
基于BERT的手术名称标准化重排序算法
2021-04-29 11:10陈漠沙谭传奇
中文信息学报 2021年3期
陈漠沙,仇 伟,谭传奇
(阿里巴巴 机器智能技术实验室,浙江 杭州 311121)
0 引言
临床术语标准化任务是医学文本信息抽取中不可或缺的一项任务。患者病历详细记录了患者的临床病史和疾病进展,包括但不限于症状、疾病、诊断和药物等。临床上,关于同一种诊断、手术、药品、检查、化验、症状等往往会有成百上千种不同的写法,标准化(归一)要解决的问题就是为临床上各种不同说法找到对应的标准说法,一方面可以帮助研究人员对电子病历进行后续的统计分析和挖掘;另一方面也可以促进AI技术在医学应用系统的落地,如“CDSS(临床决策诊疗系统)”“DRGs(诊断相关分组管理系统)”等。
近年来医院信息化建设水平的提升以及电子病历的普及,为大规模应用机器学习算法解决医学领域的研究任务提供了便利。针对医学术语归一(标准化)任务,学术界也开展了一系列评测任务,包括:ShARe/CLEF-2013任务1[1]、SemEval-2014 任务7[2]、SemEval-2015任务14[3]和N2C2-2019任务3[4],以上评测任务均是英文领域。针对中文数据集,在目前所知范围内,CHIP-2019“手术名称标准化”任务(1)http://cips-chip.org.cn/evaluation应该是第一个中文医学术语归一化评测任务。这些评测任务和数据集均有效地推动了相关技术的发展。
术语归一任务的研究大致经过了几个阶段:基于规则的方法[5-6]、基于机器学习的方法[7]和基于深度学习的方法[8-9]。本文在使用检索技术生成候选答案的基础上,借鉴了语言模型BERT的思路,在重排序阶段使用BERT[10]模型对候选答案进行打分重排序,单模型取得89.1%的准确率,最终提交的融合模型在测试集上取得92.8%的准确率,基本达到实际应用标准。本文采用的方法具备很好的泛化能力,可应用在其他类型的医学术语标准化任务上。
1 相关工作
早期的研究方法均是围绕基于规则的方法开展的,其中代表性的工作包括Ghiasvand等[5]在SemEval-2014任务7[2]上提出的基于编辑距离特征来生成候选集的方法,该方法首先通过训练数据的每一条实体及其在UMLS系统对应的标准术语学习到554种编辑距离模式,该模式之后被应用到测试集来增强候选答案的覆盖,在SemEval任务上取得了最佳性能;Kang等[6]在生物领域文本上提出了5种规则来提升疾病术语的归一化性能。
针对实体归一化任务,常见的机器学习解决思路是利用学习排序(learning to rank(2)https://en.wikipedia.org/wiki/Learning_to_rank)的方法来生成最终的答案,在医学NLP领域的代表性工作是Leaman等[7]提出的利用pairwise排序学习的方法,该方法利用向量空间来表示实体以及数据库中的标准术语,通过学习相似矩阵来完成给定实体和候选答案之间的匹配映射。
