
基于深度迁移学习的跨库语音情感识别*
2021-05-08 06:10李晓坤李洪亮
通信技术 2021年4期
李晓坤,李洪亮
(曲阜师范大学,山东 曲阜 273165)
0 引言
语音作为一种情感表达的方式,通过声调的抑扬顿挫可以表达多种不同的情感。人类的情感表达具有共性。即使所使用的语言不同,情感的本质都是相同的,都具有生气、快乐、忧伤以及厌恶等情绪。基于情感的本质属性,本文想要通过对不同语言数据库之间进行跨库识别的探索,找到一种可行的方案,以提高跨库语音情感识别的准确率。
目前,关于语音情感识别[1]的研究主要分为同库语音情感识别和跨库语音情感识别。关于同库语音情感识别,多采用深度学习的方法。Keren等人[2]使用卷积+循环神经网络(Convolutional-Recurrent Neural Network,C-RNN)的方式训练语音库,对性别、年龄、情感等进行识别。Ren等人[3]使用语谱图在生成对抗网络中对Demos数据库中的语音情感进行识别。Xie等人[4]使用改进的长短时记忆网络并加入注意力机制,在CASIA、eNTERFACE、GEMEP这3个语音库中分别进行训练和测试。陈长风[5]采用卷积+长短时记忆(Convolutional Neural Network-Long Short Time Memory,CNN-LSTM)的方法进行歌曲语音情感识别。这些方法都提升了同库语音情感识别的准确率,平均识别率达到92%。
对于跨库语音情感识别,多将一般迁移学习方法[6-10]和传统的机器学习方法[11-13]进行融合。宋鹏等人[14]将TCA和s-LDA方法相结合进行特征迁移和有监督线性分布自适应的跨库语音情感识别。Song等人[15]采用特征选择和迁移子空间学习相结合进行跨库识别。Song等人[16]使用有监督的迁移线性子空间学习和特征选择融合进行跨库识别。张昕然等人[17]提出了深度信念网络(Deep Belief Nets,DBN),将其应用于跨库语音情感识别。以上这些方法逐步提升了跨库语音情感识别的准确率,但是平均识别率最高只有54.63%。
综上所述,当前关于跨库语音情感识别的研究主要集中于一般的迁移学习方法和传统的机器学习方法相结合,且在识别率方面没有较大突破。与此同时,同库语音情感识别使用深度学习的方法大大提升了识别准确率。因此,本文提出了一个深度迁移网络模型(Attention-based LSTM Dynamic Adversarial Adaptation Networks,LSTM-TF-at-DAAN),如图1所示,采用深度迁移网络进行跨库语音情感识别。

图1 LSTM-TF-at-DAAN模型
1 LSTM-TF-at-DAAN模型
如图1所示,深度迁移网络模型——基于注意力机制的长短时动态对抗适配网络(LSTM-TF-at-DAAN)由两部分组成:一部分是迁移在源域上训练好的深度网络的部分层,另一部分是动态对抗适配网络部分。关于此模型的详细描述如下。
1.1 基于注意力机制的长短时记忆(LSTM-TF-at)网络
Xie等人[4]改进了门控循环神经网络——长短期记忆(Long Short Time Memory,LSTM),将LSTM中的遗忘门(forget-gate)改为注意门(attention-gate),改后的LSTM记为LSTM-at。其中,遗忘门的输出计算公式为:

式中,ft是遗忘门当前时刻的输出,Wf是遗忘门的权重参数,×表示矩阵乘法,Ct-1是上一时刻记忆细胞的输出,ht-1是上一时刻隐藏状态的输出,xt是当前时刻的输入,bf是遗忘门的偏差,σ是sigmoid激活函数。
门的输出计算为:

式中,ft´是注意门当前时刻的输出,Vf是注意门的权重,tanh是激活函数,Wf是传递过来的上一时刻记忆细胞Ct-1的权重。
LSTM-TF-at网络的另一个创新之处是在全连接层之前加入注意力机制。在时间维和特征维进行注意,其中注意时间维(改为中文表述)为:

sT为注意时间维的输出权重,softmax是激活函数,omax_time是LSTM最后时刻的输出,oall_time表示LSTM每一时刻的输出,wt表示oall_time权重参数,H表示转置,outputT是注意时间维的输出。注意特征维为:
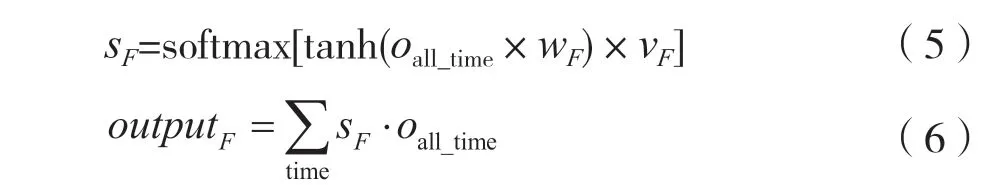
式中,sF是注意特征维的输出权重,wF是oall_time的权重,vF是sF的权重,∑表示求和运算,·表示采用hadamard积计算。
1.2 动态对抗适配网络
动态对抗适配网络(Dynamic Adversarial Adaptation Networks,DAAN)是支撑整个模型的框架,将前面训练好的LSTM-TF-at网络的前3层迁移到LSTMTF-at-DAAN模型中,作为模型的特征提取部分,与后面的动态对抗适配网络(DAAN)相结合,进行LSTM-TF-at-DAAN模型的训练和最终的测试。
Yu C等人[18]使用DAAN模型进行图像识别,在特征提取部分使用的ResNET模型,并导入已训练好的ResNET网络中的参数,后接两个全连接层,作为分类器的输出。其中,分类器的损失Ly为:
式中,xi是源域的原始特征,Gf表示特征提取器,Gy表示分类器,log表示使用logsoftmax计算损失,Pxi→c是源域中的数据属于某类的概率,C是源域的类别标签,Ds表示源域,ns是源域数据量。
另外,DAAN模型比起一般的深度学习网络多了一个判别器,使用此判别器进行源域和目标域的适配。判别器的损失分为边缘分布损失Lg为:
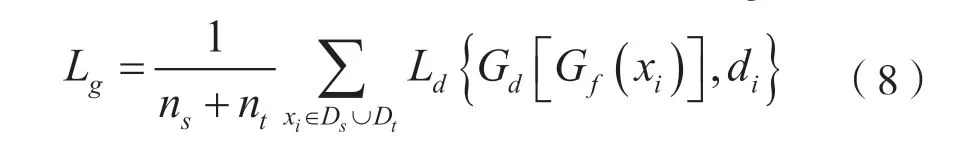
式中,nt是目标域数据量;Dt表示目标域;Ld是源域和目标域中对应的域适应损失;di是伪标签,假设源域是0,目标域是1。和条件分布损失Ll为:

将分类器和判别器的损失和作为DAAN模型的总损失L(θf,θy,θd):
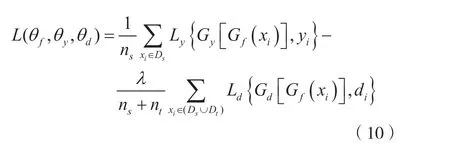
式中,θf、θy、θd分别为特征提取器、分类器、判别器中的可训练参数,λ是平衡参数。
基于注意力机制的长短时动态对抗适配网络(LSTM-TF-at-DAAN)将前人提出的基于注意力机制的长短时记忆(LSTM-TF-at)网络和动态对抗适配网络(DAAN)进行结合,应用于跨库语音情感识别。
2 实验设计和结果分析
2.1 实验设计
实验所使用的数据库描述如表1所示。两数据库中只有5类情感一致,所以从两数据库中选择相同的5种情感(生气、厌恶、害怕、快乐、悲伤)进行跨库识别。又因为深度学习时需要的训练数据较多,而EMO-DB的数据量较少,所以实验只进行eNTERFACE对EMO-DB的跨库识别,而未进行反向识别。
实验使用openSMILE[19]中的特征集The INTER SPEECH 2013 ComParE feature set[20]提取语音特征。提取其中的部分低阶语音特征,见表2,共92维,使每一条语音都变成time×92维的,并将其保存为.csv文件。
将源域的数据放入LSTM-TF-at网络模型中进行训练,为后续将LSTM-TF-at模型的部分层迁移到DAAN模型中做准备。
eNTERFACE在LSTM-TF-at网络训练中最后的正确率达到92.8%。保存训练好的模型参数,用于进行下一步DAAN模型的训练。
将训练好的LSTM-TF-at的模型的前3层(LSTM-at(2),注意时间维(1),注意特征维(1))放入DAAN,将训练好的模型参数一同导入并固定此3层。然后,随机初始化DAAN模型的网络参数进行训练。LSTM-TF-at-DAAN模型参数设置见表3。

