
基于ELMo和Transformer混合模型的情感分析
2021-04-29 09:30:04赵亚欧张家重李贻斌王玉奎
中文信息学报 2021年3期
赵亚欧,张家重,李贻斌,王玉奎
(1.浪潮集团 金融信息技术有限公司,山东 济南 250101;2.济南大学 信息科学与工程学院,山东 济南 250022;3.山东大学 控制科学与工程学院,山东 济南 250061)
0 概述
情感分析是自然语言处理的一个重要应用领域,其目的是利用计算机技术分析文本,获得文字背后的情感信息。随着互联网技术的发展,人们的活动越来越多地集中在网络上,人们通过电商网络获取商品信息,购买商品并发表评论;利用新浪、网易等主流网站获取新闻信息,并发表自己的观点;利用微博、微信等APP与其他人互动。如果能对网络上的文本进行情感分析,则有助于电商了解用户需求,实现对商品的改进;有助于新闻媒体了解用户的喜好,进行新闻的个性化推送;也有助于政府机构对舆情进行监控,避免重大舆情事件的发生。
传统的情感分析通常是采用人工抽取文本特征的方式,然后通过训练机器学习分类器实现文本的情感分类。常用的机器学习分类器有支持向量机(support vector machine,SVM)[1]、朴素贝叶斯(naïve bayes,NB)[2]、深度森林(deep forest,DF)[3]等。但此类方法需要针对不同的应用领域构造不同的特征提取方法,需要相关领域专家参与。
近年来,人工神经网络方法也被用于情感分析。人工神经网络可以自动抽取文本特征,具有人力成本低、领域知识要求少、应用范围广的特点,渐渐成为该领域的主流。Kim[4]首先将神经网络方法用于情感分类,该方法将Word2Vec工具在Google News文本语料上训练所获得的词向量作为神经网络输入;然后利用卷积神经网络(convolutional neural network, CNN)模型对句子的情感倾向进行分类。其后,Attardi等[5]使用卷积神经网络进行情感分类,并在三分类情感数据集上取得了较好的结果。
由于卷积神经网络无法有效提取词语序列之间的顺序信息,Socher等[6]提出使用递归神经网络(recurrent neural network, RNN)进行情感分析,并取得了不错的效果。此外,长短时记忆网络(long-short term memory, LSTM)也被用来进行情感分析[7],相对于递归神经网络,LSTM能更好地提取序列之间的长程信息,效果更好。
为了解决LSTM门限单元计算复杂度高的问题,Cho等[8]提出一种LSTM 的替代方案——门限循环单元(gated recurrent unit,GRU)。与LSTM 模型相比,GRU模型结构更加简单,可以大大提高模型的训练和推理速度。
注意力机制是最近NLP领域引入的一个重要概念,其核心是对观察到的数据分配权重,通过权重分配达到提取文本核心语义信息的目的。2016年,Bahdanau等[9]首先将注意力机制用在机器翻译领域。其后,Luong 等[10]、Yin等[11]、Wang等[12]将注意力机制和神经网络结合,进行情感分析。2017年,Vaswani 等[13]提出了多头自注意力(multi-heads self-attention), 该机制能够通过对句子本身分配权重、计算加权和,从而从中抽取有效的语义信息。多头自注意力基于Tansformer模型,最初用于机器翻译,Radford在此基础上提出了GPT模型[14],该模型仅保留了Transformer的decoder部分,剔除了decoder部分的第二个多头注意力结构。这样结构更加简单,与传统的RNN模型相比,运行速度更快、精度更高。