深度学习时代,研究者对实体归一任务提出了更广泛的解决思路,其中代表性工作是Luo等[8]提出的多视图CNN模型,该方法利用多任务共享网络结构同时学习出院记录的诊断信息和手术信息标准化,在中文数据集上取得了不错的性能;随着语言模型的兴起,预训练语言模型在多项NLP任务上均刷新了最优结果,针对医学术语归一任务,Ji等[9]提出的利用BERT进行重排序的思路,在多个标准数据集上均取得了最佳性能。
本文在前述方法的基础上,基于通用的检索+重排序框架,利用给BERT输入对(实体词,候选词)进行打分重排序,在CHIP评测任务上取得了不错的性能效果。
2 任务描述与数据统计
2.1 任务描述
针对中文电子病历中挖掘出的真实手术实体进行语义标准化。具体来说,给定一手术原词,要求系统给出其对应的手术标准词。其中,所有手术原词均来自于真实医疗数据,并以《ICD9—2017协和临床版》 手术词表为标准进行标注。
2.2 数据统计
表1展示了本次评测任务的部分样例数据,数据集中“手术原词”和“归一化标准词”之间存在4种匹配对应关系:

表1 手术术语标准化任务示例
(1)“一对一”关系:一个手术原词对应一个归一化标准词。
(2)“一对多”关系:一个手术原词对应多个归一化标准词。
(3)“多对一”关系:多个手术原词对应一个归一化标准词。
(4)“多对多”关系:多个手术原词对应多个归一化标准词。
数据集的详细统计信息如表2所示。通过观察表2可以发现,1个手术原词最多可以对应到7个标准词。因此,相较于单纯的“一一对应”标准词归一化,本次评测中涉及到的任务更具难度和挑战。
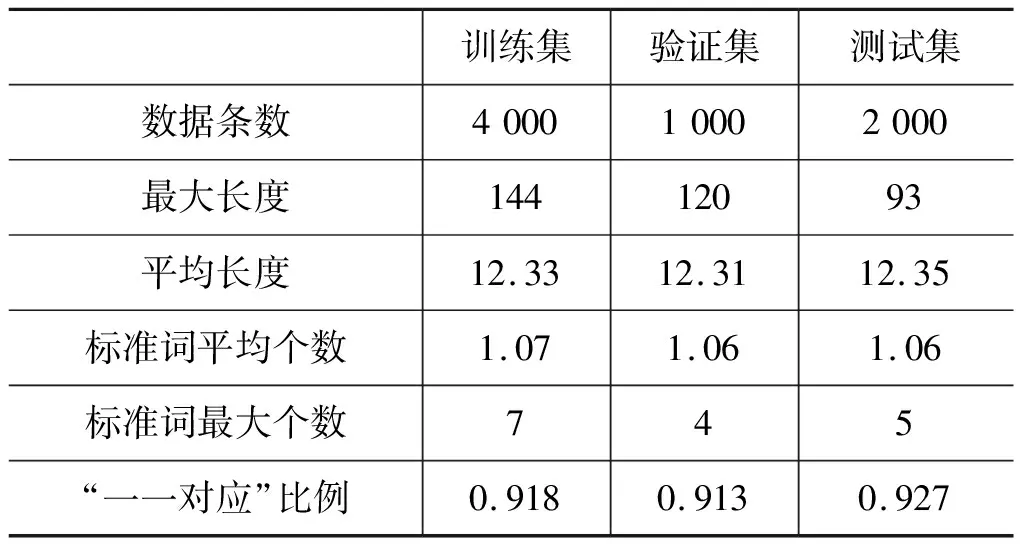
表2 评测数据分布统计
2.3 评测指标
任务以准确率(accuracy)作为最终评估标准,准确率的定义为:给出正确的手术原词加手术标准词的组合/待预测手术原词的总数,形式化描述为:对于一条手术原词Si,其对应N个归一化标准词。模型预测输出了M个归一化标准词,则该条数据的得分如式(1)所示。
(1)
总得分如式(2)所示。
(2)
其中,k表示测试集中的手术原词条目数。
3 方法
本文的模型整体架构如图1所示。首先,针对编码文件和标注文件分别建立索引;然后,对于给定的“手术原词”,分别查询两个索引文件,生成候选答案;最后,将各候选答案与手术原词一起,输入BERT模型打分,并基于BERT模型给出的分数输出“标准词”。接下来,本文将分别介绍候选答案生成、候选答案打分、后处理和模型投票部分。
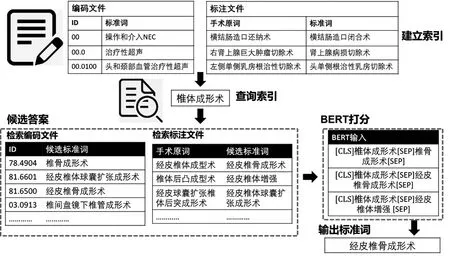
图1 模型整体架构图
3.1 候选答案生成
本文使用Lucene(3)http://lucene.apache.org/工具生成候选答案,Lucene是一套用于全文检索和搜索的开放源码程式库,其默认排序基于TF-IDF和向量空间模型,可以方便而快速地找到与被检索短语在文字上相似的目标结果。本文设计了两种检索方式,分别建立了索引。第一种方式是检索“编码—标准词”,其目标是直接查找与待归一化的“手术原词”最相近的“标准词”。第二种方式是检索“标注历史”,其目标是在标注数据上查找与待归一化的“手术原词”最相近的数据,并取该条数据的归一化“标准词”作为候选答案。本文通过结合上述两种检索方式,各取检索得分排名前20的“标准词”作为候选答案,可以达到超过99%的覆盖率。
