
面向中文新闻文本分类的融合网络模型
2021-04-29 09:29胡玉兰赵青杉牛永洁
中文信息学报 2021年3期
胡玉兰,赵青杉,陈 莉,牛永洁
(1.忻州师范学院 计算机系,山西 忻州 034000;2.西北大学 信息科学与技术学院,陕西 西安 710127;3.延安大学 数学与计算机科学学院,陕西 延安 716000)
0 引言
随着科技的快速发展,互联网已经成为信息传播的主要载体。面对互联网产生的大量文档,尤其是数量惊人的中文文档,如何从中获得有用的信息显得尤为重要。文本分类不仅可以有效地管理和筛选信息,而且在网络搜索、信息检索和排序、自动摘要生成等方面也能发挥重要的作用[1]。同时,文本分类也是自然语言处理中的重要任务之一。
对中文文本来说,由于其语义模糊、词性构成复杂、各部分信息在文档中分布不对称。因此,在建立有效的中文文本分类模型之前,首先需要将文本转换成计算机和模型可识别的形式[2-3],然后提取一些有效的特征信息,最后才能使用有效的分类算法对所提取的特征进行训练,最终达到区分文本类别的目的。
最初文本表示的主要方法是向量空间模型(Vector Space Model,VSM)或基于VSM的改进模型。在VSM中,将每个文本都表示为一个向量,其中的元素就是所谓的文本特征。然而,VSM存在的一个最大的问题就是数据稀疏问题,常常需要通过信息增益等方法来提取进一步的特征信息[4]。但是,这些方法只是一定程度上的缓解,并未真正解决问题。于是,后来研究者们转向了研究基于神经网络的文档分布式表示,进而实现了文档的词向量表示。
过去几年,根据对应的词向量,出现了一些基于神经网络的模型,譬如神经网络主题模型(Neural Topic Mode,NTM)[5]、变分推理自编码主题模型(Autoencoding Variational Inference for Topic Models,AVITM)[6]、稀疏神经网络主题编码(Neural Sparse Topical Coding,NSTC)[7]及稀疏上下文隐藏和观察语言自动编码器(Sparse Contextual Hidden and Observed Language Autoencoder,SCHOLAR)[8]等。在这期间,随着深度学习技术在自然语言处理中的广泛应用,结合深度学习方法的文本分类模型不断被提出,例如2014年由哈佛大学的Kim提出的Text-CNN[9],该模型基于卷积神经网络,而卷积神经网络关注的是局部信息,因此无法获取上下文词汇之间的全局依赖关系,也就限制了对全文语义的理解。于是,2016年复旦大学刘等人考虑到文本是一个序列模型,提出了Text-RNN[10]。该模型关注每个词的序列关系,且会存储每个词在文档前面出现的语义信息。然而,这种RNN模型对每个词在后面出现的语义信息关注不够,体现不出文档中每个单词的信息量。
