
基于高光谱成像技术的大米溯源研究
2021-05-07 09:55:04罗浩东刘翠玲孙晓荣吴静珠
中国酿造 2021年4期
罗浩东,刘翠玲*,孙晓荣,吴静珠
(北京工商大学 人工智能学院 食品安全大数据技术北京市重点实验室,北京 100048)
中国是世界大米生产和消费的大国之一,大米是中国主要的粮食产物之一。中国大米产地繁多,不同产地的大米口感、营养价值及品质均具有明显差异[1-2]。随着人们生活水平的不断提高,人们对大米的产地以及品质越来越重视。由于大米因外观及品质方面难以用肉眼检测,一些不法商贩将劣质大米混入其中,以次充好,牟取暴利,使得大米掺假问题日益严重[3]。传统的检测方法(如感官识别、近红外光谱等)均有一定劣势和不足。如感官识别受到主观因素影响,检测结果的准确性和稳定性并不高。近红外光谱法需要对大米进行研磨粉碎[4-5],使得进行检测的大米样本不能进行后续的使用[6]。
高光谱成像技术结合了近红外光谱和数字成像技术,具有高速、无损、精度高的特点,使样本避免被破坏,被广泛应用于食品检测领域[7-9]。PEREZ-RODRIGUEZ M等[10]利用基于支持向量机(support vector machine,SVM)的预测模型,建立了一种简单、快速、高效的火花放电激光诱导击穿光谱方法。对四个水稻品种(古里、IRGA424、普伊特和塔伊姆)的72个样品进行分析,得到了按植物品种鉴别水稻样品的最佳模型。该模型在试验样本中的正确预测率达到了96.4%。JI M等[11]基于高光谱成像技术建立的最小二乘支持向量机模型对猪肉中的不饱和脂肪酸包括单不饱和脂肪酸和多不饱和脂肪酸进行了检测,并绘制了单不饱和脂肪酸和多不饱和脂肪酸含量的彩色图,取得了良好的实验结果。吴宝婷等[12]利用高光谱技术对灵武枣发酵过程中pH值和总酸含量进行了定量分析,结合竞争性自适应加权算法(competitive adaptive reweighting sampling,CARS)和遗传算法(genetic algorithm,GA)进行特征波段的筛选,进而建立偏最小二乘定量分析模型。结果表明,高光谱技术可以对灵武枣发酵过程中pH值和总酸含量进行定量预测。可见,高光谱成像技术已经广泛应用于食品检测的各个领域,而大米产地溯源领域的报道并不是很多。
王璐[13]采用随机方法对大米样品进行训练集和测试集的划分,根据训练集中样本大米的平均光谱建立了最小二乘支持向量机(least squares support veotor maohine,LS-SVM)分类模型。选取正交信号校正法(orthogonal signal correction,OSC)作为光谱预处理方法,并利用连续投影算法(successive projections algorithm,SPA)提取特征波段建立大米产地分类模型,分类结果为95.36%。