
基于设备画像的机车标签体系构建方法研究
2021-04-28 03:28李鑫史天运常宝马小宁刘军
交通运输系统工程与信息 2021年2期
李鑫,史天运,常宝,马小宁,刘军
(1.中国铁道科学研究院,研究生部,北京100081;2.中国铁道科学研究院集团有限公司,北京100081;3.中国铁道科学研究院集团有限公司,电子计算技术研究所,北京100081)
0 引言
机车是铁路客货运输的重要生产工具[1],能否全面、准确地掌握机车的质量状态将直接影响铁路运输生产效率和安全管理水平。随着各类监测检测设备和信息管理系统的不断投入,铁路已积累了海量的机车数据[2]。如何将这些数据转化为形象直观,易于生产人员理解和使用的日常生产知识,发挥数据的潜在价值,已成为机务大数据应用的重要课题。
机车设备画像作为铁路机务安全大数据应用的重要研究内容,致力于将分散、庞杂、难懂的数据转变为易获得、易理解、易分析的标签体系,从而客观、精准、形象地刻画出机车质量及安全状态。借助机车标签体系开展机车事故故障精准分析和诊断,有助于防止“设备不稳定状态”导致的事故故障,提升机车安全预警能力。在此基础上,通过对机车检修方案实施个性化设计,将支撑机车从“计划检修”向“差异化检修”转变,提高机车运输生产效率。同时,机车标签体系可以辅助日常安全管理决策,提高机车质量及安全管控水平。
目前,机车设备画像研究尚处于起步阶段,在实际应用中仍面临一些困难。一是大量数据仍堆积在各自的信息系统中,数据的深层价值利用不足;二是大量数据需要结合专业的数据处理知识才能被深入理解,无法被生产管理人员充分使用;三是数据挖掘算法的应用较少,尚未构建可行的机车标签体系,无法形成真实完整的机车画像。
因此,本文运用画像及标签技术,提出基于设备画像的机车标签体系技术框架,形成完整的机车标签体系,并运用改进的K-means聚类算法等标签获取手段,在某铁路局开展实际应用研究,取得了良好的应用效果。
1 设备画像与标签技术
画像研究是通过“打标签”的形式[3],将研究对象的基本属性、行为特征等信息抽象成一个标签化的模型[4],易于人们理解且方便计算机处理分析。
1.1 设备画像
