
基于重用信息的非易失性缓存动态旁路策略
2021-04-29 03:21陈玲玲李建华
计算机工程 2021年4期
焦 童,陈玲玲,安 鑫,李建华
(合肥工业大学计算机与信息学院,合肥 230009)
0 概述
近年来,片上多核处理器集成核心的数量日益增多,对最后一级缓存(Last-Level Cache,LLC)的容量需求逐渐增加。受存储密度限制,传统静态随机存取存储器(Static Random Access Memory,SRAM)的LLC 在整个芯片上面积占比逐渐增大。此外,已发展到深亚微米级的半导体技术以及急剧增加的SRAM 静态能耗对片上LLC 性能提出更高要求。
当前电子自旋转移矩随机存取存储器(Spin-Torque Transfer Random Access Memory,STT-RAM)、相变存储器等非易失性存储器(Non-Volatile Memory,NVM)具有良好的可扩展性、极低的静态能耗以及较大的存储密度,此类新兴存储器可提高片上缓存系统的性能并降低其能耗[1-3]。然而新型非易失性存储器的读写操作具有不同的访问延迟和能耗,目前大部分基于NVM技术的缓存写操作延迟和能耗是读操作的几倍甚至几十倍[4-5]。
针对NVM 等非对称访问缓存中写操作的高延迟和高能耗问题,在进行旁路决策时应考虑缓存块分配是否合理。本文通过分析LLC 中缓存块的重用信息,提出一种基于缓存块重用的ReBP动态旁路策略,从LLC缺失填充和上级缓存写回两方面进行旁路分析,以提升非易失性缓存系统的能效。
1 相关工作
近年来,国内外研究人员采用多种方法减少STTRAM 缓存的能耗,并通过预测数据块写入频率来判断能否将数据写入STT-RAM 缓存。文献[6-7]提出一种写预测辅助STT-RAM 缓存的DASCA 系统来预测每个写入请求是否为无效写入,由于无效写入数据在下一个写入请求之前不会重用,因此DASCA 可避免无效数据写入STT-RAM 缓存。文献[8-10]提出一种基于统计的非对称缓存旁路方式SBAC,其从能耗判断是否将数据块插入STT-RAM 缓存中,如果读取和写入操作次数已知,则可计算有无旁路能耗,并估算每个模块的旁路能耗和不旁路能耗。此外,主流的NVM 缓存性能优化方法还包括基于混合缓存架构(Hybrid Cache Architecture,HCA)的方法。混合缓存由具有不同存储单元的多个阵列组成,其中包括一个容量较小的SRAM阵列和一个容量较大的STT-RAM 阵列,如果将写密集型数据存储在SRAM 阵列中,则可节省STT-RAM 阵列进行写操作所需的大量能源成本。
文献[11]提出基于读写感知的混合LLC 体系RWHCA,其根据导致LLC 未命中的指令来决定将数据块存储在STT-RAM 阵列中还是SRAM 阵列中。如果引起未命中的指令是load指令,则该指令提供给LLC的数据块有可能再次被读取,将该数据块存储在STTRAM 阵列中;如果该数据块不是由load 指令提供,则其被判断为写密集型模块而被存储在SRAM 阵列中。文献[12]提出一种HCA 管理策略,也称为适应性放置与迁移策略,其将LLC 的写操作分为预取写操作、存储指令写操作和写回操作3 种类型。在该策略中,先分析每个缓存块类型的写密集程度,再根据分析结果决定哪些类型的缓存块存储于SRAM 阵列和STT-RAM阵列中。文献[13-15]提出一种HCA 准确预测机制,使用预测表存储每个缓存块的访问模式并预测其写强度,在LLC 中存储缓存块时,可参照预测表将缓存块放入合适的阵列中。
综上所述,传统旁路策略可集中减少对STT-RAM阵列的写操作次数并预测缓存块类型。如果是重用率不高的缓存块则会绕过STT-RAM 阵列,如果是重用率较高的缓存块则不能采用旁路策略,从而导致STT-RAM 阵列产生较多高能耗写操作。本文对旁路策略进行优化,使重用率较高的缓存块绕过STTRAM 阵列,并动态地将缓存块写入其他核心的同级缓存,以进一步减少STT-RAM 的写操作。
2 基于重用的动态旁路策略
本节介绍缓存块重用信息及其利用方法与采用非对称LLC 存在的问题,阐述LLC 发生缺失时进行填充以及对来自上一级缓存写回操作的旁路策略。
2.1 重用信息
图1 为缓存块A 从填充到缓存再到被缓存管理算法逐出缓存的整个生命周期。缓存块A 通过读取访问或者预取操作填充至缓存,其在缓存中的生命周期由生存时间(从开始分配到最后一次命中的时间)和死亡时间(从最后一次命中到被逐出的时间)组成。分配后缓存块的访问命中总次数称为数据重用次数,图1 中缓存块A 的重用次数为5。第一次分配称为初始放置,为记录每个缓存块的重用次数,在每个缓存块中增加额外的两位计数器。

