
基于属性基隐私信息检索的位置隐私保护方法
2021-05-06 12:10:58杜刚张国印
哈尔滨工程大学学报 2021年5期
杜刚, 张 张国印
(1.哈尔滨工程大学 计算机科学与技术学院,黑龙江 哈尔滨 150001; 2.佳木斯大学 信息电子技术学院,黑龙江 佳木斯 154007; 3.山东科技大学 计算机科学与工程学院,山东 青岛 266590)
随着基于位置服务(location based service, LBS)的广泛应用,越来越多的人们开始关注该服务中的隐私泄露问题[1-2]。当前较为普遍的隐私保护方法有泛化[3- 4]、模糊[5-6]、加密[7-8]以及空间变换[9]等,但上述方法都面临同样的问题,即在LBS服务器提供服务的过程中不可避免地要获知用户的真实意图,进而可根据诸如兴趣点类型、查询种类等信息分析获得用户隐私。隐私信息检索(private information retrieval, PIR)是应对这种潜在隐私泄露的有效办法[10-11]。该方法对LBS服务器中的数据加密,通过二进制的可计算PIR和硬件PIR实现零信息泄露的结果检索。Wightman等[12]根据这一观点,基于经纬度的地理差异,提出了基于地图查询的PIR。杨松涛等[13]基于该技术建立了基于位置服务的盲查询方法。
但是,由于基于位置服务本身的特性,使得这种以索引为基础的隐私信息检索在执行过程中需搜寻较大规模的数据条目,这增加了反馈结果的处理时间,影响了服务质量[14]。Hu等[15]提出用分层索引提升索引效率。Yi等[16]则提出了模糊索引的概念。通常情况下,基于位置服务是一种针对用户提交信息进行反馈的服务,其反馈结果主要针对用户属性信息获得的查询结果[17-18]。因此,使用属性作为索引进行隐私信息检索将会减少处理数据量,提高检索效率,减少对服务质量的影响。基于上述观点,本文基于属性基加密提出了一种可应用于位置隐私保护的属性基PIR方法,该方法在有效的保护用户隐私信息的同时,能给提供比索引为基础的隐私信息检索方法更好的服务质量。最后,通过安全性分析和比较实验,进一步证明本文所提出的方法在隐私保护能力方面和算法执行效率方面的优越性。
1 隐私保护相关定义
1.1 系统架构及攻击假设
与传统隐私保护方法不同,基于隐私信息检索的位置隐私保护方法并不需要可信或非可信第三方,因此该方法采用如图1所示的二层系统架构。

图1 二层系统架构示意Fig.1 The system structure of two entities
从图1中可以看出,该架构中存在2个实体,即用户和LBS服务器。用户是指在固定位置或移动过程中,通过自身设备向LBS服务器请求服务的使用者;而LBS服务器是在获得用户请求信息后向用户提供服务结果的服务提供者。通常,LBS服务器由政府或大型企业提供因此是真实可信的,但所有信息均由该实体处理,使得该实体易成为攻击焦点,且在巨大商业利益诱惑下存在泄露用户隐私的可能。因此,本文假设该实体为半可信实体,既能够提供位置服务,又可对用户隐私信息进行收集并分析,因此需将用户信息隐藏防止LBS服务器获得用户隐私。
