疗方案,能有效延长患者的总生存期(overall survival,OS),提高患者生存质量。自体造血干细胞移植和低剂量姑息性放疗等方法[4]对难治性侵袭性淋巴瘤也有一定效果。复发性和难治性DLBCL通常对一线治疗方案不敏感或产生耐药性,若不能准确地对疾病进展阶段进行判断,重复地对其进行无用治疗,不仅会错过最好的二线挽救治疗时机,还会给患者带来一定的心理负担和经济负担。因此,对DLBCL疾病的进展阶段进行精确的分类预测有较大的现实意义。
资料来源
本研究数据来自于山西省某医院2011-2017年被确诊为DLBCL的患者,共384例。其中复发性DLBCL是指初次化疗获得完全缓解后复发的淋巴瘤,共74例;难治性DLBCL是指满足以下任何一项:①经标准方案规范化疗 4 个疗程,肿瘤缩小<50%或病情进展;②经标准方案化疗达CR,但半年内复发;③CR后2次或2次以上复发;④造血干细胞移植后复发,共38例;剩余病例为一般性DLBCL[5],共272例。因不同疾病进展阶段的病例数量差距较大,造成了数据的不平衡,因此需要对数据进行过采样使其平衡。本文采用的过采样方法是SMOTE算法。
原理及方法
1.类别不平衡数据
SMOTE(synthetic minority over-sampling technique)[6]算法在2002年被提出并得到认可,它的基本思想是通过人工合成新的少数类样本来降低类别不平衡性。具体做法是:假设邻近参数为k,首先从每个少数类样本的x个同类最近邻中随机选择k个样本;然后将每个少数类样本分别与选中的k个样本按式(1)合成k少数类新样本;最后,将新样本添加至训练样本集中,形成新的训练样本集[7]。
xnew=x+δ(y[i]-x)
(1)
式中:xnew为合成的新样本;x为少数类样本;δ为0到1之间的随机数;y[i]为x的第i个近邻样本。
在 SMOTE 算法中,邻近参数k是否能够合理设置将直接影响最终的分类性能。通常设置邻近参数k=5。
本研究中SMOTE使用R软件中DMwR包SMOTE语句实现,其中设perc.over=500,perc.under=100。
2.分类模型
多分类的本质是多次二分类,包括直接法和间接法。直接法是直接在目标函数上修改,将多个分类面的参数求解合并到一个最优化问题中,通过求解该最优化问题一次性实现多分类。该方法看似简单,但其计算复杂度较高,且没有通用的多分类求解法,需要根据具体问题设计策略,实现起来较困难,且分类准确率不高;间接法主要是通过组合多个二分类器来实现多分类器的构造,常见的方法有“一对一”(one-versus-one,OVO)、“一对其余”(one-versus-rest,OVR)和层次分类法等。
(1)层次分类法原理