GPT模型仅是一个前向语言模型,无法利用token对应的下文信息。为了解决这个问题,Devlin等[15]提出了BERT模型,该模型采用类似完形填空的方式,随机选择句子中的token进行mask,并同时利用mask的上下文信息预测该token。该模型虽然是一个双向模型,但在训练中引入了无关的mask标记,影响后续推导。其后,Yang等[16]提出了XLNet模型,该模型采用随机排列token的方式,并引入了双流注意力机制,不但能有效地利用句子的上下文信息,也避免了mask标记的引入。
使用神经网络进行情感分析,除需要选择一个合适的神经网络分类模型之外,获得合适的词向量表示也十分重要。词语的表征最早使用one-hot、bag-of-words等离散表示,后来基于神经网络的词嵌入(word embedding)方法被引入用来生成词语的紧致连续表示,这其中的代表有Word2Vec[17]和GloVe[18]等方法。由于此类方法不需要任何先验知识,只要提供文本语料就能训练出有效的语义表示,因此渐渐成为主流。但此类方法缺点也很明显,主要是仅能获得词语的单个语义表示,对于多义词,所获得的词向量是多个语义的合成,这在很大程度上影响了词语语义表示的准确性,给后续任务的使用带来不便。
为了解决这个问题,本文提出了基于ELMo(embeddings from language models)和Transformer的混合模型,用于短文本情感分析。ELMo是一个基于双向LSTM网络的语言模型,通过学习预训练语料,能够得到词语的深度上下文嵌入向量。该向量不仅包含词语本身的语义信息,还包含其对应上下文的语境信息,与传统词嵌入方法相比,优势十分明显。
在情感分类模型方面,本文使用改进的Transformer模型,Transformer模型是经典的Seq2Seq模型,使用多头自注意力机制(multi-heads self-attetion),并在机器翻译任务中取得了很好的效果。本文对该模型进行了改进,更改了Transformer的解码器,使其更加适合情感分类问题。实验在NLPCC2014 Task2和谭松波等人的酒店评论数据集上进行,结果表明,本文提出融合ELMo和改进Transformer的情感分析模型,其效果均高于主流方法。
1 ELMo模型
ELMo模型于2018年由华盛顿大学的Peters等[19]提出,目的是建立一个上下文相关的词语向量,为多义词提供更好的表示,克服传统词嵌入模型只能表达词语单一语义的问题。该模型的思路是利用双向LSTM网络,通过在预训练语料上训练语言模型,得到词语上下文相关的语义向量。
1.1 利用LSTM网络构建语言模型
语言模型是计算给定句子出现概率的模型。假设含有N个词语的句子S={t1,t2,…,tN},如果句子中第k个词语tk出现的概率仅与其前面出现的k-1个词有关,则该语言模型为前向语言模型。同理,如果假设句子中第k个词语tk出现的概率仅与其后面N-k个词语有关,则该语言模型为后向语言模型。