1.2 隐私保护需求
针对1.1中给出的以LBS服务器为潜在攻击者的攻击假设,若需保护用户的隐私信息,在整个基于位置服务的过程中需降低对LBS服务器的信息公布量,同时还需要获得所需要的查询服务结果。因此,基于用户属性特点,有如下隐私保护和服务需求:
1) LBS服务器无法准确识别由用户查询信息转化的属性信息;
2) LBS服务器能够根据用户提交的加密查询信息反馈查询结果;
3) 隐私处理以及服务获取过程应在用户可接受时间范围内完成。
基于上述需求,本文设计并提出了隐私保护方法。
2 属性基PIR方法及算法
2.1 属性基PIR方法
通常,用户请求基于位置服务反馈时需向LBS服务器提交查询,该查询一般为:距离我最近的饭店、当前道路上的加油站或者到某酒店的最短路程等。这些信息可形式化为Q={(x,y),t,c},其中(x,y)为用户所在位置,t为提出查询的时间,c为查询的内容。因此,上述信息可以用用户属性加以代替,即存在用户属性A={A1,A2,…,An}中的每一个属性对应查询中的一个形式化表述内容。因此,上述查询的隐私保护可转换为用户属性隐私信息检索,并解密反馈信息的处理过程。这一过程可表示为如图2所示的LBS服务器和用户之间的信息传递协议。
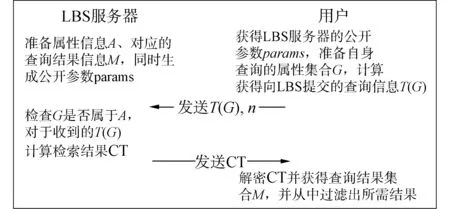
图2 属性基PIR传递协议Fig.2 The protocol of attribute based PIR
2.2 属性基PIR方法执行过程
按照属性基PIR的处理协议,隐私检索方法存在2个处理阶段,分别为LBS服务器信息处理和用户信息处理。为便于对属性PIR的理解,本文借鉴文献[12]所提供的隐私信息检索方法,将这2个阶段按照时间顺序加以表述。为便于理解,表1给出了属性PIR处理中所使用的参数及所表示的含义。
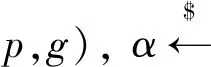
式中:g是G的生成器,G是p阶大素数循环群,F(·)是多项式时间概率算法。
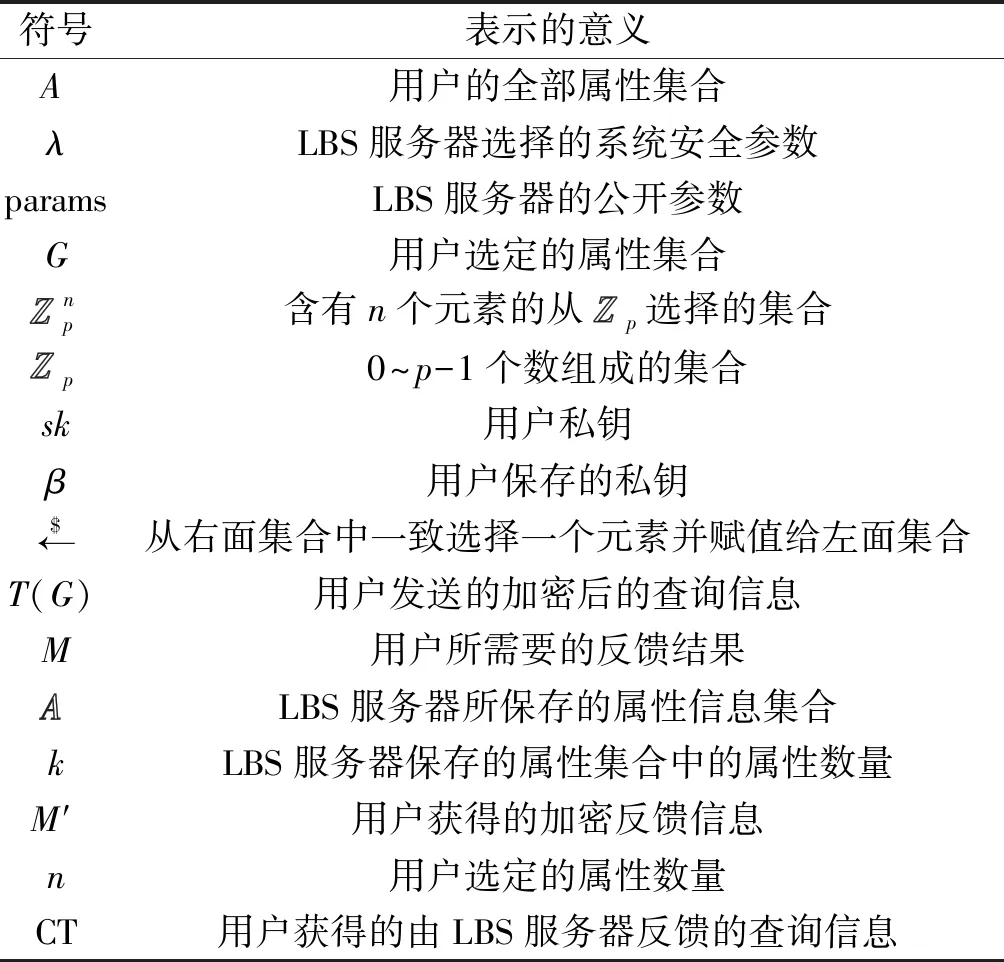
表1 属性PIR所涉及的参数Table 1 Parameters used in attribute based PIR
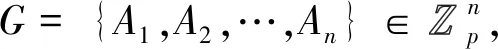
h←gβ
对于每个i分别计算:
ui←g1hri,vi←gri,Xi←gsi,Yi←gti

算法1用户加密查询处理
输入:用户查询信息转换后的属性信息G和私钥β←Zp
输出:加密后的用户查询信息T(G)
2 计算h←gβ;
3for(i=1,i<=n,i++)
4ui←g1hri,vi←gri;
5Xi←gsi,Yi←gti;
9end
10returnT(G)={Ui,Vi,Xi,Yi};
算法1中,第3~9行通过for循环实现对每个属性对应的查询进行加密,并获得加密查询信息T(G),该过程若不考虑累乘其时间复杂度为O(n),但在算法的6~8行对属性信息进行了累乘计算,因而实际的时间复杂度将达到O(n2)。
