
基于小尺度核卷积的人脸表情识别
2021-04-29 03:21:40冯杨,刘蓉,鲁甜
计算机工程 2021年4期
冯 杨,刘 蓉,鲁 甜
(华中师范大学物理科学与技术学院,武汉 430079)
0 概述
在人际交往过程中,人们通常根据对方面部表情变化来判断其情绪,以更好地进行交流。随着人工智能和机器学习的兴起,人脸表情识别技术得到深入发展,其应用日益广泛。通过增强人机界面,机器能更好地感知用户情绪,在行为科学和临床实践中捕捉并分析罪犯与患者的微观表情可了解其潜意识,基于人脸表情识别的情感分类器能帮助情感交互存在障碍的人群增进情感交流。此外,人脸表情自动识别技术还应用于人体异常行为检测、计算机接口、自动驾驶以及健康管理等多个领域。
关于人脸表情识别的研究最早始于1978 年,SUWA 等人[1]跟踪脸部视频动画获取每帧图像关键点的运动规律,并将其与原始图像关键点模型对比后得到识别结果。1991 年,MAS 等人[2]采用光流方法跟踪肌肉运动走向,获取局部空间光流值组成表情特征向量构建人脸表情识别系统。传统的人脸表情识别主要采用局部二值模式[3]、非负矩阵因子分解[4]和稀疏学习[5]等机器学习方法来提取浅层特征。
从2013 年开始,深度学习方法逐渐应用于面部情感识别的研究。文献[6]采用卷积神经网络(Convolutional Neural Network,CNN)解决了面部表情的主观独立性问题以及图像平移、旋转和尺度不变等问题。文献[7]利用区域卷积神经网络(Region Convolutional Neural Network,R-CNN)学习人脸表情特征。随着深度学习技术的不断发展,研究人员基于CNN 设置辅助网络模块、网络层结构和网络集成来增强表情识别能力。文献[8]在AlexNet 卷积神经网络中引入特征选择机制设计特征选择网络FSN。文献[9]在特征层中增加岛屿损失层,结合决策层的Softmax 损失函数共同监督CNN 训练。文献[10]提出一种3 级混合结构网络,通过决策层集成实现决策多样性,其在FER2013 数据集上识别率达到70.86%。文献[11]采用改进的深度残差网络增加网络深度,引入迁移学习方法解决数据集较小的问题,改进网络在CK+数据集上识别率达到91.33%。上述研究表明,采用卷积神经网络可得到较好的识别效果,在此基础上加深和加宽网络能有效提高识别率,但网络参数过多也造成计算复杂度大幅增加,从而导致模型计算性能下降。
为进一步提升表情识别效果,解决网络结构复杂与数据计算量大等问题,本文提出一种应用于人脸表情识别的小尺度核卷积方法。结合小尺度核卷积层、批标准化层和Leaky-ReLU 激活函数形成组合块提取图像特征,在不增加网络参数的基础上加深网络,以减少静默神经元的影响,保障神经元充分学习,并使用Adam 优化器更新网络参数加速网络训练。
1 小尺度核卷积模型
1.1 卷积神经网络
卷积神经网络主要由卷积层、池化层(也称为采样层)和全连接(Fully connected)层构成,其结构如图1 所示。其中,卷积层用于局部感知和实现参数共享,池化层用于特征降维与压缩参数量,全连接层用于整合局部特征信息。感受野[12]是卷积神经网络中最重要的概念之一,其定义为卷积神经网络每一层输出特征图的像素点在输入图像上映射区域的大小。每个卷积核均对应一个感受野,卷积核越大,则神经元感受野的值越大,卷积核能接触到的原始图像范围越大,可提取到更全面、语义层次更高的特征,但会造成网络参数量增大和计算复杂度大幅增加。因此,本文用多个小卷积核代替大卷积核,以在获取相同大小感受野的同时减少参数量。
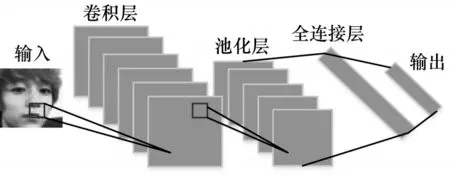
图1 卷积神经网络结构Fig.1 Structure of convolutional neural network
1.2 小尺度核卷积
在早期的研究中,为获取更大感受野,研究人员主要采用卷积核尺寸为11×11、7×7 和5×5 的卷积神经网络。随着计算性能不断提升,研究人员开始尝试使用更深和更宽的卷积神经网络。2012 年,KRJIZHEVSKY 等人[13]使用AlexNet 卷积神经网络提取特征得到良好的识别效果。AlexNet 包括5 个卷积层和3 个全连接层,每个卷积层中卷积核大小分别为11×11、5×5、3×3、3×3 和3×3。2014 年,SIMONYAN 等人[14]提出一种VGG16 网络,采用2 个3×3 卷积核组合替代1 个5×5 卷积核,得到的感受野大小与5×5 卷积核相同。2 个3×3 卷积核的参数量为19,1 个5×5 卷积核的参数量为26,由此可见在相同感受野下,采用小尺度卷积核所需参数量更少。
本文在VGG16 网络模型的基础上设计小尺度核卷积块(Conv-block),其结构如图2 所示。每个小尺度核卷积块包含2 个卷积块,每个卷积块由1 个卷积层、1 个批标准化(Batch Normalization,BN)层和1 个激活层组成。卷积层均采用3×3 卷积核,每个卷积层后加入BN 层处理,以加大搜索补偿并加快收敛。为使网络具有非线性,在BN 层后引入激活层。小尺度核卷积块选择小尺度卷积核代替大尺度卷积核,并通过增加网络层数保持图像性质,避免图像特征丢失,确保提取特征时有足够的感受野,在减少参数量的同时提升网络性能。

