
利用质量估计改进无监督神经机器翻译
2021-04-29 09:29张桂平黎天宇
中文信息学报 2021年3期
徐 佳,叶 娜,张桂平,黎天宇
(沈阳航空航天大学 人机智能研究中心,辽宁 沈阳 110136)
0 引言
最近,神经机器翻译(neural machine translation,NMT)的方法在机器翻译领域中脱颖而出,取得了极大的进展[1-3]。神经机器翻译通常由两个子神经网络组成,编码器网络将源语言句子编码成上下文向量,再由解码器网络将编码器网络编码的上下文向量迭代解码成相同意思的目标语言句子。通常在有监督的环境下,需要使用大量的双语平行句子对训练模型。然而绝大多数语言对几乎没有平行数据。无监督神经机器翻译(unsupervised neural machine translation,UNMT)成功打破了这种限制,仅仅使用两种语言的单语语料进行训练便可以完成常规的机器翻译任务。无监督神经机器翻译是基于神经机器翻译的,并结合去噪自动编码器和反向翻译[4-5]训练双重模型初始化与跨语言嵌入[6],达到机器翻译的目标。但是在无监督神经机器翻译模型训练过程中,反向翻译会产生大量的伪平行数据,而这些伪平行数据的质量在反向翻译训练中就变得至关重要。因此,在训练反向翻译的过程中控制伪平行数据质量是提升无监督神经机器翻译质量的一个关键。
本文提出了一种利用质量估计(quality estimation,QE)技术的方法,在无监督神经机器翻译训练反向翻译时设置一个固定阈值筛选伪平行数据,有效地提升了无监督神经机器翻译的效果。本文研究基于生成对抗网络[7],由反向翻译和语言建模分别作为生成器和鉴别器。通过使用质量估计评估并筛选反向翻译训练过程中生成的评分(HTER)比较高的伪平行数据。该方法在控制伪平行数据质量的同时,丰富了生成器的生成样本,让鉴别器收敛得更慢,使得生成对抗网络训练得更加充分,从而提升了无监督神经机器翻译的翻译效果。
本文在WMT 2019共享任务提供的德语—英语和捷克语—英语的单语语料上进行了无监督神经机器翻译的实验,其中质量估计模型采用预测器—估计器结构是在WMT 2019共享任务提供的德语—英语和捷克语—英语质量估计语料上训练得到的。首先需要训练预测器模型,然后再使用预测器模型来训练估计器模型,最后通过该模型的预测器对反向翻译训练过程中生成的所有伪平行数据进行评分和筛选。实验结果表明,利用质量估计的无监督神经机器翻译模型虽然训练速度有些下降,但是在WMT 2019德语—英语和捷克语—英语新闻单语语料上翻译性能分别提升了0.79和0.55个BLEU值。
本文组织结构安排如下:第1节论述了本研究的相关工作;第2节和第3节分别介绍了无监督神经机器翻译和质量估计原理;第4节说明了利用质量估计改进无监督NMT的方法;第5节给出了实验结果及其分析;最后部分为总结与展望。
1 相关工作