当LBS服务器收到用户发送的T(G)时,对于保存的兴趣点数据M,以及数据属性A,|A|=k,LBS服务器完成如下计算:
同时计算:
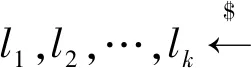
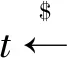
C3=Wt·M
LBS服务器获得加密信息CT=(C0,C1,C2,C3),并将其发送给用户。上述处理可表示为如算法2所示的计算处理过程。
算法2LBS服务器进行隐私信息检索
输入:用户提交的加密查询信息T(G)
输出:LBS服务器基于属性PIR处理后的加密查询结果CT。
1for(i=1,i<=k,i++)
2 计算Pi,Qi,Wi;
3end
4 随机选择l1~lk,t;
5 累乘计算P和W;
6 计算C0,C1,C2,C3;
7returnCT=(C0,C1,C2,C3);
算法2通过for循环对LBS服务器内保存的所有属性处理后获得反馈的查询结果,并向用户发送含有n个属性的查询结果集合。此时,for循环的规模远大于算法1中的for循环,即k≫n。此时算法2的时间复杂度为O(k)+O(n)=O(k)。
用户在收到由LBS服务器发送过来的信息CT后,计算:
((gt·∑i∈Aηili)-β·(gt·∑i∈Arili·ht·∑i∈Aηili))-β·
(gt·∑i∈Aθili)-β·gt·∑i∈Aβrili·ht·∑i∈Aθili·M=M
由此可在M中过滤出所需要的查询信息。最后对CT的处理过程可简化为算法3所示的处理过程。
算法3加密反馈信息解密
输入:LBS服务器反馈的加密查询结果CT;
输出:明文M′。
2returnM′;
算法3对每个属性信息进行了累加计算,处理后获得针对用户提交属性的查询结果信息。该算法的时间复杂度为O(n)。
综上,经过3个算法的处理实现了属性基PIR的处理过程,用户可通过秘密的信息检索过程获得所需的查询反馈。
3 性能评估
3.1 隐私保护和可用性分析
属性基PIR的安全性取决于LBS服务器无法准确识别由用户查询信息转化的属性信息。其可用性取决于对查询结果的准确反馈以及在有效的时间内的计算处理。
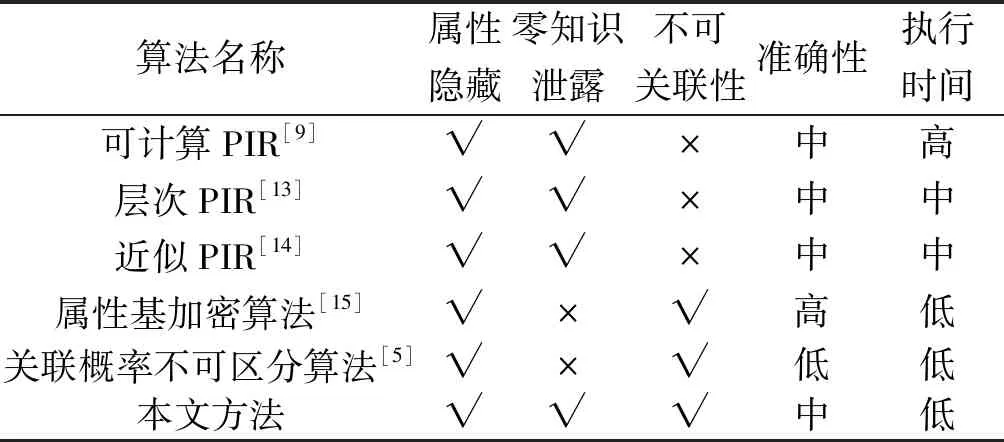
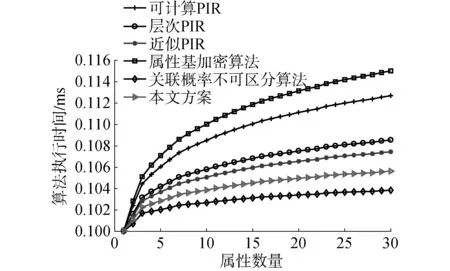
为进一步说明本文所提出算法的隐私保护能力,设存在一个在挑战者A和用户U之间的博弈来证明隐私保护强度。假设挑战者A准备了2组属性(a1,a2),并将这2个查询发送给用户U。U随机选择c∈(1,2)并表示为ac,同时将2组属性加密,然后将任意一组属性M发送给挑战者A。如果挑战者A能够计算得出c′ 满足p(ac′)≠p(ac),则A获胜。若A获胜,则需对于任意一组属性,存在p(ai∈ac|ac∈M)≠p(aj∈ac|ac∈M)∀(0 对于另一组属性,有: 在本文算法的处理下,攻击者可获得的是加密后的属性信息,在不能获得解密密钥的前提下,攻击者只能进行猜测,此时2次猜测成功的概率彼此相等,有pi=pj,∀(0 通过上一节给出的属性基PIR在隐私保护和可用性方面的理论分析可知,该算法能够保障用户的隐私且具有良好的执行效率。