图1 缓存块A 的生命周期Fig.1 Life cycle of cache block A
2.2 不同延迟的LLC 平均访问时间
由于读写具有不对称性,因此NVM 缓存需要特定的管理策略。然而LRU 等传统缓存管理策略仅考虑了缓存块的局部特征,却无法感知NVM 缓存的读写非对称性。针对该问题,本文在多核处理器中基于不同缓存参数配置进行实验(见3.1 节),得到不同写延迟配置下运行SPLASH-2[16]基准测试程序的LLC 平均访问时间,实验结果如图2 所示。

图2 不同写延迟配置下的LLC 平均访问时间Fig.2 LLC average access time under different write delay configurations
在图2 中,第1 组未配置3 级缓存LLC(Without LLC),得到数据直接从主存中填充到L2 缓存时的总数据访问时间。第2 组(写延迟为读延迟的1 倍,记为1×)配置了具有相同读写访问延迟的缓存。第3 组写延迟分别增加到读延迟的2 倍(2×)、3 倍(3×)、4 倍(4×)和5 倍(5×)。可以看出,当缓存读写访问趋于不对称时总数据访问时间会增加,当LLC 缓存的写延迟足够大时删除LLC 缓存有助于减少总数据访问时间。对于radiosity 和radix 等基准测试程序,删除LLC 缓存可减少访问时间,说明将缓存块从主存填充到LLC 意义不大。
2.3 LLC 缺失时的旁路策略
当LLC 缺失时,目标缓存块会从主存调出填充到LLC 中,采用旁路策略可减少LLC 中写操作次数并避免性能下降。由于缓存具有非包含性,因此缓存块即使通过旁路绕过LLC 也可保持数据一致性。下文将针缓存系统配置介绍LLC 的读操作(写操作与此类似)。
当LLC 缺失时,缓存块从主存调出后的填充操作如图3所示(虚线表示模块之间可以数据互通,以下同)。如果主存加载的缓存块绕过LLC,则其将被直接填充到L2 缓存,如路径2 所示;否则缓存块正常加载到LLC中,如路径1 所示。结合图2 的分析结果可知,将部分重用缓存块填充到LLC 并不能带来性能上的提升,其原因是此类缓存块常由于后续请求被修改或被更新,导致LLC 中大部分为无效缓存块,仅当来自上级缓存的数据逐级写回,才能使得LLC 中缓存块重新有效。

图3 LLC 缺失时缓存块的填充操作Fig.3 Filling operation of cache block when LLC is missing
基于上述规则,如果某个核心所执行的指令请求逐级向下级缓存索引缓存块,则当LLC 未命中时,整个缓存会产生一次缺失,此时需要从主存中查找缓存块进行填充。如果此后缓存块在其生命周期中有较高的重用率,可无需填充至LLC。当该缓存块被替换算法逐出LLC 时,在某个时刻核心有一条相同的指令请求并再次出现缓存缺失,利用以往记录可将缓存块填充至对应核心的L2 缓存中,无需填充到LLC。
为支持旁路策略,需要额外的预测表来保存相应指令的部分地址位,且LLC 的每个缓存块添加额外的数据比特来保存相应的部分地址位,LLC 缓存块和预测表的结构如图4 所示。当缓存块从主存填充至LLC 时,需将请求指令的部分地址保存至缓存块。如果该缓存块被替换算法选择为牺牲块,则需检查该缓存块的重用信息,每个缓存块均添加重用计数位(V),当重用计数位超过给定阈值(本文中阈值为2)时,该缓存块中部分指令地址(Addr)位被保存到预测表中。如果此后有一条相同的请求指令出现LLC缺失,则表明查询预测表匹配成功,且缓存块会从主存旁路至L2 缓存。

