
改进邻域保持嵌入—独立元分析的间歇过程故障检测算法
2021-05-07 03:40赵小强姚红娟
计算机集成制造系统 2021年4期
赵小强,姚红娟
(1.兰州理工大学 电气工程与信息工程学院,甘肃 兰州 730050;2.甘肃省工业过程先进控制重点实验室,甘肃 兰州 730050;3.兰州理工大学 国家级电气与控制工程实验教学中心,甘肃 兰州 730050)
0 引言
为满足现代社会迅速变化的市场需求,生产小批量、多品种、高附加值产品的间歇过程[1]受到了广泛的关注,注塑、发酵、生物制药、半导体制造等都属于典型的间歇过程。为提高生产效率,生产设备的自动化程度不断提高,使得生产过程的复杂性越来越高,对生产过程的安全、可靠运行提出了更高的要求,因此如何对间歇过程进行及时、准确的故障检测和诊断,以保障其生产安全和产品质量成为工业界和学术界的研究热点[2]。
基于数据的多元统计方法在间歇过程监控中得到了广泛应用[3-4],多向主成分分析(Multiway Principal Component Analysis, MPCA)[5]、多向偏最小二乘(Multiway Partial Least Squares, MPLS)[6]等都是典型的多元统计方法,它们均对降维后的过程数据建立统计模型进行过程监测,但只能提取满足高斯分布数据的二阶统计信息,不适用于对非高斯信息的提取。另一种重要的多元统计方法——多向独立成分分析(Multiway Independent Component Analysis, MICA)[7]无需过程变量满足高斯分布的假设,能够提取过程数据的高阶统计信息,因此被用来解决过程数据的非高斯分布带来的监控效果欠佳的问题[8]。为有效克服快速独立成分分析(Fast Independent Component Analysis, FastICA)算法易陷入局部最优的问题,文献[9]提出了基于粒子群优化的ICA算法,通过优化的负熵最大化方法对独立成分进行估计,能够表现出更好的分离效果;文献[10]首先采用核熵成分分析(Kernel Entropy Component Analysis, KECA)对数据进行白化处理,然后利用ICA对白化向量进行非高斯成分提取,从而解决过程监控中非线性与非高斯共存的问题。但无论是提取数据高斯信息的PCA算法还是关注非高斯信息的ICA算法,在用于过程监测时都需要过程数据符合高斯或者非高斯分布的假设。但实际工业过程数据往往并不满足单一分布的假设,而是高斯与非高斯的混合分布,因此单一监控方法往往会损失一些重要信息,而使其监控效果欠佳。为此,国内外学者将PCA和ICA算法结合,提出一些解决过程数据复杂分布的扩展方法:Ge等[11]提出了结合相似性因素的ICA-PCA的两步信息提取策略;衷路生等[12]提出了分布式ICA-PCA的故障检测方法,根据非相关性将原始数据空间自动划分为不同子块,对各个子块利用ICA-PCA进行特征提取。以上方法在一定程度上提高了间歇过程故障检测效果,但是没有考虑数据的非线性结构,且忽略了数据的局部流行结构,用关注全局信息的线性扩展算法去提取非线性与复杂分布特性共存的间歇过程数据特征,必然造成一些重要信息丢失,从而不能得到令人满意的监控效果。