目前,学界已经提出了几种不直接使用双语平行语料训练NMT模型的方法。Leng等人[8]使用的方法是训练从源语言翻译到枢轴语言,再将枢轴语言翻译到目标语言的独立翻译。这种方法虽然巧妙,但却对枢轴语言的依赖性很高,同时无形之中引入了第三种语言,甚至是第四种语言互译的误差,而且通过枢轴语言引入的误差无法消除。
由于跨语言嵌入的成功,Lample等人和Artetxe等人同时提出了基于预训练跨语言嵌入训练无监督神经机器翻译的方法。该方法仅仅使用了两种语言的单语语料独立地训练两种语言的嵌入,并学习线性变换[9]和对抗训练[6]将它们映射到共享空间中。由此产生的跨语言嵌入用于初始化两种语言的共享编码器,整个系统使用去噪自动编码器、反向翻译和对抗训练[10]组合训练。Yang等人[11]进一步改进了这种方法,他们使用两种语言特定的编码器,只共享其参数的一个子集,并结合本地和全局生成对抗网络训练无监督神经机器翻译。但这些方法训练模型时并未考虑到反向翻译生成伪平行数据的质量,导致模型训练不够充分。
现阶段,反向翻译技术经常被应用于无监督神经机器翻译中。Wang等人[12]使用质量估计的方法,即使用OpenKiwi[13]筛选反向翻译生成的伪平行数据与真实的平行数据结合的方法训练NMT,提升了机器翻译的性能。Li等人[14]利用反向翻译使用单语语料扩充平行数据,采用新的数据增强方法在保持模型小的前提下进一步提高NMT对噪声的鲁棒性和翻译效果。Miguel等人[15]采用合成数据生成的方案,在NMT模型的交叉熵优化范围内重新构造了反向翻译,阐明了其基本的数学假设和启发式用法之外的近似值。利用公式指出了基于采样的方法的基本问题,并提出通过禁用目标到源模型的标签平滑和从受限搜索空间采样来解决神经机器翻译数据增强问题。但Wang等人、Li等人和Miguel等人的方法均使用了有监督的方法来解决数据不足和控制伪平行数据质量的问题,并没有解决不使用双语平行语料训练机器翻译任务的问题。
本文的方法基于Lample等人[5]的无监督NMT的方法,仅仅使用两种单语语料利用质量估计筛选伪平型数据训练反向翻译的同时,使用更少的数据训练并提升了无监督神经机器翻译的性能。
2 无监督神经机器翻译模型
本文基于Lample等人[5]的研究,提出的模型由编码器和解码器组成,其整体架构如图1所示。

图1 无监督神经机器翻译模型整体架构
初始化虽然之前大部分的研究依赖于双语词典,但是使用Conneau等人(1)使用两种不相关语言的单语语料初始化一个跨语言嵌入文本。提出的预训练跨语言嵌入的方法更加简单、有效。首先,对于两种语言的语料做字节对编码[16](byte pair encoder,BPE)处理。该处理减少了词表大小,并消除了输出译文中出现的未知单词。其次,通过联合处理两种语言的语料,应用联合BPE的一部分共享单词消除了双语词典的需要。最后,在相同的两种语言联合语料库上学习标记嵌入[17],使用这些嵌入来初始化编码器和解码器中的查找表。