图4 LLC 缓存块和预测表的结构Fig.4 Structure of LLC cache block and prediction table
下文列举多核处理器实例(见图5)来介绍基于预测表和重用信息的LLC 旁路策略(初始冷启动下,预测表为空且无任何信息)。
1)在图5(a)中,当核心0 的一条指令请求A 访问LLC 出现缺失时,预测表为空,通过查询主存获得对应的缓存块1 并将其填充至LLC,如图5(b)所示。导入缓存块后,更新状态信息为:重用计数设置为0,Addr 域保存指令地址A 的高位部分。此后每次访问和命中缓存块1 均需更新重用计数器的值,以便后续旁路策略执行决策。
2)在图5(c)中,在某一个时刻缓存块1 和缓存块2 被替换算法先后从LLC 中逐出,此时需检查缓存块的重用信息,并根据重用计数器的值来动态决定对应缓存块的地址信息是否需保存到预测表。由于缓存块1 的重用计数器值为3,超出给定阈值,因此缓存块1 的Addr 位被写入预测表。因为缓存块2的重用计数器值为1,未超出给定阈值,所以缓存块2的Addr 位无需写入预测表。此后若再访问缓冲块1,则通过检查预测表可判定是否进行旁路操作。
3)在图5(d)中,当核心0 的一条指令请求A 访问LLC 出现缺失时,如果通过查询预测表发现以前的记录中保存有指令A 的地址,则请求匹配成功。来自主存的缓存块将通过旁路策略被直接填充至核心0 的L2 缓存中。此时若所需访问的地址在预测表中,则说明对应的缓存块重用性很高,使其绕过LLC 缓存可减少写次数,不影响对该缓存块的再次访问。

图5 LLC 旁路策略实例Fig.5 Example of LLC bypass strategy
4)图6为缓存块填入LLC 的过程。核心1有一条指令请求缓存块2,由于该缓存块已被逐出LLC,因此会出现LLC 缺失,需访问主存来获取缓存块2,此时查询预测表未能匹配成功,将缓存块填充至LLC中。因为缓存块2 被重用的次数小于旁路策略ReBP中设定的阈值,所以其被逐出LLC 时相关地址信息未存储于预测表中,当其被再次访问时,ReBP 在预测表中无法找到对应的信息,因此,对缓存块2 不采取旁路操作。

图6 缓存块填入LLC 的过程Fig.6 Process of filling cache block into LLC
上述工作均围绕读操作进行,本文所提旁路策略ReBP 对写操作的处理方式与此类似,同样根据相应缓存块的重用信息,利用预测表动态地进行旁路操作。
2.4 写回LLC 时的旁路策略
上级缓存(假设为L2缓存)的写回操作旁路策略如图7所示。当L2缓存中的缓存块被写回时,如果采用旁路策略,则该缓存块将写回其他核心的L2缓存中,如路径4所示;否则,该缓存块正常写回LLC缓存中,如路径3所示。

图7 上级缓存写回操作旁路策略Fig.7 Bypass strategy for write-back operation of superior cache
对写回的缓存块进行旁路操作目前存在如下问题:1)需确定对哪些写回的缓存块使用旁路操作;2)将采取旁路操作的缓存块保存到何处。针对第1 个问题,根据上文分析结果,具有较高重用计数的缓存块从当前缓存被逐出后,仍有较高的概率被再次重用填充。因此,该缓存块填充到存储压力较小的核心的L2 缓存,不仅能减少基于NVM 的LLC写操作次数,还能以较小的代价再次重用该缓存块。针对第2 个问题,为获取各个核心L2 缓存的存储压力等状态信息,本文所提旁路策略在多核芯片中增加缓存监控模块CM(见图8),以监测各个L2 缓存当前的存储压力,为旁路的缓存块选择合适目标,从而使得各个L2 缓存的负载更均衡。在下文的对比实验中,将CM 模块设置为实时查询模式,并分析实时查询和间隔查询对缓存性能的影响。