3.2 候选答案打分
通过Lucene检索得到候选标准词后,本文基于Transformer框架对候选标准词进行打分。由于手术原词和标准词不易拆分,如上文例子中提到的“多对一”情况,将手术原词拆分后就无法对应到正确的标准词了。因此,本文将该任务定义为:某一个归一化标准词是否被包含在手术原词之中。即将整个手术原词和一个归一化标准词作为一条输入,判别该归一化标准词是否应该出现在最终输出之中。本文使用BERT模型作为打分模型,如图2所示。

图2 BERT打分模型
对于“手术原词”和一个候选“标准词”,本文按照BERT模型的规范,将其按字分词并排列成“[CLS]手术原词[SEP]标准词[SEP]”的形式,输入BERT编码器。然后将BERT编码器的结果,即“[CLS]”位置处的表示,输入多层感知机中,得到二维向量。最后,通过Softmax归一化为0到1之间的概率。
3.3 后处理
针对模型的输出结果,本文采用了两种后处理方式:①若原词中不包含分隔符号“+”,则只输出得分最高的一个手术标准词;②若所有候选得分均未超过选定的阈值,则从候选标准词中输出得分最高的一个手术标准词。
3.4 模型投票
本文在提交结果时使用集成模型,按上述模型设定,共训练了10组模型。这10组模型的区别在于训练集的不同,因为评测任务参赛选手自由划分训练集和验证集,我们将验证数据集随机等分成三份,在某些实验组上会将验证集的两份加入到原始训练集中,作为最终的模型训练数据,将剩余的一份验证集作为最终的验证集。为了集成这10组模型,本文通过投票的方式来集成不同模型的输出,得到最终输出结果。对于每一个输入的手术原词,10组模型分别输出各自的“标准词”预测结果,统计所有预测结果中各个“标准词”的出现次数,将出现次数最多即得票数最高的“标准词”作为最终预测结果,若有多个候选“标准词”的得票数相同,则这些候选词均会被输出作为预测结果。
4 实验结果及分析
4.1 实验结果
对于训练数据的构造和采样,本文尝试了多种方式,结果如表3所示。基于在验证集上的结果,最终本文选择“BERT-Base-Chinese(4)https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip”初始化的“BERT-取前20候选+10倍正例”的模型设定。
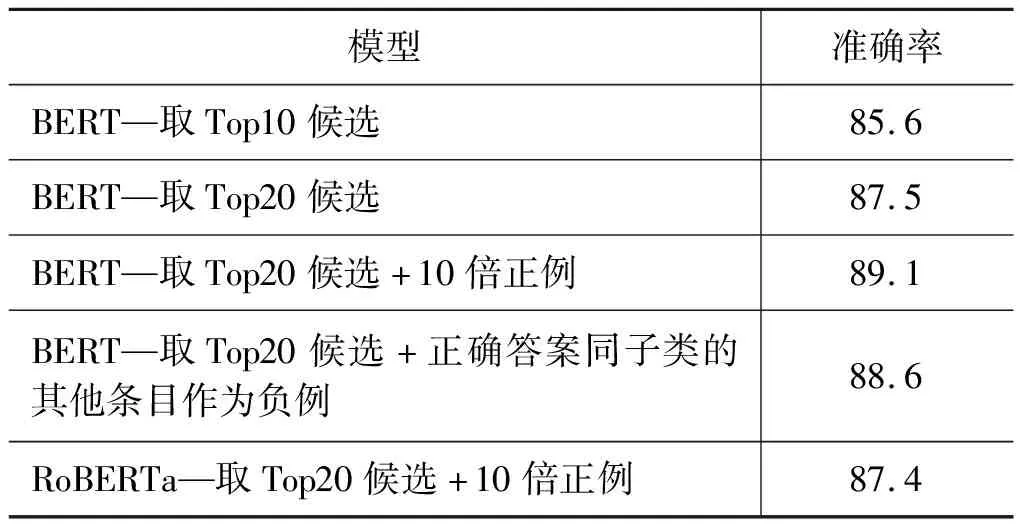
表3 不同采样策略下的模型准确率
4.2 实验分析
4.2.1 候选答案生成
在候选答案生成中,我们结合了两种检索方式,表4展示了在验证集上两种方法的检索覆盖率。

表4 检索方式覆盖率统计
可以观察到,使用单一检索方式,都无法覆盖到全部数据。“编码检索”的缺点在于:对于与标准词在字面上差异较大的手术原词,无法检索到候选答案。“历史检索”的缺点在于:未在标注历史中出现过的归一化“标准词”,无法得到正确的候选答案。而通过结合上述两种方式,各取检索得分排名前20的“标准词”,就可以达到超过99%的覆盖率,基本上解决了候选答案生成问题。
