
一种具有隐蔽色特征物体的图像分类方法研究
2021-04-29 06:27李佳君李宇海高裴裴
红外技术 2021年4期
刘 峰,李佳君,李宇海,高裴裴
(1.天津大学 精密测试技术及仪器国家重点实验室,天津 300072;2.中国电子科技集团公司第五十三研究所,天津 300300;3.南开大学 计算机学院,天津 300071)
0 引言
计算机视觉分类的场景中出现颜色形状等特征相似的不同类别物体时会对图像分类的精度造成极大的影响,所以提高在此类场景下的图像分类精度在视觉探测领域具有重要的理论和应用价值。由于光谱信息是由物体的内在性质所决定的,所以不同物质的光谱信息必定存在差异,利用不同物体不同谱段的光谱差异就可以挖掘出物体的隐蔽特征。深度学习作为挖掘和分析高光谱数据的有效手段,通过适当改进网络结构可以在高光谱图像的分类上取得比传统分类算法更好的效果。Song 等人[1]通过PCA(principal component analysis)降维和训练残差网络来实现高光谱图像分类,罗建华等[2]提出了PCA 数据降维和深度卷积神经网络结合的分类方法,虽然这两种方法都取得了不错的效果,但是仅利用了高光谱数据的光谱特征而忽略了其空间特征;Chen 等人[3]通过空谱联合以及深度信念网络的方式对高光谱数据进行分类,但是在高光谱数据处理阶段没有考虑谱段的降维,在数据谱段较多时会极大的增加网络运行的负载;Zhao 等人[4]利用PCA 进行数据降维并提出了一种空谱结合的MCNN(multiscale convolutional neural network)分类网络,张倩等人[5]利用PCA和改进的自编码器进行了高光谱数据的分类,上述方法在University of Pavia 遥感数据集上进行实验,但是PCA是从数据方差的角度进行数据的降维,舍弃了光谱特征的局部线性部分并且没有解决在自然环境小样本数据集条件下的分类问题。
高光谱图像容易受光照强度、采集视角、色彩等因素的影响,而胶囊网络作为一种较为独特的深度学习方法,其构造的胶囊结构善于捕捉图像中物体的姿态、纹理、色调等特征,将其应用到图像分类可以减轻光照强度、姿态、色彩等因素的影响从而提取到更丰富的谱段特征[6]。另外,高光谱数据在空间上的相邻像素可能属于相同的类,因此空间特征在高光谱图像分类中越来越重要,做好高光谱空谱联合的特征工程对最终的分类精度影响极大。基于上述特点,本文提出了一种具有隐蔽色特征物体的图像分类方法,通过结合邻域像素实现空谱联合特征的构造,然后将所有谱段进行均分并分别对每个谱段区间进行基于局部线性嵌入算法的特征降维,该算法形成了保留更多局部线性特征的空谱联合构造样本,最后在此基础上构建了小样本条件下的主动学习胶囊网络分类器,针对具有隐蔽色特征物体的场景在自建高光谱数据集上取得了优于其他分类算法的性能。
1 隐蔽色物体的高光谱数据
高光谱成像技术是一种基于方位和光谱三维信息探测的光电探测技术,利用高光谱成像技术针对具有多个隐蔽特征物体的场景进行数据采集,在获取观测对象二维空间信息的同时对每个空间像素色散,形成几十到几百个波段的连续光谱,从而使每一个像素拥有上百维的数据。目前,成像光谱仪的探测波长范围一般分为400~1000 nm、900~1700 nm、1100~2500 nm、3000~15000 nm。本文的高光谱数据均是在波长范围384.612~1005.620 nm 下进行采集,共有853个谱段,光谱分辨率达到了0.7 nm,空间像素大小为635×1004。图1展示了在不同的波段下的图像数据,可以看出在不同波长的采样下,不同物体的反射强度是具有明显区别的。特别的,在采集场景中都存在几个隐蔽色人造物体,但由于其与周围颜色相似,几乎看不到其位置分布在哪里。图2展示了高光谱数据场景中不同物体的光谱曲线图,拍摄场景主要分为隐蔽物-网、隐蔽物-车、草地、树木、阴影和天空等6类。

图1 不同波段下的高光谱图像(单位:nm)Fig.1 Hyperspectral images in different wavebands(Unit:nm)