图8 CM 模块结构Fig.8 Structure of CM module
图9 为核心之间的旁路策略。由于缓存块A 将被替换算法逐出,查找该缓存块的重用计数信息后,若发现其超过设定的阈值,则可采取旁路操作。检查CM 模块中各个核心的L2 缓存负载信息,若当前核心2 的L2 缓存缺失率较其他核心更低,则可选择从核心0 中的L2 缓存写回核心2 的L2 缓存中。如果来自核心0的写回缓存块重用计数信息超过设定的阈值,则不采用旁路策略,直接正常写回LLC 中。该旁路策略通过将来自L2缓存的写回缓存块旁路至其他核心,减少了LLC的写次数,使该缓存块具有更高的重用率,后续访问再次重用这些缓存块的概率较高。由于L2 缓存更接近处理器,因此可缩短缓存块的访问延迟,提高整体系统性能,并减少LLC 的写入次数。

图9 核心之间的旁路策略Fig.9 Bypassing strategy in cores
3 实验与结果分析
本文通过实验对提出的ReBP 策略进行验证,分别评估其在单个和多个应用程序场景下的性能,并与其他相关策略进行对比分析。
3.1 实验方法
本文采用Sniper 模拟器[17]进行片上多核处理器系统仿真实验。该系统有4 个核心,每个核心的主频为2 GHz。片上缓存系统设置为3 级缓存,L1I/L1D 和L2是基于SRAM 的缓存,LLC 是基于STT-RAM 的非对称访问缓存,相关组件配置如表1 所示。

表1 相关组件配置Table 1 Configuration of related components
为评估基于STT-RAM 的LLC 性能,本文将其与基于SRAM 的LLC 进行比较。通过采用CACTI 6.5[18]和NVSim[19]建模仿真4 MB STT-RAM 和4 MB SRAM 缓存对应的特性,参数设置如表2 所示。由于STT-RAM具有非易失性,因此其静态能耗比SRAM 缓存少一个数量级。在相同的存储容量下,若STT-RAM 所占面积越小,则STT-RAM的LLC在同等面积上存储信息越多。
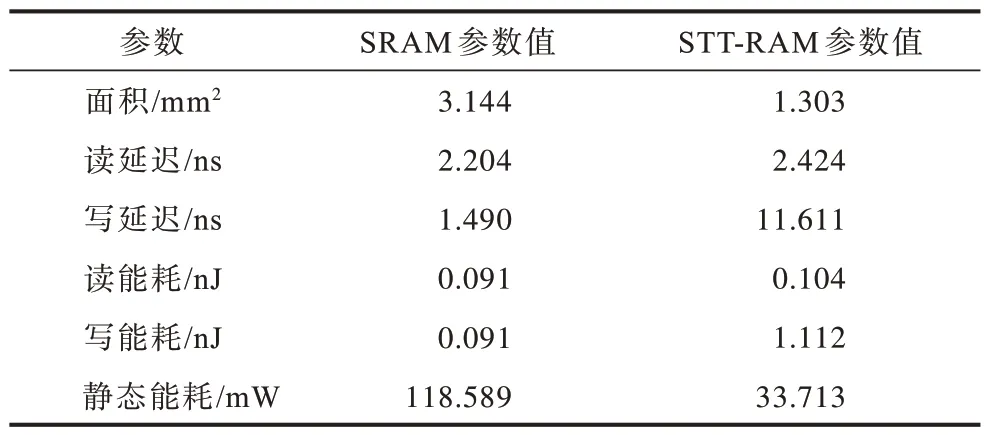
表2 SRAM 和STT-RAM 的仿真参数设置Table 2 Simulation parameter setting of SRAM and STT-RAM
为进行全面评估,分别在单一和随机混合的多程序基准中进行分析。所有的基准测试均来自SPLASH-2。从SPLASH-2中随机选择4个程序构成多程序工作负载,如表3所示,并对所有负载运行过程中整个缓存层次的静态能耗和动态能耗进行统计。本文仿真实验实现了3种缓存策略:1)无旁路的高速缓存策略Baseline;2)基于统计的缓存旁路策略SBAC-Private[20],其利用数据重用计数概率进行旁路决策;3)本文提出的基于重用的旁路策略ReBP。以系统运行应用负载的总执行时间作为性能指标,将高速缓存的总能耗作为能耗指标。所有仿真结果均以Baseline策略为基准进行对比。