邻域保持嵌入(Neighborhood Preserving Embedding, NPE)算法由于能够在降维的同时保持数据的局部流行结构而被广泛应用于高维数据的特征提取中[13-14],它能够发倔出隐藏于原始高维数据中更多的本质信息。NPE算法虽然能够通过近邻点重构样本点获得数据的局部特征,但工业过程数据分布复杂,仅用NPE难以对具有多分布、非线性等复杂特性的工业过程得到满意的监控效果。因此,学者们对NPE进行了一系列改进,Jiang等[15]将概率加权策略与NPE算法结合用于化工过程监测,提高了故障检测率;杨健等[16]考虑数据之间的时序相关性,提出了时序约束NPE算法,克服了过程数据动态性带来的监控效果不佳的问题;赵小强等[17]针对NPE算法忽略全局结构的缺陷,建立了提取全局—局部信息的目标函数,在提取数据局部信息的同时兼顾全局结构,改善了间歇故障检测效果;为了能够对非线性数据有效地提取特征,Tao等[18]提出了核邻域保持嵌入算法(Kernel NPE, KNPE),但基于核的特征提取能力受到核参数的影响,且核参数的选择也是个难题。
因此,本文针对间歇过程数据的强非线性以及高斯与非高斯混合分布的特性带来的故障检测效果欠佳的问题,提出了基于多向差分邻域保持嵌入—加权差分独立元分析(Multiway Differencial Neighborhood Preserving Embedding-Weighted and Differencial Independent Component Analysis, MDNPE-WDICA)的间歇过程故障检测算法。首先通过J-B test方法将原始数据空间划分为高斯子空间和非高斯子空间;然后通过MDNPE算法提取高斯子空间数据的局部流行结构,并处理数据的非线性,通过T2和SPE两个统计量完成对高斯子空间的监测;接着利用WDICA算法提取非高斯子空间数据的非高斯与高阶统计量信息的同时处理其非线性,通过I2和SPE两个统计量完成对非高斯子空间的监测;最后通过贝叶斯推断构造出联合统计量,完成整个间歇过程监控。
1 基本算法
1.1 邻域保持嵌入(NPE)
邻域保持嵌入(NPE)算法是由He等[19]提出的一种局部流行学习算法,通过求解特征映射A(a1,…,ad),将RM空间数据X(x1,…,xN)映射到特征空间Y={y1,…yN},{yi|yi∈Rm}(m≤M)中,且满足Y=AΤX。NPE首先利用k近邻法(kNN)为每个数据点寻找k近邻,通过近邻点线性重构数据点构造重构系数矩阵W,定义重构误差为:
(1)
式中:N为样本点数;wij为样本点xi的第j个近邻点的重构系数。
NPE算法的思想是在高维空间中重构数据点xi的重构系数wij,以此在低维空间中重构对应的数据点yi。因此,特征映射A通过求解式(2)的最优解得到:
(I-W)y=aΤX(I-W)Τ(I-W)XΤa
=aΤXMXΤa。
(2)
式中:M=(I-W)Τ(I-W),约束条件为yΤy=aΤXXΤaΤ=1。
通过简单的代数运算,式(2)的优化问题最终转换为如下的广义特征值求解问题:
XMXΤa=λXXΤa。
(3)
求解获得最小的m个特征值,其对应的特征向量构成特征映射矩阵A。
1.2 独立成分分析(ICA)
独立主元(ICA)算法是一种能够将隐藏于混合信号(x1,x2,…,xM)中的未知独立源信号(s1,s2,…,sM)分离出来的方法,其模型为:
X=AS+E。
(4)
式中:X∈RM×N为观测数据,A∈RM×m为未知混合矩阵,S∈Rm×N(m≤M)为独立元矩阵,E为误差矩阵。
ICA的目标是通过寻找一个分离矩阵W,从观测信号中估计出独立源信号,即