图2 小尺度核卷积块结构Fig.2 Structure of small-scale kernel convolution block
卷积层采用内核大小为m×m的滤波器与输入图像进行卷积运算。每个卷积层的网络神经元与输入图像局部区域有m×m个连接,计算公式如下:

其中,x为输入图像中进行卷积运算的局部感受野像素值,y为输出特征图的像素值,w为卷积核的权重值,b为偏置值,f(·)为Leaky-ReLU 激活函数[15]。
f(·)是ReLU 激活函数的变体,其计算公式如下:

其中,斜率α∈(0,1),本文中设置α=0.01。由于导数不为零,因此激活函数使负轴信息不会完全丢失,从而减少静默神经元,可有效解决ReLU 函数在负区间时神经元不学习的问题。
批标准化操作采用单位高斯分布规范网络中的激活函数以避免输入初始化,从而使每层输入达到稳定分布,以帮助网络训练并避免出现过拟合现象。
1.3 基于小尺度核卷积的人脸表情识别模型
本文基于小尺度核卷积的人脸表情识别模型结构如图3 所示。该模型由5 个采用3×3 卷积的小尺度核卷积块、5 个最大池化(Max pooling)层、1 个全连接(Fully connected)层和1 个输出层组成。5 个小尺度核卷积块的卷积核个数分别为64、128、256、512和512,步长和填充均为1。模型输入为44 像素×44 像素的灰度图,经过第1 个小尺度核卷积块处理后,输出64 张44 像素×44 像素的特征图,与原输入图像大小相同。最大池化层进行下采样,得到64 张大小为22 像素×22 像素的特征图,每张特征图大小均为原输入图像的一半。经过第2 个小尺度核卷积块处理后,输出128 张大小为22 像素×22 像素的特征图。最大池化层进行下采样,得到128 张大小为11 像素×11 像素的特征图。再经过3 次相同的“小尺度核卷积块+池化”操作后,得到512张大小为2像素×2像素的特征图,输入含有512 个神经元的全连接层,输出1 个512 维向量,最终通过Softmax 分类器获得7 种表情的分类结果,人脸表情识别模型的各层具体参数如表1 所示(“—”表示该参数值不存在)。