王靖会等[14]采集了吉林省梅河口市水稻主产区及松原、大安、辉南等其他水稻产区共990个大米样本的高光谱图像作为研究对象,利用多元散射校正(multiple scattering correction,MSC)处理方法对光谱进行了预处理。采用了多层感知机(multilayer perceptron,MLP)、极限学习机(extreme learning ma chine,ELM)与在线序列极限学习机(online sequence extreme learning machine,OS-ELM)算法,分别基于全波段高光谱数据建立产地溯源模型。实验结果表明,OS-ELM模型分类效果最好,可以准确的进行大米产地的溯源。市场上大米产地来源极多,造成东北大米掺假问题严重。东北大米来源于多个产地,品种不一,不同产地的东北大米也存在着形态、成分组成等差异。再加上高光谱数据信息量丰富,但一些相关性不强的光谱信息会影响预测模型的准确性,容易造成信息冗余,这就为应用高光谱技术建立大米产地溯源造成了干扰和困难[15-16]。
本研分以大米产地的溯源为出发点,使用高光谱成像技术,以来源于5种东北和5种非东北的大米作为样本集,对大米的产地进行溯源研究。通过主成分分析法(principal component analysis,PCA)进行主成分提取,实现高光谱数据降维,避免信息冗余[17-18]。采用SVM建立大米产地溯源模型,旨在对市场中流通的大米产地进行快速、准确的判别。
1 材料与方法
1.1 材料与试剂
黑龙江长粒香、吉林稻花香、圆粒香以及辽宁小町米(2种):北京古船米业有限公司;江苏长粒香、小町米、河北小町米、安徽小町米以及浙江圆粒香:浙江农业科学院。
1.2 仪器与设备
SISUCHEMA-SWIR高光谱成像系统:芬兰SPECIM公司。
1.3 方法
1.3.1 大米高光谱技术路线及操作要点
预热→调距→调参→扫描
预热:开启高光谱成像系统预热30 min以上。
调距:调整载物台的距离,确保激光可以穿过大米样品。调整镜头与大米样品的距离,确保所有大米样品进入高光谱成像系统扫描范围。
调参:经过调整参数,确保大米样品像素最清晰。将采集过程中的曝光时间设为3.8 μs,帧率为50 Hz。
将100颗同一产地的大米样本放于板上以便高光谱仪器进行扫描。
1.3.2 感兴趣区域的提取
感兴趣区域提取就是将大米样本的高光谱图像中的目标区域进行提取,因每个像素点的光谱信息不同,目标区域的大小、位置都会对实验数据造成影响。使用ENVI4.8按照大米样本的轮廓,手动提取感兴趣区域,并将感兴趣区域内所有像素点的平均光谱作为大米样本的光谱信息,最后得到10种大米的高光谱数据。
1.3.3 大米检测图像的校正
由于高光谱采集样本数据时光源强度不均匀以及摄像头中暗电流存在,会对图像采集产生较大的噪声,导致光谱信息不准确[19]。为了对图像进行修正,消除噪声的影响,必须对原始的高光谱采集数据进行黑白板校正[20]。高光谱图像的黑白板校正利用(1-1)在ENVI4.8中处理完成。