本节将通过与其他几种基于位置服务的隐私保护算法之间的对比,进一步证明所提出方法的优越性。参与比较的算法有:基于索引的可计算PIR[10],基于分层索引的层次PIR[15],基于模糊索引的近似PIR[16],基于属性泛化的属性基加密算法[17]以及基于属性模糊的关联概率不可区分算法[5]。实验将使用北京出租车行驶数据,并在Intel Core i5 1.70 GHz CPU、4gb RAM笔记本电脑上利用Matlab R2017a在Windows 7×64操作系统上完成测试,所有结果均是取计算500次后的平均值作为比较结果并绘制完成结果图。 表2给出了几种算法在不同安全环境下、查询准确性以及算法运行时间上的效果比较。 表2 不同算法效果比较Table 2 The comparison effects of different algorithms 图3给出了几种不同算法在属性数量变化下的攻击者猜测成功概率。从该图中可以看出,本文方法因使用属性基PIR,所以随属性增加,攻击者攻击成功的概率变化不大。同样使用PIR技术的可计算PIR、层次PIR以及近似PIR等3种方法的攻击成功概率也变化不大,这是因采用PIR索引差异导致的攻击效果差异。而属性基加密算法,尽管采用属性加密来防止属性被攻击者识别,但该算法一方面需提交用户真实位置,导致被识别的概率高于PIR;另一方面随着属性数量的增加,其保护性逐渐降低,因此其攻击成功率要高于上述几种基于PIR的算法。最后,关联概率不可区分算法采用的是位置模糊,并未对用户的属性信息加以保护,其被攻击者有效识别的概率高于其他算法,攻击成功率最高。 图4给出了几种不同算法在查询次数变化下的攻击成功概率。从该图中可以看出,随着查询次数的增加,所有算法都不可避免地存在更高的被攻击者识别的概率。这是因为随着查询次数的增加,用户将暴露更多的潜在信息给LBS服务器,这些信息可作为背景知识被攻击者所利用,进而提升攻击成功率。在这些方法中,本文方法因采用属性基PIR,其被暴露属性的可能性较低,攻击者利用属性关联获取用户隐私信息的成功率要低于其他PIR算法。而其他PIR算法,诸如计算PIR、层次PIR以及近似PIR等3种方法,由于采用加密技术,使得可暴露的信息量要少于泛化或模糊的算法,因此其攻击成功率要低于属性基加密算法和和关联概率不可区分算法。最后,属性基加密算法可针对的属性要高于关联概率不可区分算法,其攻击成功率要低于关联概率不可区分算法,而关联概率不可区分算法则是几种算法中最易被攻击者攻破并获取用户隐私信息的算法。 图3 不同算法的攻击成功概率vs.属性数量Fig.3 The success ratio of guessing the privacy vs. the number of attributes 图4 不同算法的攻击成功概率vs.查询次数Fig.4 The success ratio of guessing the privacy vs. the number of requests 图5给出了几种不同算法在属性数量变化下的算法执行时间差异。