设备画像是借鉴用户画像[5]的概念,采集目标设备的基本信息和在运行过程中留下的各类数据,并将其转换为画像标签。通过构造精准、细粒度和结构化的标签体系[6],形成设备的抽象画像模型,进而利用数据挖掘等方法,对设备状态进行有针对性的分析和研究。
铁路机车设备画像是设备画像在铁路机务专业的具体应用,是将机车运用、整备、检修、专项整治等多个维度的海量数据,按照一定的结构精炼成机车的画像标签,使机车数据表述更加规范化、形象化和可读化,从而对机车的健康状态实现精准、科学、直观地把控,降低机车数据的分析难度,推动大数据技术与机车运输生产管理的深入结合。
1.2 标签技术
标签是基于人为定义的规则,结合实际应用而高度精炼的简洁、具体、形象化的特征标识[7]。标签具有“人为定义”“语义化”“短文本”这3 个特点[8],即通过人为的概括或定义,以唯一性的语义说明对应标签的具体含义。设备的标签与设备画像之间的关系如图1所示。
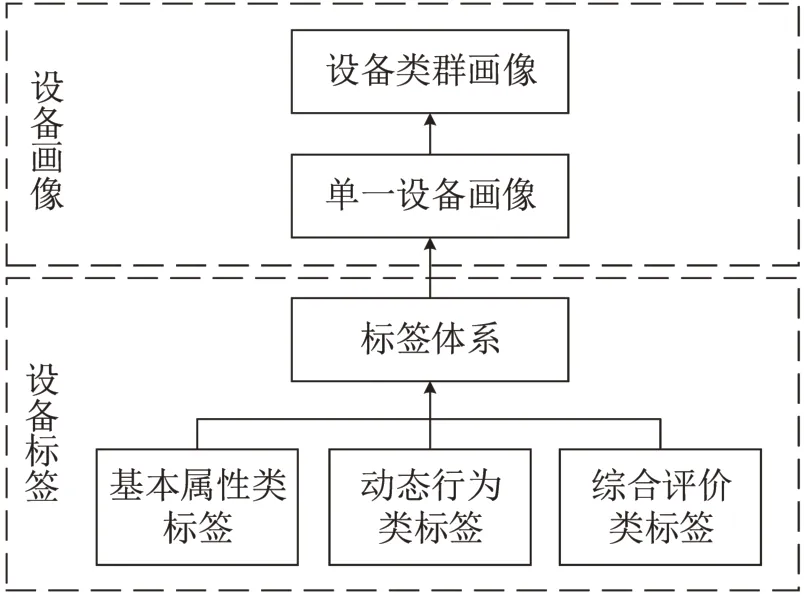
图1 设备标签与设备画像关系结构标签评价Fig.1 Relationship between equipment labels and equipment portrait
设备标签可分为“基本属性类标签”“动态行为类标签”“综合评价类标签”这3 类[9]。基本属性类标签描述设备固有的、静态的属性,取值通常比较容易。动态行为类标签反映设备的运转状态、养护情况、事故故障等动态信息,体现设备的实时状态。综合评价类标签则是根据设备的生产特点及制度规范总结归纳的具有评价性质的信息。
2 机车标签体系
2.1 技术架构
机车标签体系的技术架构以单台机车为研究主体,由“数据采集层”“标签库层”“标签应用层”构成,如图2所示。
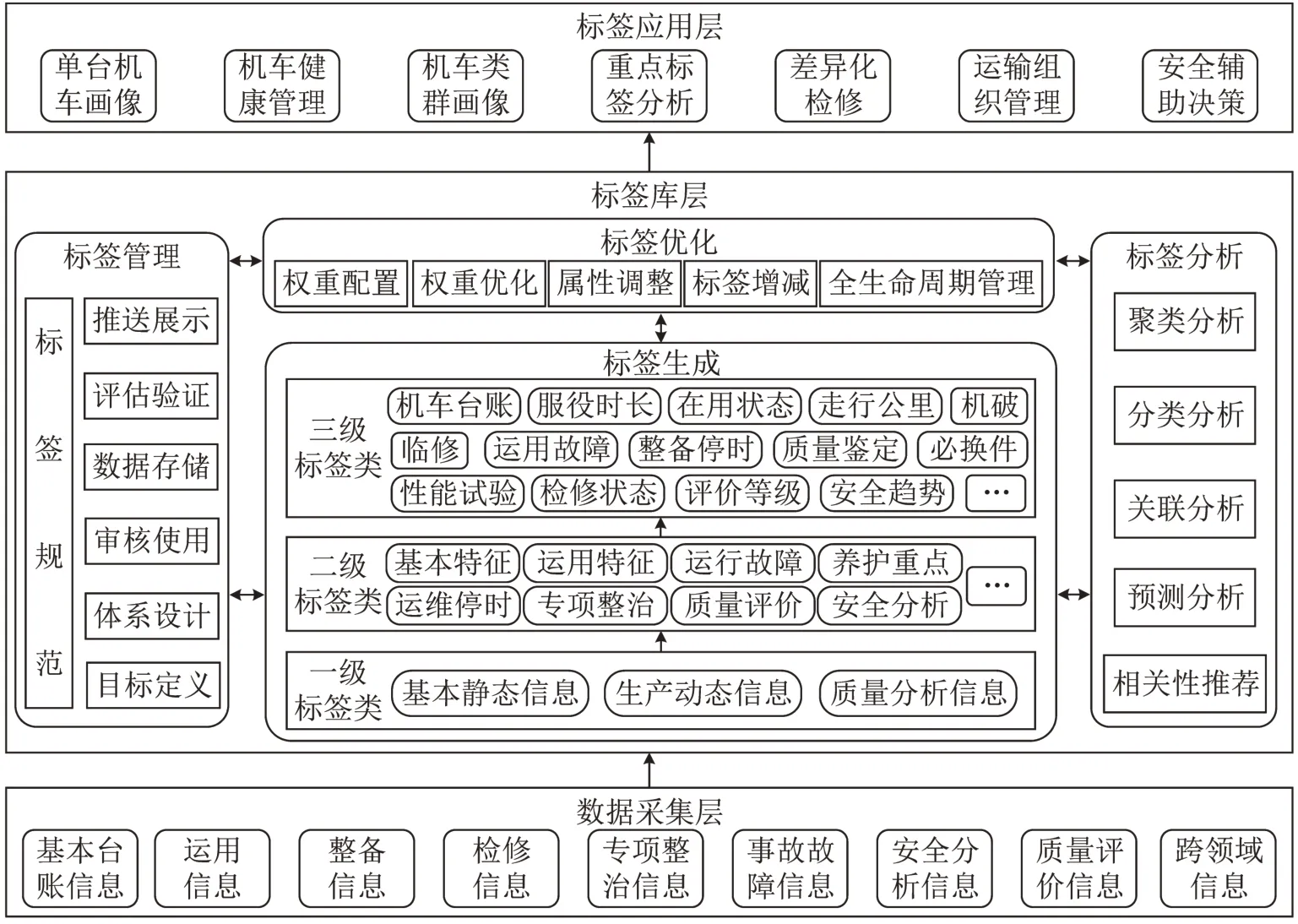
图2 机车标签体系技术架构Fig.2 Technical framework of locomotive label system
技术架构以数据汇集为基础,以标签生成、优化及管理为核心,以标签应用为目标,利用大数据挖掘算法,整合机车各类生产数据,开展机车标签体系的全生命周期管理,满足机务专业相关的业务需求。
(1)数据采集层
