
融合文本分类的多任务学习摘要模型
2021-04-29 03:20周伟枭蓝雯飞
计算机工程 2021年4期
周伟枭,蓝雯飞
(中南民族大学计算机科学学院,武汉 430074)
0 概述
文本摘要是自然语言处理(Natural Language Processing,NLP)的重要分支[1],其将源文本压缩成短文本且包含了源文本中的主要信息。抽取式摘要方法[2]通过从源文本中抽取句子组成摘要,具体为对句子重要性打分并按分数排序选取句子[3]。生成式摘要方法[4]通过重新组织源文本的主要内容形成摘要,摘要过程与人工撰写类似。现有生成式摘要模型本质上都是基于编码器-解码器架构的单任务模型,文献[5]指出此类模型虽然能够生成流畅的摘要,但在准确性方面表现较差,甚至可能与源文本的中心思想相悖。
多任务学习(Multi-Task Learning,MTL)共享相关任务之间的表征,能使摘要模型更好地概括文本主要内容。文献[6]提出一对多、多对一、多对多三种多任务学习方法。文献[7]将情感分类定义为特殊类型的摘要任务,将文本以标签方式进行概括。受文献[6]研究工作的启发,本文根据文本分类和文本摘要的相关性,提出一种多任务学习摘要模型。通过一对多的形式关联主要任务和辅助任务,借助文本分类改善摘要模型的生成质量,使用K-means 聚类算法构建文本分类数据集,并利用基于统计分布的判别法全面评价摘要准确性。
1 相关工作
近年来,深度学习技术在文本摘要领域得到广泛应用。文献[8]提出基于注意力机制的端到端模型,并将其应用于文本摘要任务。文献[9]将注意力机制应用于自然语言处理领域。文献[10]提出指针网络,将解码器中固定规模的词汇表扩展至可变规模的词汇表。文献[11]提出CopyNet 模型,并在文本摘要任务上验证了CopyNet 模型相较传统模型具有显著优势。摘要任务与翻译任务不同,其数据集中参考摘要的长度远短于源文本,导致传统模型和CopyNet 模型无法很好地对源端文本以及参考摘要进行对齐。文献[12]指出对齐问题导致解码器容易重复生成冗余的单词或句子,针对此问题,该文献提出在解码器中引入覆盖度机制协助调整未来时间步的注意力。文献[13]提出Pointer-Generator(Coverage),缓解了集外词(Out of Vocabulary,OOV)和重复生成问题。
随着深度学习技术的发展,研究人员通过多任务学习提高模型生成摘要的准确性。文献[14]将问题生成作为辅助任务,提出基于多层编码器-解码器模型的多任务学习架构。文献[15]指出翻译任务与摘要任务具有较强的相关性,使用机器翻译可提高摘要模型的生成性能。文献[16]提出基于多任务学习的深层神经网络框架,通过同时学习人的注视行为以及文档中的词性和句法属性来预测输入文档中表达的整体情绪。与文献[14-16]研究工作不同,本文将文本分类作为辅助任务,使得摘要模型能够学习到更抽象的信息。文献[17]在文献[13]的基础上定义了一个内容选择器来确定源文本中哪些短语一定包含在摘要模型中,该模型是关键词识别与文本摘要的混合模型。文献[18]将多模态注意力机制引入摘要模型中,输入源文本、参考摘要和参考图片进行训练。多模态注意力机制同时关注摘要和图片中的信息以生成质量更高的摘要,该模型是文本摘要与图片识别的混合模型。此外,文献[19-21]从不同角度研究多模态摘要模型。
针对编码器-解码器架构的改进,文献[22]将单独的编码器划分为多个协作编码器,使用深度通信代理表示这些协作编码器,并在不同代理间实现数据共享,摘要模型通过提高编码质量间接提高生成摘要的质量。文献[23]提出Transformer 模型,其相比循环神经网络(Recurrent Neural Network,RNN)序列具有更优的并行化处理能力和特征提取能力,逐渐被应用于文本摘要领域。
2 多任务学习摘要模型
2.1 总体框架
多任务学习将相关任务放入同一框架中进行训练,一般分为一个主要任务和若干个辅助任务。文本分类是对不同文本中的重要信息进行区分,文本摘要是从文本中识别出重要的信息并进行提取,类别标签是更抽象的摘要表示。多任务学习摘要模型的总体框架如图1所示,由共享编码器(Shared Encoder)、分类器(Classifier)和摘要解码器(Summarization Decoder)构成。