式中:Rc为相对反射率图像;R0为原始反射率图像;RW为白色参考图像;RB为黑色参考图像。
一是“好教育进行时”促进了各区、各校对好教育的思考,各区、各校、个人都对好教育有自己的理解和追求,对好学校、好校长、好教师、好学生也有了更新、更深的思考,这种教育观、学校观、教师观、学生观、质量观的更新,对教育的改革创新意义重大。
1.3.4 数据集划分
在Matlbe2016环境下进行样本集的划分,采用X-Y距离样本集算法,将大米样本分为测试集和训练集,测试集和训练集比例为4∶1,其中800个大米作为测试集,剩下的200个大米作为训练集。
2 结果与分析
2.1 主成分分析法和变量相关性分析
计算变量间相关性,画出各波段对应的相关系数曲线图,结果如图1所示。由图1可知,波段之间的吸光度值基本在0.8以上,对全波段进行主成分降维。
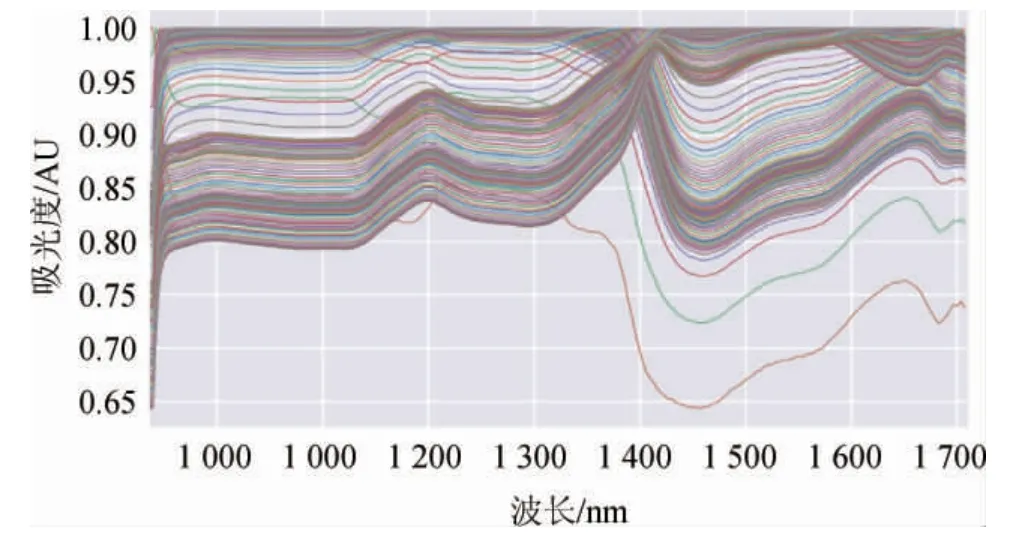
图1 相关系数曲线图Fig.1 Curve graph of correlation coefficient
2.2 全波段主成分分析
PCA是一种非监督模式识别算法,可以降低高光谱数据的维数,提高模型工作效率,同时增强大米相关信息并降低干扰信号。全波段成分的方差贡献率如表1所示。由表1可知,当4个主成分时,主成分累计方差贡献率达到99.9%,因此选取第4 个主成分作为特征。

表1 主成分分析贡献率统计结果Table 1 Statistics results of contribution rate of principal component analysis
2.3 预测模型的建立与结果
SVM是一种以结构风险最小化的学习型算法。其优势是实现数据的降维,克服了传统机器学习的维数灾难问题[21]。在小样本数据集中的分类具有显著优势。SVM的中心思想是构造支持向量机Xi和输入层Xn之间的内积核。K(X,Xn)为核函数,能产生重要作用的是惩罚参数c。
本次建模使用了线性函数(linear)和高斯函数(radial),核函数是线性函数时,当C=0.011时,准确率为78%。核函数是高斯函数(radial)时,准确率最大值为57%,比线性函数小,因此选择线性函数最优参数进行建模。
在R-4.0.2上进行实验建模分析。将来自东北大米的黑龙江长粒香、吉林稻花香、圆粒香以及辽宁小町米归为一类(ALL)。非东北大米有:江苏长粒香(SU01)、江苏小町米(FX17APC)、河北小町米(HBTS)、安徽小町米(HUI)以及浙江圆粒香(ZJ01)。训练集实验结果如表2所示。由表2可知,使用训练集中的800个大米样品高光谱数据进行模型的建立,除江苏长粒香外,其他种类大米的训练集预测准确率达到了98%以上。
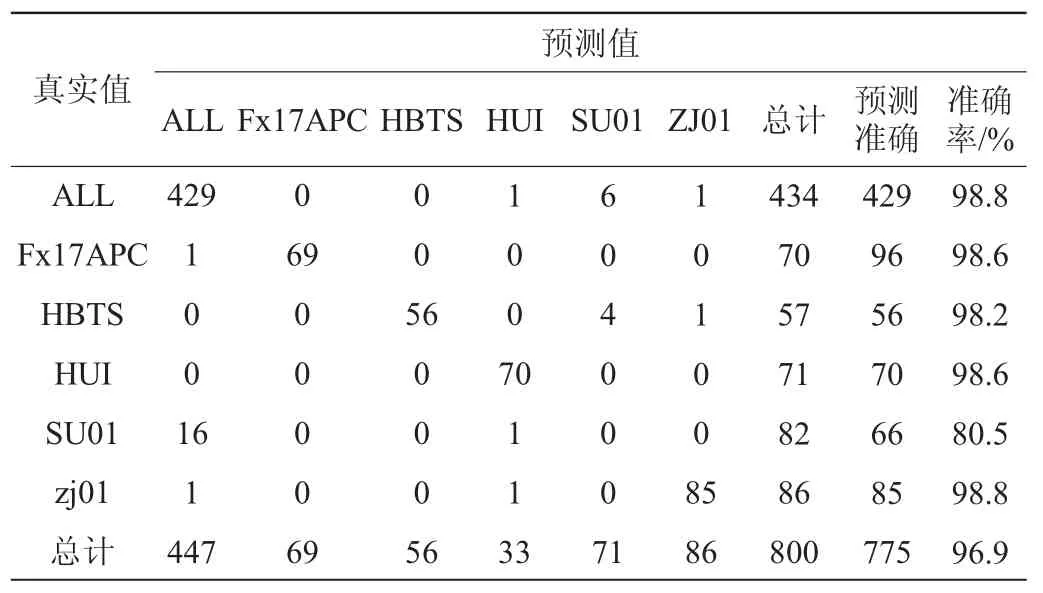