数据采集层是以系统对接,数据录入,批量导入等方式,采集机车相关的各类数据,为标签形成和优化提供基础数据来源。基本台账信息以静态信息为主,数据内容保持时间较长,数据采集比较容易。运用信息、整备信息、检修信息、专项整治信息和事故故障信息等数据为动态生产信息,基本涵盖了机务系统日常运输生产中的所有环节,这些数据大多存储于相应的信息管理系统中,可以采用系统对接、人工转储等方式获取。安全分析信息和质量评价信息属于综合评价类数据,主要依据各项规章及行业专家意见获得。跨领域信息则是与机车有关的其他专业领域的数据,如天气信息、地理信息、线路信息、供电信息等。
(2)标签库层
标签库层是利用数据采集层所提供的各类数据,按照标签体系结构,生成能够刻画机车特征的各个标签。标签库层包含“标签管理”“标签生成”“标签分析”“标签优化”4个子层。
标签管理子层通过设计、审核、展示等多个标签管理环节,全过程服务于标签的生成、存储、评估、优化和调整。标签生成子层通过数据提取、统计和挖掘等手段,利用数据采集层提供的各类数据,形成能够反映机车真实状态的特征标识,构建机车设备画像的3 级标签体系。标签分析子层是相关数据挖掘算法的集成,为标签生成、优化和分析过程等提供算法支持。标签优化子层是随着数据的积累、业务的调整和生产制度的革新,通过与标签管理子层的实时联动,运用标签分析子层提供的相关分析算法,对标签体系进行优化和升级。
(3)标签应用层
标签应用层利用机车标签体系开展机车画像分析及应用。首先,通过单台机车画像的实现,全面、客观、形象地刻画机车的运维特征和健康状态。进而,按照机车类型、所属站段、担当线路等,实现机车类群的整体质量把控。此外,还可以对机破、运用故障、碎修、5 项专检等关键标签进行挖掘分析,以满足故障处理、整备排班、更新改造等业务需要。
在有效地把握机车健康状态的基础上,还可以有针对性地调整机车的整备及检修计划,为机车由计划性检修向差异化检修转变,最终为实现状态修提供必要的数据支撑和参考依据。同时,易于理解的画像标签及相关分析还可以支撑机车运输组织管理和安全辅助决策等需求,实现机车数据应用与生产管理之间的良性闭环。
2.2 标签体系
机车标签体系以单台机车为基本单元,按照3级标签体系结构,综合利用机车各类生产数据,产生完整的机车画像标签。
(1)一级标签
机车的一级标签体现机车设备画像的基本刻画维度,是机车的共有特征,数量固定,形式统一,可以梳理为基本信息、运用质量、整备质量、检修质量和质量评价等维度,如表1所示。

