
结构约束的对称低秩表示子空间聚类算法
2021-04-29 03:21:00鲍灵浪
计算机工程 2021年4期
陶 洋,鲍灵浪,胡 昊
(重庆邮电大学通信与信息工程学院,重庆 400065)
0 概述
在现实世界中,高维数据的局部结构和全局结构都较为复杂,且此类数据通常位于多个低维子空间的并集中。基于这一事实,许多对应子空间的聚类算法相继被提出,用于解决高维数据的聚类问题。子空间聚类方法将数据分割至对应的子空间,用以揭示高维数据的潜在子空间结构,目前已被广泛应用于显著性检测[1]、运动分割[2]、人脸聚类[3-4]和图像分割[5]等领域。将基于表示的方法与谱聚类算法[6-8]相结合是其中一种具有代表性的方法,其先从给定的样本数据中学习数据之间的相似度矩阵,再将相似度矩阵应用于谱聚类中以获得最终的聚类结果。此类方法成功的关键是构造一个“好”的相似度矩阵。文献[9]提出稀疏子空间聚类(Sparse Subspace Clustering,SSC)方法,通过l1范数最小化技术找到每个数据向量的稀疏表示矩阵,但其解缺乏全局约束。文献[10]提出一种低秩表示(Low-Rank Representation,LRR)聚类方法,利用矩阵的核范数来查找所有数据的最低秩表示,从而捕获数据的全局结构。文献[11]提出一种对称约束的低秩表示聚类(LRRSC)方法,将对称约束应用于低秩表示中以提高原始低秩表示算法的聚类精度。文献[12]通过将高斯场与调和函数合并到LRR 框架中,提出一种非负低秩表示聚类方法,在一个优化步骤中同时完成了相似度矩阵构建和子空间聚类。文献[13]提出一种局部与结构正则化的低秩表示(LSLRR)聚类方法,该方法同时考虑数据的局部几何结构和全局块对角线结构,弥补了经典LRR 聚类方法的不足。
通过SSC 获得的表示系数矩阵虽然具有很强的子集选择能力,可以消除不同类型的样本,但是矩阵过于稀疏,缺乏对相似样本的聚集能力,从而无法有效地聚类高度相关的样本数据。同理,虽然基于LRR 的方法可以聚合高度相关的数据,但是生成的表示系数矩阵非常密集,缺乏区分不同类型样本的能力且无法引入数据的标签信息。针对上述问题,本文提出一种结构约束的对称低秩表示(Structure-Constrained Symmetric LRR,SCSLR)算法用于子空间聚类。通过引入结构约束和对称约束平衡低秩表示系数矩阵的类间稀疏性和类内聚集性,从而更准确地揭示数据的子空间结构。
1 相关工作

基于谱聚类的子空间聚类方法首先找到一个表示矩阵Z∈ℝn×n,以表示其他样本对选定样本进行重建的贡献度(见式(1)),然后通过对表示矩阵Z施加不同的约束项则,构造包含不同信息的相似度矩阵。

在此方面,LRR 是最具代表性的表示方法之一,计算公式为:

其中,Q是Z和E的惩罚函数,Ω是约束项。
文献[14]通过在LRR 模型中定义Z≥0 实现PSD约束。文献[11]通过定义Z=ZT保证每对数据点之间的权重具有一致性。文献[15]通过定义Q(Z,E)=λ1‖Z‖1+λ2‖E‖2,1构造稀疏低秩表示矩阵。文献[9]证明了低秩表示可以获得块对角解,当训练样本足够时,其为子空间聚类的理想方法,但是当训练样本不足时,其效果非常差。本文对低秩表示的目标函数施加结构约束和对称约束,以减小核函数对秩的惩罚,并获得具有结构约束的对称低秩图。利用表示矩阵Z*构造相似度矩阵的计算模型,如式(3)所示:

在此基础上,本文将获得的相似度矩阵W应用于谱聚类方法(如文献[16]方法)中,得到最终的聚类结果。
2 引入结构和对称约束的LRR 子空间聚类
在子空间聚类研究中,对低秩表示解的结构施加约束能够获得较好的聚类结果。因此,本文提出结构约束的低秩表示子空间聚类方法,将结构约束和对称约束引入低秩表示的解,以构造一个加权稀疏和对称低秩的亲和度图。其中,低秩约束用于捕获数据的全局结构,结构约束用于捕获数据的局部线性结构,并且对称约束可以确保每对数据点之间的权重具有一致性。事实上,结构约束即加权稀疏表示,其能揭示同类样本之间的强亲和力与不同类样本之间的强分离性,即类内强亲和性与类间强分离性。
为从数据的结构中获得表示模型,可对LRR 模型解的结构施加约束项。本文通过在目标函数中添加|约束和zij=zji约束来限制解的结构(见式(4)),与仅考虑核范数的目标函数相比,这样不仅可以提高解的秩,而且还可以保留数据点间的内在几何结构,获得更优的子空间聚类效果。