图2 场景中不同物体的光谱曲线Fig.2 Spectral curves of different objects in the scene
2 分类过程及算法描述
2.1 胶囊网络
Hinton 认为卷积神经网络没有考虑到简单对象和复杂对象之间存在的重要空间层次,弱化了图像特征的表达能力。为了解决卷积神经网络的这一固有缺点,Hinton 于2017年提出了胶囊网络[7],其模型结构如图3所示。
首先,胶囊网络会对输入的图像数据进行卷积操作并进行ReLU激活,从而得到ReLU Conv层;然后将ReLU Conv 作为下一层的输入,再次进行卷积操作并将其调整成适用于胶囊网络模型的向量神经元层而不是卷积神经网络中的标量神经元层,该卷积层被定义为主胶囊层(primary capsule)。不同于卷积神经网络中的标量神经元,胶囊网络中的每一个胶囊是由一个向量表示的,该向量中的每个值即代表了当前需要分类物体的一个特征。主胶囊层的每个胶囊通过动态路由算法的正向传播得到特征更加紧凑的胶囊,该胶囊层被定义为数字胶囊层(digit capsule),其数字胶囊的总个数便为分类任务中的物体类别总数,通过计算数字胶囊层中各个胶囊的模值||L||2可以得到输入样本属于各个类别的概率,从而以最大模值胶囊所代表的类别作为样本的分类输出结果。

图3 胶囊网络模型结构Fig.3 Architecture of capsule network
2.2 主动学习
影响深度学习分类精度的因素不仅包括合适的分类网络选择,还包括训练分类器所需样本的质量。在具有颜色相似特征物体的高光谱图像场景下,胶囊网络训练器面临着标注样本稀缺、人工标注成本高昂的问题[8]。为了提高标注样本的数量和质量,本文采用了主动学习的策略。假设总体样本分为已标注样本库(训练样本库)T和未标注样本库U,主动学习会以迭代方式从U中选择最具有代表性、对训练器最有益的样本经由专家标注扩充到T中,更新T、U 后再次重复,最终提高T的数量和质量,其更新和扩充T的过程为:①从总体样本库中随机选取少量的样本进行人工标注得到初始T,T中应当包含所有6类物体;②使用初始T 训练得到初始化的胶囊网络分类器C;③利用查询函数F对U 进行采样得到最有价值的未标注样本;④使用初始化胶囊网络分类器C 对采样的样本进行分类;⑤将明显错分的样本认为是对C 最有益的样本,交由专家E 标注后加入T 并更新T和U,再次进行模型训练优化分类器C;⑥重复③~⑤步骤,不断更新样本库结构,最终得到分类性能最好的高光谱胶囊网络分类器C。其整个工作流程如图4所示。
查询函数直接决定了主动学习对模型训练带来的收益大小,其设计常依从两个准则:不确定性准则[9]和差异性准则[10]。不确定性准则可以从信息熵的概念来进行解读,那就是样本包含的信息量越丰富信息熵就越大,就代表着较大的不确定性。查询函数应该想办法来避免数据冗余、保证每次新加入的样本与原有训练集中样本的差异性。

图4 主动学习工作流程Fig.4 Active learning process
为了综合考虑训练样本库中各个样本的不确定性差异和样本总体的均值差异,本文提出了一种结合信息熵和最大均值差异的查询函数:

式中:α和β分别为信息熵和最大均值差异的比例参数,本文均设置为0.5;s为通过限定条件筛选出的待扩充样本集合,l是需要利用主动学习补充样本的目标类别;L是所有的目标类别;sl是未标注样本集中类别l的n维高光谱特征向量;是已标注样本集中类别l的n维平均高光谱特征向量,f(·)是把特征从原样本空间映射到希尔伯特空间的核函数。
通过抽取高光谱一个谱段所形成的光谱反射图,利用二维图像标注工具对其中的隐蔽物-车、隐蔽物-网、草、树、阴影和天空6类物体进行方框标注,标注结果如图5所示。