表1 机车标签体系的一级标签Table 1 First class labels of locomotive label system
(2)二级标签
机车的二级标签是对一级标签的细化,体现机车标签体系的管理及分析维度,数量及形式基本固定,涵盖基本特征、运用特征、运行故障、整备重点、检修重点、专项整治、运维停时、质量评价、安全分析等多个方面。机车标签体系的二级标签如表2所示。
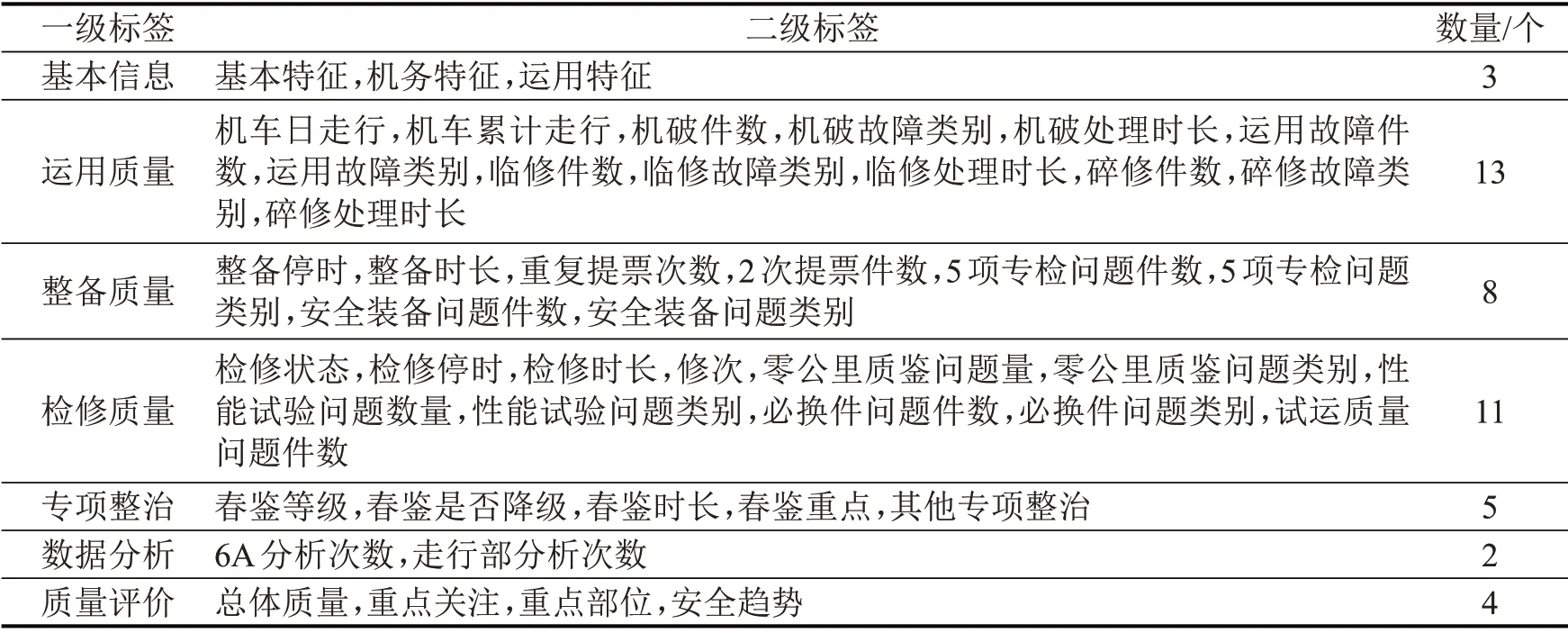
表2 机车标签体系的二级标签详情Table 2 Second class labels of locomotive label system
(3)三级标签
三级标签是反映机车具体状态的个性化特征,是对二级标签具体内容的明确,兼具使用价值和统计分析价值,不同机车的三级标签具体内容不尽相同。
机车的三级标签主要有以下几种获取方式:
一是直接获取。这类标签主要用来描述机车的固有属性和基本特征,不需要过多的计算和处理便可以从数据库中直接提取,如配属时间、生产厂家、担当线别等。
二是统计计算。这类标签通过简单的数量统计和逻辑运算即可获得,如故障类别及对应数量等,多存在于动态行为类标签中,体现机车质量的实时状态。
三是挖掘分析。这类标签不能通过简单的计算获得,需要运用聚类、分类、预测、关联分析等多种数据挖掘算法,综合分析机车产生的各类数据,从而形成能够抽象描述机车某一维度的标签信息。其中,聚类分析方法应用较多,在尚无法获知标签具体内容的类别划分时,可以通过聚类算法挖掘分析机车相应数据,得到准确的标签类别。
3 标签生成的聚类算法
如上所述,机车的3级标签大多通过聚类方法获得,而经典的K-means聚类算法存在聚类效果过于依赖初始化中心的问题。通过改进初始质心的选取方式,可以改善聚类效果,提高聚类效率。
3.1 K-means算法
K-means 算法是基于距离的聚类算法[10],采用距离作为相似性的评价指标,以最小化误差函数为基础将数据划分为预先设定的K个类别,每个类别由距离靠近的对象组成,算法把得到紧凑且独立的簇作为最终目标。K-means算法的基本流程如下:
Step 1 对于共有n个样本的数据集U={x1,x2,…,xn} ,随机选取K个样本作为初始的聚类质心,表示为μi,其中,K≤n,i≤n,聚类类别表示为C={C1,C2,…,Ck} 。
Step 2 分别计算数据集中的每个样本xi距离K个聚类质心的距离,并将该样本划分到距离最小的聚类中心所对应的类中。
Step 3 当遍历所有样本点后,重新计算每个类别的聚类质心,作为下一次聚类过程中所在类别的新的中心点,i≤K。
Step 4 重复Step 2 和Step 3,直到各个类别的聚类质心不再变化。
对于欧式空间的样本数据,以平方误差和eSSE作为聚类的目标函数,并作为衡量不同聚类效果的指标[11],表示为样本点x到所在聚类类别Ci的聚类质心μi间距离的平方和。当eSSE值越小,表明聚类类别内部的样本越相似,最优的聚类结果应使得eSSE达到最小值。
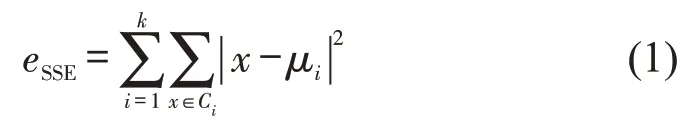
K-means 算法具有快速、高效的计算优点,但是,其聚类效果容易受到初始质心的影响陷入局部最优。可以通过优化初始质心解决这一问题。
3.2 K-means算法的改进
为避免K-means 算法的聚类效果陷入局部最优,选取初始质心时,质心间的距离要尽可能的远。质心优化选取的基本思路为:
Step 1 从数据集U={x1,x2,…,xn} 中随机选取一个样本xi作为第1个聚类质心μ1。
Step 2 计算每个样本与当前选定的聚类质心的最短距离D(x),并作为样本被选取为下一个聚类质心的权重值。某个样本xi的D(xi)值越大,表示样本xi被选取作为下一个聚类中心的概率越大;选择D(xi)最大的样本点成为下一个聚类质心。
Step 3 重复Step 2直到选择出K个聚类质心。
当选取出K个初始质心后,则转入K-means算法中Step 2~Step 3。
尽可能最大化地增大初始质心点之间的距离,能显著地改善最终结果的误差。虽然选取初始质心时会多花费一些时间,却能提高聚类过程的收敛速度和算法的稳定性。
3.3 验证比较
采用经典的鸢尾花卉数据集(Iris Dataset),分析比较上述两种算法的聚类效果。K-means 算法的聚类效果如表3所示,改进初始质心选取方式后的聚类效果如表4所示。