近年来,随着注意力机制在自然语言处理中的广泛应用,注意力机制已经应用到像机器翻译、对话系统、图片捕获这样的序列到序列的模型中,并取得了不错的效果[11]。因此,为了解决上述模型中存在的问题,本文不仅将卷积神经网络和循环神经网络进行了融合,而且引入了注意力机制来获取词在文档中的重要程度,提出一种面向中文新闻文本分类的融合网络模型。
1 相关工作
1.1 经典模型分析
目前文本分类模型主要分为传统文本分类模型和基于神经网络的文本分类模型。
1.1.1 传统文本分类模型
传统文本分类模型的分类方法主要聚焦于特征提取和选择合适的分类算法,通常采用基于词袋和词频逆文本频率(TF-IDF)的朴素贝叶斯文档分类模型,如Blei等人提出的LDA模型[12]。然而,这类方法中存在的最大问题就是数据稀疏,于是Yan等人提出了BTM模型[13],虽然该模型在一定程度上缓解了短文本特征空间高维稀疏问题,但是由于它仅依靠语料本身提供的信息进行文档主题推断,效果依然不够理想。
1.1.2 基于神经网络的文本分类模型
伴随着深度学习和词向量的发展,在相关国际顶级会议(如ACL、AAAI、ICJAI等)上引发新的研究热潮,Lau等人和Wang等人先后提出了TDLM模型[14]和TCNLM[15],其中TDLM模型以文档的词向量拼接为输入,并使用CNN转换为文档向量,进而从文档向量中推断出类别,模型中采用注意力机制获取文档的主题分布,并将其融入循环神经网络的隐藏层中,但是通过在公开评测的数据集,如20NewsGroups、Web-Snippet上进行对比,在20NewsGroups上的效果并不理想,主要是因为20NewsGroups数据集中偏长文档较多,而使用卷积神经网络捕获的是文本的局部关键信息。随后吴小华等人[16]将Self-Attention机制和双向LSTM相结合,此模型是通过Bi-LSTM获取词的前后依赖关系,进而通过注意力层捕获词在文档情感分析中的影响程度。
在深度学习任务中,为了提高分类的精度,一些学者不断加深神经网络,如Johnson等人[17]和Conneau等人[18]通过增加网络的深度提高分类精度,而深度网络模型不仅耗时而且容易出现梯度消失或爆炸问题。在计算机视觉领域,Huang等人提出了DC-CNN模型[19],采用密集连接的方式将前面所有层的特征映射输入到后面层,取得了不错的效果。受此启发,本文将GRU网络中的每个隐藏单元与后面所有GRU层相应的隐藏单元通过密集连接来加强上下文中的语义信息,其次分别采用自注意力机制获取词在文档分类中的影响程度,并通过最大池化层获取每个词向量维度上的最大值,即对文档分类影响最大的词,然后将各自学习到的文本表示进行拼接,最后通过分类器进行文本分类。