图1 多任务学习摘要模型的总体框架Fig.1 The overall framework of summarization model with multi-task learning
共享编码器与分类器构成分类模型,与摘要解码器构成摘要模型。编码器采用硬共享机制,来自两个任务的梯度信息直接通过共享参数传递,强制所有任务使用公共空间表示。在训练编码期间,摘要任务与分类任务交替运行,随机输入相应任务数据集中的源文本。在训练解码期间,分类器或摘要解码器进行标签类别预测或摘要生成,相对于真实标签或参考摘要计算损失,反向传播并更新模型参数。在测试编码期间,编码器接收摘要测试集作为输入。在测试解码期间,摘要解码器使用集束搜索预测下一时刻的单词输出并选择概率最高的单词序列作为生成的摘要。
2.2 共享编码器
RNN 通常用来处理时间序列数据,能够很好地提取文本单元之间的前后关联信息。RNN 变体包括长短时记忆(Long Short-Term Memory,LSTM)网络[24]和门控循环单元(Gated Recurrent Unit,GRU)[25]。LSTM在RNN 的基础上引入了遗忘门、输入门和输出门,前向传播公式如下:

其中,xt为LSTM 的输入,ht-1、ct-1分别为上一时刻的隐藏状态和细胞状态,ht、ct分别为当前时刻的隐藏状态和细胞状态。
GRU 将LSTM 的3 个门简化为更新门和重置门。在逻辑架构中,GRU 没有细胞状态c,直接将隐藏状态h传递给下一个单元,前向传播公式如下:

本文使用双向LSTM(Bi-directional LSTM,Bi-LSTM)和双向GRU(Bi-directional GRU,Bi-GRU)作为多任务学习摘要模型的编码器以更好地捕捉双向语义依赖关系。给定源文本D={w1,w2,…,wn},每个单词wi被嵌入K维向量,Bi-LSTM 或Bi-GRU 对其双向编码,输出两个隐藏状态序列。在具体实现中,源文本通过数据块的方式进入编码器,在变长序列中进行补零操作来处理长度变化。
2.3 摘要解码器
2.3.1 Pointer-Generator 解码器
摘要解码器与文献[13]提出的Pointer-Generator解码器类似,其生成的单词可以来源于源文本或指定的词汇表。摘要解码器架构如图2 所示。
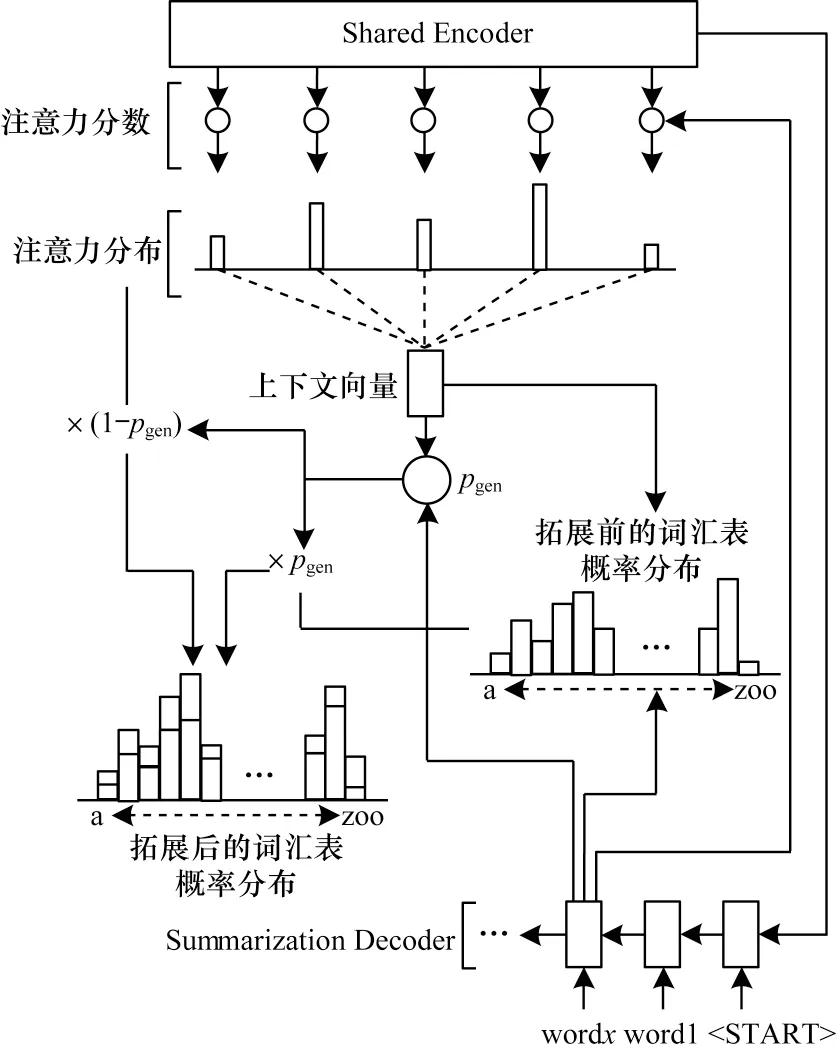
图2 摘要解码器架构Fig.2 Summarization decoder architecture
Pointer-Generator 解码器接收共享编码器输出的隐藏状态序列,并将源文本表示为两者的级联:

在每一时刻t,单层LSTM 或GRU 接收单词的嵌入达到新的解码器状态st,通过注意力机制计算注意力分数、注意力分布at和上下文向量ct。计算公式如下:

其中:v、Wh、Ws、ba为可优化的参数;tanh 为激活函数;at为源文本单词上的概率分布,指导解码器重点关注某些单词。
传统基于注意力机制的编码器-解码器模型从当前解码器状态st和上下文向量ct中生成词汇表概率分布Pvocab,而Pointer-Generator 解码器定义pgen,由当前解码器状态st、当前时刻输入单词嵌入向量et和上下文向量ct共同决定,计算公式如下:

其中:wc、ws、we、bpgen表示可优化的参数;σ表示sigmoid函数;pgen表示从词汇表中生成单词的概率,(1-pgen)表示通过从注意力分布at中抽取源文本单词的概率。拓展后的词汇表概率分布计算公式如下:

其中,w表示某个单词。与Pointer-Generator 相比,传统编码器-解码器模型被限制在容量有限的词汇表中。
2.3.2 覆盖度机制
本文在摘要解码器中引入覆盖度机制[13]缓解重复生成的问题。覆盖度向量covt表示时刻t前所有解码的注意力分布at˜的总和,计算公式如下:

其中,covt可解释为源文本单词上的非规范化分布,表示在当前时刻这些单词从注意力机制中获得的覆盖程度。若将covt作为注意力向量的额外输入,则式(4)改写为:
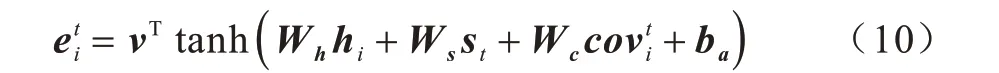
其中,v、Wh、Ws、Wc、ba是可优化的参数。覆盖度机制通过总结已有决策避免重复注意相同的位置。摘要解码器在时刻t的损失被定义为复合损失函数,计算公式如下:


2.4 分类器
文本分类作为辅助任务帮助摘要模型学习到更加抽象的信息,提高解码器生成摘要的准确性。分类器架构如图3 所示。
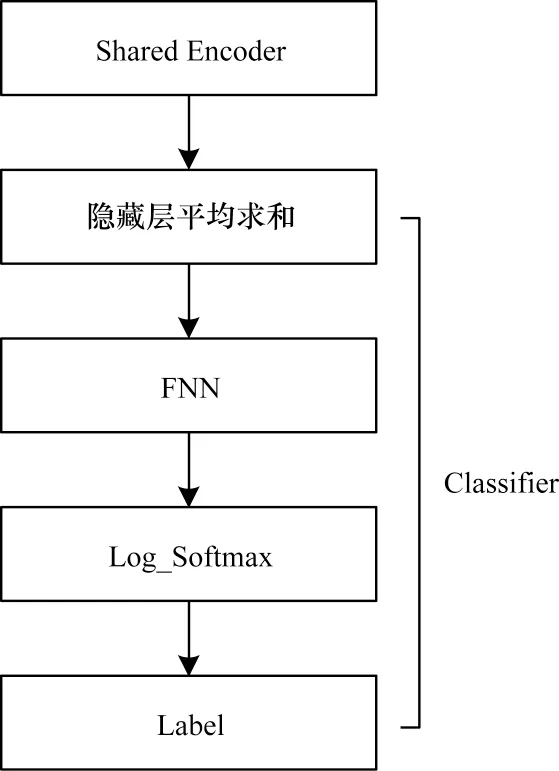
图3 分类器架构Fig.3 Classifier architecture

其中,hf和hb分别表示正向、反向编码的文本表示,hs表示最终文本表示。
前馈神经网络(Feedforward Neural Network,FNN)将hs映射为与文本类别数量相同的维度。使用Log_Softmax 函数计算类别标签的概率分布,计算公式如下:

其中,exp 表示以e 为底的指数函数。本文结合Log_Softmax 函数与负对数似然损失计算预测类别与真实类别的损失,该损失等价于预测类别与真实类别的交叉熵。
3 数据集构建
3.1 文本摘要数据集
CNNDM(CNN/Daily Mail)[26]是摘要领域的基准数据集之一,源文本和参考摘要分别来源于在线新闻文章和人工撰写。本文使用CNNDM 的匿名版本,其中包含286 896 组训练集、11 489 组测试集和13 368 组验证集。
3.2 文本分类数据集
在多任务学习中,多个数据集原始特征如果有一定相似性,则可以提高摘要任务的性能。本文通过无监督算法获取CNNDM 源文本的类别标签,文本分类数据集的构建流程如图4 所示,具体步骤如下:
1)剔除CNNDM 训练集中的参考摘要,保留源文本。
2)对抽取出的源文本进行分词、去停用词和去低频词,避免停用词和低频词对有效信息造成的噪声干扰。
3)使用TF-IDF 特征提取方法将预处理后的源文本向量化,TF-IDF 特征提取方法的主要思想为评估某个词相对于数据集中某份文件的重要程度。
4)应用K-means 聚类算法对向量化后的文本进行聚类操作。
5)得到类别数量分别为2、10、20 的3 个文本分类数据集,将其分别称作Cluster-2、Cluster-10、Cluster-20,为研究不同类别数量的文本分类数据集参与训练对模型生成摘要准确性的影响提供数据集支撑。

图4 文本分类数据集的构建流程Fig.4 Construction process of text classification datasets
4 评价指标与判别法
4.1 ROUGE 评价指标
ROUGE[27]是文本摘要领域的基准评价指标,基于摘要中n元词(n-gram)的共现信息来评价摘要的准确性。ROUGE-N和ROUGE-L 计算公式如下:

其中,n表示n⁃gram 的长度,{RS} 表示参考摘要,Countmatch(gramn)表示参考摘要与待测摘要中相同的n⁃gram 个数,Count(gramn)表示参考摘要中出现的n⁃gram 个数。
ROUGE-L 中的L 即为最长公共子序列(Longest Common Subsequence,LCS),计算公式如下:

其中,LCS(X,Y)表示参考摘要与待测摘要最长公共子序列的长度,m表示参考摘要的长度。
4.2 基于统计分布的判别法
ROUGE 对比参考摘要与待测摘要来判定摘要准确性,但是忽略了摘要句子在源文本中出现的位置信息。本文提出一种基于统计分布的判别法,从总体分布的角度判断待测摘要的准确性。基于统计分布的判别流程如图5 所示。

图5 基于统计分布的判别流程Fig.5 Discriminant process based on statistical distribution
本文将待测摘要表示为S={s1,s2,…,sn}、si={e1,e2,…,em},参考摘要表示为G={g1,g2,…,gn}、gi={t1,t2,…,tp},源文本表示为D={d1,d2,…,dn}、di={c1,c2,…,cq},其中,s、g、d分别表示S、G、D中的文本,e、t、c分别表示s、g,d中的句子,n表示测试集数据量,m、p、q分别表示s、g、d的句子数量。计算s1与d1的位置向量的具体步骤如下:1)定义雅卡尔相似系数,该系数通常用来判断句子之间是否冗余,计算公式如下:
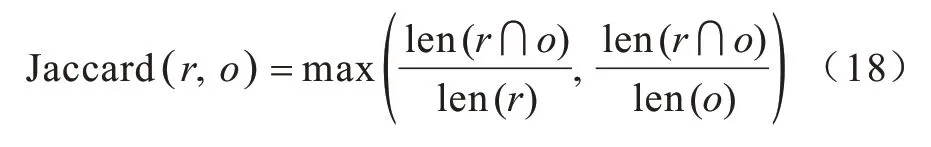
其中,r、o分别表示ei、cj中非冗余单词的集合,∩表示交集,len 函数计算集合的大小。
2)雅卡尔相似系数越高,cj替代ei的能力越强,寻求ei对应最高雅卡尔相似系数的cj。

5 实验与结果分析
5.1 实验设置
本文使用深度学习框架PyTorch实现6种单任务基线模型和6种多任务学习摘要模型,各个摘要模型基本架构及配置如表1所示,其中,Attention、Coverage分别表示注意力机制、覆盖度机制,Cluster表示使用文本分类数据集,Pointer-Generator默认使用注意力机制和指针网络。

