
基于分层图像融合的虚拟视点绘制算法
2021-04-29 03:21:26蔡李美李新福田学东
计算机工程 2021年4期
蔡李美,李新福,田学东
(河北大学网络空间安全与计算机学院,河北保定 071000)
0 概述
基于深度图像的绘制(Depth Image Based Rendering,DIBR)技术是自由视点电视中的关键技术[1]。通过纹理图及其对应的深度图能够绘制出任意视点的虚拟图像,但目前DIBR技术绘制的虚拟图像依然存在重叠、空洞等问题,影响图像质量,主要原因是由于遮挡和深度图的不连续,在三维图像变换后会出现多个像素点映射到同一位置,导致背景像素覆盖前景像素的重叠问题。此外,由于物体之间的遮挡,在参考视点中被前景物体遮挡的区域绘制到目标视点后会变得可见,从而形成空洞区域。
为提高绘制后目标视点视图的质量,国内外许多学者对此展开了研究。已有的方法可以分为在三维图像映射前进行处理、对三维图像变换过程进行处理和在三维图像变换后进行处理。在三维图像映射前进行处理的方法,如文献[2]对深度图中的背景区域进行滤波,在减少空洞的同时能够减轻几何失真,文献[3-5]将深度图物体边界扩展到彩色图像的过渡区域,解决伪影和空洞问题,文献[6]利用具有深度置信度的图像引导TGV 模型使深度图和纹理图边缘对齐,对深度图进行恢复,文献[7]采用图像分割技术对图像进行分割处理再进行三维映射,解决像素点的错误映射问题。对三维图像变换过程进行处理的方法,如文献[8]采用邻域插值法进行裂缝填充,该方法只适合于空洞区域较小的情况,文献[9]通过对多个映射像素点的深度和空间位置信息进行加权插值操作来实现裂缝的填充。在三维图像变换后进行处理的方法,采用基于样本的图像修复方法[10]或双向DIBR 技术[11]对虚拟图像进行后处理,如文献[12-13]将深度信息引入优先级计算中,提高修复准确性,文献[14]将待填充块的优先级以背景纹理优先,抑制前景纹理的错误延伸,文献[15]利用深度图与最大化类间方差算法,解决相对背景的识别问题,文献[16]利用深度值对融合后的空洞进行判断,将外侧一定范围的背景像素复制到前景,能够减轻前景纹理的扩散,文献[17]对深度和纹理图进行分层映射解决了伪影和裂缝问题,但融合后仍需要进行剩余小空洞的填充。
针对三维映射后出现的重叠问题和双向DIBR图像融合后对特殊位置空洞进行处理时出现的前景像素扩散问题,本文提出一种基于分层图像融合的虚拟视点绘制算法。通过消除双向DIBR 映射后左、右虚拟视点图像的伪影,利用深度图对左、右虚拟视点图像进行分层融合,填充分层融合后背景图像中的空洞,最终生成虚拟视点图像。
1 双向DIBR 绘制技术
1.1 三维图像变换
双向DIBR 绘制技术是分别将左、右参考视点的参考图像和其对应的深度图像通过三维图像变换生成任意位置的虚拟视点图像,其中,三维图像变换技术是虚拟视点绘制过程中的关键技术,分为以下两个步骤:
步骤1利用深度信息将参考图像的每一个像素点投影到三维欧式空间,计算公式如下:

其中,(Xw,Yw,Zw)T表示三维欧式空间中像素点的位置,pr=(ur,vr)表示参考图像平面上像素点的位置,Kr、Rr、tr分别表示参考图像摄像机坐标系的内参矩阵、旋转矩阵和平移矩阵,λr为参考图像摄像机缩放系数,取值为深度值。
步骤2将三维欧式空间中的点投影到虚拟视点图像平面上,计算公式如下:

其中,pv=(uv,vv)表示虚拟视点图像平面上像素点的位置,Kv、Rv、tv分别表示虚拟视点图像摄像机坐标系的内参矩阵、旋转矩阵和平移矩阵,λv是虚拟视点图像摄像机缩放系数,取值为深度值。
1.2 图像融合技术
双向DIBR 技术利用不同视点之间的信息冗余性,即左侧虚拟视点图像中的空洞在右侧虚拟视点中不一定是空洞,因此可以用右侧虚拟视点的信息进行填补,反之亦然。传统的基于距离的图像融合公式如下:

其中,Iv(u,v)是虚拟视点图像在(u,v)处的像素值,IL(u,v)、IR(u,v)分别表示映射后左侧虚拟视点图像和右侧虚拟视点图像在(u,v)处的像素值,α为权重因子,由参考视点与虚拟视点之间的距离决定,计算公式如下:

其中,tV、tL、tR分别为虚拟视点、左侧参考视点和右侧参考视点的平移向量。
传统的基于距离的图像融合方法能够消除由遮挡引起的虚拟图像中的大面积空洞,但是在图像直接融合后会出现前景物体中残留背景像素的重叠问题,如图1(a)所示。由于物体边缘的前景像素映射到背景中,在直接图像融合后前景物体两侧均出现伪影,如图1(b)所示。此外,图像融合后仍会剩余小部分空洞,如图1(c)所示。本文将空洞周围在水平或垂直方向含有前景像素的这类空洞称为“特殊位置空洞”,由于空洞周围存在前景像素,直接融合后很难处理。

图1 传统图像融合方法Fig.1 Traditional image fusion method
2 分层图像融合方法
为解决传统图像融合方法存在的问题,本文提出一种基于分层图像融合视点绘制算法。利用双向DIBR 映射得到左、右虚拟视点图像,再分别对其进行伪影去除、前景和背景分割、分层融合等操作最终得到虚拟视点处的图像。虚拟视点生成算法流程如图2 所示,分层图像融合是本文算法的重点,主要是对重叠问题和空洞问题的后处理。
2.1 图像分层预处理
预处理工作包含两部分:
1)消除裂缝。由于像素点位置的舍入误差,在三维图像变换过程中,参考图像的像素点并不一定落到虚拟视点图像的整数像素位置上,因此形成裂缝。对正向映射得到的深度图进行中值滤波,再利用滤波后的深度图和虚拟视点图像进行逆向映射[18]消除裂缝,图3(a)和图3(b)为裂缝消除后的左、右虚拟视点图像。

图3 裂缝去除后的虚拟图像Fig.3 Virtual image after crack removal
2)消除伪影。由于深度图和纹理图在前景物体边缘处的不一致,导致前景物体的边界像素点会被错误地映射到背景区域。解决伪影的一种简单有效的方法是利用形态学对空洞区域进行膨胀,将处于背景区域的伪影作为空洞进行处理。具体步骤如下:
(1)提取深度图的掩模图记为mask,对深度值Depthv(u,v)为0 的空洞区域进行标记,公式如下:

(2)对提取的掩模图mask 进行形态学膨胀操作,计算公式如下:

其中,S表示大小为5×5 的矩形结构元素,⊕表示形态学的膨胀操作。利用空洞膨胀后的掩模图M就可以得到消除伪影后的左、右虚拟视点图像,如图4(a)和图4(b)所示。

图4 伪影去除后的虚拟图像Fig.4 Virtual image after artifact removal
2.2 基于分层图像融合的视点绘制
2.2.1 前景和背景分割
将深度信息引入到融合算法中,通过权重比例进行融合能够在一定程度上解决重叠问题,但不是使用原始真实的前景像素值进行填充[19]。本文算法对重叠问题进行后处理,在图像融合之前先对左、右虚拟视点图像进行前景和背景分割,可以有效地将存在于前景物体中的背景像素分割到背景图像中,这时原来前景物体中的背景像素区域将变成空洞区域,然后再进行分层融合,则使用的是真实的前景像素。
利用Canny 算子检测深度图中深度值存在突变的物体边缘区域如图5 所示,本文使用的深度值是场景的实际深度值。