为使所获得的Z对噪声更具鲁棒性并且避免NP 问题,构建结构约束的对称低秩表示(SCSLR)模型,如式(5)所示:

实际上,当数据带有标签时,可以将SCSLR 看作半监督的LRRSC[8]。而对于不带标签的数据,可以利用数据的结构来构造权重R,即权重由角度确定。这意味着来自同一类的数据点之间的角度越小则样本权重就越小,反之则越大。通过数据标准化处理,计算出数据点之间内积的绝对值后,理想的权重矩阵R构造如下:

2.1 模型优化
本文使用交替极小化方法求解式(5)中的目标函数。引入辅助变量J和L,将式(5)所示模型转换为:
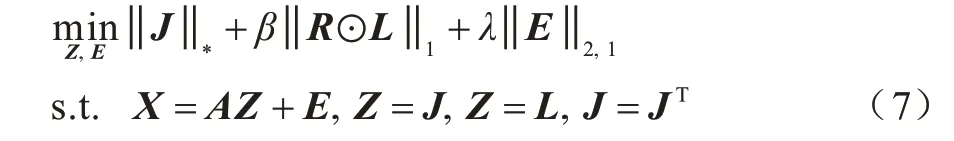
在式(7)所示模型中,增强拉格朗日函数表示为:
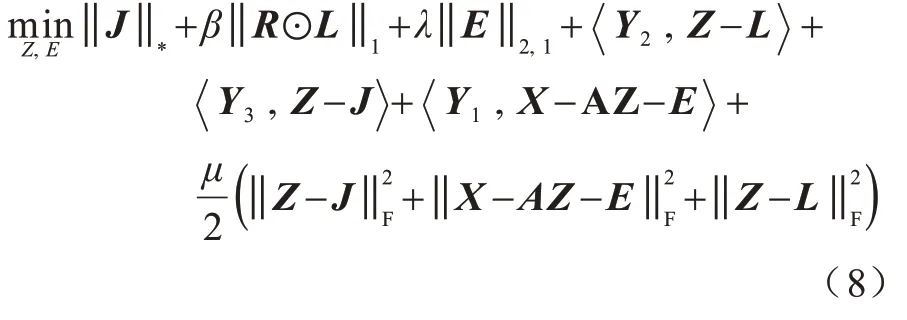
利用算法1 对式(8)所示函数进行推导,获得所有子问题的解,并且数据矩阵X本身可以直接用作字典[4]以捕获数据集X的基础行空间。本文使用奇异值阈值运算[11,17]分步解决变量J和L的优化问题。
算法1式(8)所示模型的交替极小化方法求解
输入数据矩阵X,参数λ>0
输出表示矩阵Z∗
初始化Z=J=L=0,E=0,Y1=Y2=Y3=0,μmax=1010,ρ=1.1,ε=10-6
1)固定其他变量,更新J:

2.2 结构约束对称低秩图的构造


在此基础上,应用NCuts 算法将样本分割为相应的子空间。假设将图G=(V,E,W)分为A和B两部分,且这两部分满足条件A∪B=V和A∩B=Ø,则分割公式如下:
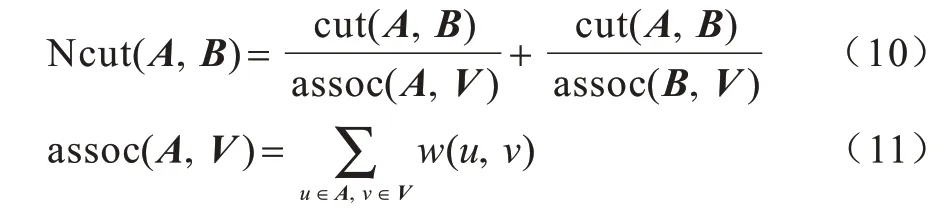
式(10)代表A和B两部分的类间相似度,其值越小越好,式(11)则代表A部分和整体节点V的权重之和。求解出Ncut 的最小值即能得到较好的分割结果。
SCSLR 算法描述如下:
算法2SCSLR
输入数据矩阵X,参数λ>0
输出聚类结果。
1)根据算法1 获得表示矩阵Z∗。
2)根据式(9)求出相似度矩阵W。
3)将W输入到标准分割算法NCuts 中,获得聚类结果。
3 实验结果与分析
在Extended Yale B人脸数据集[18]和Hopkins 155运动分割数据集[19]上进行实验,以证明本文算法的收敛性。图1 显示了目标函数值和迭代次数的关系。可以看出,在前几次迭代中,目标函数值急剧减小,然后趋于平稳,说明SCSLR 能够在几个迭代步骤后收敛到局部最优解。