ELMo模型利用LSTM网络构建前向语言模型。假设t1,t2,…,tk对应的词向量分别为x1,x2,…,xk(该词向量可使用Word2Vec等工具计算获得),将其依次输入一个含有L层的LSTM网络,得到对应层的隐状态hl,1,hl,2,…,hl,k,其中l为LSTM的层数l={1,2,…,L}。取最后一层隐状态hL,1,hL,2,…,hL,k,输入softmax层转化为概率输出yL,1,yL,2,…,yL,k,则该输出为前向语言模型对应词语的概率分布P(t1),P(t2|t1),…,P(tk|t1,t2,…,tk-1)。
同理,ELMo利用另外一个LSTM网络构建后向语言模型,该LSTM的方向和前向LSTM的方向相反。将t1,t2,…,tk对应的词向量x1,x2,…,xk输入,同样得到对应层的隐状态h′l,1,h′l,2,…,h′l,k,将最终层对应的隐状态经过softmax映射转换为概率输出y′L,1,y′L,2,…,y′L,N,此概率为后向语言模型对应词语的概率分布P(t1|t2,…,tN),P(t2|t3,…,tN),…,P(tk|tk+1,…,tN)。
最后,为了构建双向语言模型,连接两个方向LSTM最终层的隐状态,得到HL,1,HL,2,…,HL,N,其中HL,k={hL,k,h′L,k},k表示第k个位置词语输入对应的隐状态。HL,k经过softmax激励函数得到Yk,即为双向语言模型第k个词语对应的概率分布P(tk|t1,t2,…,tk-1,tk+1,…,tN)。模型如图1所示。

图1 ELMo模型
1.2 ELMo词向量
ELMo词向量通过对双向LSTM每一层的隐状态向量加权求和获得。假设前向LSTM和后向LSTM隐层连接后的向量为Hl,k,输入词向量为xk,则ELMo词向量表示为:
(1)
其中γ为缩放因子,sj为针对隐状态的归一化系数,表示每一层隐状态的占比。这两组参数通过后续任务优化获得。如果不对后续任务进行二次优化,也可以直接使用LSTM最后一层隐状态作为ELMo词向量,即
ELMok=HL,k
(2)
2 基于Transformer的情感分类模型
2.1 自注意力机制
注意力机制(attention mechanism)来源于人类视觉处理过程,最初应用在机器翻译任务中。其核心思想是,通过计算译文句中单词与原文句中单词之间的相互关系,得到译文单词相对于原文单词的权重分布,然后通过加权处理,得到译文单词的最佳语义表示。自注意力是注意力机制的一种特殊形式,也叫内部注意力,特指注意力的计算仅对于同一句子进行。
自注意力机制通过三个矩阵实现,分别是查询(Query)矩阵Q、键(Key)矩阵K和值(Value)矩阵V。Q和K用于计算输入词语与句子中其他词语之间的相似性,并根据相似性计算注意力的分配比例,值矩阵V表示句中词语对应的注意力值。Q、K、V可以采用多组,每一组被称为一个头(head),此时被称为多头自注意力。
实际计算中,三个矩阵均为句子矩阵X,X∈N×d的线性变换,其中N为句子长度,d表示词向量的维度,其计算如式(3)所示。
(3)
每一组Qi,Ki,Vi矩阵计算一个头的注意力数值headi,将多个headi连接,得到最终的多头注意力向量Z,计算如式(4)所示。
(4)
2.2 Transformer模型