1.2 背景模型
1.2.1 GRU网络模型
GRU网络是在2014年Cho等人[20]为了简化LSTM循环神经网络的结构提出的,是LSTM的一种变体,在文本分类上二者效果相当,但是由于GRU模型少了一些矩阵运算,其计算效率更高。GRU的网络结构图如图1所示。
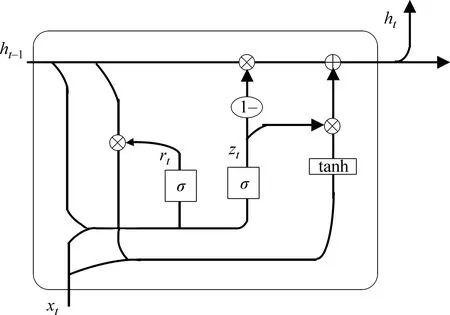
图1 GRU网络结构图
从图中可以看出,GRU只有两个门且没有细胞状态,因此GRU有更少的参数,相对容易训练且过拟合问题不太严重。
GRU网络模型中第t层的更新计算公式如式(1)~式(4)所示。
(1)重置门rt的计算[见式(1)]。
rt=σ(Wrxt+Urht-1+br)
(1)
其中,σ表示激活函数,Wr、Ur、br为重置门的参数,xt为第t层的输入,ht-1是上一时刻的状态。
(2)
其中,⊙表示矩阵元素相乘,Wh、Uh为候选状态的参数,其他同上。
(3)更新门zt的计算[见式(3)]。
zt=σ(Wzxt+Uzht-1+bz)
(3)
其中,σ表示激活函数,Wz、Uz、bz为更新门的参数,xt为第t层的输入,ht-1是上一时刻的状态。
(4)隐藏状态ht的计算[见式(4)]。
(4)

1.2.2 Dense网络
DenseNet[19]由Huang等人2017年提出,是一种密集连接的CNN。其核心思想是将网络中的每一层都与后面所有层进行直接连接,实现每一层所学习的特征直接传给其余层,其中的Dense Block结构图,如图2所示,在Dense Block内进行的是在特征维度上的拼接而不是按元素进行的叠加。该网络已经在计算机视觉领域取得了很好的效果,其优点是可以缓解训练过程中的梯度消失问题,加强特征传播与复用,减少了参数量。
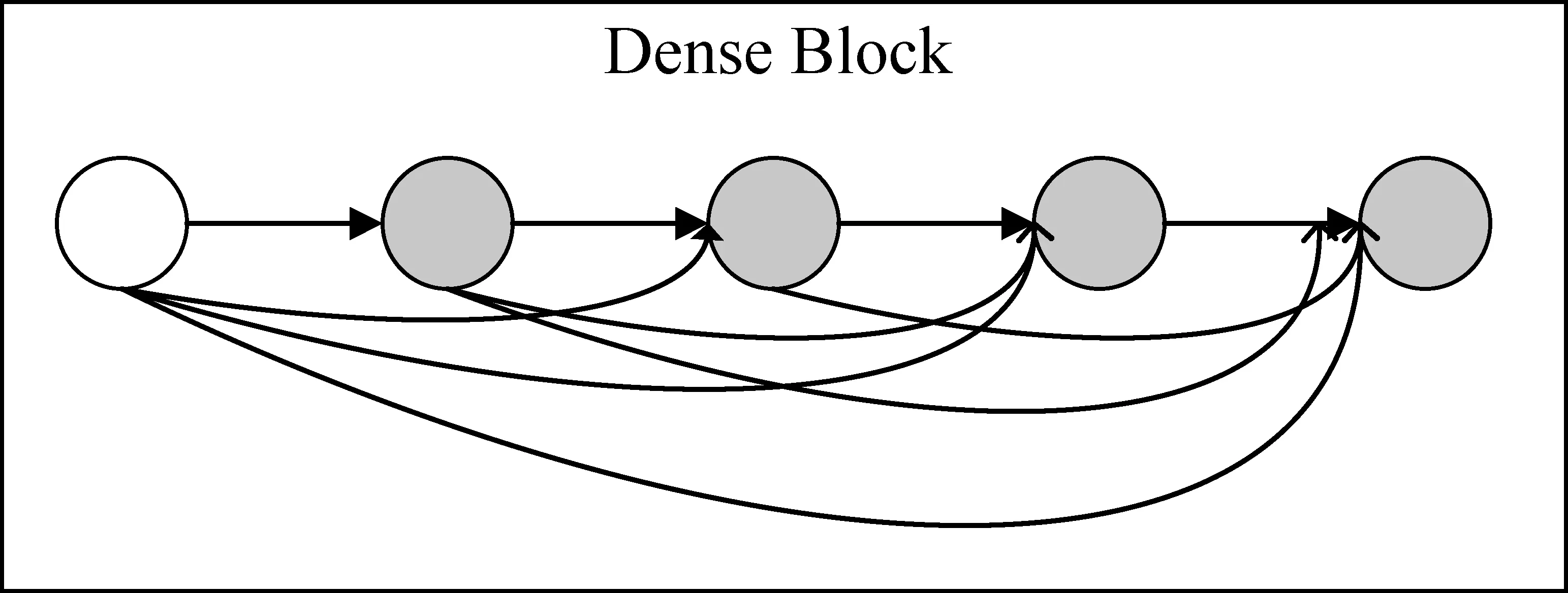
图2 Dense Block结构图
2 面向文本分类的融合网络模型
本文所提出的融合网络模型主要由词嵌入层、密集连接的双向GRU(DC-BiGRU)网络层、最大池化层、权重调整层、Softmax分类层组成,其模型结构如图3所示。各层的具体过程下文一一描述。

图3 模型结构图
2.1 词嵌入层
词向量的表示方法有多种,常用的表示方法有词袋模型和n-gram模型,但是这两种表示方法的一个共同问题是它们丢失了文本的顺序性,通常它们是和浅层机器学习模型一起使用的。这两种表示方法很少用于深度学习,因为RNN和Conv1D等架构会自动学习到文本特征。本文采用Word2Vec工具获得基于谷歌新闻语料的预训练词向量表,对文本中的词通过查找预训练词向量表得到文本的词向量表示:S:{w1d,w2d,…,wnd},其中n为每个文本序列的长度,d为词向量维度。该层的输入是大小为l×b的文本矩阵,输出是大小为l×b×d的词向量矩阵,其中,l为文本固定长度,b为批处理的文本数量,d为词向量维度。