在验证集上各取排名前50的检索结果也未能覆盖的几个例子如表5所示,从中可以观察到,这几个例子的“手术原词”和“归一化标准词”在字面上差距较大,并且存在无法解析的缩写,未来需要医学相关知识或更多的标注数据,以帮助模型得到更好的检索结果。

表5 检索召回失败举例
4.2.2 模型集成
本文用不同的训练数据训练了10组模型进行集成,为简单起见用数字1、2、3来表示验证数据集被随机分成的三部分,10组模型在验证集上的结果如表6所示。

表6 不同stacking策略下模型准确率
4.3 实验参数设置
本文方法BERT中的参数均使用“BERT-Base-Chinese”中的原始参数。隐藏层的维度为768,dropout参数设置为0.1,batch-size大小设置为64,选择Adam作为优化器,学习率设置为0.000 01,训练轮次设置为40。两种检索方式均取排名前20的检索结果作为候选答案。
5 错误分析
针对模型在验证集上预测错误的例子,我们进行了人工分析和归纳,模型预测的错误大致可以分为两类。
(1)模型对“术式”“操作”和“部位”的特征学习得不充分,这类错误占据了85.6%,如对手术原词“腹腔镜下胆囊取石术”,模型预测的最高分是“胆道镜下胆管取石术”,而对应的标准术语应该是“腹腔镜下胆囊切开取石术”,在这个例子中,模型没有区分出“腹腔镜”和“胆道镜”这两个操作原语。
(2)模型预测出来的标注词数量错误,这类错误占据了3.8%,主要出现在手术原词和标准词个数不一致的情况下,模型未能很好地学习到数量上的映射。
6 总结
在CHIP-2019评测任务1上,本文提出了一种比较通用的解决术语归一的框架:检索+重排序,检索部分采用了开源的Lucene对训练数据和标准答案集做检索生成候选答案;重排序部分本文采用了当下流行的BERT语言模型来辅助(手术原词,候选词)打分排序。本文提出的方法在测试集上单模型达到了89.1%、融合模型达到92.8%的性能,证明了该方法的有效性。本文提出的方法具备较强的通用性,可同步迁移到医学领域其他类型术语的标准化任务上。同时本文提出的方法也有一定的局限性,如“错误分析”一节中所提到的,未能够利用医学领域知识,因此如何在模型中引入医学领域知识是未来重点的突破方向之一。此外,本文用到的BERT模型是官方开源的基础模型,本次任务由于时间关系以及医学文本的隐私性,我们未能对语言模型进行fine-tuning工作,医学领域的语言模型也是后续可尝试的方向。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
科普童话·学霸日记(2020年1期)2020-05-08
音乐天地(音乐创作版)(2019年10期)2020-01-06
小天使·一年级语数英综合(2019年2期)2019-01-10
求学·理科版(2017年3期)2017-04-27
中学生英语·阅读与写作(2014年7期)2014-08-22
中国科技术语(2012年3期)2012-03-20
中国科技术语(2012年3期)2012-03-20