本文采用的是层次分类法[8-9],其原理是第一层将所有类分为一级子类,第二层再将一级子类进一步分为二级子类,直到能够区分所有类别为止。图1为包含四个类别的两种层次结构。图1(a)是完全二叉树,它在每个决策节点将所包含的类别分为两个包含类别数目相同的子类;图1(b)是偏二叉树,它在每个决策节点将一类与其他所有类别分开。
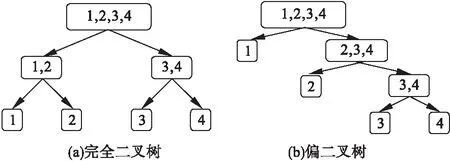
图1 层次分类法结构
针对本研究数据,使用偏二叉树层次结构,即先将所有病例分为一般性DLBCL和复发性/难治性DLBCL两类,然后再将复发性/难治性DLBCL分为复发性DLBCL和难治性DLBCL两类,最终将所有病例分为一般性DLBCL、复发性DLBCL和难治性DLBCL三类。
(2)层次分类法基分类器的选择
在本研究中,层次分类法将三分类的DLBCL疾病进展阶段数据分为两层二分类。在每层二分类中,首先应用支持向量机[10]、BP神经网络[11]、随机森林[12]等单分类器构建二分类模型;然后,分别应用上述单分类器构建集成学习二分类模型,集成方法主要包括AdaBoost集成[13]和Stacking集成[14],并将集成模型与各个单分类器的分类性能进行比较;最后分别选择两层中分类性能最优的模型并组合在一起,即完成层次分类法基分类器的选择。
(3)构建模型
为进一步证实层次分类法的分类性能,本文应用可进行直接多分类的单分类器(SVM、随机森林和BP神经网络)构建直接三分类模型,并应用上述单分类器构建AdaBoost集成模型和Stacking集成模型,分别将其分类性能与层次分类法进行对比。
①直接多分类
分别从一般性、复发性和难治性DLBCL三类中各随机抽取三分之一样本合并,作为测试集;其余样本作为训练集,训练集用于构建模型,测试集用于测试模型的分类准确率,重复采样并构建模型100次。
②层次分类法
将三分类的疾病进展阶段分为两层二分类。第一层分别从一般性DLBCL和复发/难治性DLBCL两类中各随机抽取三分之一样本合并,作为测试集,其余样本作为训练集,训练集用于构建模型,测试集用于测试模型的分类准确率,重复采样并构建模型100次;第二层从复发性DLBCL和难治性DLBCL两类中抽样,其余同上所述。
3.评价指标
本研究采用准确率(accuracy)[7]、灵敏度(sensitivity)、F值、ROC曲线下面积(AUC)和G-means值作为评价指标。由于AUC、F值、G-means一般仅适用于二分类问题,因此本研究中,上述指标用于两层二分类最优模型的选择,准确率作为经典直接多分类器和层次分类法的对比评价指标。
每个分类器的结果可以分为真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)四类。由此可得以下的公式:
(2)
(3)
(4)
(5)
由式(3),(4),(5)可得出F值和G-means的表达式为:
(6)
(7)