语言建模语言建模通过去噪自动编码器实现,分别针对源语言和目标语言进行优化并更新神经网络参数,使得反向翻译生成的伪平行数据越来越好。最小化目标函数如式(1)所示。
(1)
其中,C是一个部分单词被删除的噪声模型。Ps→s和Pt→t分别由源端和目标端工作的编码器和解码器组合而成。
反向翻译在反向翻译过程中,通过使用普通的编码器和解码器实现,最小化目标函数如式(2)所示。
(2)
其中,u*(y)表示从y∈T推导出来的源语言句子,u*(y)=argmaxPt→s(u|y)。同样,v*(x)表示从x∈S推导出来的目标语言句子,v*(x)=argmaxPs→t(v|x)。将(u*(y),y)和(x,v*(x))组成自动生成的伪平行句子对。注意,最小化Lback这个目标函数时并没有产生数据,在随机梯度下降的每次迭代中,最小化目标函数式(1)中的Llm和式(2)中的Lback之和。
语言建模用于优化反向翻译生成的句子,反向翻译用于翻译模型。而Lample等人忽略了用于翻译模型训练的伪平行数据的质量以及生成对抗网络训练样本的丰富性,因此我们引入了质量估计模型。
3 质量估计模型
本文使用了质量估计模型——OpenKiwi[13]。OpenKiwi是一个开源的质量估计框架,其实现了过去几年中比较流行的四个系统: QUETCH[18],NUQE[19],预测器—估计器[20]和线性堆叠系统[19]。本文的研究基于预测器—估计器模型,下面将介绍OpenKiwi的预测器—估计器模型。图2为OpenKiwi的预测器—估计器模型整体架构。

图2 OpenKiwi的预测器—估计器模型整体架构
OpenKiwi遵循Kim等人提出的架构,包含两个部分: 预测器和估计器。预测器用于在给定目标语言句子的源语言句子左、右上下文的情况下,预测出目标语言句子的每一个词。估计器用于接收由预测器产生的特征,并将每个词分类为OK/BAD。预测器使用双向LSTM编码源语言,两个单向LSTM按从左到右(LSTM-L2R)和从右到左(LSTM-R2L)的顺序处理目标语言。对于每个目标单词ti,其左上下文和右上下文的表示被连接起来,并在最终的softmax层之前用作对注意模块的查询。它由WMT共享任务组织者提供,作为附加数据的大型并行语料库进行训练。估计器将特征序列作为输入: 对于每个目标单词ti,在softmax之前的最后一层(在处理ti之前),以及LSTM-L2R和LSTM-R2L的第i隐藏状态的串联(在处理ti之后)。此外,使用一个多任务架构来训练这个系统,以预测句子级的HTER值。总的来说,该系统能够预测句子级分数和所有单词级标签(对于机器翻译单词、间隙和源单词),源单词标签是通过反向训练预测器产生的。
本文主要使用了OpenKiwi的神经质量估计模型(即预测器—估计器模型)对反向翻译生成的伪平行数据进行评估,再通过该模型给出的句子级HTER值对伪平行数据进行筛选。