(5)

2 基于MDNPE-WDICA的监控策略
2.1 基于J-B检验的高斯与非高斯划分
间歇过程数据分布复杂,不再服从单一的高斯或者非高斯分布。因此,本文采用Jarque-Bera检验方法将原始数据空间变量进行高斯与非高斯划分,随机变量x的N个样本分别表示为x1,…,xN,定义样本的偏度系数b1和峰度系数b2分别为:
(6)
(7)

理想状态下,若随机变量x服从正态分布,则b1=0,b2=3。于是,JB统计量被构造为:
(8)
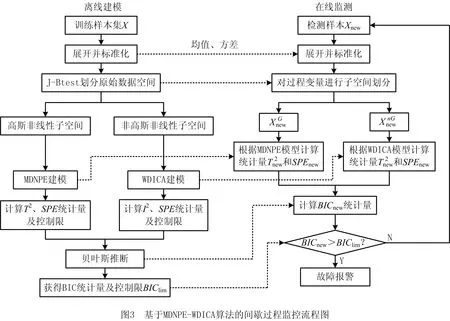
由式(8)可知,理想状态下,若变量服从正态分布,其JB统计量的值为零;反之,JB统计量将为一个逐渐增大的值。按式(8)计算出每个变量数据的JB统计量,然后基于显著性水平α1和采样点数N得到阈值JBα1,当JB X=[XGanssiansubspace,XnonGanssiansubspace]。 (9) NPE作为一种线性降维算法,能够在降维的同时保持数据的局部结构不变。与PCA算法相比,NPE算法能够发掘隐藏在原始高维数据中更多的本质信息,但工业过程数据具有非线性,用NPE算法处理必将丢失一些重要信息;而核方法是处理数据非线性的常用传统方法,它将原始数据映射到一个高维的特征空间,并在映射的过程中寻求一种线性关系,能够有效地处理数据的非线性,但由于其引入了核函数而使计算复杂,导致在线监测的实时性下降,不能及时检测到故障的发生。差分策略[20]不但能够处理数据的非线性,而且计算简单。下面通过一个非线性数值例子[21]来说明差分策略的非线性处理能力。 x=t+e1,y=t2+e2。 (10) 其中:t服从均匀分布,e1和e2均为高斯白噪声。 根据式(10)产生400个二维原始数据,其散点图如图1所示。从图1中可以看出,图像呈抛物线形状,是典型的非线性,对原始数据进行差分处理后,其散点分布图如图2所示。从图2中可以看出,经过差分处理后,除个别离群点,图像近似呈现出直线形状,即变量y和变量x之间的非线性关系经过差分策略处理后,转换成了线性关系,从而验证了差分策略的非线性处理能力。 本文将差分策略与NPE算法结合,提出差分邻域保持嵌入(MDNPE)算法,首先寻找样本点的最近邻,将其与样本点进行差分运算,通过这种转换将非线性问题转化为差分空间的线性问题,然后利用NPE算法在高维差分空间充分提取数据的局部结构特征来建模,MDNPE算法能够在充分提取原始数据局部流行结构的同时有效地解决数据的非线性,且与传统基于核的非线性方法相比,能够大大减少计算量,进而提高对间歇过程在线检测的实时性。 (11) 对样本空间中每个数据点进行如式(11)差分处理后,得到差分矩阵: (12) 然后在样本差分空间中寻找差分样本近邻点,通过近邻点重构样本点,并定义重构误差为: (13) 最后,通过求解式(14)的广义特征值问题,得到最小的m个特征值对应的特征向量构成特征映射矩阵Ad(a1,a2,…,am) (14) MDNPE算法将高斯非线性空间划分为特征空间和残差空间,构造T2和SPE统计量分别对特征空间和残差空间进行监控。对于新来的数据xnew,通过MDNPE算法获得其低维表示ynew,则与ynew对应的T2和SPE统计量可通过式(15)、式(16)计算: T2=ynewΛ-1ynew; (15) SPE=‖xnew-Aynew‖2。 (16) 其中Λ表示Y的样本协方差矩阵。 由于高斯非线性子空间的数据必然满足高斯分布,统计量的置信限在置信度α下用经验分布计算得到。 ICA作为一种提取全局特征的线性算法,能够充分发掘数据的非高斯和高阶统计信息,但ICA算法未考虑数据的非线性,且在特征提取时忽略了数据的局部信息,因此本文提出了加权差分独立成分分析(WDICA)算法。首先将原始数据进行加权差分处理,解决数据的非线性,并充分利用数据的局部结构,得到加权差分矩阵Xwd;然后对Xwd进行奇异值分解得到白化向量;最后通过ICA算法充分提取非高斯子空间信息来进行建模。WDICA算法能够在充分提取非高斯信息的同时处理数据的非线性,从而提高非高斯子空间监控效果。 (17) 式(17)中权值 (18) 由式(17)可以得到加权差分矩阵Xwd,计算其协方差矩阵: (19) 对协方差矩阵V进行奇异值分解: V=UDUΤ。 (20) 选取白化向量: Z=QX。 (21) 由式(4)和式(21)可得Z=QX=QAS=BS,其中B=QA为正交矩阵。于是,独立元估计值为: (22) 通过FastICA算法求出B,从而得到分离矩阵W=BΤQ。 