
融合可变形卷积网络的鱼眼图像目标检测
2021-04-29 03:21刘宏哲
计算机工程 2021年4期
包 俊,刘宏哲
(北京联合大学北京市信息服务工程重点实验室,北京 100101)
0 概述
视觉环境感知能够提供驾驶场景的基本信息,在自动驾驶技术的发展中发挥着重要作用。传统的环境信息获取是通过窄角针孔摄像头的方式,而自动驾驶汽车需要更大的视野来感知复杂的环境,鱼眼图像具有视场大和视角广的特点,因此,鱼眼照相机在自动驾驶领域得到广泛应用。
鱼眼照相机拍摄的图像具有很强的失真[1],畸变给图像处理带来困难,鱼眼图像在使用前通常是去失真的,但图像去失真会损害图像质量(尤其是在图像边界处)并导致信息丢失。此外,标准相机的视野有限,要求许多相机覆盖整个车身周边地区,解决该问题的方法是在环境信息感知时使用鱼眼镜头,广角视图可以提供180º的半球视图。利用该特点,理论上只需2个摄像头就可以覆盖360º。然而,鱼眼相机在图像中引入了强烈失真,使得场景中的元素在图像上出现畸变,因此,常规的目标检测网络(如Faster_RCNN[2])难以应用于鱼眼图像的目标检测任务。
近年来,卷积神经网络在图像分类、语义分割[3]和目标检测等视觉识别任务中得到广泛应用,此外,手工构建的结构(如金字塔池模块[4])也有助于提高卷积神经网络的目标特征提取能力。然而,卷积神经网络具有固定的结构,如固定的过滤核、接收野大小和池核,缺乏处理几何形变的内部机制,因此,其对图像中存在形变的目标的建模能力有限。
在利用深度学习技术对鱼眼图像进行处理时,主要存在2 个问题,一是目前找不到合适的网络模型来对鱼眼图像中的物体形变进行很好地建模,二是目前深度学习网络模型需要大量的训练数据集,但现有公开数据集都是普通图像数据集,如COCO2017[5]、PA-SCAL VOC 2012[6]和Cityscapes[7]等,用于鱼眼图像目标检测的数据集非常少。
针对普通卷积神经网络难以对鱼眼图像中的目标形变进行有效建模的问题,本文提出一种融合可变形卷积网络的多阈值目标检测器,以对鱼眼图像中的目标进行检测。针对训练数据集缺乏的问题,本文在数据采集车上安装鱼眼相机,采集城市道路环境中的鱼眼图像并做标注处理。其中,数据集采用VOC 格式,数据量是9 942 张,分为训练集(5 966 张)、验证集(994 张)和测试集(2 982 张)。在此基础上,利用该目标检测器在公开的鱼眼图像数据集SFU_VOC_360[8]和本文所采集的鱼眼图像数据集上分别进行实验,以验证检测器的目标检测准确性。
1 相关工作
利用计算机视觉技术判断图像或视频序列中是否存在目标并给予精确定位即为目标检测,目标检测技术可广泛应用于智能交通中的车辆辅助驾驶系统、人体行为分析、机器人开发以及视频监控等领域。卷积神经网络作为深度学习的重要组成部分,已经被成功应用于目标检测领域,卷积神经网络凭借其在学习目标纹理和梯度特征时的优势而受到越来越多的关注。
在由传统相机拍摄的图像上能取得较好检测效果的网络,如Faster-RCNN、R-FCN、YOLO 和SSD等,在处理目标形变较大的鱼眼图像时效果并不理想。因此,设计针对存在较大目标畸变的图像的目标检测算法[9]尤为必要。
文献[10]提出一种基于变换不变图网络的图形构造方法,该方法中卷积滤波器对不同位置上相同图案的响应类似,与镜头畸变无关,但其缺点是仅限于特定类型的映射投影成像畸变。文献[11]提出主动卷积(ACU)单元,其定义的卷积没有固定的形状,可以通过训练中的反向传播(BP)来学习其形状,但ACU 的缺点是采样位置的学习过程不稳定,模型耗时较长。文献[12]提出一种球形卷积网络,该网络用全局投影将360°全景输入图像展开为单个平面图像,然后将卷积神经网络应用于变形的平面图像上。文献[13]提出一种场景理解网络,构造Bottom-Net模型,网络将图像的每个垂直列作为输入,输入列的宽度为24,重叠23 个像素,然后每列通过卷积网络输出k(高度)种标签中的一个,但是该网络的缺点是模型冗余率太高。文献[14]构造失真-觉察卷积滤波器,与标准卷积方法相比,其能有效处理目标形变,但在处理等距投影和鱼眼镜头等立体角投影时效果较差。文献[15]提出的鱼眼目标检测网络中引入了分通道卷积,其对下视鱼眼图像的目标检测性能有所提升。文献[16]构建FisheyeMODNet网络,分别处理2 个时间序列图像,将像素标记为运动或静态,但是该网络仅能在KITTI 数据集上训练,在鱼眼图像上泛化性能较低。
DCN(Deformable Convolutional Networks)[17-18]有可变形卷积和可变形感兴趣区域(RoI)池化2 个模块,可增强卷积神经网络的转换建模能力。DCN在模块中增加有额外偏移量的空间采样位置,无需从目标任务中学习偏移量,其可以代替现有卷积神经网络模块,并通过标准反向传播进行端到端训练,产生可变形卷积网络。
2 融合可变形卷积网络的目标检测器
可变形卷积网络对传统卷积神经网络进行改进,替换其中的固定卷积层和池化层,从而更好地处理鱼眼图像中的目标形变问题,有效提取物体特征并提升目标检测效果。
2.1 融合DCN 的Faster_RCNN 网络
基于DCN 的改进Faster_RCNN 目标检测网络将Faster_RCNN 中的固定卷积层和池化层,替换为可变形卷积和可变形池化。具体如下:
1)传统的卷积结构可以定义为式(1):