4 融合质量估计的无监督NMT模型
为解决神经机器翻译需要大量双语平行语料的问题,无监督神经机器翻译采用反向翻译的方法训练翻译模型。反向翻译的方法一直是在无监督神经机器翻译领域广泛使用的方法,通常在最小化损失函数时,不通过产生数据的模型进行反向传播,这样做是为了训练反向翻译的简单性[5],但是却忽略了神经机器翻译训练使用数据质量的重要性。因此,本文提出了利用质量估计来控制反向翻译训练过程中产生的伪平行数据质量的方法,对应的无监督NMT单次训练流程如图3所示。
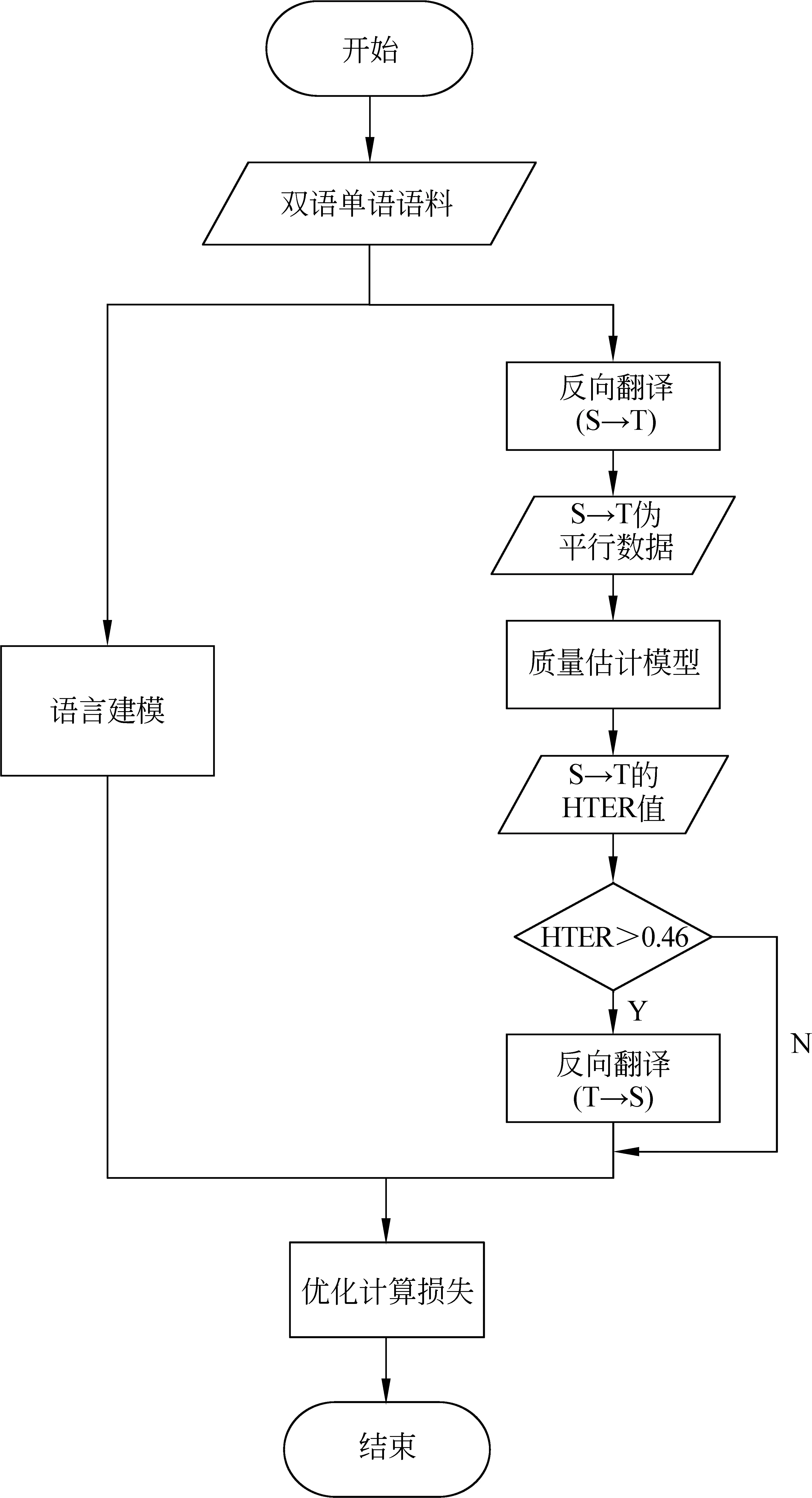
图3 无监督NMT单次训练流程图S表示源语言句子,T表示目标语言句子,我们人为地将反向翻译分为两步
4.1 质量估计模型训练
本文选择并训练了质量估计模型OpenKiwi。为了训练OpenKiwi质量估计模型,我们选择了使用WMT 2019共享任务提供的质量估计测试集、验证集和训练集。为简化系统加载模型的复杂性,我们仅训练了英语—德语和英语—捷克语的质量估计模型,这样避免了反向翻译筛选伪平行数据时由于使用不同的模型而引入误差的问题。最终,本文分别使用皮尔逊系数为58.51和54.91的英语—德语和英语—捷克语的句子级质量估计模型融入到反向翻译中。
4.2 融合质量估计的反向翻译
反向翻译的方法(又称作往返翻译),主要是利用编码器和解码器在两种语言单语语料上分别训练独立的翻译模型。因此,无监督神经机器翻译在训练过程中会通过两个方向轮流迭代训练同一个编码器和解码器,最后将该编码器和解码器应用到常规机器翻译中。
常规反向翻译的方法是一个将源语言翻译到目标语言再翻译回源语言的一个过程(图4),假设源语言句子为S,目标语言句子为T,则常规反向翻译即S→T→S。本文所使用的方法需要在反向翻译过程中使用QE模型,首先,将常规反向翻译过程分为两个阶段: ①将源语言句子翻译成目标语言句子,即S→T;②将①翻译出的目标语言句子翻译回源语言句子,即T→S。然后,在①阶段后加入QE模型对伪平行句子对进行质量评估,评估结果为QE模型给出的HTER值,再将QE模型给出的HTER值与阈值进行比较后筛选数据,在第4.3.2节中会介绍阈值的选择方法。最后将满足HTER值大于阈值的伪平行数据继续执行②阶段并计算损失,优化后更新神经网络参数,结束当前反向翻译过程。

图4 常规反向翻译示意图
以德语—英语为例,下文德语使用De表示,英语使用En表示。在一次训练中,反向翻译可能会先从德语语料中选取一个批次的德语训练De→En→De,随后再从英语语料中选取一个批次的英语训练En→De→En,最后反复迭代并不断优化模型。因此我们在一次训练中既要评估De→En→De伪平行数据也要评估En→De→En伪平行数据。我们选择在反向翻译的①阶段进行评估(即De→En和En→De),而在反向翻译的②阶段并没有进行评估。其原因在于反向翻译也是神经网络训练机器翻译的过程,②阶段翻译的输入数据是由①阶段翻译得到的数据,若①阶段翻译所得数据HTER值不高,则②阶段翻译所得数据HTER值必然不高。并且,在一次反向翻译迭代中进行两次质量评估耗时更多,因此本文选择在反向翻译的①阶段进行评估。图5即为利用质量估计的反向翻译示意图。