WDICA算法将非高斯非线性子空间划分为独立元空间和残差空间后,分别用I2和SPE统计量进行监控,定义如下 I2(xi)=s(xi)Τs(xi); (23) (24) 最后,通过核密度估计(KDE)确定统计量置信限。 对原始空间进行空间划分后,需要对每个子空间进行建模,以得到相应的统计量和控制限,从而实现对每个子空间的在线监控。为了在监测时对间歇过程进行整体考虑,实现对高斯与非高斯成分均能充分提取,通过贝叶斯推断建立一个统一的统计量,并获得相应的控制限,以实现对整个间歇过程的监控。在非高斯非线性空间XnG定义I2统计量的故障概率为: (25) 式中:Ν和F分别表示正常和故障工况;PI2N=α2,PI2F=1-α2,α2为置信水平。PI2(XnG|N)和PI2(XnG|F)计算如下: (26) 同样地,可以计算获得PT2(F|XG)、PSPE(F|XG)和PSPE(F|XnG),最终BIC统计量被构造为: BIC= (27) BIC统计量的置信限为1-α2,本文取α2=95%。 基于MDNPE-WDICA的间歇过程故障检测包括离线建模和在线监测两个阶段,如图3所示。 (1)离线建模步骤 步骤1采集多批正常工况数据,得到三维数据矩阵X(I×J×K)。其中:I表示批次数,J表示变量数,K表示每一批次的采样点数。将X按批次方向展开并标准化,得到二维矩阵X(I×JK),再将其沿变量方向展开为矩阵X(IK×J)。 步骤2利用式(8)计算每个变量的JB统计量,将其与阈值JBα1比较,得到如式(9)所示的高斯与非高斯子空间。 步骤4对被J-Btest划分到非高斯子空间的变量数据,首先根据式(17)计算得加权差分矩阵;然后将其进行白化处理,利用式(22)得到分离矩阵W和独立元矩阵S;最后根据式(23)和式(24)计算非高斯子空间数据的I2和SPE统计量,并通过核密度估计得到其控制限。 步骤5通过式(27)将高斯子空间T2与SPE统计量和非高斯子空间I2与SPE统计量构造成一个统一的统计量BIC,并计算其控制限BIClim。 (2)在线监测步骤 步骤1将检测样本Xnew(1×J×K)按批次展开得到Xnew(1×JK),对其按照正常工况数据的均值和方差进行标准化处理,然后将其按变量展开为Xnew(K×J)。 步骤5根据式(27)计算xnew联合统计量BICnew,当BICnew的值超过其控制限,表明间歇过程发生故障,否则正常。 青霉素生产制备过程是典型的具有非线性、高斯与非高斯混合分布等特性的间歇生产过程。本文采用美国Illinois州立理工学院于2002年开发的青霉素仿真平台Pensim 2.0[22]产生间歇过程数据,用以间歇过程故障检测研究。该仿真平台通过设置不同但都在正常范围的初始条件,产生多批次数据,设定每批次的反应时间为400 h,采样时间为1 h,共产生30批正常操作数据,并选择其中的16个过程变量作为监控变量(如表1)构成三维数据矩阵X(30×16×400)用于建模。另外,为了模拟实际过程变量的扰动,所有测量变量均加入了高斯白噪声。Pensim 2.0仿真平台除了产生正常工况数据外还提供了通风速率、搅拌功率、底物流加速度三类故障,用以产生故障工况数据,本文引入的故障种类及其参数设置如表2所示。 表1 监控变量 表2 不同参数下的故障类型 本文选取30批数据中的其中一批数据利用JB统计量对其16个过程变量进行高斯与非高斯划分,取显著性水平α1=0.05,将编号为1、3、5、9、10、12、13的变量划分到高斯子空间,编号为2、4、6、7、8、11、14、15、16的变量划分到了非高斯子空间。 核主成分分析(KPCA)[23]、核邻域保持嵌入(KNPE)[24]均为经典的基于核的非线性特征提取方法,多向差分局部保持投影(multiway Differencial Locality Preserving Projections, DLPP)[20]是近年来提出用于非线性过程故障检测的方法,与基于核的方法相比,其运算量较小且具有更好的故障检测效果,多向主成分分析—独立成分分析(multiway PCA-ICA, MPCA-ICA)[25]考虑到化工过程的高斯与非高斯混合分布特性,将原始数据空间划分为高斯、非高斯子空间后,分别用PCA和ICA算法对两个子空间进行特征提取,通过两步提取策略提高了故障检测率。下面采用KPCA算法、KNPE算法、DLPP算法、MPCA-ICA算法以及本文所提算法分别对表2中4种故障工况下的过程数据进行监控,检测结果如表3所示。 