图1 SCSLR 目标函数值与迭代次数的关系Fig.1 Relationship between objective function value of SCSLR and number of iterations
同样使用上述两个基准数据集,通过与低秩表示(LRR)[10]、稀疏子空间聚类(SSC)[9]、半正定低秩表示(LRR-PSD)[14]、局部子空间相似(LSA)[20]、低秩子空间聚类(LRSC)[21]和对称约束的低秩表示(LRRSC)[11]这六种有效的子空间聚类算法进行实验比较,评估SCSLR 的聚类效率和鲁棒性。对比算法的源代码从相应作者的主页获得。选取计算子空间聚类误差来评估算法性能,如式(12)所示:

其中,Nerrror表示错误分类的数据点的数量,Ntotal表示总数据点的数量。在实验过程中,LRR、LSA、SSC、LRSC、LRRSC 和LRR-PSD 的参数设置由其作者提供或手动调整。SCSLR 中包含β、λ、α三个参数。参数λ和β用于在低秩表示、加权稀疏表示和误差之间进行平衡,如果β较大,则意味着模型强调加权稀疏性而不是低秩性,反之亦然。当数据“干净”时,λ应相对较大,反之亦然。参数α的范围为1~4,用于提高低秩表示的分离能力。
3.1 人脸数据集上的聚类效果
在Extended Yale B 人脸数据集上进行聚类效果对比。该数据集包含38 个对象,每个对象由在不同光照下拍摄的64 张图像组成,分辨率为192 像素×168 像素,共2 414 幅图像,本实验将图像分辨率调整为48 像素×42 像素。图2 为Extended Yale B 数据集的前10 个对象的示例图像。人脸聚类即是根据每个样本的特征从多个样本中对每组具有固定姿势和变化照度的人脸图像进行聚类操作。由于人脸图像位于9 维子空间的并集,因此可以通过子空间聚类来解决上述问题。本文使用Extended Yale B 数据集前10 个对象的640 张正面人脸图像。为进行公平比较,直接使用48 像素×42 像素的图像而不进行预处理,通过PCA将这些图像分别投影到500 维、300 维、100 维、50 维的特征空间。
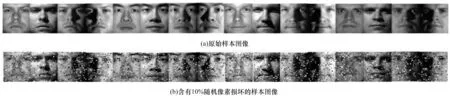