图5 利用质量估计的反向翻译示意图
4.3 人工翻译错误率与阈值选择
4.3.1 人工翻译错误率
质量估计模型的估计器最终评估结果为人工翻译后编辑率(human translation error rate,HTER)。HTER[21]值是人工修正译文所需要编辑的百分比。HTER值的取值范围在0~1之间,越接近0代表翻译得越好,不需要人工编辑,越接近1代表翻译得越不好,需要多次人工编辑。
4.3.2 阈值选择及使用
句子级的质量估计模型,将翻译出来的平行句子对放入到该质量估计模型,再由质量估计模型预测出HTER值供我们进行筛选。最后再将该批次评估得到的数据按照式(3)计算,作为该批次伪平行数据的评估结果。注意,我们为了提升评估效率,采用了将一个批次的伪平行数据放入到模型中预测的方式。
Hbatch=(H1+,…,+Hi+,…,+Hn)/n
(3)
其中,n为一个批次的句子的数量,Hi为一个批次中其中一对伪平行数据的HTER值。筛选伪平行数据的阈值则是通过多次实验,取生成句子对的HTER最高值(Hmax)与最低值(Hmin)的平均值,如式(4)所示。
β=(Hmax+Hmin)/2
(4)
其中,β为筛选平行数据的阈值(最终,阈值选择为0.46和0.49)。最后,通过固定阈值筛选反向翻译所产生的伪平行数据,再使用满足该阈值的伪平行数据训练并更新神经网络参数。
对于阈值的设置,由于反向翻译训练过程中生成伪平行数据的质量是越来越好的,并且阈值和HTER值均不是固定值,若使用动态阈值的方法无法控制伪平行数据的留取比例,无法对实验结果进行分析,因此我们并没有选择使用设置动态阈值的方法,而是采取了设置固定阈值的方法来控制伪平行数据的质量。
5 实验与结果
本节首先描述我们使用的数据集和实验,然后将本文使用的方法与Lample等人的方法对比,最后针对本文的实验结果进行分析。
5.1 数据与预处理
OpenKiwi使用了WMT 2019共享任务提供的英语—德语和捷克语—英语语料。其中包括随机抽取并打乱顺序的500万句子对作为训练集,以及验证集各1 000句。表1为OpenKiwi所使用的De-En和Cs-En数据信息。

表1 OpenKiwi所使用的数据集信息 (单位: 句)
对于无监督NMT,我们选取与Lample等人和Artetxe等人相同的数据集(WMT 2019新闻语料)。首先分别将单语数据(WMT 2019提供的各年份新闻单语语料)混合在一起,再分别将数据打乱顺序,并从中随机抽取1 000万句德语和英语的单语语料。测试集为newstest2016共2 999句,验证集为newsdev2015共2 169句。表2为无监督NMT所使用的De-En数据信息。