2.2 DC-BiGRU层
密集连接的双向门控循环单元(Densely Connected Bi-directional Gate Recurrent Unit,DC-BiGRU)层的作用是提取词向量序列中的全局特征。
为了更大程度地获取全局特征,一方面让模型更大程度地捕获文本的上下文语义信息;另一方面通过顺序堆叠的方式建立更高层次的网络,加强特征的传播和特征复用。
为了更大程度地捕获文本上下文语义信息,本文采用了双向GRU网络。因为GRU仅可以学习到上文的信息即每个位置t的隐藏状态只能对前面文本的信息进行正向编码,无法反向编码,只有增加反向传播的GRU才可以学习到后面文本即下文的信息。
双向GRU的具体表示如式(5)~式(7)所示。

如果通过顺序堆叠的方式建立更高层次的网络,随着层数的加深通常会出现梯度消失或爆炸的问题,为了解决此问题,本文引入了密集连接块,将每一层双向GRU和后续所有的双向GRU层进行直接连接,在实现特征复用和加强特征传播的同时,还减少了参数量。其模型结构如图4所示。
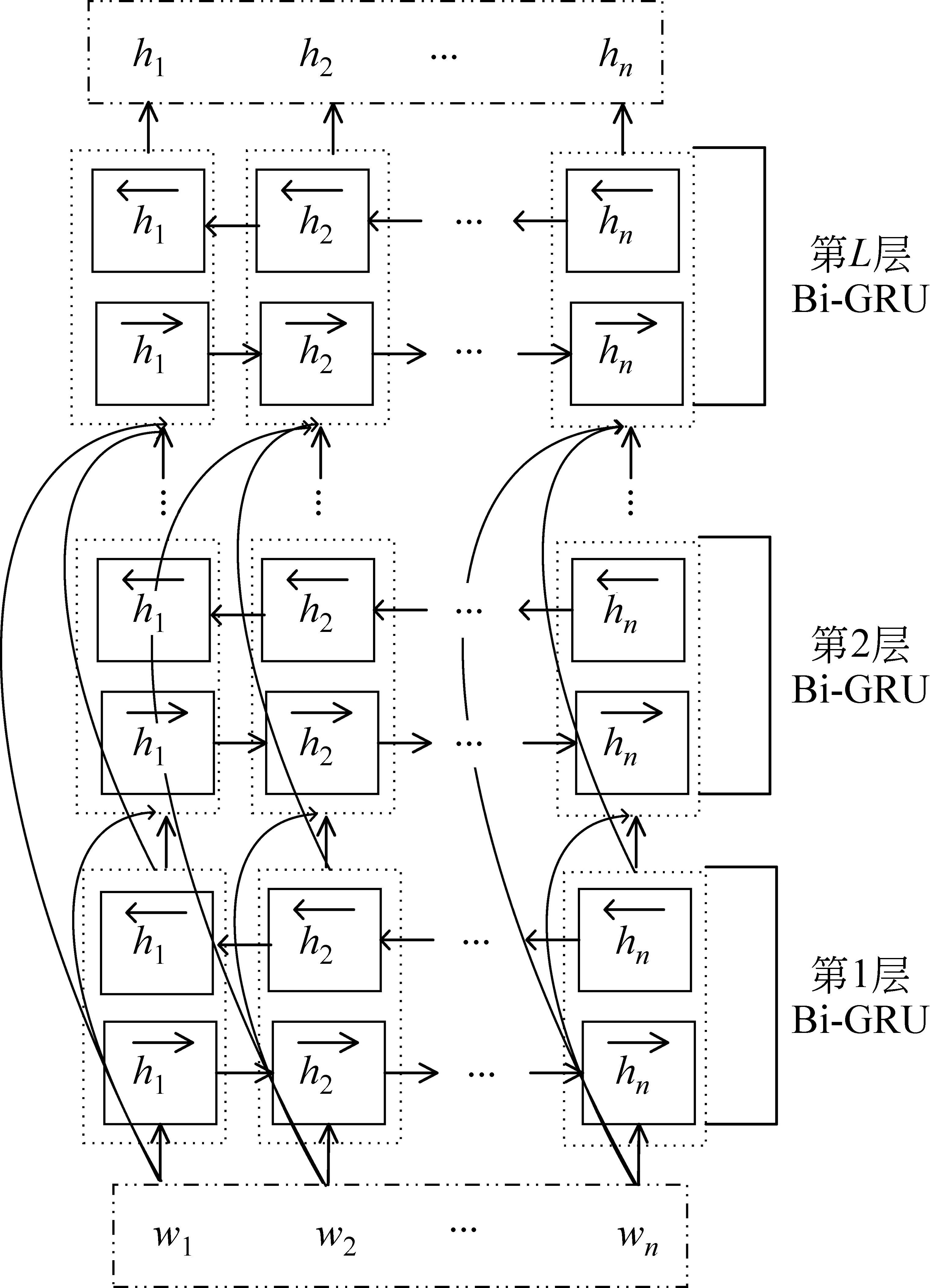
图4 DC-BiGRU模型结构图
第一层输入为:
{w1,w2,…,wn}
第一层输出为:
第二层的输入为:
第二层输出为:
{h12,h22,…,hn2}
第L层输入为:
第L层输出为:H={h1,h2,…,hn},为密集连接的双向GRU网络学习到的特征表示。
2.3 最大池化层


图5 最大池化层操作示意图
2.4 权重调整层
权重调整层的作用是对DC-BiGRU层学习到的词向量根据词序列中的每个词对文本分类任务的影响程度调整其权重。该层采用自注意力机制来调整词向量的权重,因为自注意力机制可以直接对自身信息训练更新参数,捕获词之间的依赖关系,能够学习到文本的内部结构,实现也较为简单,还可以并行计算。其计算方法如式(8)~式(10)所示。
其中,hi为DC-BiGRU输出的词向量,Xi为经过tanh激活函数处理后的词向量,αi为词在文本中的注意力权重,u为经过词的加权平均得到的文本表示。
2.5 Softmax分类层
将前面通过最大池化层得到的文本表示v和经过权重调整层得到的文本表示u进行拼接,然后通过全连接层进行调整得到z,最后将其输入Softmax层对文本进行分类。计算过程如式(11)、式(12)所示。
z=F(v⊕u)
(11)
(12)
2.6 模型训练