表3 多程序工作负载Table 3 Multiprogramming workload
3.2 单应用评估
图10 为上述3 种策略运行SPLASH-2 程序单应用基准测试下的能耗结果。可以看出,ReBP 策略使缓存系统的能耗较Baseline 策略平均减少22.5%,而SBAC-Private 策略使缓存系统的能耗较Baseline 策略平均减少15.2%。对基于非易失性存储器的缓存而言,旁路策略的能耗减少量与预测精度有关。由于基于重用的预测能获得较高预测精度,因此ReBP策略可将高重用的缓存块保留在上级缓存中的L2缓存,将低重用计数缓存块绕过LLC。错误预测会导致ReBP 策略将有用的缓存块也进行旁路,从而抵消其被正确实现带来的优势。

图10 3 种策略的单应用能耗对比Fig.10 Comparison of single application energy consumption of three strategies
如果应用程序自身的L2 缓存缺失率非常高,则旁路策略的作用将十分有限。例如对于ocean.cont-scale程序,ReBP 策略仅降低2%的能耗。由于L2 缓存缺失率高,因此ReBP 策略将缓存块旁路到其他L2 缓存可能会进一步增加缺失率,从而在一定程度上抵消ReBP策略带来的收益。
旁路策略除了通过减少STT-RAM 的写操作降低能耗之外,对系统性能也有影响。图11 为单应用场景下3 种策略中应用负载的运行时间对比情况。可以看出,ReBP 策略使应用负载的运行时间较Baseline 策略平均减少6.6%,其原因如下:1)ReBP 策略可减少STT-RAM 中延迟较大的写操作对读操作的干扰,从而提升系统性能;2)ReBP 策略使重用率高的缓存块绕过LLC,提升了LLC 的空间利用率,其可容纳更多缓存块来提升系统性能。SBAC-Private策略基于缓存块的统计信息进行,预测精度低于ReBP 策略,其使应用负载的运行时间较Baseline 策略平均减少5.4%。

图11 单应用场景下3 种策略应用负载的运行时间对比Fig.11 Running time comparison of application load of three strategies in single application scenario
由图11 还可以看出,对于ocean.cont 程序,ReBP策略使应用负载的运行时间较Baseline 策略增加5%。因为L2 缓存缺失率普遍较高,所以ReBP 策略中旁路到其他核心的L2 缓存的缓存块造成目标核心后续访问缓存出现较多缺失,导致该程序在ReBP策略下运行时间延长。由上述分析可知,ReBP 策略的核心之间容量共享方案需考虑L2 缓存本身的压力,若压力达到一定程度,应关闭ReBP 策略中核心之间的旁路,这也是下一步继续优化ReBP 策略的一个重要方向。
3.3 多应用评估
图12 为3 种策略在多应用(程序)基准测试下的能耗结果。可以看出,ReBP 策略在大部分多应用基准测试中的能耗较SBAC-Private 策略更少。与Baseline 策略相比,ReBP 策略与SBAC-Private 策略分别将能耗平均降低15.4%和11.3%。在多应用场景下,ReBP 策略将核心的高重用缓存块填充至其他核心的L2 缓存可能会提升L2缓存的缺失率。因为每个核心均运行多个线程,会增加各L2 缓存之间旁路的频率,从而给L2 缓存缺失率偏高的应用造成额外的缺失,浪费能耗且影响性能。由图12 还可以看出,对于mix3、mix7、mix9 和mix10 这4 个基准测试多程序,ReBP 策略的能耗高于SBAC-Private 策略。