图2 Extended Yale B 数据集前10 个对象的示例图像Fig.2 Example images of top10 objects on Extended Yale B dataset
由于SCSLR 算法的聚类性能受到β、λ、α参数的影响,并且聚类结果在参数λ和α的更改过程中受到很大影响,因此笔者根据经验固定参数β=0.03,而仅改变λ和α。图3 显示了SCSLR 的平均聚类误差随参数λ和α不同组合的变化。通常,较小的α会导致较差的聚类性能,但较大的α必须配合缩小λ的范围才能获得较好的性能。由图3(a)~图3(c)可以看出,当λ∈{0.50,0.75,…,2.50}且α=1 时,聚类误差高达50%。由图3(d)可以看出:当λ范围在1.00~1.75 之间且α=1 时,聚类误差在10.16%~17.34%之间变化;当λ范围在1.00~1.75 之间且α=2 时,聚类误差在1.25%~2.81%之间变化;当λ范围在1.00~1.75 之间且α=3 时,聚类误差在1.72%~11.56%之间变化。总体而言,SCSLR 必须缩小λ的范围至1.00~1.50 才能获得更好的结果。由图3(e)可以看出,在通过PCA 获得的50 维数据上,SCSLR 表现良好。总体而言,当λ和α的组合恰当时,SCSLR 具有稳定且理想的聚类性能。
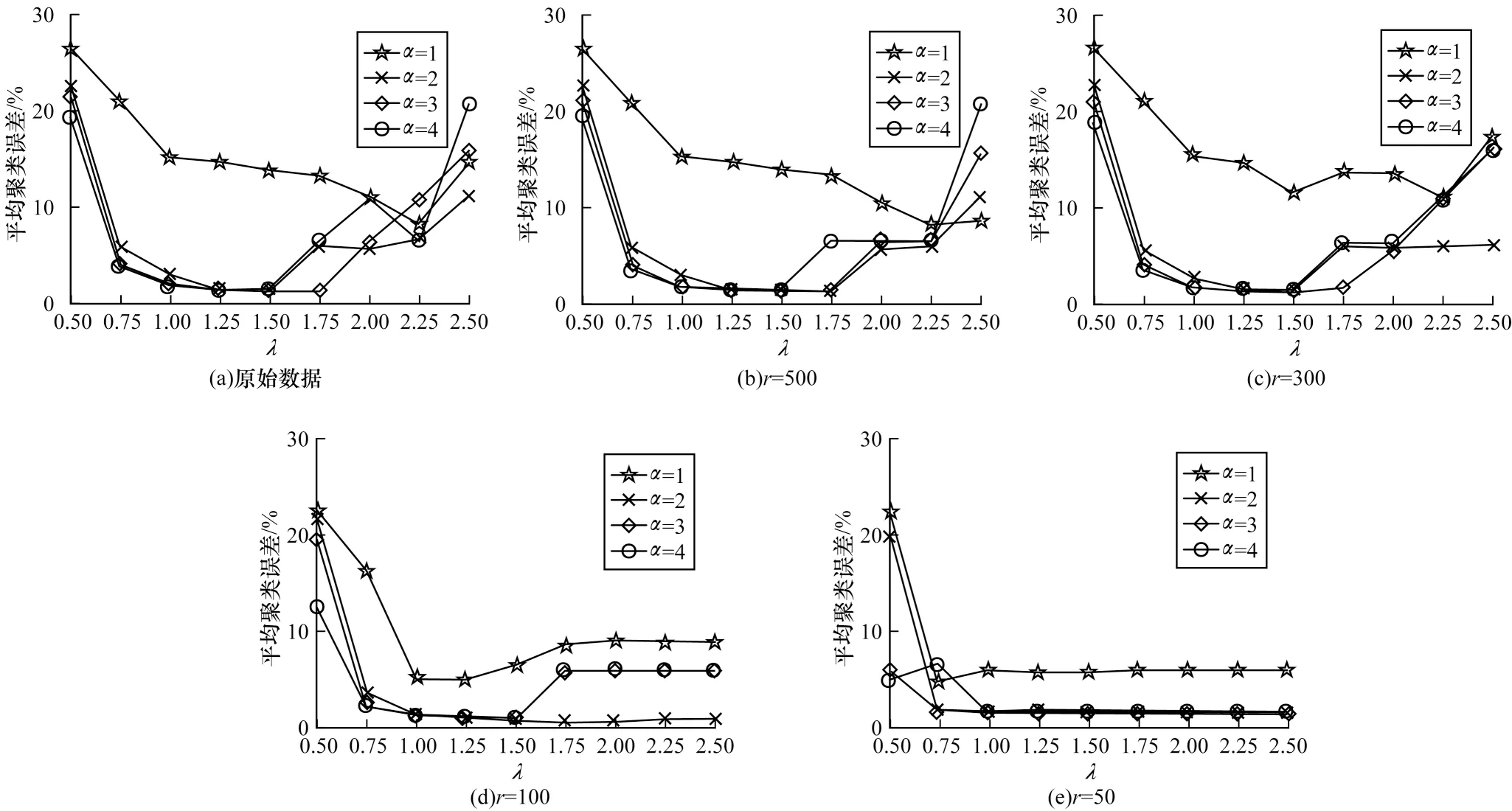
图3 Extended Yale B 数据集上SCSLR 的平均聚类误差随参数λ 和α 的变化Fig.3 Change of average clustering error of SCSLR varies with parameter λ and α on Extended Yale B dataset
Extended Yale B 数据集上不同算法的平均聚类误差对比如表1所示,其中加粗数据为最优数据。可以看出,SCSLR 在原始数据和通过PCA 获得的500 维、300维、100维数据上较其他算法表现出更优秀的聚类性能。例如,r=100时SCSLR 的平均聚类误差非常低,仅为1.25%,与LRR、LRSC、LRR-PSD、LSA 和SSC 相比聚类精度提高了至少20%。虽然LRRSC在总体上取得了良好的结果,但SCSLR的聚类精度仍比LRRSC提高了2.3%~3.1%。上述结果表明,在具有非预期噪声的数据上,SCSLR算法所获得的表示矩阵可以显著提高聚类精度。