Transformer由Google的Vaswani等人于2017年提出,最早用于自然语言翻译。该模型为典型的Encoder-Decoder结构,Encoder和Decoder均可叠加多层。Encoder模块包含一个自注意力层和一个前馈神经网络层。自注意力层采用多头自注意力机制,前馈神经网络是一个标准的两层神经网络,第一层使用Relu激活函数,第二层无激活。此外,注意力层和前馈神经网络都采用残差连接,并进行批标准化(batch normalization),进一步增强网络的泛化能力。
Decoder模块包含两个自注意力层和一个前馈神经网络,实现译文句子的解码。该模块的第一个注意力层为带屏蔽的多头自注意力层(masked multi-head attention),目的是在推导过程中屏蔽未来输入。该模块的第二个注意力层和前馈神经网络与Encoder模块中的结构几乎完全一样,唯一的区别是,Decoder的输入除了包含前一层的输出之外,还增加了Encoder的输出。多个Decoder模块可以叠加,最后一个Decoder的输出经过一个线性变换,并利用softmax函数,得到输出词语的预测概率。
Transformer本质上是一个自编码器,不能利用词语之间的顺序信息,所以引入位置嵌入向量(position embedding,PE)来表示词语的位置。PE的计算如式(5)所示。
(5)
其中d表示PE的维数,pos表示词语在句中的位置。2i表示PE的偶数维度,2i+1表示奇数维度。Transformer实际使用的输入是词语词向量和PE之和。
Transformer模型抛弃了传统的RNN网络结构,全部使用自注意力机制实现。该模型不像RNN模型那样每次只能提取一个方向的特征,可直接提取句子的双向语义特征。此外,该模型还避免了RNN的梯度衰减和长程信息丢失问题,且更易于并行实现。
2.3 改进的Transformer的分类模型
虽然Transformer模型有诸多好处,但该模型是经典的Seq2Seq模型,输入、输出都是词语序列,无法直接用于情感分类任务。为了解决这个问题,本文对Transformer模型进行了修改,主要有以下几点:
(1)Transformer的Encoder模块的作用是将整个句子的语义融合到每个词语中,这样做既可以丰富词语的语义,也有利于多义词的语义消歧。但由于多头注意力运算是针对单个词向量进行的,因此编码结果仍然是单个词向量。然而,情感分析需要的是句子的整体语义表示,需要将编码后的词向量进行融合。为解决这个问题,本文在最后一个Encoder模块中增加了一个concat单元,将所有的词语向量进行连接,构成整个句子向量。假设句子的编码器的输出为e1,e2,…,eN, 每个向量的维度为d,则连接之后的句子向量为E={e1,e2,…,eN},E∈RN×d。
(2)对于Transformer的Decoder模块,其主要目的是根据每个词语的Encoder信息,结合译文上文信息,对译文进行解码,这部分对分类任务而言是不必要的。本文去除了原结构的两个自注意力层,仅保留残差连接和前馈网络。其考虑是,concat模块的作用只是单纯地连接多个Encoder输出的词向量,并不能很好地对其语义特征进行融合,因此,保留一个前馈网络,将连接后的向量进行二次映射,以保证更好的融合效果。相对于原结构,前馈神经网络不再针对单个词语进行,而是针对整个句子向量E进行;保留残差连接目的是考虑到Decoder模块可以叠加多层,残差连接能保证初始信息向更深层模块传递。