图12 3 种策略的多应用能耗对比Fig.12 Comparison of multi application energy consumption of three strategies
在应用负载的运行时间上,ReBP 策略在多应用情况下与SBAC-Private 策略相似,均比Baseline 策略高约3%。图13 为多应用场景下3 种策略中应用负载的运行时间对比情况。可以看出,ReBP策略与SBAC-Private策略应用负载的运行时间比Baseline 策略更长,其原因是每个核心都运行多个线程,各级缓存负载均很高,降低了ReBP 策略和SBAC-Private 策略进行旁路决策的精度。ReBP策略和SBAC-Private策略可有效降低STTRAM 缓存的能耗,但若多核系统中运行的应用对延迟敏感,则需慎用旁路策略。
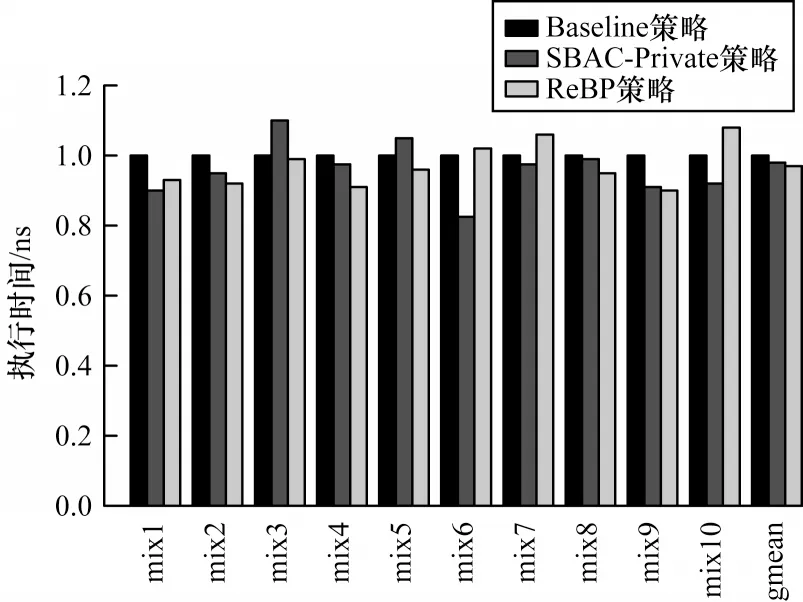
图13 多应用场景下3 种策略应用负载的运行时间对比Fig.13 Running time comparison of application load of three strategies in multi application scenario
3.4 CM 模块查询间隔分析
在上述实验中,采用ReBP 策略对L2 缓存块进行旁路操作时,CM 模块设置为实时查询方式,通过不断查询比较4 个L2 缓存的缺失率选择合适的旁路路径。然而该实时查询存在较大开销,可将CM 模块缺失率查询方式设置为间隔查询来减少开销。在不同CM 模块查询间隔时间下,将ReBP 策略在3 个单应用场景和3 组多应用场景中应用负载的运行时间进行对比分析,结果如图14 所示。

图14 不同应用场景下CM 模块查询结果Fig.14 Query results of CM module in different application scenarios
由图14可以看出,当查询间隔时间为8 ms时,mix4应用负载的运行时间最优,其他应用均在4 ms 的查询间隔时间下获得最优性能。此外,当查询间隔很短时应用的运行时间延长,当查询间隔逐渐增加后应用的运行时间缩短,但当查询间隔进一步增加后应用的运行时间又延长。其原因在于,非常小的时间间隔会使得CM 模块查询频繁,造成查询总开销较大,从而影响应用的性能。随着查询间隔时间增加,CM 模块中各个L2 缓存块的压力信息由于长时间得不到更新,造成旁路策略长时间写入同一个核心L2 缓存块中,导致该缓存块负载较大,进而污染该缓存产生额外的LLC 访问次数,最终使得整个应用的运行时间增加。由上述分析可知,查询间隔时间取4 ms 最佳。
4 结束语
非易失性存储器可替代传统基于CMOS 芯片的RAM 存储器作为片上缓存,但其写操作代价过高导致无法被大规模应用,而利用缓存旁路技术可减少缓存的写操作来提升非易失性缓存性能。本文分析测试程序访问最后一级缓存时的特征,提出基于缓存块重用的动态旁路策略,通过提升旁路决策精度确保旁路的效率,同时将高重用的缓存块动态旁路到存储压力较小的上级缓存,以减少非易失性缓存的写操作次数。实验结果表明,与未采用旁路策略的缓存相比,该策略的基准测试程序运行时间和缓存能耗更低,有效提高了整体缓存性能。由于本文采用LLC 缺失时的旁路策略,因此LLC 体系结构设计为非包含模式,该模式下LLC 写操作次数相对较多。后续考虑在该策略的基础上,将LLC 体系结构设计为包含模式以减少写操作次数,并采用添加额外标签的无数据存储方式,实现空间容量利用率最大化。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
建材发展导向(2021年16期)2021-10-12
建材发展导向(2021年23期)2021-03-08
测控技术(2018年5期)2018-12-09
华人时刊(2018年15期)2018-11-10
安徽医科大学学报(2016年12期)2017-01-15
电信科学(2016年10期)2016-11-23
中国体外循环杂志(2015年3期)2015-12-08
科技传播(2015年20期)2015-03-25