表1 摘要模型基本架构及配置Table 1 Basic architecture and configuration of summarization models
在训练和测试期间,截断输入文本至400 个单词以内,限制生成摘要长度至120 个单词以内。所有模型的隐藏状态维度均设置为256 维,单词嵌入向量维度设置为128 维。本文没有使用预训练词向量,所有模型词汇表大小设置为50 000,所有模型的摘要任务采用Adagrad 优化器[28],初始化学习率设置为0.15,累加器的起始值设置为0.1,梯度剪裁阈值设置为2。文本分类任务使用Adam[29]优化器,初始学习率设置为0.001。所有模型均在单个GeForce GTX TITAN X 12 GB 显存GPU 上训练。在训练期间,设置数据块大小为16,防止多任务学习导致GPU 显存波动引起显存溢出。在测试期间,设置数据块大小为100,所有模型的摘要解码器的集束搜索尺寸设置为4。
5.2 结果分析
本文使用files2rouge 包测评所有模型生成摘要的ROUGE-1、ROUGE-2、ROUGE-L 在95%置信区间的标准分数,测试文本为CNNDM 测试集。6 种单任务基线模型的ROUGE 标准分数如表2 所示,结果显示Pointer-Generator 架构的性能优于传统Encoder-Decoder 架构,特征提取器(LSTM 和GRU)的选择对基线模型生成摘要准确性的影响较小。
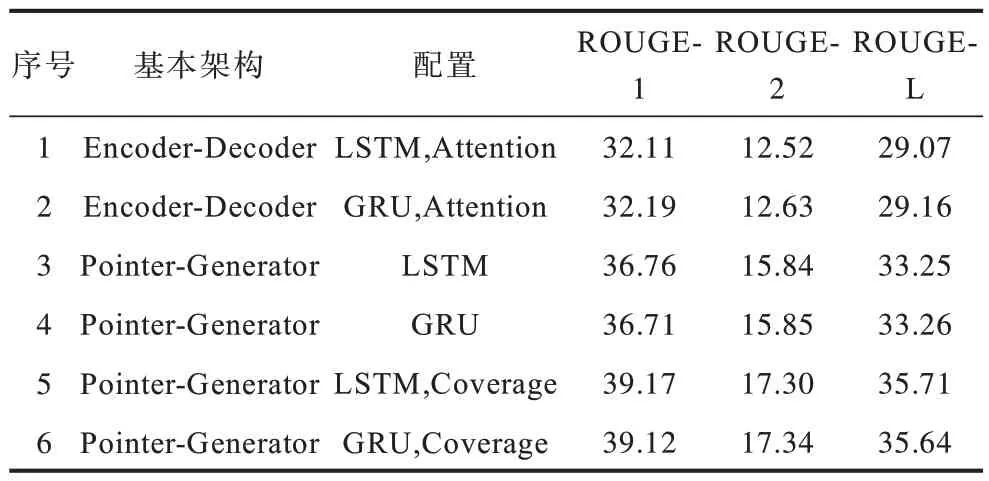
表2 单任务基线模型性能对比Table 2 Performance comparison of single task baseline models
多任务学习摘要模型的ROUGE 标准分数如表3 所示,结果显示:在ROUGE-1、ROUGE-L 指标上,6 种多任务学习摘要模型均能生成更准确的摘要,Multi-task(GRU,Cluster-10)相较于强基线模型Pointer-Generator(GRU,Coverage)分别在3个ROUGE指标上提高了0.23、0.17 和0.31 个百分点;在ROUGE-2 指标上,Cluster-10 参与训练后的模型优于性能最好的单任务基线模型。使用GRU 作为特征提取器的模型在部分指标上的提升略高于LSTM,这可能是数据集较大所致。文本分类数据集的选取对模型的生成性能影响较大。在ROUGE 指标上,使用Cluster-10 训练后的模型均生成了最准确的摘要。本文认为出现该结果的主要原因为:过大的类别数量影响文本分类的效果从而影响生成摘要的质量,过小的类别数量使得引入的抽象信息不够从而干扰摘要模型。

表3 多任务学习摘要模型性能对比Table 3 Performance comparison of summarization models with multi-task learning
本文将测试集参考摘要的分布向量作为基准,统计并对比3 种摘要模型生成待测摘要的分布向量,同时计算不同分布向量间的余弦相似度,具体结果如表4 所示。