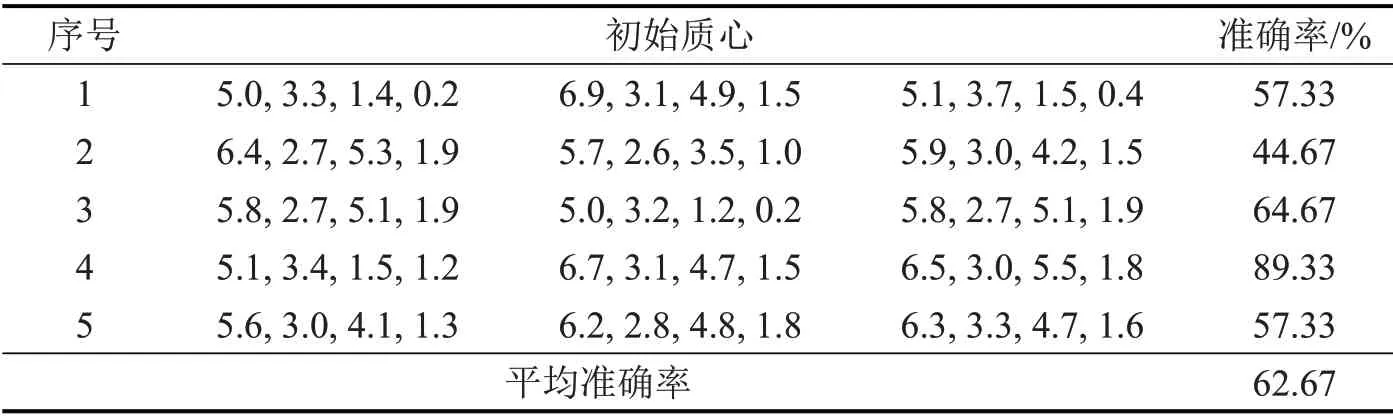
表3 K-means算法对Iris数据集的聚类效果Table 3 Clustering effect of K-means algorithm on Iris data set
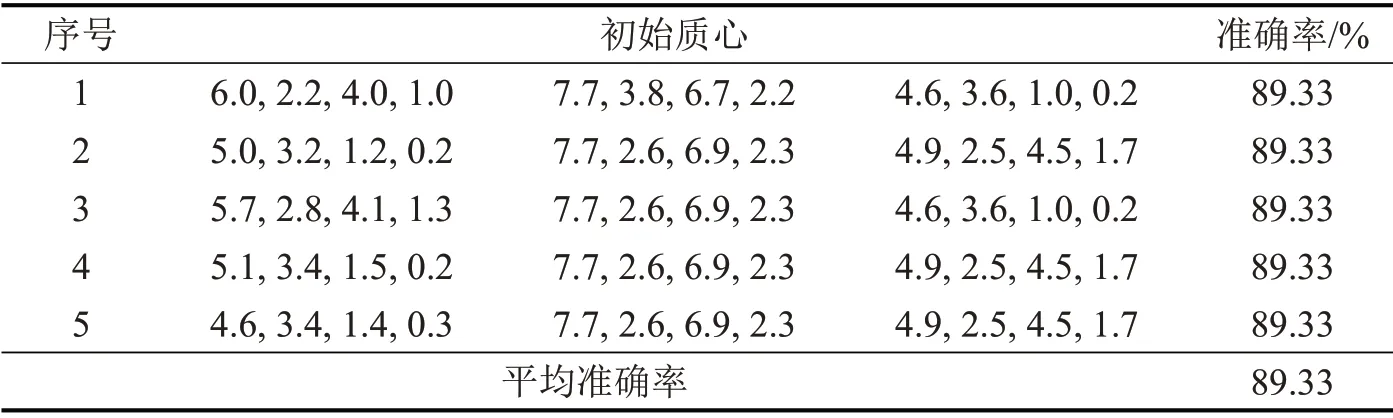
表4 改进的聚类算法对Iris数据集的聚类效果Table 4 Clustering effect of improved K-means algorithm on Iris data set
通过比较可知,改进初始质心的选取方式,聚类的平均准确率由62.67%提升到89.33%,准确率和稳定性均有较大幅度提升。
4 案例研究
基于机车设备画像标签体系和标签获取方式,利用某铁路局2019年全年积累的机车生产数据,产生完整的机车画像3级标签。
4.1 K-means改进算法的应用
以该铁路局2019年1月-12月共计59112条“机车整备时长”数据为例,应用K-means改进算法,对机车“整备质量”(一级标签)下的“整备时长”(二级标签)进行聚类分析,形成相应的3级标签类别。
在进行聚类分析时,首先需要确定聚类类别K的值。在尚不明确数据分布的情况下,往往较难确定某个3级标签的实际类别数。因此,需要根据业务实际和历史数据,比较不同K值下的聚类效果,选取适合的K值。
聚类样本总的eSSE值会随着K值的增大而逐渐减小。当K的取值偏小时,eSSE值会随着K的增大而快速降低;当K的取值较大时,eSSE值会随着K的增大转为缓慢下降的趋势。“整备时长”的eSSE值与K值的关系如图3所示。
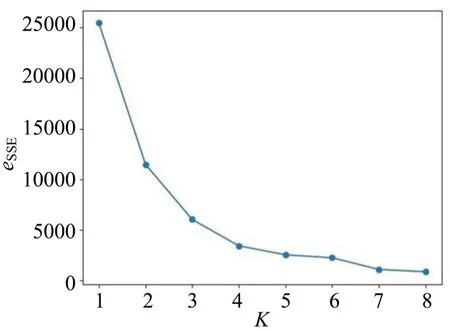
图3 某铁路局机车整备时长eSSE 值与K 值的关系Fig.3 Relationship between eSSE and K of clustering of locomotive maintenance time in a railway bureau
由图3可知,当K=4 时,eSSE值开始变为缓慢下降趋势,因此,可以根据业务需要,将机车“整备时长”下分为4 个3 级标签。具体聚类结果如表5所示。
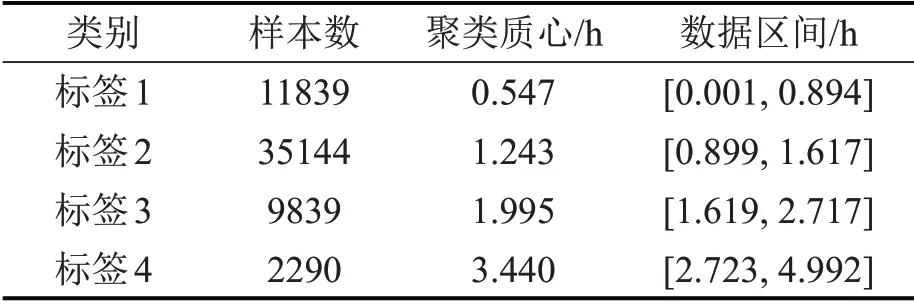