由于采用的Adam优化方法后期的学习率太低,导致收敛性较差。通过分析常用的两种优化方法Adam和SGD方法的优缺点,针对这一问题采取了一种措施:在前期时采用Adam,后期换成SGD,这样可以有效利用二者的优点,提高算法的收敛速度,而AMSBound[22]正是将二者的结合实现智能化,给出切换SGD的时机选择方法,采用动态边界的学习速率,实现平稳过渡到SGD。该方法在保持自适应方法的快速初始化和超参数不敏感等优点的同时,在多个标准基准上取得了良好的效果。因此,本文采用AMSBound优化方法作为模型训练中的优化器,来加速模型训练。调用的方式和Adam优化器类似:optimizer=adabound.AdaBound(model.parameters(), lr=1e-3, final_lr=0.1)。
损失函数选取交叉熵损失,具体计算如式(13)所示。
(13)
3 实验对比与分析
3.1 实验数据集
为了证明所提出模型的有效性,在实验中选取中文新闻文本分类中两个经典数据集NLPCC2014(1)http://tcci.ccf.org.cn/conference/2014/pages/page04_eva.html和THUCNews(2)thuctc.thunlp.org,其中NLPCC2014一级类别有24种,主要包括体育、农业和财政等,数据格式见表1所示。

表1 数据格式
将NLPCC2014按照训练集和测试集类别分布一致划分为训练集(42 689个样本)和测试集(11 577个样本)。THUCNews由清华大学自然语言处理实验室推出,是基于新浪新闻的历史数据,现有新闻文献74万篇,分为14大类,包括金融、彩票和体育等。对于数据集THUCNews,一种类别随机选择3 000个训练样本和500个测试样本。两个数据集的详细信息见表2。从表2中可以看出,NLPCC2014的文档平均长度为470.6,属于较长文本数据集,THUCNews的文档平均长度只有22.34,属于短文本数据集。

表2 数据集的详细信息
3.2 数据预处理
Step1由于中文不能直接采用空格进行分词,需要将实验所选的数据集利用jieba(3)https://github.com/fxsjy/jieba中文分词工具进行分词,同时利用相应的停用词文档去掉停用词,得到所需的中文词表,将每个文本采用较短补零、较长截断的方式统一成固定长度的样本,方便后面处理。对于NLPCC2014数据集,实验中的固定长度设为420。
Step2采用CBOW模型对大量的谷歌新闻语料预训练,得到预训练词向量,该词向量维度为300。对于未出现在预训练词向量中的词,在[-1,1]内随机生成300维的初始化词向量。
3.3 实验超参数设置
(1)初始化学习率lr=le-3。
(2)词向量的维度为300,最小批次为64,NLPCC2014数据集文档长度为420,数据集THUCNews的文档长度为25。
(3)模型中密集连接层的隐藏单元数为12,最后一层的隐藏单元数为100。