从该图中可以看出,所有算法的执行时间均随用户属性数量的增加而增长,这是因为属性加密算法以及其他算法,都需对增加的属性进行加密、泛化或模糊处理,上述过程增加了处理时间。在这些算法中,本文算法由于采用了属性基检索,其执行时间要低于采用索引检索的PIR算法,且由于对多个属性同时加密,其执行时间要低于用户协作的属性基加密算法,仅高于采用偏移的关联概率不可区分算法。其他几种PIR则按照可计算PIR,层次PIR以及近似PIR的顺序,其算法执行时间相应减少。 图5 不同算法的算法执行时间vs.属性数量Fig.5 The running time of various algorithms vs. the number of attributes 图6给出了不同算法在查询次数变化下的算法执行时间差异。从该图可看出,随查询次数的增加,所有算法的执行时间均逐渐增长,这是由于每次查询需重新执行隐私保护算法,其执行时间随查询次数逐渐增加。本文方法由于采用属性基检索,其算法处理步骤相对较少,因而其执行时间最少。而属性基加密算法由于采用协作用户提供查询结果,因此在多次查询的情况下,其算法执行时间稍高。关联概率不可区分算法需要计算各位置间的关联概率,且需要满足差分隐私约束,因而其执行时间要高于前2个算法。最后,计算PIR、层次PIR以及近似PIR则按照索引执行的难易程度,其算法执行时间依次增加。 图6 不同算法的算法执行时间vs.查询次数Fig.6 The running time of various algorithms vs. the number of requests 综上,可认为本文所提出的属性基隐私信息检索方法在安全性和算法执行效率等方面要优于其他同类算法。 1) 通过安全性和性能分析以及同类算法的对比实验,可认为本文所提出的方案具有更好的隐私保护能力和算法执行效率。 2) 在研究过程中还发现,这种基于加密手段的隐私保护算法其计算时间仍高于匿名策略的隐私保护算法,但其隐私保护能力更高。所以,本文所提出的方案更适合在一些计算能够较强的移动设备上使用。 由于本文方案是利用移动用户属性完成的隐私信息检索,今后的工作将在较少属性范围内的特征属性匹配检索方面展开,以进一步减少算法执行时间。3.2 实验设定
3.3 测试结果及分析



4 结论
猜你喜欢
自动化学报(2021年8期)2021-09-28 07:20:18太原科技大学学报(2019年3期)2019-08-05 01:18:18爱你(2018年16期)2018-06-21 03:28:44新闻传播(2016年18期)2016-07-19 10:12:06信息安全研究(2016年10期)2016-02-28 20:18:19现代计算机(2016年11期)2016-02-28 18:35:15指挥与控制学报(2015年4期)2015-11-01 10:09:34电子设计工程(2015年17期)2015-02-27 12:08:03华东师范大学学报(自然科学版)(2014年1期)2014-04-16 02:54:52河南科技(2014年11期)2014-02-27 14:10:19