图5 二维图像标注Fig.5 2-d image annotation
可以看出由于场景中各类物体分布不均、形状不规则,初始的人工标注比较难以覆盖目标类别的所有部分且不一定是该类别最具代表性的样本像素,另外特定类别具有隐蔽性特征不易分辨,为标注工作带来困难。通过(1)式的查询函数可以在限定条件下寻找未标注类别的像素集合,并通过信息熵和最大均值差异得到该集合下最具代表性的待构造像素样本,从而扩大原本的样本数量。基于改进的结合信息熵和最大均值差异查询函数的主动学习方法,相比于单一考虑不确定性或者差异性的主动学习方法,对代表性样本的提取效率更高,从而使目标分类精度得到提升。
2.3 空谱联合及改进LLE(local linear embedding)算法的特征工程
2.3.1 空谱联合的特征构造
现有的高光谱图像分类方法多注意到空间信息的利用,但却很少考虑地物在空间分布上具有连续性的特点,基于此,在特征构造阶段应当考虑光谱图像在空间邻域的有效特征[11]。高光谱空间图像中的每一个像素可以向谱段延伸,即每一个谱段内相同位置的像素都可以用来表达同一个物体,本文所使用的高光谱数据具有853个谱段,即每一个二维空间中的像素都对应一个853×1的光谱特征向量,对该向量进行光谱特征与空间特征结合的主要思想就是选择一定大小空间(m×m)邻域的样本均值作为空域特征并将其融合到谱段之中。假设空间中某一点(i,j)的谱特征为f1(x,y),则基于空间邻域Q计算得到的空域特征为:

本文由于谱段较多,为了降低空域的计算量,选择邻域大小为3×3且只融合物理距离最近的4个像素的空域特征,然后将融合空域特征的光谱数据拼接到采样像素自身光谱数据之后形成一个1706×1的构造向量。如图6所示为融合空谱特征示意图,圆点是采样像素点,其4个邻域像素由三角点表示,通过卷积可以得到样本像素的邻域平均值,该平均值用菱形点表达,最终通过将采样数据和融合空域特征的数据拼接得到空谱联合构造的样本。
2.3.2 波段均分的LLE 特征降维
由于高光谱数据在采集时谱域和空域一样也具有连续性的特点,而传统的PCA、LDA(linear discriminant analysis)等关注样本方差的降维方法却并没有将这一特点考虑进去,而是从谱段的成分占比和分布情况进行降维,相比之下,局部线性嵌入(locally linear embedding,简称LLE)算法关注于降维时保持样本局部的线性特征,在较窄范围的谱段进行降维后可以出色的保证特征的连续性,很适合对谱段分辨率较高的高光谱数据进行降维。LLE算法假设数据在较小的局部区域内是呈线性关系的,也就是说任何一个数据可以由它邻域中的其他数据线性表示,比如有一个样本pi,它可以用距离其最近的其他3个样本pj、pk、pl线性表示:

式中:wij、wik、wil为权重系数;pj、pk、pl为样本。

图6 空谱特征融合Fig.6 Merging spatial-spectral features
利用LLE 进行特征降维后,样本pi在低维空间对应的投影pi′和pj、pk、pl对应的投影pj′、pk′、pl′也尽量保持同样的线性关系:

式中:wij、wik、wil为权重系数;pj′、pk′、pl′为样本。
也就是说,投影前后线性关系的权重系数wij、wik、wil是尽量不变或者最小改变的。由于样本总是由距离最近的其他样本所表示,导致该算法所保持的线性关系仅仅局限在采样样本的附近,离采样样本欧氏距离较远的其他样本将不会严格保持这一线性关系[12]。为了尽量克服LLE的这一缺陷,本文通过将高光谱波段进行均分,将总长为1706的构造波段分为19个区间,前18个区间均具有90个波段,最后一个区间具有86个波段,通过在各个较窄波段区间的降维维持了LLE对线性关系的敏感度,改进的算法也保留了LLE 对高光谱降维的独特优势。本文最终通过波段均分的LLE降维方法将前18个区间从90维降到25维,最后一个区间从86维降到50维,总谱段从1706维降到500维。具体的算法流程如下:
输入:
近邻数k,降到的维数
输出:
低维样本集:

1)对于xm,以欧式距离||L||2在Di中检索出其最近的k个近邻{xm1,xm2,…,xmk},Q(i)表示xm的k个近邻样本集合;
2)对Di的每个样本xm,求出局部协方差矩阵Zi及其对应的权重系数向量Wi:

式中:1k为k维全1 向量。
3)假设Di在低维的di维投影为{y1,y2,y3},则对其加一个约束条件:

4)由权重系数向量Wi组成权重系数矩阵W,计算矩阵:

5)计算矩阵M的前di+1个特征值及其di+1个特征值对应的特征向量V:

6)取第二个特征向量到第di+1个特征向量组成的矩阵即为输出的低维样本集矩阵:
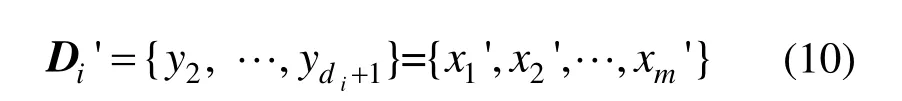
7)将所有输出的低维样本集拼接得到D′:

图7展示了类别为隐蔽物-车的采样像素的样本构造和降维过程,首先获取采样点及其邻域的光谱信息,然后通过卷积拼接得到预处理的特征向量,最后经过波段均分LLE(band averaging LLE)降维得到胶囊网络分类器的输入样本向量。

图7 样本构造过程Fig.7 Sample construction process
2.4 高光谱数据的胶囊分类网络
本文所提出的分类方法的主要工作流程包括:①对输入的高光谱图像数据进行空谱联合的特征构造;②利用波段均分的局部线性嵌入算法对构造特征进行降维并得到胶囊网络的输入样本向量;③对高光谱数据进行空间域的随机标注,得到少量标注的训练样本;④采用主动学习扩充训练样本库并迭代更新未标注样本库和标注样本库;⑤通过迭代更新的训练样本不断训练胶囊网络分类器从而迭代优化其在具有隐蔽色特征场景下的高光谱分类性能;⑥对所有样本的输出结果进行拼接得到胶囊网络分类效果图,其中每类样本用不同颜色进行表示。该方法的总体流程图如图8所示。

图8 分类方法的总体流程图Fig.8 Overall flow chart of classification method
基于主动学习的胶囊分类网络主体架构如图9所示。通过特征工程得到的胶囊分类器的输入样本大小为500×1,ReLU Conv 卷积层的卷积核大小为9×1×256,该卷积层的作用是将高光谱样本的像素特征转换成局部特征,然后作为输入送入到胶囊构造层中;胶囊构造层的卷积核大小为3×1×256,卷积得到的向量通过胶囊构造(capsule construction)形成多个主胶囊单元,胶囊构造核大小为32×8,即把256维的向量分为32 份,每一份有8个通道,每8个通道组成一个主胶囊单元,该层共输出32个胶囊单元,后接一个全连接层为动态路由选择做准备;路由选择层使用胶囊网络特有的动态路由算法通过迭代的一致性完成信息的传递,形成6个16维大小的数字胶囊;分类层按顺序保存6个数字胶囊的模值||L||2,以其中的最大模值代表的物体类别作为分类器的输出结果,从而实现高光谱的图像分类。
3 实验与结果分析
3.1 实验环境以及实验性能的评价
实验环境为Ubuntu 16.04 LTS 64位操作系统,实验平台为NVIDIA Jetson TX2 嵌入式平台,其GPU 拥有256个CUDA核心,CPU为四核ARM A57 Complex,内存为8 GB 128位的LPDDR4,实验所用深度学习框架为PyTorch。实验装置如图10所示。
由于分类网络的输入样本是以高光谱图像中的单一像素构造而成的,则输出结果也将是该像素的类别,在胶囊分类器输出分类结果后对数据进行拼接和着色处理,可以得到如图11所示的分类效果。从分类效果图可以看出,前述的具有隐蔽色特征的人造伪装物体被明显区分出来;自然场景中的树林、草地、迷彩网等其他颜色接近的物体也同时得到了精确的分类。
通过计算原始图像中各类物体的像素总数与胶囊分类网络输出分类图中各类物体像素的比值来评价各种方法的分类性能,即:
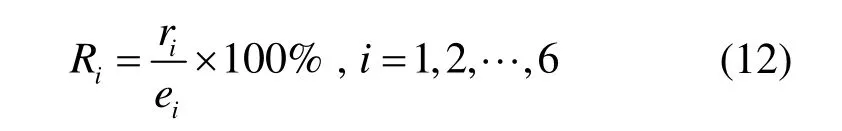
式中:Ri为类别i的物体的分类准确率;ri为分类网络输出的类别i的物体检测正确的像素总数;ei为实际的类别i的物体的像素总数。