其中,pn是卷积输出每个点相对感受野上每个点的偏移量,其取整数。
采用可变形卷积后,需在式(1)基础上给每个点增加一个偏移量Δpn,该偏移量是由另一个卷积得出,因此一般为小数,如式(2)所示:

式(2)中的x(p0+pn+Δpn)的取值非整数,并不对应特征图上实际存在的点,因此,必须通过插值得到其值。如果采用双线性插值的方法,x(p0+pn+Δpn)可以转换为式(3):

其中,x(q)表示特征图上所有整数位置上点的取值,x(p)=x(p0+pn+Δpn)表示加上偏移量后所有小数位置上点的取值。
2)传统的RoI Pooling 可以用式(4)来表示。整个RoI 被分为k×k个bin,每个bin 的左上角坐标是p0,p是bin 中每个点相对于p0的坐标偏移量,nij是第ij个bin 中的点数。将可变形卷积套用到传统的RoI Pooling 上,可以得到可变形的RoI Pooling,如式(5)所示。

其中,Δpij是每个bin 的偏移量,该偏移量是针对整个bin,即对于一个bin 中的每一个点,该值都相同。
可变形卷积与标准卷积对比如图1 所示。可变形卷积的基本思想是卷积核的采样方式可以通过学习得到,传统卷积窗口只要训练其像素权重参数即可,而可变形卷积网络必须外加一些参数用来训练卷积窗口的形状。

图1 可变形卷积与普通卷积对比Fig.1 Comparison of deformable convolution and ordinary convolution
在可变形卷积中,可变形卷积操作和池化操作都是2 维的,均在同一通道上进行。常规的卷积操作可以分为2 个部分:在输入的特征图上使用规则网格R进行采样,R定义了感受野的大小和扩张;进行加权运算。以3×3 的可变形卷积为例,其示意图如图2 所示,可变形卷积可以提高对形变图像的建模能力,其基于一个平行网络学习偏移(offset),使得卷积核在输入特征图的采样点发生偏移,然后集中于感兴趣的区域或目标。

图2 3×3 可变形卷积示意图Fig.2 Schematic diagram of 3×3 deformable convolution
可变形池化原理如图3 所示,以3×3 可变形RoI池为例[19],其相比普通RoI Pooling 增加了一个offset。可变形池化的具体操作为:首先,通过普通RoI Pooling 得到一个特征图,在特征图中加一个全连接层,生成每一个位置的offset;然后,按照式(3)~式(5)得到ΔPij。为了使offset 的数据和RoI 的尺寸相匹配,需要对offset 进行微调。