图3 人脸表情识别模型Fig.3 Facial expression recognition model
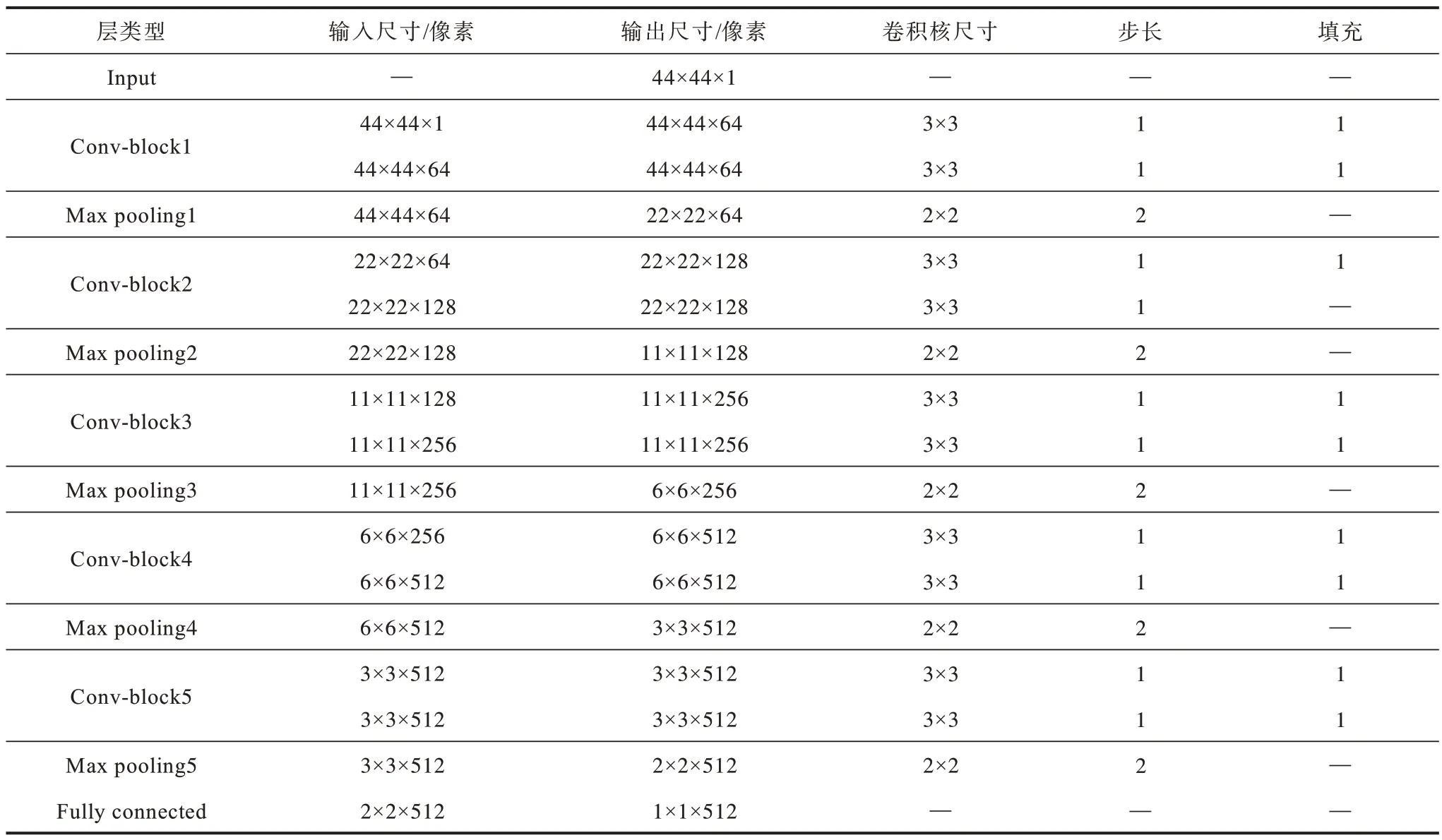
表1 人脸表情识别模型参数Table 1 Parameters of facial expression recognition model
在上述模型中,池化层对输入层的空间维度执行下采样操作,通过降低特征维度来减小输入图像的特征图大小并采用最大池化操作。完全连接层具有与输入中每个权重相连的神经元,最终输出结果为1 个向量,其维度大小为卷积核个数。
Softmax 分类器将输入值压缩为0~1 输出直观的归一化类概率,计算公式为:

其中,N为总类别数,S(x)j为Softmax 分类器将输入x分类为j的概率。
交叉熵损失函数的表达式如下:

其中,g(xi) 为模型输出预测值,yi为真实值,N为样本数。
模型计算复杂度通常采用参数量衡量,参数量的计算公式如下:

其中,S为模型整体参数量,K为卷积核尺寸,I为输入图像通道数,O为输出图像通道数。本文模型参数量较传统AlexNet 网络和VGG16 网络大幅减少,并少于改进AlexNet[16]网络,表明采用小尺度核卷积块的模型结构可有效减少参数量,在一定程度上降低计算复杂度。
2 实验与结果分析
本文实验采用GPU 版本的pytorch 框架,硬件平台为Ubuntu 16.04.2,双核Intel 2.2 GHz CPU,Tesla K80 GPU,1 TB 硬盘内存,11 GB 运行内存。在全连接层上应用Dropout 算法,丢失率设置为0.6,以避免出现过拟合现象。采用参数β1=0.600 和β2=0.999 的Adam 优化器来更新网络模型参数。
2.1 数据集
本文采用FER2013 数据集[17]和CK+数据集进行训练与测试。FER2013 数据集是常用的人脸表情公开数据集,共有35 888 张面部表情图像,包含不同光照情况、姿势角度和面部比例的人脸。该数据集由28 709张训练图像、3 589 张公开测试图像和3 589 张私有测试图像组成,图像均为48 像素×48 像素的灰度图。其中,每张图像的类别标记如下:0=愤怒,1=厌恶,2=恐惧,3=快乐,4=悲伤,5=惊喜,6=中立,7 种表情示例如图4 所示。

图4 FER2013 数据集中7 种表情示例Fig.4 Example of seven kinds of expressions in FER2013 dataset
CK+数据集[18]是人脸表情识别的代表性数据集之一,其包括123 个人共593 组图像序列,展示人脸从表情平静到表情变化达到峰值的过程。该数据集中带标签的表情序列有327 个,包含中性、愤怒,蔑视、厌恶、恐惧、高兴、悲伤和惊讶8 种表情。本文实验选取除中性表情之外的其他7 种表情图像,7 种表情示例如图5所示。从每组图像序列中提取最后3帧图像,共981张。所有图像经过预处理大小均为48 像素×48 像素。

图5 CK+数据集中7 种表情示例Fig.5 Example of seven kinds of expressions in CK+dataset
2.2 结果分析
为解决数据样本小造成模型泛化能力差的问题,本文实验对数据进行增强处理。在训练阶段,对原始图像进行随机剪裁,得到大小为44 像素×44 像素的图像,再进行随机镜像处理以弱化过拟合作用。在测试阶段,分别在每张图像的左上角、右上角、左下角、右下角和中心处进行切割,并通过水平镜像处理使数据集扩大10 倍,将其输入人脸表情识别模型得到相应的概率,概率取平均值后的输出类别即为最终的表情类别。
在FER2013 数据集实验中,在模型训练阶段将28709张图像作为训练集。实验共迭代250 轮,批大小设置为128。初始化学习率设置为0.01,前80 轮迭代学习率保持不变,当迭代轮数超过80 后,学习率开始衰减,每迭代5 轮衰减1 次,学习率减少1/10。在测试阶段,用3 589 张公开测试图像得到识别率,并通过反向传播进一步优化网络。然后用3 589 张测试图像验证模型,对每轮迭代的识别率取平均值得到最终识别效果,以此来评估算法性能。
本文生成的FER2013 测试集表情分类混淆矩阵如图6 所示,其反映了人脸图像在7 种表情上的识别率。可以看出,快乐最易区分,其识别率达到92%,明显高于其他表情。惊讶、厌恶和中性的识别率也较高,分别为85%、78%和74%,这4 种表情也是人类日常生活中常见的面部表情。愤怒、恐惧和悲伤的识别率相对较低,分别为64%、56%和61%,其原因为:1)数据集中这3 种表情图像数量较少造成训练不足,导致分类出现误差;2)这3种表情具有一定相似性,容易混淆难以区分。