表1 Extended Yale B 数据集上不同算法的平均聚类误差Table 1 Average clustering error of different algorithms on Extended Yale B dataset %
3.2 运动分割数据集上的聚类效果
Hopkins 155 运动分割数据集包含155 个单独的序列,每个序列位于一个低维子空间中,并包含从两个或三个运动中提取的39 个~550 个数据向量。运动分割是指将多个刚性运动对象的特征轨迹聚类到与每个运动对象相对应的子空间的问题。在仿射投影模型下,单个刚性运动对象的特征轨迹位于低维线性子空间中。因此,可以通过子空间聚类方法解决运动分割问题。
对于每个运动对象,使用跟踪器自动提取运动轨迹。为评估SCSLR 在运动分割中的性能,本文设计了以下两种实验方案:实验方案1 使用原始轨迹的特征轨迹,实验方案2 使用PCA 将原始数据投影到4n维子空间(n是子空间的数量)上。特别地,将系数的总和设置为1,因为它们都在仿射子空间中实现。
β=0.03 情况下SCSLR 在Hopkins155 数据集上平均聚类误差随参数λ和α的变化如图4所示。由图4(a)和图4(b)可以看出,SCSLR 的聚类误差在不同参数设置下表现出相似的趋势。当α=2 时,图4(a)中SCSLR的聚类误差在1.37%~2.53%之间变化,而图4(b)中SCSLR 的最低聚类误差仅为1.43%。
所有算法在Hopkins 155 数据集上的平均聚类误差和时间对比如表2 和表3 所示,其中加粗数据为最优数据。可以看出,SCSLR 的平均聚类误差明显低于其他算法,分别为1.37%和1.43%,与LRRSC 相比分别提高了0.13%和0.13%,证实了结构约束的对称低秩表示在揭示子空间自然结构方面具有优势。同时由于LRR会对系数矩阵进行处理,因此其性能优于SSC,这也证实了使用低秩表示的结构来构造相似度矩阵是有必要的。此外,在两个实验中,LRSC、LRR-PSD 和LSA 均出现了较高的聚类误差。

图4 Hopkins 155 数据集上SCSLR 的平均聚类误差随参数λ 和α 的变化Fig.4 Change of average clustering error of SCSLR varies with parameter λ and α on Hopkins 155 dataset

表2 Hopkins 155数据集上不同算法的聚类性能(实验方案1)Table 2 Clustering performance of different algorithms on Hopkins 155 dataset(experimental scheme 1)

表3 Hopkins 155数据集上不同算法的聚类性能(实验方案2)Table 3 Clustering performance of different algorithms on Hopkins 155 dataset(experimental scheme 2)
4 结束语
针对子空间聚类问题,本文假设高维数据近似位于多个子空间的并集中,提出一种结构约束的对称低秩表示算法SCSLR。将对称约束和结构约束融合到高维数据表示的低秩属性中,同时捕获高维数据的全局对称结构和子空间的加权局部线性结构,从而提高聚类性能。SCSLR 的实质是挖掘一个可以体现子空间自然结构的表示矩阵,通过进一步利用该矩阵主方向的角度信息得到用于谱聚类的相似度矩阵。在基准数据集上的实验结果验证了该算法优秀的聚类性能和鲁棒性。后续将降低SCSLR 在处理大规模数据集时的计算复杂度,同时针对低秩表示算法寻找矩阵最优解时需要进行多次迭代的问题,寻找更有效率的求解算法。
猜你喜欢
加油站服务指南(2021年4期)2021-07-21 02:29:22
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学年刊A辑(中文版)(2020年1期)2020-05-19 00:30:30
数学物理学报(2019年6期)2020-01-13 06:08:16
电子测试(2017年15期)2017-12-18 07:19:27
数学物理学报(2017年5期)2017-11-23 07:51:31
智能系统学报(2015年4期)2015-12-27 09:38:39
人生十六七(2015年6期)2015-02-28 13:08:38
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