图5 Canny 算子边缘检测Fig.5 Canny operator edge detection
根据检测得到的物体边缘深度值的均值求取前景和背景分割的深度阈值T,通过深度阈值T指导左、右虚拟视点图像的前景和背景分割。若左侧虚拟视点在(u,v)的深度值DepthL(u,v)小于深度阈值T,则认定为前景;若DepthL(u,v)大于深度阈值T,则认定为背景,因此得到左侧前景、背景分割图像ILf(u,v)、ILg(u,v)的公式如下:


同理,可得右侧前景和背景分割图像IRf(u,v)和IRg(u,v),最终的前景和背景分割图像如图6 所示。

图6 前景和背景分割图像Fig.6 Foreground and background segmentation image
2.2.2 图像分层融合
根据深度阈值分割得到的左侧虚拟视点前景和背景图像ILf(u,v)、ILg(u,v)以及右侧虚拟视点前景和背景图像IRf(u,v)、IRg(u,v), 利用基于距离的融合方法进行分层图像融合,可以使重叠问题得到解决。左侧前景图像和右侧前景图像在像素点(u,v)处进行融合得到虚拟视点前景融合图像If(u,v),公式如下:

同理,可得背景融合图像Ig(u,v),此时,进行分层融合后的前景物体中已经不存在背景像素,如图7(a)所示,融合后的背景图像只有背景像素,如图7(b)所示。

图7 分层融合后的虚拟图像Fig.7 Virtual image after layered fusion
2.2.3 空洞收缩和背景填充
为尽可能地保留原始像素的真实值,本文提出一种空洞收缩的处理方法对伪影消除过程中扩大的空洞区域进行收缩。首先利用伪影去除后的前景融合图像If(u,v)和未进行空洞膨胀的前景融合图像Inf(u,v),对需要空洞收缩区域进行标记holeshrink,再根据标记后的图像指导空洞收缩,公式如下:
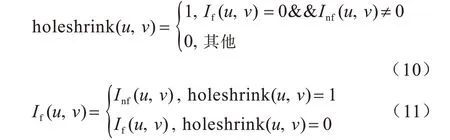
在式(11)中,If(u,v)是最终空洞收缩后的前景融合图像,如图8(a)所示,同理可得最终空洞收缩后的背景融合图像Ig(u,v),如图8(b)所示。

图8 空洞收缩后的前景和背景融合图像Fig.8 Foreground and background fusion image after holes contraction
在空洞的后处理中,特殊位置空洞的处理最为关键。本文对只含有背景像素的背景融合图像Ig进行空洞填充,由于周围不存在前景像素,因此可以有效地解决特殊位置空洞的前景扩散问题。
考虑到用于空洞填充的经典的Criminisi 算法的复杂度相对较高,本文利用大小为W=(2n+1)×(2n+1)窗口求像素均值方法对Ig进行背景空洞的填充。
最后将前景融合图像If覆盖空洞填充后的背景融合图像Ig得到虚拟视点处的图像,公式如下:

其中,Ivir(u,v)为最终的虚拟视点图像,如图9 所示。

图9 分层融合后的虚拟视点图像Fig.9 Virtual viewpoint image after hierarchical fusion
3 实验与结果分析
为验证本文算法的有效性,实验将本文算法与经典Criminisi算法、文献[16]改进的相邻像素填充算法、文献[19]改进的视点合成算法、文献[20]深度引导的视点绘制算法进行主观和客观的比较。采用由微软研究院的交互视觉媒体组提供的Ballet和Breakdancers图像测试序列进行实验,共8 个视点,每个视点的纹理图和深度图均为100帧,图像分辨率为1 024像素× 768像素。在三维图像变换时,对于Ballet测试序列,以Cam3和Cam5 作为参考视点,以Cam4 作为目标视点,对于Breakdancers 测试序列,以Cam2 和Cam4 作为参考视点,以Cam3 作为目标视点,在不同帧之间进行了实验对比。Criminisi算法中的匹配块的大小设置为9×9,匹配源图是整幅虚拟图像。
不同算法之间和不同帧之间的主观质量对比如图10~图12 所示。

