
基于CRNN 的汽车发动机声纹个体识别方法
2021-05-06 06:10高晓利赵火军骆明伟
火力与指挥控制 2021年3期
高晓利,李 捷,王 维,赵火军,骆明伟
(四川九洲电器集团有限责任公司 四川 绵阳 621000)
0 引言
声纹识别是重要的身份鉴别技术,有着广泛的应用领域,如军事安全、信息安全等[1]。同类声源的不同个体间的声音非常相似,无法通过人耳进行判别,但是这些相似的声音具有不同的特征参数[2]。从声音中提取一组反映个体特征的声学参数构成个体声纹是一个复杂的过程,也是声纹识别的关键。
根据声音信号的声学特殊性,已经提出一些有效的声学特征提取方法,如MFCC(Mel-Frequency Cepstral Coefficients)参数,它是将声音信号的频谱通过非线性变换转换为Mel频率,然后再转换到倒谱域上,从而获得MFCC 参数,但MFCC 参数方法在加入背景噪声后分析性能变差。如果信号的一个频率被噪音污染,那么该方法无法有效阻止噪音在整个特征向量上扩散[3]。文献[4]提出了基于小波分析的声源识别方法,但小波变换具有左递归的性质,高频区间存在着时域分辨率的差异,并且一定存在着最差分辨率的区间[5]。小波包变换能够解决小波变换由于没有对同一尺度上的细节作进一步分解,造成高频信息不能得到很好地处理这一问题[6]。文献[7]使用小波包分析+BP 神经网络,逐层分析信号在各子频段的能量谱,获取信号更精细的频域信息。该方法在频域上能获取更丰富的特征,但忽略了声音信号的时域连续性。
而声谱图是声音信号在频率和时间维度上的二维图像,其纵轴为时间,横轴为频率,灰度为幅值。使用声谱图作为声音信号的特征提取方式,获取图像形式的二维声纹特征作为分类识别阶段的输入。CNN 擅长处理图像信息,适用于处理声谱图中的“纹理”信息。文献[8]提出了通过CNN 完成声纹识别的方法。然而,声谱图中不仅包含表现声音片段的“纹理”特征,还有时域上的前后关联特征,使用CNN 仍不能充分挖掘声谱图中的信息。RNN模型的网络结构可以表达前后信息相关的时序效果,所以在时序信息处理方面有很大的优势[9]。通过将擅长时序建模的RNN 对CNN 的输出进行更进一步分析,建立改进的CRNN,充分挖掘声谱图中所包含的声纹特征,完成更全面的识别模型建立。
本文通过声谱图完成声音信号特征提取,采用网络参数优化的改进CRNN 完成模型训练和测试。首先介绍系统的总体结构,分析各部分的实现原理,最后通过仿真验证方法的有效性。
1 声纹识别系统
系统分为训练和测试两部分,如图1 所示。在训练阶段,发动机声音通过声谱图分析后得到声纹特征,按照分类标签信息存储在声纹数据库。利用训练数据训练由CNN 和RNN 共同构成的深度学习网络模型。在测试阶段,先进行测试声音数据的声谱图提取,再结合在训练阶段获取的深度学习模型,得到判别结果。根据最终统计结果,评估系统的识别率。
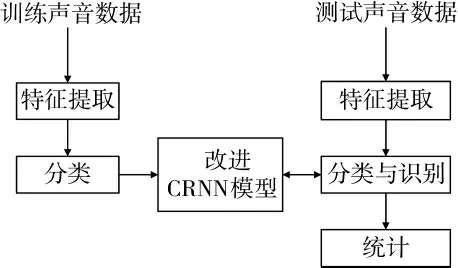
图1 声纹个体识别系统
1.1 基于声谱图的特征提取
在特征提取阶段获取的特征向量应能对不同声源有所区分。传统傅里叶变换适用于分析平稳信号,而不适用于分析非平稳信号或暂态信号。声谱图分析适用于各类声音信号的分析,是一种时频分析方法。声谱图是表示声音信号频谱随时间变化的图形。
声谱图分析方法通过对声音信号进行交叠分段的短时傅里叶变换,是一种在时域上连续分析频域特征的方法。任一时刻的某频率成分的强弱用相应的灰度深浅来表示,综合了频谱图和时域波形的特点,声谱图分析过程如图2 所示。首先对声音信号进行预处理,该过程包含归一化、分帧和加窗。进行特征提取前进行归一化处理,可以消除信号采集时引入的发动机声音音量大小差异造成的后期分析误差。归一化处理采用式(1)所示方法:

其中,Si是声音信号离散序列S 的第i 个元素,μ 和σ 分别是其绝对值和标准差。Spi是归一化的序列Sp的第i 个元素。

图2 声谱图分析流程
根据声音信号的短时平稳原则,每帧取20 ms~50 ms长度。为了使帧与帧之间平滑过渡,分帧一般采用交叠分段,由此保持声音信号的连续性。每一帧加窗后,按照0.5 帧长进行滑窗,进行频谱分析,求取该帧长信号的能量谱。将每帧的能量谱再按照时间序列进行连接,获得该声音片段的声谱图。
1.2 基于改进CRNN 的分类与识别
目标声纹图是目标声音信号的视觉表征,根据不同的声音特征反映出不同的“纹路”特征,因此,采用更适用于图像特征提取的CNN 进行下一步特征提取。CNN 是深度学习领域重要的网络模型之一,是一种层与层之间局部连接的神经网络[10]。
本文方法用CNN 从声谱图中提取声纹的特征参数,再通过RNN 对特征信息进行时序建模。RNN 和CNN 在建模能力上各有所长,RNN 可以用于描述时间上连续状态的输出,有记忆功能,而CNN 用于静态输出,共同构成CRNN 同时具有时间和空间的特性。
1.2.1 基于CNN 的声谱图特征提取方法
卷积神经网络一般由若干个卷积层- 激活层-池化层-批处理层的结构组成,如图3 所示。

图3 CNN 结构
其中,卷积层中奇数尺寸的滤波器能获取到更好的中心特征,故卷积核设为奇数[11]。激活层采用ReLU 激活函数,池化层采用Max Pooling 方式。同时通过批处理加快网络收敛速度。
传统的池化方法会同时在时域和频域方向上进行池化,而这样会丢失声谱图中的时序信息。有别于传统池化层,本文方法将只在频率上作池化以保留声谱图的时序信息,故池化窗大小为(2*1)。
1.2.2 基于改进CRNN 的声纹个体识别
仅通过CNN 提取声谱图特征的方法没有充分挖掘和利用声音信号的时序特征,而RNN 作为一种反馈神经网络,网络中的输出结果不但与当前输入信息以及网络权重有关,还与之前时刻信息输入相关,能够充分利用时间序列优势,其网络结构如图4 所示。中间隐藏层中的神经元相互连接,其中每个神经元的输入既包括当前时刻输入层的数据,也包括前一时刻隐藏层的输出。通过隐藏层和输入层的连接,将t-1 时刻的隐藏层状态作为t 时刻输入的一部分[12]。T 既为时序长度,C 为经由CNN 提取的特征数,F 为频率方向的长度。
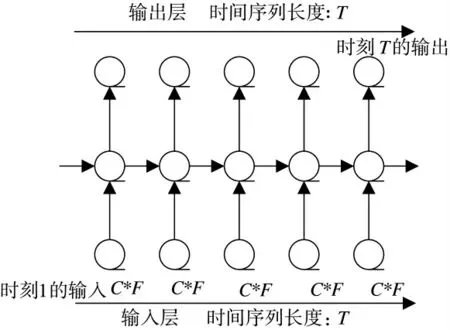
图4 RNN 结构
本文方法利用RNN 在时间序列建模的优势,完成进一步的分类和识别。从CNN 输出的特征向量维度是C×(F×T)。用一个时间序列来重新表示CNN 的输出,时间序列长度为T,S={S1,S2,…,Si,…,ST},Si是大小为C×F 的向量,将CNN 的输出转置为T 个大小为C×F 的向量,即从“特征数频率时间”向量转置为“时间频率特征数”向量来作为RNN的输入,两个网络间的对应关系如图5 所示。从RNN 输出的向量个数与时序长度T 对应,这里只采用最终时刻的输出,即对应图4 中T 时刻输出的数据,经过Softmax 分类器进行分类。
2 仿真实验
本文实验平台为联想ThinkStation,搭载NVIDIA K420 GPU。采用主流的深度学习框架TensorFlow 进行训练和验证。
实验数据来自实采的13 辆不同汽车(其中两辆为同型号)的发动机声音,涵盖了发动机的启动、平稳运行、若干次加速、停止运行全过程,由此涵盖发动机所有可能的工作状态。声音信号参数及特征提取阶段对声音信号的处理参数如表1 所示。