表2 无监督NMT所使用的De-En数据信息 (单位: 句)
为了验证方法的有效性,我们还选择了由WMT 2019共享任务提供的捷克语单语语料。与前文提到的方式相同,随机抽取1 000万句捷克语单语句子。捷克语测试集和验证集分别为newstest2014共3 003句和newstest2015共2 656句。英文使用的语料与上文所述相同。表3给出无监督NMT所使用的Cs-En数据信息。

表3 无监督NMT所使用的Cs-En数据信息 (单位: 句)
本文所述实验数据均使用Moses[22]提供的tokenizer.perl脚本处理。
5.2 初始化
无监督NMT的方法需要使用跨语言的BPE[23]嵌入(2)https://github.com/glample/fastBPE(来初始化共享查找表)。我们使用fastText[24]来生成嵌入,其嵌入维度为512,上下文窗口大小为5,负样本数为10。将fastText(3)https://github.com/facebookresearch/fastText应用于源语言语料和目标语言语料的联合语料,实现了跨语言的BPE嵌入。
5.3 质量估计模型训练
本文首先使用第5.1节提到的500万训练数据训练预测器,最终En-De和En-Cs预测器训练结果的BLEU值分别为44.77和43.75。再使用质量估计语料训练估计器,最终En-De和En-Cs估计器训练结果的皮尔逊系数分别为58.51和54.91。表4为本文所述实验最终使用的OpenKiwi质量估计模型的测试结果。

表4 质量估计模型的测试结果
5.4 模型超参数和评估
对于无监督NMT模型,本文采用Transformer架构,在编码器和解码器中都使用了4层(其中3层编码器和解码器参数共享)、Multi-head Attention参数为8。在编码器和解码器之间、源语言和目标语言之间共享所有查找表。嵌入和隐藏层的维度设置为512。使用Adam优化方法,学习率为10-4,β1=0.5,Batch Size为32,dropout为0.1。表5为本文采用的Transformer架构参数设置。

表5 Transformer架构参数设置
5.5 模型选择
对于模型选择,本文在模型连续10次没有改进的情况下停止对于模型的训练。BLEU[25]被用作评估指标。对于德语—英语和捷克语—英语,我们使用由Moses(4)http://www.statmt.org/moses/提供的multi-belu.perl脚本评估翻译性能。
我们考虑了两个模型选择的过程: 基于Lample等人的“反向”翻译(source→target→source和target→source→target)的BLEU值的无监督准则,以及使用包含100个平行语句的小验证集的交叉验证。在实验中发现,使用Transformer模型时,无监督准则与测试指标高度相关。因此,我们使用100个平行语句的小型验证集选择的无监督准则最佳的Transformer模型。