图10 Ballet 序列重叠问题对比结果Fig.10 Comparison results of Ballet sequence overlap problems

图11 Ballet 序列空洞问题对比结果Fig.11 Comparison results of Ballet sequence hole problems

图12 Breakdancers 序列空洞问题对比结果Fig.12 Comparison results of Breakdancers sequence hole problems
从图10 可以看出,对于重叠问题,Criminisi 算法、文献[16]算法、文献[19]算法在胳膊处均存在背景像素,文献[20]利用深度进行插值避免背景像素覆盖前景像素,本文算法用真实的前景像素填充背景像素。从图11 和图12 可以看出,对于处于特殊位置的空洞,其他4 种算法均出现了前景像素的错误扩散,这是由于Criminisi 算法进行空洞填充时不区分前景和背景像素进行逐层收缩,受前景像素的干扰较大。文献[16]利用一定范围的背景像素替换前景像素,对于特殊位置空洞仍会出现前景纹理的扩散,文献[19]同样受到前景像素的干扰,文献[20]降低了前景像素的干扰。将前景和背景进行分层融合,能够排除前景像素的干扰,避免前景纹理出现在背景中。
为进一步验证本文算法的有效性,采用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似度(Structural Similarity,SSIM)作为客观质量的评价指标,其中,PSNR 值越高,SSIM 值越接近于1,则表明图像的质量越好。不同算法在Ballet 和Breakdancers 图像测试序列上的PSNR 比较如图13所示,可以看出本文算法和其他4 种算法相比具有一定的优势,尤其是在Ballet、Breakdancers 图像测试序列中,存在个别图像帧的PSNR 值低于其他4 种算法,但是整体上仍高于其他4 种算法。

图13 不同序列的PSNR 比较Fig.13 PSNR comparison of different sequences
表1 和表2 给出了不同测试序列以及不同算法之间的平均PSNR 值和SSIM 值,其中,ΔPSNR1 表示Ballet 序列中本文算法的PSNR 值与其他4 种算法PSNR 的差值,ΔSSIM1 表示本文算法的SSIM 值和其他4 种算法的SSIM 的差值,同理,ΔPSNR2 和ΔSSIM2 表示Breakdancers 序列中的差值。通过表1和表2 可以看出本文算法优于其他算法。

表1 不同算法的平均PSNR 比较Table 1 Comparison of average PSNR of different algorithmsdB

表2 不同算法的平均SSIM 比较Table 2 Comparison of average SSIM of different algorithms
4 结束语
本文针对三维映射后出现的重叠和空洞问题,提出一种基于分层图像融合的视点绘制算法。对左、右虚拟视图空洞区域进行膨胀来消除伪影,利用深度图进行前景和背景分割以及分层融合解决重叠问题,对融合后的背景图像进行填充解决特殊位置空洞问题。实验结果表明,与经典Criminisi等算法相比,本文算法绘制出的图像质量较高。但随着场景复杂度的增加,依靠单阈值进行前景和背景分割会降低绘制图像的准确率,为提高绘制图像的质量,进行合理的多阈值图像分割将是下一步的研究内容。
猜你喜欢
计算机应用(2019年3期)2019-07-31 12:14:01
故事作文·高年级(2017年2期)2017-03-01 13:03:27
软件导刊(2016年9期)2016-11-07 22:22:57
科技视界(2016年2期)2016-03-30 11:17:03
河南电力(2016年5期)2016-02-06 02:11:24
新闻传播(2015年20期)2015-07-18 11:06:46
新闻前哨(2015年2期)2015-03-11 19:29:22
中国水利(2015年5期)2015-02-28 15:12:40
世界科学(2013年11期)2013-03-11 18:09:47
上海大学学报(自然科学版)(2012年5期)2012-10-16 07:23:36