表4 摘要模型的分布向量与余弦相似度统计Table 4 Distribution vector and cosine similarity statistics of summarization models
本文设置域的数量X=6 并过滤源文本句子数量小于X的样本。分析表4 数据可知,参考摘要共有43 656 个句子在源文本中找到替代句,在不同域中的分布呈现急速下降趋势,表明CNNDM 数据集中源文本头部的信息量较大。3 种模型生成的待测摘要分别有34 279、29 883、32 408 个句子能够找到替代句。与测试集参考摘要相比,模型生成的摘要更加倾向于头部信息提取。Pointer-Generator(LSTM,Coverage)生成摘要的句子数量少于Pointer-Generator(LSTM),其主要原因为覆盖度机制的引入缓解了重复生成问题。Multi-task(LSTM,Cluster-10)生成的摘要句子数量介于Pointer-Generator(LSTM,Coverage)和Pointer-Generator(LSTM)之间,本文认为这是因为多任务学习摘要模型学习到了分类数据集中的抽象信息,其在保证句子数量的前提下更加集中于第3 个和第4 个域中信息的提取,其生成摘要与测试集参考摘要最接近。
5.3 样例分析
本文通过样例分析以验证多任务学习摘要模型学习到了分类数据集中的抽象信息。测试集参考摘要与模型生成摘要的样例如下:
1)测试集参考摘要:
“shelley dufresne was arrested in september when a student at the high school she taught at started bragging about sleeping with two teachers.it was later revealed that the 16-year-old had sex with both dufresne and his former english teacher,24-year-old rachel respess.dufresne,32,pleaded not guilty to charges in november,but changed course on thursday when she admitted having sex with the teen.in a forgiving plea deal,dufresne will only have to attend a 90-day therapy program,stay away from the victim and turn in her teacher’s license.in exchange,the charge of carnal knowledge of a child will be dropped after her probation and she won’t have to register as a sex offender.however,dufresne is still awaiting an arraignment on charges for having a threesome with the same student and respess in a different parish.”
2)Pointer-Generator(LSTM):
“shelley dufresne,32,was arrested in september when a student at destrehan high school started bragging to friends at the st charles parish courthouse on thursday.she was arrested in september when a student at destrehan high school started bragging that he was sleeping with both of them.dufresne,32,was arrested in september when a student at destrehan high school started bragging that he was sleeping with both of them.”
3)Pointer-Generator(LSTM,Coverage):
“shelley dufresne,32,was arrested in september after the teen in question started bragging to friends at the st charles parish,louisiana school that he had slept with two teachers.an investigation later revealed that the unidentified teen had sex with both his current english teacher at the time,dufresne,and his english teacher from the prior year,24-year-old rachel respess-including an alleged a threesome with both at respess’s house.”
4)Multi-task(LSTM,Cluster-10):
“shelley dufresne confessed in court thursday to having sex with a 16-year-old student in exchange for a plea deal that gets her out of prison time.an investigation later revealed that the unidentified teen had sex with both his current english teacher at the time,dufresne,and his english teacher from the prior year.respess taught the same student english the year prior.though she originally pleaded not guilty to a count of obscenity,the original charge of carnal knowledge of a juvenile will be held for the three years dufresne is under probation for obscenity.”
对比样例显示,Pointer-Generator(LSTM)存在重复生成的问题(“dufresne,32,was arrested in september when a student at destrehan high school started bragging”出现了两次),Pointer-Generator(LSTM,Coverage)避免了此问题。但上述两种模型忽略了测试集参考摘要中“交换条件”的基本事实(“in exchange,the charge of carnal knowledge of a child will be dropped after her probation and she won’t have to register as a sex offender”),Multi-task(LSTM,Cluster-10)生成的摘要包括“交换条件”的事实(“in exchange for a plea deal that gets her out of prison time”)。在对部分研究样例进行比对分析后,本文发现多任务学习摘要模型更容易学习到时间点信息以及比较隐蔽的逻辑信息。
6 结束语
本文结合文本分类辅助任务,提出一种多任务学习摘要模型,使用K-means 聚类算法构建Cluster-2、Cluster-10 和Cluster-20 文本分类数据集,利用基于统计分布的判别法计算待测摘要与测试集参考摘要的分布向量在向量空间中的余弦相似度,从总体分布的角度判断待测摘要的准确性。实验结果表明,与现有摘要模型相比,该模型生成的摘要更准确。由于Transformer 模型架构具有优越的并行化序列处理能力以及特征提取能力,因此后续可将Transformer模型架构和其他相关任务引入多任务学习摘要模型中,进一步提升其在不同摘要数据集中的摘要生成质量。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
中国生物医学工程学报(2019年6期)2019-07-16
成都信息工程大学学报(2018年3期)2018-08-29
制造技术与机床(2017年7期)2018-01-19
自动化学报(2016年3期)2016-08-23
电测与仪表(2016年5期)2016-04-22
电子器件(2015年5期)2015-12-29