5.6 实验结果与分析
通过使用第4.3.2节所述的方法计算,在本文所述实验中所训练的质量估计模型对伪平行数据评估得出,其中英语—德语(英语—捷克语)HTER最大值为0.61(0.65),最小值为0.31(0.33),因此将反向翻译训练时德语—英语(和捷克语—英语)所需阈值分别设置为0.46(和0.49)。与此同时,我们还针对该阈值进行放大和缩小,分别进行对比实验。放大后的阈值不能大于0.61且缩小后的阈值不能小于0.31,于是我们选择0.56和0.36分别进行实验。表6为德语—英语Baseline模型与UNMT+QE模型的数据筛选比结果(5)由于训练过程中反向翻译的伪平行数据质量会改变,因此此处统计比率为第1个epoch(留下数据/总数据)。以及其第1个epoch评测的BLEU值对比。由表6可见,本文所述方法成功地利用质量估计模型控制了无监督神经机器翻译训练反向翻译时所生成的伪平行数据质量。
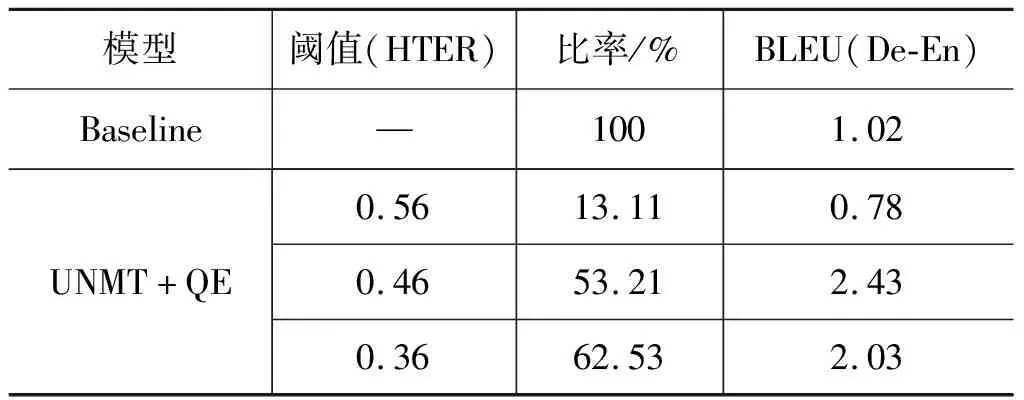
表6 德语—英语Baseline模型与UMT+QE模型的数据筛选比 (单位: word/s)
与Baseline模型相比,我们的模型丰富了由反向翻译的生成样本,使鉴别器收敛得更慢,使得生成对抗网络训练得更加充分,从而提升无监督神经机器的翻译效果。由第4.3.2节所述方法得到的阈值为0.46(0.49)。由表6可见,QE模型在筛选句子时减少了句子的数量,同时提高了模型训练的质量(BLEU值)。当阈值为0.36时UNMT+QE模型的数据筛选比相对阈值为0.46时高9.32%,但BLEU值却比阈值为0.46时要低;当阈值为0.56时,模型筛选去掉的数据数量比较多,不利于模型训练。实验结果表明,当筛选掉的数据与保留的数据比接近1∶1时模型取得的BLEU值比较高,实验中既不能筛选掉过多的数据,也不能保留过多的数据,因此本文在德语—英语和英语—捷克语实验时阈值选择了第4.3.2节所述方法,分别设置为0.46和0.49。
表7为Baseline模型与本文模型结果数据对比。本文所提出的模型比基线系统在英语—德语和捷克语—英语翻译上BLEU值分别提升了0.79和0.55。

表7 WMT 2019 De-En和Cs-En测试结果
图6和图7分别为德语—英语和捷克语—英语训练中Baseline模型与本文模型(阈值分别为0.46和0.49)的每个epoch结果对比。由此可见,本文模型在训练绝大多数的epoch时均比基线模型高出0.25~1.25个BLEU值。我们认为,性能提高的原因是质量估计模型控制了产生的伪平行语料的质量(即保留了质量相对较差的译文),使鉴别器计算得到的损失值较大,因此收敛更慢,从而使得生成对抗网络训练得更加充分。