(4)dropout=0.7(经验值),采用Dropconnect方法在模型训练过程中,作用于hidden-to-hidden权重矩阵上,将节点中每个与其相连的输入权值以1-p的概率变为0。
3.4 模型对比与分析
本文采用精确率、召回率、F1-score三个评价指标来衡量分类模型的性能。
为了验证本文所提出的融合网络模型对中文新闻文本分类的有效性,分别与Text-CNN模型[9]、Text-RNN模型[10]、A-LSTM模型[23]、AC-BiLSTM模型[24]进行对比。
对于数据集NLPCC2014,各模型的三个评价指标结果见表3。从表中可以看出本文所提出的模型的三个评价指标不仅优于经典Text-CNN、Text-RNN模型,而且也优于A-LSTM和AC-BiLSTM两个新模型。与该数据集上表现较优的经典Text-CNN模型相比,精确率提高了5.4%,召回率提高了5.7%,F1-scoe提高了5.6%。与最新模型AC-BiLSTM相比,精确率提高了2.1%,召回率提高了3.6%,F1值提高了2.9%。可见,将基准模型进行一定程度的融合,可以适当提高模型的性能。
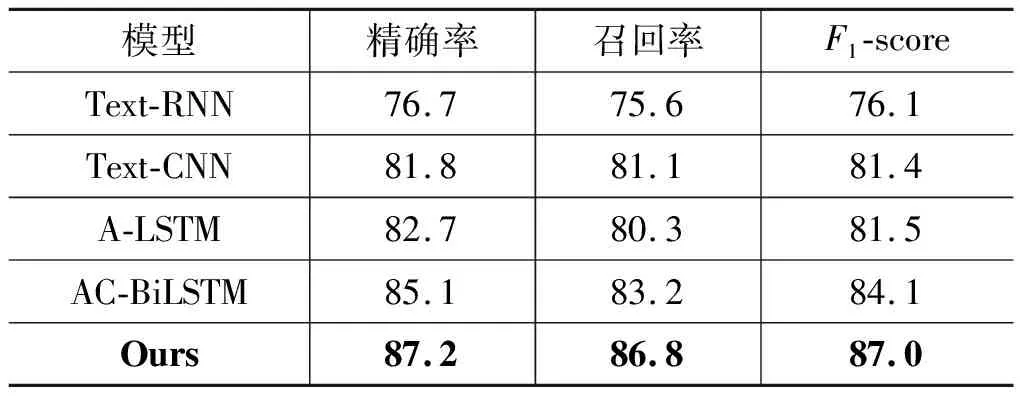
表3 NLPCC2014数据集的实验结果(%)
对于THUCNews数据集,也进行了同样的对比,具体结果见表4。从表中可以看出所提出的融合网络模型的三个评价指标均优于经典的Text-CNN和Text-RNN模型,同时也优于新模型A-LSTM和AC-BiLSTM,但是提高的幅度较小。与在该数据集上表现较优的经典Text-RNN模型相比,精确率提高了0.5%,召回率提高了0.2%,F1-score值提高了0.3%。
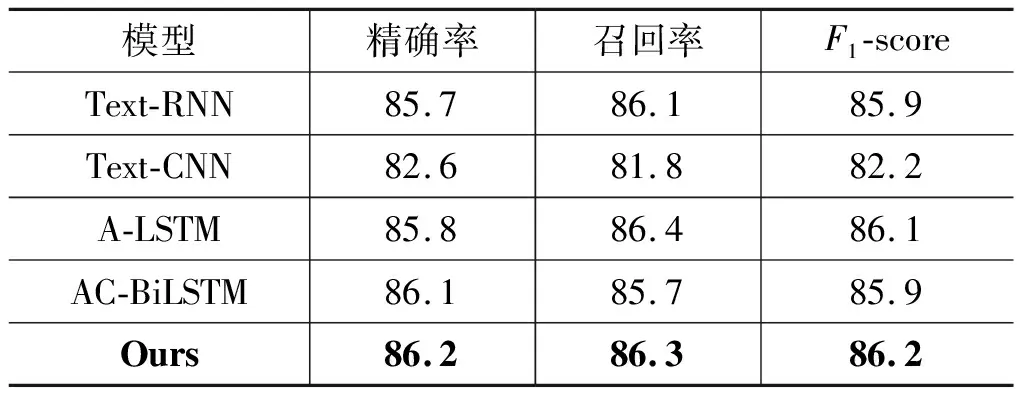
表4 THUCNews数据集的实验结果(%)
由于五个对比模型在不同数据集上的效果不一样,因此,为了验证各模型的适应程度,对其在不同数据集上的精确率进行了比较,具体结果见表5。

表5 不同数据集精确率结果(%)
从表5中可以看出,本文所提出的模型在NLPCC2014数据集上表现得更优,说明融合网络模型更适合较长文本数据集,由于短文本含有类别的信息较少,因此性能提高的幅度较小。而Text-RNN模型,因为循环神经网络只会记住一段长度前的信息,所以处理较长文本时表现较差。
3.5 GRU层数对模型的影响
通过多次实验发现,对本文所提出的融合网络模型性能影响最大的是密集连接的GRU层数。通常层数相对较多时模型的精确率更高,但是当层数增加到一定数量时模型的精确率反而会下降,因为层数过多时会出现过拟合问题。因此,在NLPCC2014数据集上对如何设置密集连接层数进行了统计分析,在实验过程中以步长为3进行了统计,其具体结果见图6。从图6可以看出,开始时随着层数的增加模型的精确率不断提高,但是如果层数太深模型的性能反而会下降。当密集连接层数取15左右时模型的效果最好。