图3 3×3 可变形RoI 池化示意图Fig.3 Schematic diagram of 3×3 deformable RoI pooling
基于DCN的改进Faster_RCNN网络中的bac-kbone选用Resnet50[20],将Resnet 的阶段3~阶段5 中的卷积层和池化层替换成可形变卷积和可形变池化,改进的Resnet结构如表1所示,融合可变形卷积的Faster_RCNN网络结构如图4 所示。
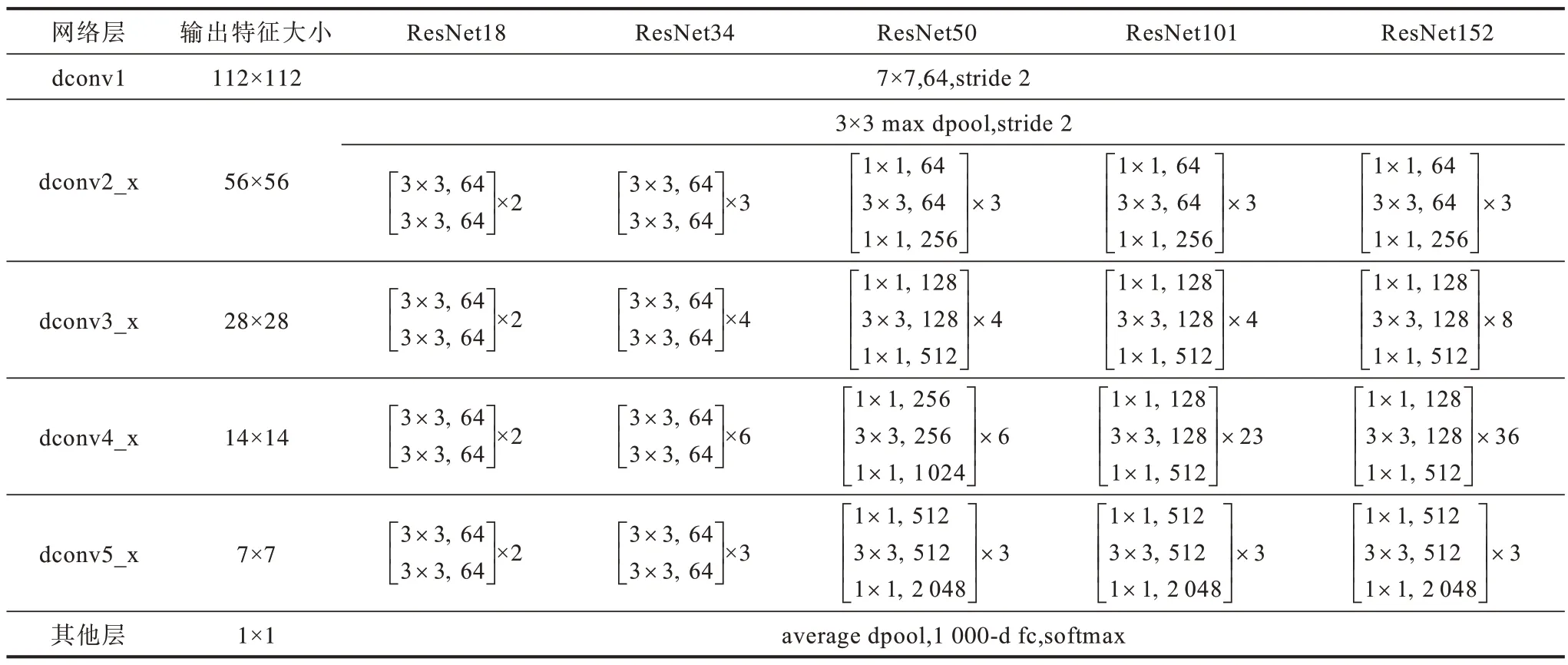
表1 改进的Resnet 网络结构Table 1 Improved Resnet network structure

图4 融合DCN 的Faster_RCNN 网络结构Fig.4 Faster_RCNN network structure combining DCN
时间复杂度即模型的运算次数,可用浮点运算次数(FLOPs)衡量。时间复杂度决定了模型的训练预测时间,如果复杂度过高,模型训练和预测会耗费大量时间,无法快速地预测和验证模型性能。卷积神经网络结构的时间复杂度为:

其中,D是神经网络层数,即网络深度,Ml是第l层卷积核输出特征图的边长,Kl是第l层网络的卷积核边长,Cl是第l个卷积层的输出通道数。经分析计算,融合可变形卷积的Faster_RCNN 网络结构的时间复杂度为3.8×109。
空间复杂度(访存量)包括总参数量和各层输出特征图2 个部分。空间复杂度决定了模型的参数数量,由于维度灾难的限制,模型的参数越多,训练模型所需的数据量就越大,而现实生活中的数据集通常不会太大,从而导致模型的训练很容易过拟合。卷积神经网络结构的空间复杂度为:

经分析计算,融合可变形卷积的Faster_RCNN网络结构的空间复杂度为4.8×108。
2.2 融合DCN 的Cascade_RCNN 网络
重叠度(Intersection-over-Union,IoU)阈值取值越高,就越容易得到高质量的样本,但是一直选取高阈值会引发2 个问题:
1)样本减少而引发过拟合。
2)在训练和推断阶段使用不同的阈值很容易导致正负样本误匹配问题。
为解决上述问题,Cascade_RCNN提出一种多阶段的结构,其利用不断提高的阈值,在保证样本数不减少的情况下训练出高质量的检测器[21]。
区域候选网络提出的候选区域多数质量不高,导致无法直接使用高阈值的目标检测器。Cascade_RCNN使用级联回归作为一种重采样机制,逐阶段提高候选区域的IoU值,从而使得前一个阶段重新采样过的候选区域能够适应下一个有更高阈值的阶段。Cascade_RCNN具有以下优势:
1)每一个阶段的目标检测器都不会过拟合,都有足够满足阈值条件的样本。
2)更深层的目标检测器可以优化更大阈值的候选区域。
3)每个阶段的阈值不相同,意味着可适应多级的分布。
4)在推断时,虽然最开始区域候选网络提出的候选区域质量不高,但每经过一个阶段后质量都会提高,从而和有更高IoU 阈值的目标检测器之间不会有很严重的正负样本误匹配问题。
将Cascade_RCNN 中的固定卷积层和池化层替换为可变形卷积层和可变形池化层,能够更好地对形变目标进行建模以及对鱼眼图像实现特征提取,从而提升鱼眼图像的目标识别准确率。融合可变形卷积和可变形池化的Cascade_RCNN 网络结构如图5 所示。骨干网络采用Resnet50,其有5 个阶段,本文实验中替换阶段3~阶段5 中的固定卷积,阶段替换与实验数据集有很大关系,替换阶段3~阶段5 中的固定卷积是最适合本文实验数据集的一种替换方式[22]。经分析计算,融合可变形卷积的Cascade_RCNN 网络的时间复杂度为1.3×108,空间复杂度为3.5×108。

图5 融合DCN 的Cascade_RCNN 网络结构Fig.5 Cascade_RCNN network structure combining DCN
3 实验结果与分析
本文使用单个NVIDIA GTX 1080Ti GPU 平台,利用Pytorch 深度学习框架对模型进行训练和评估,根据平均精度(mean Average Precision,mAP)标准值来衡量算法对鱼眼图像的目标检测性能[22]。
3.1 实验数据集
实验中采用最近公开的SFU_VOC_360 鱼眼图像数据集,该数据集由著名数据集VOC2012 的后处理常规图像生成,包含39 575 张用于目标检测的鱼眼图像,共有20个类别,数据集标签如表2所示,SFU_VOC_360鱼眼图像数据集部分图像如图6 所示。检测目标出现较大的形变,说明鱼眼图像目标检测的难度大于普通图像。

表2 SFU_VOC_360 数据集标签Table 2 SFU_VOC_360 dataset label

图6 SFU_VOC_360 鱼眼图像数据集部分图片Fig.6 Some images of SFU_VOC_360 fisheye image dataset
3.2 实验结果
将原始Cascade_RCNN 网络作为基准方法,与本文基于可变形卷积网络的目标检测方法进行比较。基准方法使用RoIAlign 来提取感兴趣区域的特征,采用平均精度(mAP)作为度量指标。首先,在本文所采集的真实鱼眼图像数据集上进行目标检测,比较基准方法与本文方法的检测性能,结果如图7所示。从图7 可以看出,本文方法相比基准方法有0.025 的mAP 性能提升。2 种方法训练的学习率、训练轮次和平均单张图片检测时间对比结果如表3所示。

图7 真实鱼眼图像上的测试结果Fig.7 Test results on real fisheye image

表3 2 种方法在真实鱼眼图像数据集上的检测性能对比Table 3 Comparison of detection performance of two methods on real fisheye image dataset
真实道路场景鱼眼图像的分辨率是1 280 像素×720像素,本文方法在该图像上的检测结果如图8所示。

图8 真实道路场景鱼眼图像检测结果Fig.8 Real road scene fisheye images detection results
在SFU_VOC_360 鱼眼图像数据集上比较基准方法与本文方法的检测性能,训练的学习率、训练轮次以及平均单张图片检测时间对比结果如表4 所示。SFU_VOC_360 鱼眼图像数据集的分辨率是486×486,本文方法在该鱼眼图像数据集上的检测效果如图9所示,目标检测的准确率如表5所示。从中可以看出,本文方法相比基准方法有0.034 的mAP性能提升。

表4 2 种方法在SFU_VOC_360 鱼眼图像数据集上的检测性能对比Table 4 Comparison of detection performance of two methods on SFU_VOC_360 fisheye image dataset

图9 SFU_VOC_360 鱼眼图像测试结果Fig.9 SFU_VOC_360 fisheye images test results

表5 SFU_VOC_360 鱼眼图像数据集测试结果Table 5 Test results of SFU_VOC_360 fisheye image dataset
4 结束语
本文提出一种融合可变形卷积网络的目标检测方法,用于原始鱼眼图像的目标检测。采用特征金字塔结构检测多尺度物体,结合多阈值目标检测器的特性提升模型性能。实验结果表明,该方法在鱼眼图像中对目标进行检测时精度较高。本文构建的数据集规模仍然较小,下一步将尝试构建目标种类更全面的大型数据集,以供鱼眼图像目标检测算法训练与测试。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
摄影之友(影像视觉)(2018年6期)2018-07-06
北京航空航天大学学报(2018年1期)2018-04-20
饮食与健康·下旬刊(2017年1期)2017-02-08
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