F值既考虑精度(正确阳性结果的数量除以所有阳性结果的数量),也考虑召回率(正确阳性结果的数量除以应该返回的阳性结果的数量)。只有精度和召回率都比较高的前提下,F值才会高。G值综合考虑了少数类和多数类的分类性能,必须满足多数类和少数类样本正确率的值同时高,G值才会高。受试者工作特征曲线(receiver operating characteristic curve,ROC)是在平面上以假阳性率(FPR)为横坐标,以真阳性率(TPR)为纵坐标所画的一条曲线,横坐标FPR和纵坐标TPR可由下式计算得出:
(8)
(9)
4.变量筛选
病例信息来自于医院的电子病例,包括一般情况、病理信息、CT/PET-CT影像数据和治疗方案等100余个变量。结合《2013年中国弥漫大B细胞淋巴瘤诊断与治疗指南》[15],对两层二分类分别进行变量重要性排序,筛选出前18个与疾病进展阶段分类相关的变量。图2为前30个变量的重要性排序(其中1为原发部位,2为继发部位)。
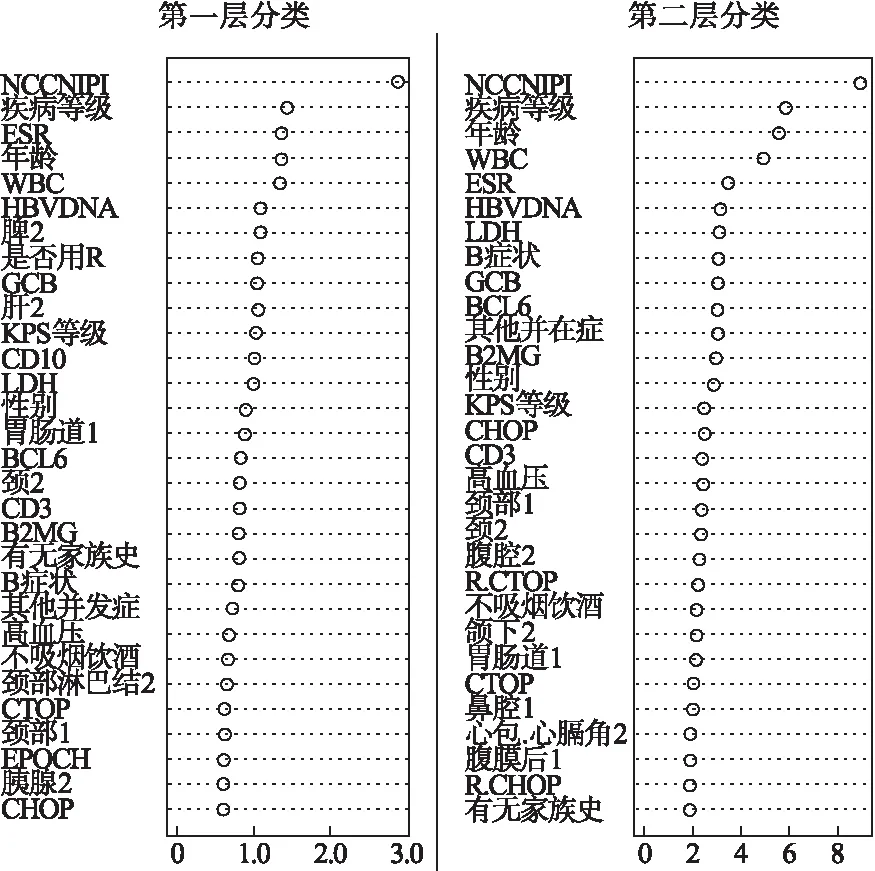
图2 变量重要性排序
结 果
1.直接多分类
表1为三种单分类器及其构建的集成模型的直接多分类结果,用分类准确率作为评价指标。

表1 直接多分类准确率
由表1可知,三种单分类器中,随机森林分类准确率最高,BP神经网络和SVM准确率相差不多;各单分类器的AdaBoost集成模型分类准确率较单分类器均有所提高,三种单分类器组合的Stacking集成分类准确率高于SVM和BP神经网络,但所有直接多分类模型准确率均没有达到90%。
2.层次分类法
表2和表3分别是使用测试集进行验证的两层分类模型的评价指标。
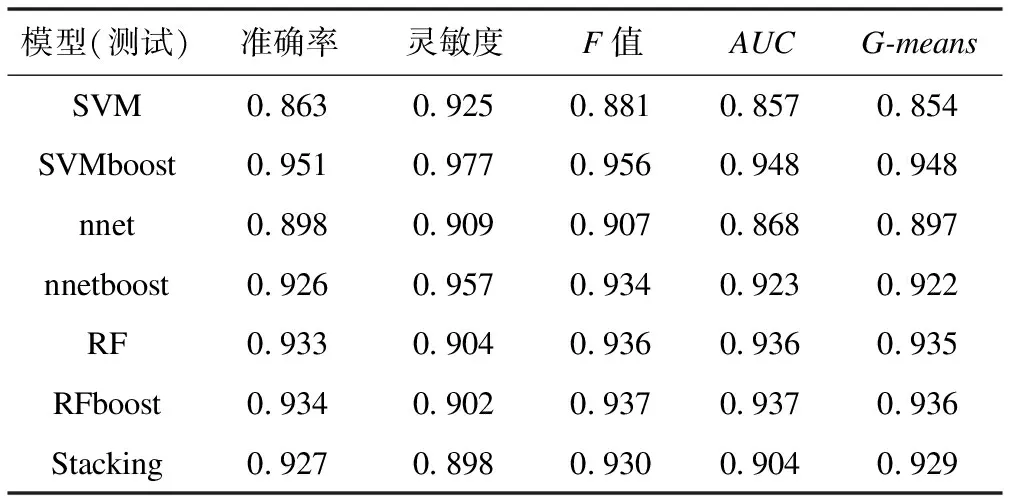
表2 第一层分类模型性能评价

表3 第二层分类模型性能评价
由表2可得第一层二分类中,SVMboost模型性能最优(准确率=0.951,灵敏度=0.977,F值=0.956,AUC=0.948,G-means=1.001),因此选取SVMboost作为第一层的基分类器;由表3可得第二层二分类中,SVMboost模型性能最优(准确率=0.972,灵敏度=0.997,F值=0.975,AUC=0.969,G-means=0.968),因此第二层的基分类器也选择SVMboost。
将两层二分类所选择的最优基分类器SVMboost组合起来,疾病进展阶段三分类准确率可达0.924。图3为直接多分类模型和本文所应用的层次分类法的分类准确率对比。层次分类法的分类准确率明显高于直接多分类模型。
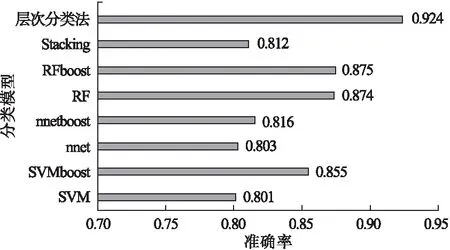
图3 八种分类模型的准确率