表3 不同方法的故障检测率 % 由表3可知,本文所提算法相比于其他4种算法对4种故障均有更好的故障检测效果,从而验证了本文所提算法在间歇过程故障检测中的有效性。为了进一步说明本文所提算法的有效性,给出5种算法在表2中故障1工况下(对通风速率在采样点150~250之间加入10%的阶跃信号作为故障信号)的监控图,如图4~图11所示。图中实线代表检测数据的统计量值,虚线代表统计量控制限。在故障阶段(采样点150~250),理想的图形特征为所有采样点统计量值均在控制限以上,若某采样点的统计量值未超出控制限,则表明算法未检测出该采样点存在的故障,即出现了漏报警;在正常工作阶段(采样点0~150和250~400),理想的图形特征为所有采样点的统计量值均在控制限以下,若某采样点的统计量值超出控制限,则表明算法对没有故障的采样点发出了警报,即出现了误报警。 KPCA的T2和SPE统计量监控图如图4和图5所示。从两图中可知,KPCA算法的T2统计量只在采样点150、160以及250三处检测到故障,且在20~40点之间出现误报警。SPE统计量虽然能够检测到大部分采样点的故障,但在正常阶段,大量采样点统计量值超出控制限,即存在大量误报警;图6和图7为KNPE的T2和SPE统计量监控图,从两图中可以看出,KNPE算法对故障较为敏感,除少量采样点的统计量值低于控制限,大部分采样点的故障均可以被检测到,但在正常阶段,大量采样点的统计量值超过控制限,即存在大量的误报警;图8和图9为DLPP的T2和SPE统计量监控图,从两图中可以看出,相比于基于核方法的KPCA和KNPE算法,DLPP算法表现出较好的检测效果,其SPE统计量的检测率达到了100%,但在采样点0~150之间,统计量值超越控制限,即出现了误报警。 图10为MPCA-ICA的统计量监控图,该算法考虑了间歇过程的高斯与非高斯混合分布特性,通过PCA和ICA分别提取了原始空间的高斯成分与非高斯成分,提高了故障检测率,但由于其未考虑数据的非线性特性且提取的只是数据的全局结构,导致在采样点10~120以及280~380之间,有部分采样点统计量超过控制限,即出现了较多误报警;图11为本文所提算法的统计量监控图,可以看出,本文所提算法能够完全检测到故障的发生,并在第250点开始故障消除后,采样点统计量值能够回到低于控制限的正常水平上,即本文算法能够准确检测出故障的发生与消除,且与其他算法相比,具有最少的误报警。由此可知,本文所提算法具有更好的故障检测效果。 间歇过程具有比连续过程更加复杂的过程特性,这些复杂特性的存在影响了间歇过程故障检测的效果。本文提出的基于MDNPE-WDICA的故障检测算法能够克服间歇过程数据的非线性以及高斯与非高斯混合分布特性共存造成的故障检测率较低的问题。首先通过J-B test方法将原始数据空间划分为高斯子空间与非高斯子空间,然后通过对不同子空间采用不同方法进行建模,充分提取各个子空间数据的特征结构,最后通过贝叶斯推断构造出的联合统计量监控整个间歇过程。将本文算法应用到青霉素生产制备过程中,检测效果优于KPCA、KNPE、DLPP以及MICA-PCA方法,进一步验证了本文算法的有效性。由于本文研究的是非线性以及高斯与非高斯混合分布数据特点下的间歇过程故障监测问题,而实际过程中可能会出现更复杂的情况,如非线性、非高斯、多模态、动态性等多种特征并存的情况,这是下一步需要进行的研究工作,并可以尝试应用到注塑、发酵和生物制药等间歇过程中。2.2 MDNPE的高斯非线性子空间建模


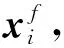

2.3 WDICA的非高斯非线性子空间建模

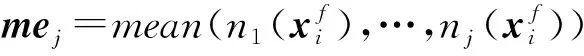


2.4 基于贝叶斯推断建立联合统计量
2.5 基于MDNPE-WDICA的监控步骤



3 案例研究及分析











4 结束语
猜你喜欢
煤气与热力(2022年4期)2022-05-23
新世纪智能(数学备考)(2021年5期)2021-07-28
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
浙江大学学报(工学版)(2016年2期)2016-06-05
电影故事(2015年16期)2015-07-14
信息安全研究(2015年3期)2015-02-28
安徽工业大学学报(自然科学版)(2014年4期)2014-07-11
太空探索(2014年1期)2014-07-10
中国中医药现代远程教育(2014年20期)2014-03-01