图6 密集连接层数对模型精确率的影响
3.6 简化测试
为了评估模型中的各部分对整体性能的影响程度,对模型进行了简化测试,即分别将模型中的密集连接、最大池化、自注意力机制去除,统计处理NLPCC2014数据集的精确率的变化情况,实验结果如图7所示。去除密集连接操作部分后,模型的精确率下降了7.43%,下降得最多,说明密集连接起到了较大的作用,也就是说通过密集连接的确可以加强上下文中的语义信息。去除最大池化操作部分后,模型的精确率下降了6.25%,说明最大池化操作在整个模型提取特征时起到了一定作用。去除自注意力机制操作部分后,模型的精确率下降了4.16%,看起来自注意力机制对模型的影响最小,但是如果没有自注意力机制,整个模型的精确率只有83.04%。
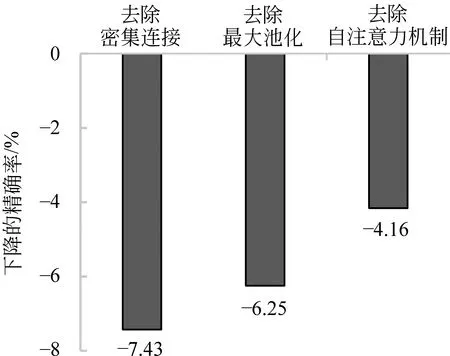
图7 简化测试结果图
4 结论
本文受DenseNet的启发,将双向GRU网络中的每个隐藏单元与后面所有双向GRU网络中相应的隐藏单元进行直接密集连接,来最大程度地捕获词在上下文中的语义信息。其次,将所学习到的特征表示,一方面,通过最大池化层进一步学习词向量在每个维度上的最大值,保留主要特征的同时降低特征词向量维度;另一方面,采用自注意力机制获取文本中更关键的信息。然后将所学习到的文本表示进行拼接,最后通过分类器对文本进行分类。
由于模型中采用的Word2Vec是通过对具有数十亿词的新闻文章进行训练得到的词向量,同时双向GRU网络和自注意力机制更适合于获取较长文本序列信息,因此所提出的融合网络模型更适合于处理较长的文本信息。此外,所提出的模型虽然在精度方面有所提升,但是在训练过程中所花费的时间较长。为了使得模型有更广的适用领域,下一步计划不仅采用善于学习短文本信息的方法或机制对模型进行改进,而且还需要在训练时间方面进行优化。
猜你喜欢
东北水利水电(2022年6期)2022-06-28
客联(2022年3期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
康复(2022年31期)2022-03-23
中国新闻周刊(2021年26期)2021-07-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年11期)2019-07-04
信息安全研究(2016年4期)2016-12-01
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