Decoder模块的输入有两个,一个是Encoder编码后的句子向量E,另一个是前一层Decoder的输出E′。对于第一层的Decoder结构,其前一层Decoder输出E′为原始句子词向量连接后的向量X={x1,x2,…,xN},X∈RN×d。
(3)最终层Decoder的输出为Z,Z∈RN×d。为了进一步抽取主要特征,添加一个max池化层,获取融合后词向量在所有维度上的最大值,其输出为Z′,Z′∈Rd,计算公式如式(6)所示。
(6)
其中,Z′d表示输出词向量第d维分量值,Zi,d表示Z矩阵i行d列的分量值,max表示取Z矩阵每一行的最大值。
最后,池化后输出Z′接一个线性映射单元,并利用softmax函数计算各类情感倾向的概率,计算公式如式(7)所示。
Y=softmax(Z′W+b)
(7)
其中,W,W∈Rd×2为神经网络权值矩阵,b,b∈R2为网络偏置项。Y表示二分类输出,表示输入文本属于正面、负面情感的概率。改进后的模型结构如图2所示。

图2 改进的Transformer分类模型
模型优化采用交叉熵损失函数,如式(8)所示。
(8)
其中,S表示训练样本总数,k表示类别,Ypi,k表示第i个样本对应第k个类别的期望输出概率,Yi,k表示第i个样本对应第k个类别的模型实际输出概率。
2.4 基于ELMo和Transformer的混合模型
基于上述模型,本文提出了基于ELMo和Transformer的混合模型用于情感分析,该模型可分为6个主要模块,结构图如图3所示。
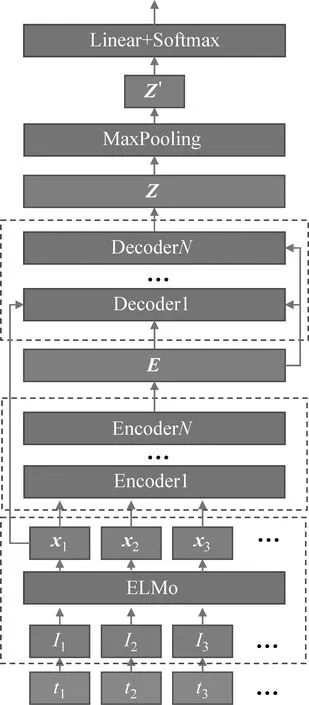
图3 基于ELMo和Transformer的混合模型结构图
(1)句子分词模块。利用中文切词工具,如结巴分词、StanfordNLP分词工具对中文句子进行分词,将其切分为独立的token。
(2)词向量计算模块。利用Word2Vec工具,在预训练语料中训练,获得词嵌入向量。然后将上一步获得的token转换为对应词向量。
(3)ELMo词向量计算模块。将Word2Vec获得的词向量输入ELMo模型,并在预训练语料中训练该模型,取双向LSTM最后一层的隐状态向量并进行连接,生成ELMo词向量。
(4)Encoder计算模块。ELMo词向量输入Transformer的Encoder模块,获得对应的编码向量。Encoder模块可以叠加多个,进行多次编码。
(5)Decoder计算模块。连接编码向量并输入Decoder模型进行解码,经过多次特征映射,获得整个句子的语义向量表示。Decoder模块同样可以叠加多个,进行多次映射。
(6)分类输出模块。将Decoder生成的语义向量输入线性模块,然后经过softmax激励函数,得到最终的分类结果。
相对于传统的情感分析模型,该模型有如下优点:
(1)输入分类器的词向量不再是原始的词嵌入向量,而是ELMo向量。ELMo向量既包含词语本身语义,也包含词语对应的上下文语义,包含的信息更加丰富。
(2)情感分析模型大多基于自回归结构或自编码结构,本文模型采用这两种结构的组合,即ELMo的自回归结构(BiLSTM)和Transformer的编码器结构(multi-heads attention),两种结构的组合能更好地提取特征。
(3)本文提出的改进Transformer结构利用句中所有词语融合后的向量作为最后的句子向量(Concat+Feed Forward+Max Pooling),与BERT仅采用[CLS]标记相比,能更好地表示整个句子。
3 实验