图9 高光谱数据分类结构图Fig.9 Architecture of hyperspectral data classification
3.2 标注方法对比实验
为了验证利用主动学习进行样本标注有利于提高胶囊网络的分类性能,本文进行了如下4组实验:训练样本全部从已标注样本中随机选择、主动学习选择样本占比20%、主动学习选择样本占比30%、主动学习选择样本占比40%。特征构造的方法保持一致,设置胶囊网络的Batch_size为64,总共迭代次数为30000次,共计进行320个Epoch。模型初始学习率设置为0.001,每迭代训练10个Epoch,学习率调整为原来的一半,通过标记样本得到预训练模型,然后通过查询函数选择与已有标记样本差异较大的未标记样本,通过专家标注后送入训练模型,每查询到300个未标记样本进行一次网络参数的优化,参与训练的样本共有6000个,分为隐蔽物-车、隐蔽物-网、草、树木、阴影和天空6类,每个类别分别有1000个样本,测试样本共4000个。表1是5种不同标注样本占比的分类实验结果,从图5的二维标注可以看出每类物体的样本像素是不一样的,其中草地样本数是最多的,隐蔽物-车、阴影和天空的总样本偏少。实验发现这些类别在50%、60%占比的情况下主动学习扩大的标记样本和40%情况下的扩大标记样本基本没有差异,故继续扩大主动学习选择样本的比例对网络分类性能没有显著提高。实验数据证明训练样本中利用主动学习选择的样本占比为30%时,网络分类精度最高。

图10 实验装置图Fig.10 Display of the experimental devices

图11 高光谱分类效果图Fig.11 Hyperspectral image classification effect map
3.3 分类方法对比实验
为了进一步验证胶囊网络的有效性,本文分别选择LR、AlexNet 两种分类方法进行实验与之对比,LR、AlexNet和胶囊网络训练迭代次数均为30000次,特征构造、降维的方法均保持一致,选择准确率作为不同方法分类性能的评价指标。AlexNet 各项参数设置与胶囊网络相同,即Batch_size为64,总共迭代次数为30000,共计进行320个Epoch,模型初始学习率设置为0.001,每迭代训练10个Epoch,学习率调整为原来的一半;LR的初始学习率设置为0.001,每迭代1000次,学习率降低为原来的一半。参与训练的样本共有6000个,同样分为隐蔽物-车、隐蔽物-网、草、树木、阴影和天空6类,每个类别分别有1000个样本,其中随机标注的样本占比70%,主动学习标注的样本占比30%;测试样本共4000个。表2是3种分类方法的实验结果,实验结果表明本文提出的针对具有隐蔽色特征物体分类的主动学习胶囊网络算法具有出色的分类效果,不论是相比与AlexNet 还是LR算法,分类精度都取得了较大的提升。

表1 不同标注方法的分类性能比较Table1 Comparison of detection performance of different methods of labelling

表2 不同分类方法的性能比较Table2 Comparison of detection performance of different methods of classification
4 结论
针对具有不同类别隐蔽物的场景进行图像分类的问题,本文提出了一种具有隐蔽色特征物体的图像分类方法,采用光谱分析技术并将图像的空间特征融入到高光谱特征中并通过改进的特征降维算法更好地实现了高光谱空谱联合特征的保留,利用胶囊网络学习隐蔽物高光谱数据中丰富的特征信息,取得了比现有其他分类方法出色的分类精度。另外,针对实际面临的样本标注困难的情况,本文选择了基于改进查询函数的主动学习方法对训练样本进行扩充,最终使标注的样本更具有代表性,有效减少了样本标注的工作量以及网络模型的训练量。实验结果表明,该方法在自建高光谱数据集上,针对具有隐蔽色特征的物体和其他自然场景物体的分类精度都取得了出色的效果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
车主之友(2022年4期)2022-08-27
黑龙江大学自然科学学报(2022年1期)2022-03-29
现代装饰(2021年2期)2021-07-21
空间科学学报(2021年1期)2021-05-22
小学生优秀作文(低年级)(2020年4期)2020-07-24
海峡姐妹(2019年12期)2020-01-14
火控雷达技术(2016年1期)2016-02-06
食品工业科技(2014年23期)2014-03-11