图5 CNN+RNN 深度学习网络结构

表1 特征提取参数
80%的声音片段作为训练数据,用于网络模型训练,余下的20%声音片段用于对模型的测试验证。声音片段有24 000/s 个数据点,帧移设置为240,则可获得100 帧/s数据。帧长取768 个数据点,对应声音信号短时平稳的30 ms长度。最初生成的声谱图大小为768*100,其中,100 对应1 s的100帧,768 对应声谱图频域的0~24 kH z。
考虑到过高的频率分量已经不属于有用信息,大多属于噪声信号,在多次仿真实验和训练基础上,最终选择在频域方向上作1/8 裁剪,以减少噪声等冗余信息,同时减少CRNN 深度学习网络的数据处理量。最终作为CRNN 输入的声谱图大小为96 100。如下页图6 所示是某片段的原始时域图和声谱图,既包含每帧的能量谱信息,又保证了时间上每帧的平滑过渡连续性。
下页表2 是识别仿真中不同参数的网络以及各自的识别率。仿真中CNN 网络共4 层,每层提取的特征数目为32/64/128/128,批处理batch 大小为8。卷积层采用的卷积窗大小为(5×5),实验输出标签为1 到13,分别对应13 台车辆的发动机。
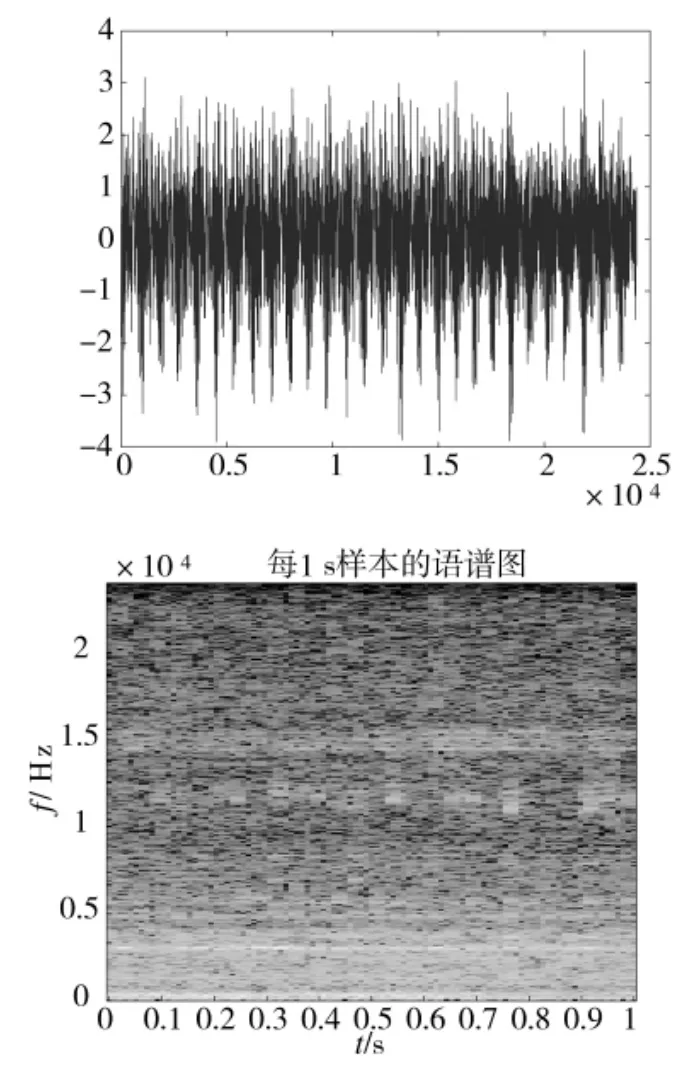
图6 某声音片段原始时域图和对应声谱图

表2 识别网络参数及结果
为了证明时序信息的重要性,改进CRNN 作为实验组在池化层不对时序方向作池化,即池化区域设置为(1×2),经过4 层卷积和池化处理后的CNN网络输出是128 张大小为6×100 的小声谱图,特征映射的数量即为128,6 和100 分别是输出图的高度和宽度,最终输出向量为128×(6×100),转置后输入到RNN 的向量为100×(1 286)。普通CRNN作为对照组的池化区域大小设置为(2×2),最终输出向量为128×(6×6),转置后输入到RNN 的向量为6×(128×6)。RNN 网络分别设置为3/5/7 层以作对比,每层大小为768。
从表2 中可以看出,相对普通CRNN,在使用相同层数的CNN 和RNN 情况下,改进CRNN 的识别率有所提高。这是因为改进CRNN 在池化层的参数调整,没有对时间维度的信息作池化处理而得到的结果。加入RNN 后的网络识别率随着RNN 的层数增加而升高,而同时网络模型也变大。
同时,仅使用普通CNN 处理声谱图“纹理”信息时的识别率低于加入RNN 处理时序信息后的识别率。其模型尺寸超过了加入3 层RNN 后的网络模型,原因是全连接层处理的数据量(6×6×128)多于后者CRNN 中处理的(6×128)。在只使用CNN的情况下,对池化区域作特殊处理对提高识别率帮助不大,且由于输出的数据量(128×6×100)太大,使得后期全连接层的模型尺寸也更大,导致整个模型尺寸达到了909 Mb。
3 结论
本文在特征提取阶段使用声谱图分析提取发动机的声纹特征,使用这些特征参数在分类识别阶段完成基于改进CRNN 的深度学习网络模型的训练,充分利用卷积网络的图像处理优势和递归神经网络的时序建模优势,获得了高识别率的声纹个体识别模型。通过对比实验结果表明,基于改进CRNN的识别方法优于传统方法,识别率有显著提高。相比普通CRNN,在模型大小不变的情况下,识别率提升了将近2%。相比单独CNN,识别率提升了8%。
同时,本文的改进CRNN 模型的参数除了表中CNN 和RNN 参数,还有全连接层的层数、每层节点数、学习率、正则化等大量参数,这些参数的调整确定目前需要大量实验支持。模型参数的调整方法还有待进一步的理论研究。在面对设备小型化时,网络模型的大小也需要得到控制。网络模型的轻量化设计也是今后的研究方向之一。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
导航定位学报(2022年5期)2022-10-13
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
电机与控制学报(2018年9期)2018-05-14
计算机应用(2016年10期)2017-05-12
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