3.1 数据集
实验在两个数据集上进行,一个是自然语言处理和中文计算国际会议公布的深度学习情感分类数据集(NLPCC2014 Task2)[20]。该数据集分为训练集和测试集,其中,训练集包含10 000条产品评论信息,正面和负面评论各5 000条;测试集包含2 500条产品评论信息,正面和负面评论各1 250条。为了评估模型参数,取训练集的80%作为实际的训练集,剩余20%作为开发集。
另一个是谭松波等[21]收集的酒店评论数据集,该数据集包含10 000条评论信息,其中正面评论7 000条,负面评论3 000条。根据不同规模,该数据集被划分为四个不同的数据集,分别是htl-2 000,htl-4 000,htl-6 000,htl-10 000。其中,前三个数据集为平衡数据集,正面评论和负面评论数据各半,最后一个数据集为非平衡数据集。实验中,为了方便和前人的结果进行比较,采用10折交叉验证,每次取90%样本作为训练集,剩余10%的样本作为测试集。模型参数与NLPCC2014数据集的最优参数保持一致,因此不再划分开发集。
3.2 实验参数设置
本实验模型采用ELMo和Transformer的混合模型,其中,ELMo模型输入词向量维度为256,双向LSTM的层数为2,展开深度为30,输出ELMo词向量的维度为512。ELMo模型采用预训练方式,预训练在百科类问答语料上进行,该语料包含150万个预先过滤的问题和答案。(1)语料下载地址: https://github.com/brightmart/nlp_chinese_corpus
Transformer的Encoder采用多头注意力机制,多头数目定为8,多头注意力输出向量的维度为512,神经网络的激励函数采用gelu(Gaussian Error Linear Units)[22],其形式为:

(9)
Decoder模块采用本文2.3节描述的改进模型。
实验评测采用正确率指标(Accuracy,A),其计算如式(10)所示。
(10)
其中,TP、TN、FP、FN分别对应阳性、阴性、假阳性和假阴性样本的数目。
实验中,将整个微博评论短文本视为一个长句子,预处理去除停用词、标点并进行分词,然后输入ELMo模型获得该句子对应的ELMo词向量集合。输入Transformer时,要设定最大句子长度(ELMo词向量集合所包含最大词向量个数),对长度大于该数值的句子进行截断,对长度小于该数值的句子进行填充。(填充
为了获取最优实验参数,句子最大长度采用64、128和256,Encoder和Decoder层数采用1~8层,在NLPCC2014 Task2数据集上进行实验,开发集上的结果如图4所示。

图4 采用不同Encoder/Decoder层数和不同句子最大长度在开发集上的实验结果
从图4中可以看出,当句子最大长度为64时,平均正确率最低,为80.96%,句子最大长度为128和256时,正确率相当,但句子最大长度为128时,正确率略高且更稳定。考虑到模型的计算复杂度,选择最佳句子长度为128。对于层数,从图中可以看出,当Transformer层数为6时,效果最好,达到了83.97%,实验结果和原始的 Transformer构造的机器翻译模型设置的最优层数相同。
3.3 本文模型与其他模型的对比
为了证明本文模型的有效性,实验分别在NLPCC2014 Task2和谭松波的酒店评论数据集上进行,对比实验中采用如下模型:
(1)经典的LSTM模型。使用Word2Vec提取词语向量,然后利用LSTM模型进行情感分类。
(2)GRU模型。GRU模型是LSTM模型的一种变体,结合了遗忘门和输入门,合成为一个更新门限,相对于LSTM单元更加简单,更利于训练。
(3)CNN模型。输入使用Word2Vec提取词语向量,然后利用卷积、池化操作进一步抽取整个句子的语义特征,最后通过softmax激励进行情感分类。
(4)LSTM+CNN2+CNN3混合模型[20]。由于CNN不考虑句子中词语之间的顺序关系,因此考虑在此基础上融合LSTM模型,进一步丰富所提取的特征,其中CNN2、CNN3分别表示采用卷积核大小为2、3的卷积神经网络。
(5)SVM模型,经典的机器学习模型,其核心思想是找到高维空间中的最优决策面。
(6)NB模型,朴素贝叶斯模型。
(7)BCWCNN模型[23],双线性字词卷积神经网络。为了克服词向量表征语义不充分的问题,选取词向量和字向量作为特征输入卷积神经网络进行训练,然后使用融合后的特征进行分类。
(8)WCTAT-Bi-LSTM模型[24],基于Bi-LSTM 的字、词和词性注意力模型。该模型输入采用词向量和字向量的融合向量,分类模型使用含有注意力机制的双向LSTM模型。
(9)BFDF模型[25],基于强化表征学习的深度森林模型。
(10)Google的BERT-base模型,中文模型采用科大讯飞提供的BERT-base预训练模型[26],输入采用字向量。
(11)Word2Vec+Transformer模型。输入采用Word2Vec提取的词向量,分类模型采用本文2.3节介绍的Transformer模型。
(12)ELMo+Transformer。输入向量采用ELMo词向量,分类模型采用本文2.3节介绍的Transformer模型。
上述神经网络模型中,模型(10)、(11)、(12)的Transformer采用gelu激励函数,其余模型均采用relu激励,模型(11)中的ELMo也采用relu激励。
3.4 结果分析
在NLPCC2014 Task2数据集上的实验结果如表1所示。从表中可以看出,本文提出的基于ELMo和Transfomer的混合模型取得了最好的效果,正确率达到了79.68%,与LSTM模型相比,正确率提升13.04%;与CNN模型相比,正确率提升6.32%;与LSTM+CNN2+CNN3的融合模型相比,正确率提升3.52%;与BERT-base模型相比,正确率也略有提升。后三个模型均采用Transformer作为分类器,其正确率好于其余非Transformer模型,这说明多头注意力机制在抽取文本整体语义特征方面,较传统的CNN或RNN模型更具优势。
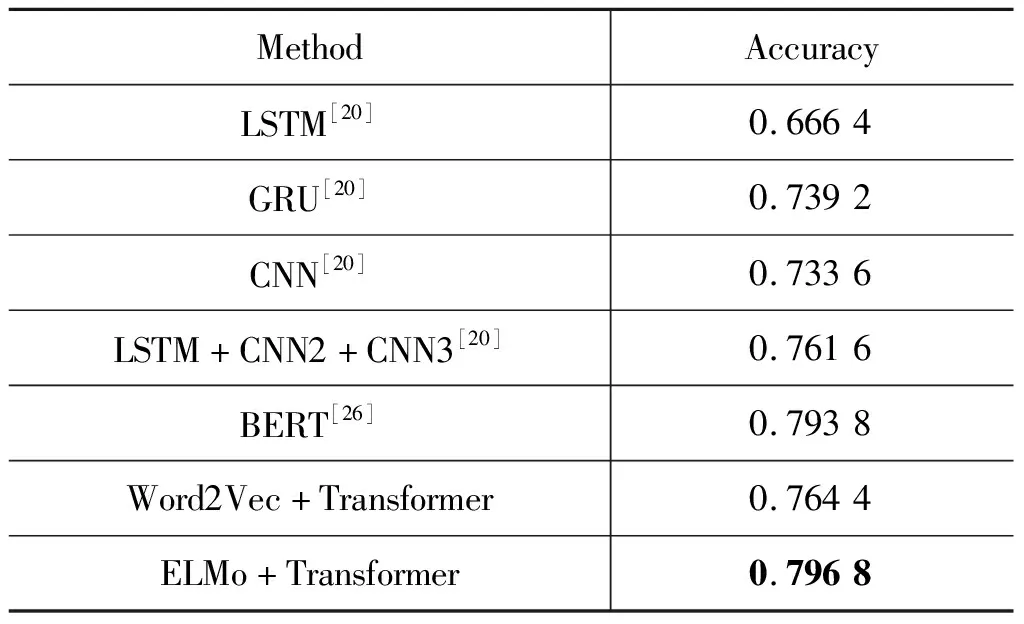
表1 不同方法在NLPCC2014 Task2数据集上的实验结果
本文方法使用ELMo词向量作为Transformer的模型输入,与使用Word2Vec词向量相比,分类性能提升了3.24%,这说明ELMo中的双向LSTM网络在提取词向量特征方面作用明显。此外,ELMo是预训练模型,训练采用了超大规模语料,相对于仅使用任务数据进行训练双向LSTM模型,其抽取的特征涵盖的范围更广,更具一般性。