表2 低阶语音特征

表3 LSTM-TF-at-DAAN模型参数
最后,分类识别时如果目标域识别出的类别标签少一类别,将目标域中识别为最多的一类进行二次标定,重新给定伪随机标签进行二分类。将此部分数据重新划分为训练集和测试集,按7:3的比例进行划分,使用SVC[21]进行分类,重复分割数据集进行多次测试,并保留最好的结果。实验流程如图2所示。
2.2 实验结果及分析
将eNTERFACE作为源域、EMO-DB作为目标域,LSTM-TF-at-DAAN模型的测试结果和已发表的一般迁移学习[14-16]的测试结果进行比较,结果见表4。

图2 实验流程
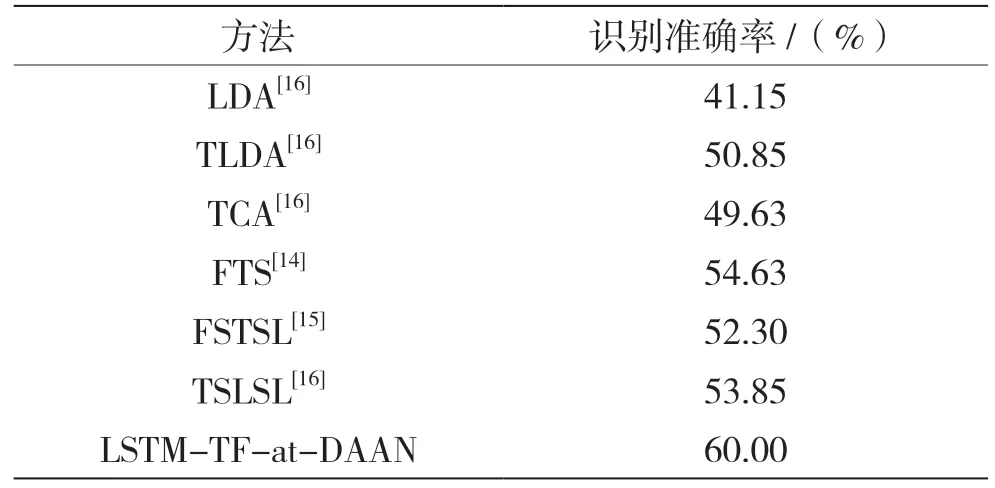
表4 平均识别率比较
通过在eNTERFACE和EMO-DB语料库上的识别率对比发现,在对类别不平衡的小样本语音库EMO-DB的识别中,LSTM-TF-at-DAAN模型较现有的基于一般迁移学习方法的跨库识别,平均识别率提升了5.37%。
3 结语
为了解决跨库语音识别的识别率低的问题,本文提出了基于LSTM-TF-at-DAAN模型进行跨库语音情感识别的方法,通过与已有的迁移学习方法的识别率进行对比,证明了此模型的有效性。本文的实验仅在两个语音库上进行,为近一步验证模型的有效性,下一步将使用更多的数据库进行训练和测试,以提升模型的性能。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
计算机技术与发展(2020年11期)2020-12-04
计算机应用与软件(2020年1期)2020-01-14
计算机测量与控制(2019年4期)2019-05-08
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
青年文学家(2015年29期)2016-05-09