图6 FER2013 数据集表情分类混淆矩阵Fig.6 Confusion matrix of expression classification in FER2013 dataset
在CK+数据集实验中,将数据集按9∶1 的图像数量比例分为训练集和测试集,得到882 张训练图像和99 张测试图像。实验共迭代60 轮,批大小设置为128。初始化学习率设置为0.01,前20 轮迭代学习率保持不变,当迭代轮数超过20 后,学习率开始衰减,每迭代1 轮衰减1 次,学习率减少1/5,采用十折交叉验证法得到CK+测试集表情分类混淆矩阵,如图7所示。与FER2013 测试集实验类似,由于恐惧、悲伤和蔑视3 类表情的图像数量相对较少且表情不易区分,因此其识别率低于愤怒、厌恶、高兴和惊讶。

图7 CK+数据集表情分类混淆矩阵Fig.7 Confusion matrix of expression classification in CK+dataset
为验证本文方法的有效性,分别在FER2013数据集和CK+数据集上,将本文方法与FER2013 record[19]、DNNRL[10]和CPC[20]、FsNet+TcNet[21]、MSSD+KCF[22]、FRR-CNN[23]、多特征融合[24]以及改进残差网络[11]等其他表情识别方法的识别率进行比较。其中,FER2013 record、DNNRL 和CPC 是人脸表情识别的经典方法,FER2013 record 具有Kaggle2013 比赛识别率排行榜最高的记录,DNNRL 提出3 级混合结构并采用决策层集成获取决策多样性,CPC 将数据集进行复杂感知分类,可解决环境和表情类别的不一致问题。FsNet+TcNet和MSSD+KCF 为近年来提出的方法,FsNet+TcNet 对图像进行人脸分割处理,通过分割出与表情识别关联度最大的人脸区域来提升网络识别精度,MSSD+KCF采用多尺度核特征卷积,以通道数合并的特征融合方式提高表情识别精度。上述方法在FER2013 数据集和CK+数据集中的比较结果如表2 所示。

表2 不同表情识别方法在2 个数据集中的识别率Table 2 Recognition rate of different expression recognition methods in two datasets %
由表2 可以看出,对于FER2013 数据集和CK+数据集,本文方法优于减少特征冗余的卷积神经网络FRR-CNN、多特征融合方法和改进残差网络的方法。本文方法保留了图像特征的完整性,在原始图像基础上进行数据增强处理,并采用多层小尺度核卷积减少网络参数量,在一定程度上降低了算法复杂度,因而其识别效果更好。
3 结束语
本文提出一种利用小尺度核卷积的人脸表情识别方法,采用小尺度核卷积块与池化层相结合的网络结构提取人脸表情特征,在相同感受野下加深网络并精简网络结构,利用Softmax 分类器获取表情分类结果,同时在模型训练和测试阶段对数据进行增强处理,提升网络泛化能力以减少识别误差。实验结果表明,与FER2013 record、DNNRL 等方法相比,该方法的人脸表情识别率更高。后续将去除人脸图像中与表情无关的冗余部分,以更精确地提取表情特征。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
动漫星空(2018年9期)2018-10-26 01:17:14
中国交通信息化(2018年3期)2018-06-13 03:27:58
太空探索(2016年5期)2016-07-12 15:17:55
中国交通信息化(2016年2期)2016-06-06 07:28:02
发明与创新(2015年33期)2015-02-27 10:40:09
时代英语·高三(2014年5期)2014-08-26 17:01:17