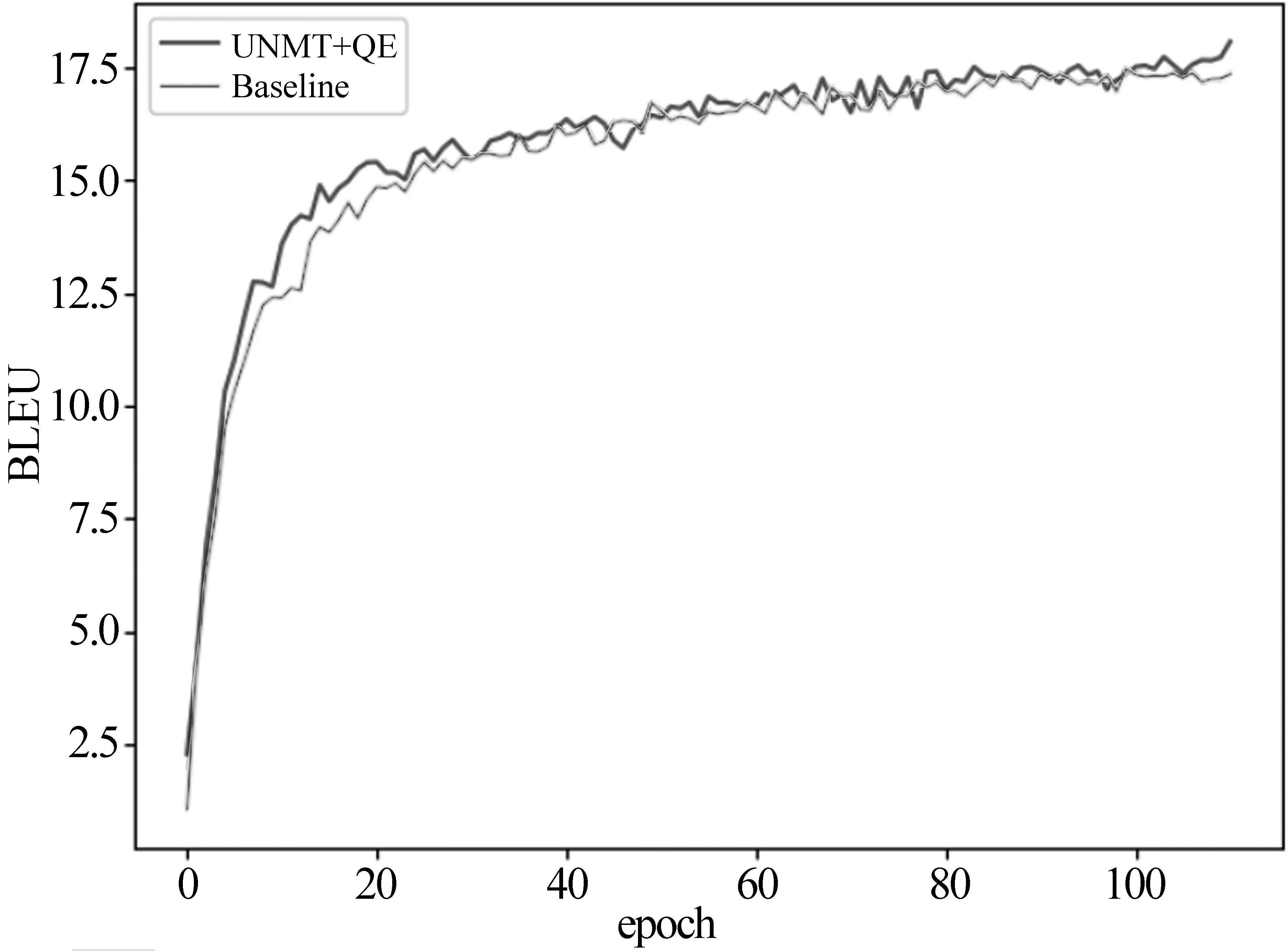
图6 德语—英语训练中Baseline模型与本文模型的每个epoch结果对比
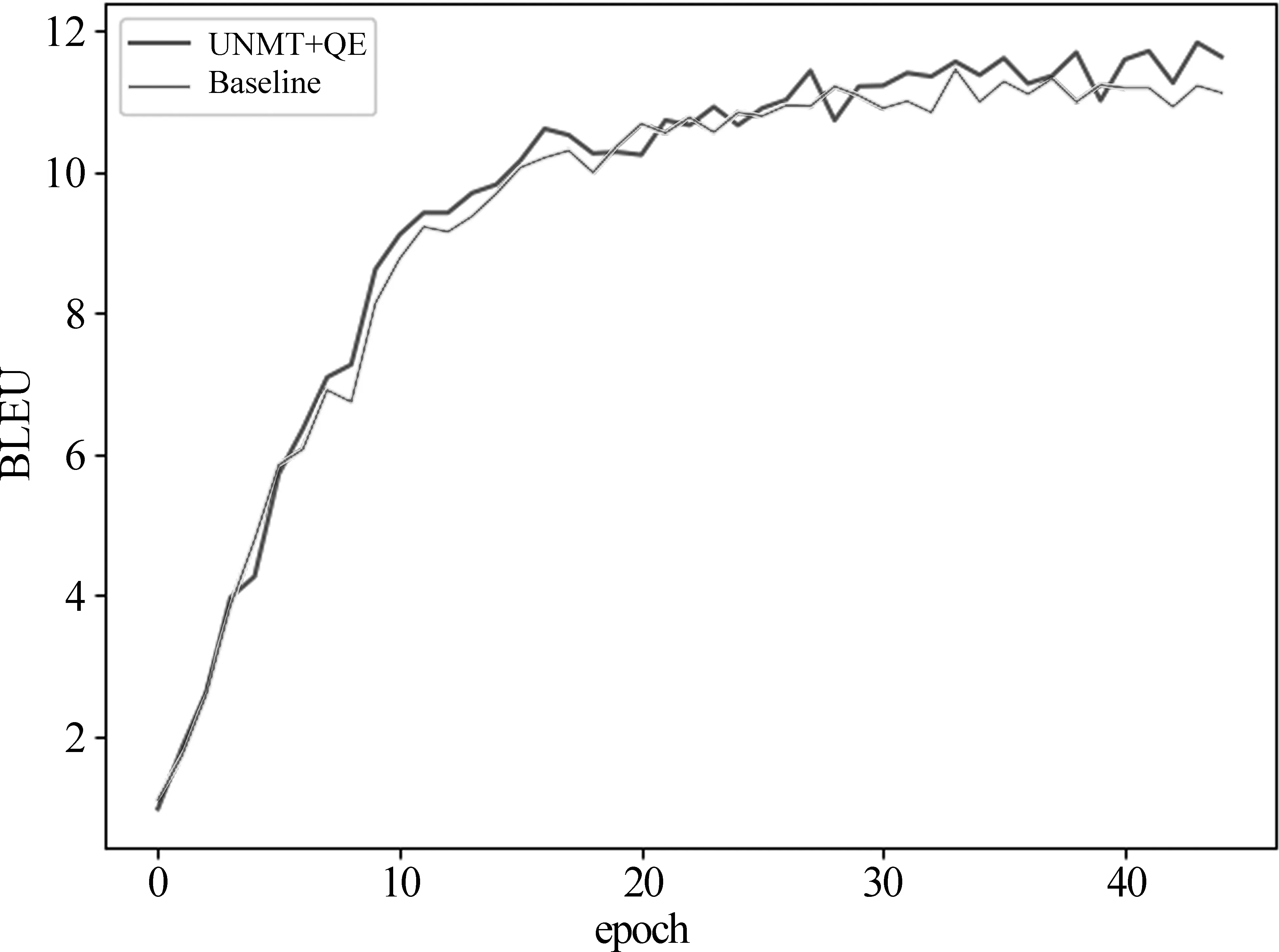
图7 捷克语—英语训练中Baseline模型与本分模型的每个epoch对比
由于每次在训练反向翻译时,在①阶段需要将每个Batch Size生成的伪平行数据向量转换为伪平行句子对,因此在系统运行的临时存储空间上平均增加230MB左右,增加了模型的空间复杂度。与此同时,需要对每个Batch Size生成的伪平行句子对评分,增加了模型对伪平行数据评估的时间复杂度。
利用质量估计的无监督神经机器翻译模型,可以有效控制伪平行数据的质量。虽然在训练时不可避免地增加了时间复杂度和空间复杂度,但成功地为生成对抗网络提供了更多的训练样本,让生成对抗网络训练得更充分,从而使无监督神经机器的翻译效果得到有效提升。
6 总结与展望
无监督神经机器翻译旨在使用更少的单语语料解决机器翻译的双语平行语料不足和语种扩充等问题。本文提出的方法解决了现有无监督神经机器翻译在训练反向翻译时无法控制伪平行数据质量的问题。我们将常规的反向翻译分成两个阶段,在①阶段利用质量估计对其生成的伪平行数据进行评分(HTER),再通过该评分与我们设置的固定阈值比较,筛选出比阈值高的伪平行数据完成反向翻译的②阶段。通过实验发现,我们的方法基于生成对抗网络和QE,在控制伪平行数据质量的同时丰富了由反向翻译作为生成器的生成样本,使由语言建模作为鉴别收敛得更慢,使得生成对抗网络训练更加充分,从而提升无监督神经机器翻译的翻译效果。本实验在WMT 2019共享任务提供的英语-德语和捷克语-英语单语语料上与基线相比,BLEU值分别提升了0.79和0.55。
本文提出的方法有一定的效果,但是由于使用了另一个比较大的模型导致模型整体训练速度有所降低,尽管如此,本模型同时也在使用少量的数据的前提下提升了无监督神经机器翻译的效果。未来的研究将主要针对使用更少的单语数据,更加快速地训练完成无监督神经机器翻译,使得其训练效果和常规神经机器翻译同步,甚至取得更好的效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
思维与智慧·上半月(2022年4期)2022-04-08
小哥白尼(神奇星球)(2021年4期)2021-07-22
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
河北遥感(2017年2期)2017-08-07
海外华文教育(2016年1期)2017-01-20
衡阳师范学院学报(2016年3期)2016-07-10
汽车观察(2016年3期)2016-02-28
当代教育理论与实践(2015年9期)2015-12-16