在酒店评论数据集上,实验分别对htl-2 000,htl-4 000,htl-6 000和htl-10 000四个数据集进行了测试,从表2可以看出,相较于BCWCNN模型,正确率分别提升了1.2%、0.25%、1.48和1.96%,对于采用融合字词向量特征的双向注意力LSTM模型,正确率分别提升了0.7%、2%、1.98%和1.36%。这说明本文方法相对于传统方法具有优越性,这一方面是由于ELMo向量相对于传统的词向量融合了词语上下文,能够更好地表示多义词,另一方面也是因为Transformer的多头注意力机制能够有侧重地对多个词向量进行融合,更好地提取整句语义。
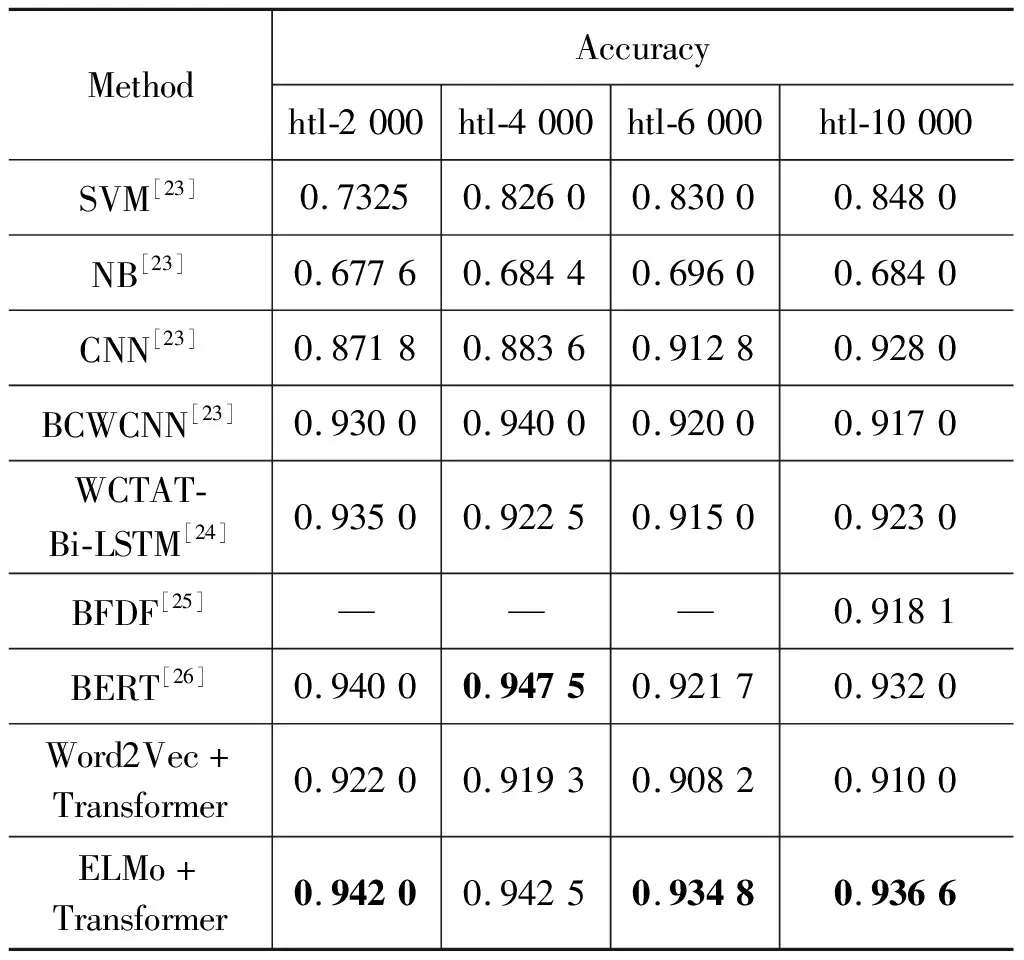
表2 不同方法在酒店评论数据集上的实验结果
与BERT模型相比,除在htl-4 000数据集上本文模型正确率略低之外,在另外三个数据集上正确率分别提升0.2%、1.31%和0.46%。这主要是因为BERT模型仅使用输出的第一个[CLS]标记作为整个句子的语义向量,而本文提出改进的Transformer模型将所有词语的词向量进行Concat并在Decoder阶段进行二次映射,最后通过Max Pooling抽取融合后词向量在每个维度的最大值,将该值作为整个句子的语义向量进行预测,该向量所包含的语义更加全面。
此外,本文方法与BERT等方法的预训练阶段不同,BERT直接预训练分类模型,而本文方法预训练的是ELMo模型,没有预训练基于Transformer的分类模型。这样,无须引入额外mask标记,减少了mask对后续推导的影响。
4 结束语
本文提出了基于ELMo和Transformer的混合模型用于情感分析,该模型抛弃了传统的词嵌入方法(如Word2Vec、GloVe),利用ELMo模型抽取词向量。与传统方法相比,ELMo模型引入双向LSTM模型学习词语的上下文,进一步丰富了词向量的语义,能更好地表示多义词。分类器采用Transformer模型,采用多头注意力机制,能够以不同的方式对句子中的词向量进行融合,有侧重地抽取句子的整体语义。Transformer相对于RNN模型,是真正意义上的双向模型,能够直接融合词语的上下文特征,而非简单连接两个方向提取的特征向量,因此提取的特征更加准确。实验在NLPCC2014 Task2情感分类数据集和谭松波的酒店评论数据集上进行,结果证明了本文方法的有效性。
近些年来,注意力机制被证明在提取语义特征方面十分有效。对于ELMo模型,本文采用双向LSTM网络生成上下文相关的词向量,并没有引入注意力机制,下一步考虑在模型中引入注意力机制,进一步增强ELMo模型表征词向量的能力。此外,先在大规模语料中预训练模型,然后在新的任务上精调参数已成为当前自然语言处理的主流范式,此时,预训练的语言模型也是后续任务的分类模型,其中代表如BERT。因此,构造基于ELMo的预训练和分类综合模型也是下一步的研究方向。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
开放教育研究(2020年2期)2020-03-31 01:54:14
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
现代语文(2016年21期)2016-05-25 13:13:44
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