图4分别给出了两层分类模型中各个基分类器训练集和测试集的分类准确率(其中1代表第一层分类,2代表第二层分类)。由图4可知,所有模型中训练集的分类准确率均优于测试集;所有模型的第二层分类准确率均高于第一层分类。对集成模型与单分类器进行分类性能比较可知,除随机森林模型外,集成模型的分类性能均优于其对应的单分类器,而随机森林本身就是对树模型的Bagging集成模型,本研究中对其做进一步的AdaBoost集成后发现其模型的分类性能并未明显提升。

图4 层次分类法训练集和测试集的分类准确率
讨 论
本文应用的层次分类法能将复杂的多分类问题简化,每一层都含有7个基分类器,包括单分类器和同型/异型集成模型,分类准确率高于几种用于对比的直接多分类器;在其他应用集成算法的直接多分类研究中,宋亚男等在未进行不平衡数据处理的AdaBoost 模型预测2型糖尿病患者降糖药用药分类准确率仅为0.642[16],王莉莉等在基于主动学习不平衡多分类 AdaBoost 算法的心脏病分类的准确率为0.883[17],均未达到90%,而Stjepan Picek等在机器学习旁路攻击中[18],层次分类法的分类准确率比直接多分类法提高了21%。层次分类法应用灵活,每种基分类器对不同数据类型的分类性能均有所差别,赵理莉等在宫颈细胞识别的层次分类法中每层使用了6种基分类器[19]。此外,层次分类法实际应用广泛,包括Celine Vens等对文本进行层次分类[20],IvicaDimitrovski等进行医学图像注释[21],以及Ricardo Cerri等对蛋白质功能预测等生物信息学任务等[22]。本文层次分类法的模型构建通过R语言实现,其他软件如Python等也可实现,适用性较强。
但是层次分类法中存在自上而下的“误差累积”问题,且该方法每层分类所需的运行时间较长。本文每层分类循环次数为100次,运行时间超过20小时。当需要解决5类或5类以上的多分类问题时,应用该方法所需要分的层次更多,所得分类准确率会越低,运行的时间也越长。此外,如何在层次分类中有效地进行特征变量选择也是一个值得关注的问题,不同的特征变量能影响各层中子类的区分,进而影响整个分类模型的准确率。例如Hussein Alahmer等在基于特征差的肝脏肿瘤层次分类中[23],不同的特征采集导致分类性能差异很大。如何解决和改进上述几个方面是本研究需要进一步研究的问题。
猜你喜欢
中国民间疗法(2021年13期)2021-08-30
中老年保健(2021年5期)2021-08-24
中老年保健(2021年6期)2021-08-24
中老年保健(2021年11期)2021-08-22
中国民间疗法(2021年1期)2021-04-20
中华养生保健(2020年3期)2020-11-16
中学生数理化·高一版(2020年2期)2020-04-21
录井工程(2017年1期)2017-07-31
中国中医药信息杂志(2016年5期)2016-12-01
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