表2 大米产地溯源训练集结果Table 2 Result of the training set of rice origin traceability
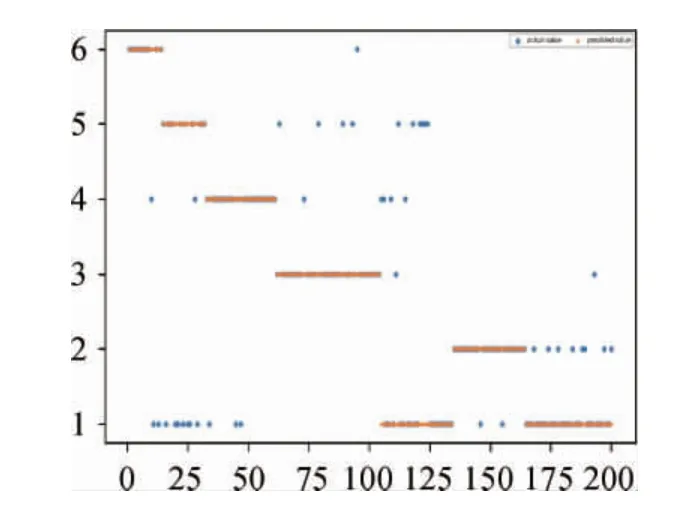
图2 测试集的结果Fig.2 Result of test set
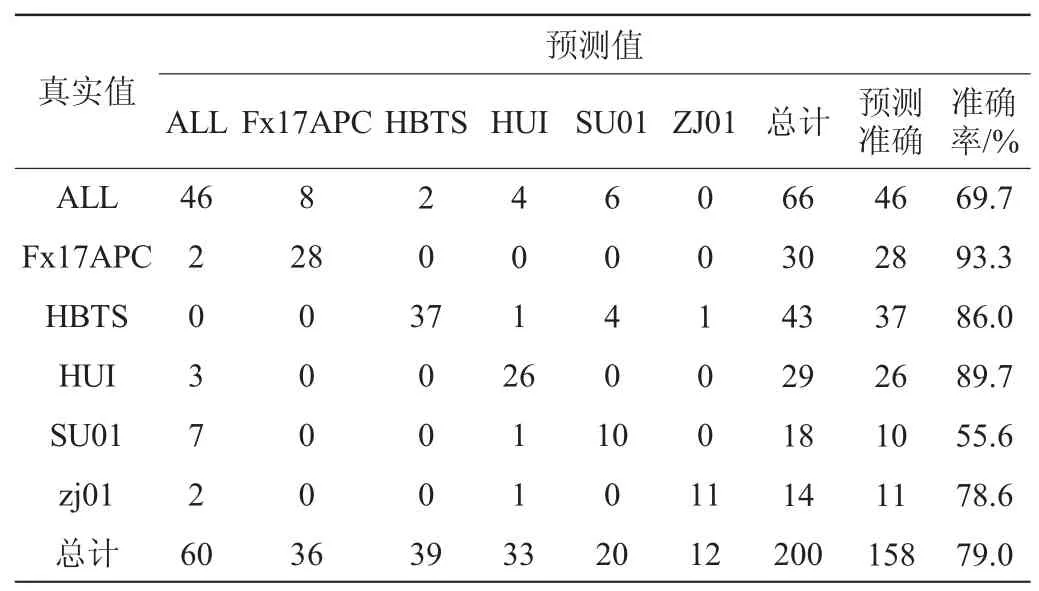
表3 大米产地溯源测试结果Table 3 Result of rice origin traceability test
由表3可知,江苏小町米(FX17APC)的判断准确率最高,达到了93.3%。河北小町米(HBTS)、安徽小町米(HUI)以及浙江圆粒香(ZJ01)判断准确率在80%左右,而江苏长粒香(SU01)的预测准确率偏低,江苏长粒香的高光谱信息和东北地区大米样品高光谱信息较为接近,使得模型预测结果产生偏差。整体大米溯源预测模型准确率为79%,结果表明高光谱成像技术可以用于大米产地的溯源。
3 结论
采用主成分分析法前几个主成分就已经包含了样品大部分信息,因此比较前几个主成分的贡献率,其中第4主成分累计方差贡献率为99.9%,故采用第4主成分建立大米产地溯源模型。
SVM的中心思想是构造支持向量机内积核。能够对核函数产生重要作用的是惩罚参数c。c表示的是对误差的宽容度,c值越高,说明对误差容忍度越小,过高容易出现过拟合现象。c值过低,容易出现欠拟合的情况。因此c值过大过小都会影响最终模型预测结果。当采用线性函数时,c=0.011时,准确率为78%时,最终模型预测结果较好。
采用主成分分析法(PCA)对高光谱数据的主成分进行了提取,并结合支持向量机(SVM)建立了大米产地溯源预测模型。以提取的第4主成分建立的模型质量有所优化。不仅降低了建模的复杂程度,解决了光谱信息冗余问题,并且提高了模型预测效率,预测准确性以及稳定性。通过预测结果可以发现,高光谱信息较为相近的大米溯源会有一定误差,有待进一步数据处理进行大米产地溯源判断。实验结果表明,高光谱成像技术可以实现对大米产地溯源的快速、准确预测,在大米产地溯源具有广阔的应用前景。
猜你喜欢
中国农机化学报(2023年12期)2023-04-29 22:48:41
北京航空航天大学学报(2022年8期)2022-08-31 08:58:58
江苏农业科学(2019年6期)2019-09-25 04:23:19
中国外汇(2019年22期)2019-05-21 03:14:56
意林·全彩Color(2018年9期)2018-10-12 01:06:54
中成药(2018年8期)2018-08-29 01:28:16
绿色科技(2017年20期)2017-11-10 18:54:19
兽医导刊(2016年6期)2016-05-17 03:50:58
中国光学(2015年5期)2015-12-09 09:00:28
软件导刊(2015年1期)2015-03-02 12:02:05