表5 某铁路局机车整备时长在K=4 时的聚类结果Table 5 Clustering result of locomotive maintenance time of a railway bureau when K=4
根据聚类结果,同时结合生产实际,可将标签1 记为“整备时长正常”,表示整备作业时间符合作业规范要求;标签2 的数据量占比59.45%,可将这一特征记为“整备时长略长”,表示机车的整备时间基本符合作业需要,稍有耗时;标签3则记为“整备时长较长”,表示整备作业时间已超出正常作业的时间规范;标签4 按照聚类情况记为“整备时长过长”,表示整备作业时间过长,已影响到机车整备效率。
按照此方法,对全局的机车在“机车日走行”“机破件数”“碎修件数”“整备时长”“性能试验问题件数”等多个标签维度进行聚类分析,并对相应的3级标签赋予具体内容。
4.2 机车完整标签体系的产生
随机选择该局的1 台机车,通过直接提取、统计分类、聚类分析等方法,产生该台机车具体的3级标签,形成完整的机车设备画像标签体系,如图4所示,其中出于数据安全考虑已对部分数据做脱敏处理。
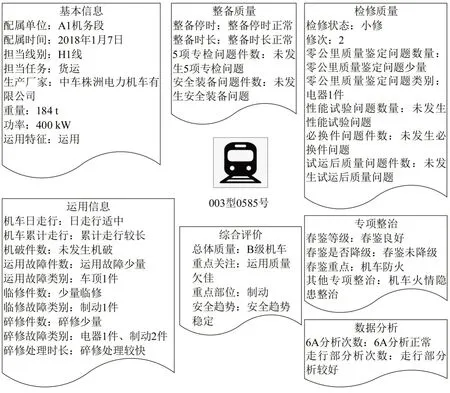
图4 某铁路局某台机车的标签体系Fig.4 Label cluster of a locomotive in a railway bureau
结合该局的实际生产管理情况,以月度为时间单位,对机车的3 级标签进行更新,得到机车不同月份的画像标签。只需将更新数据与不同类别的数据区间进行比较,得到相应的新的3级标签。此外,为保证聚类结果的准确有效,还应该结合行业专家意见、业务应用需要、数据积累情况、服务器处理能力等因素,及时调整机车3级标签的类别划分和含义描述,实现机车标签体系的全生命周期管理和动态优化。
5 结论
本文针对铁路机务专业在大数据应用中的现实需要,提出运用画像及标签技术,构造客观、全面的机车标签体系,通过机车设备画像实现精准的质量分析及高效的安全管控。运用机车设备画像的概念及与标签的理论关系,针对机车质量管理、差异化检修、安全辅助决策等应用场景,设计机车设备画像标签体系技术架构,阐述技术架构由数据采集到标签生成再到标签应用的内在逻辑和流程,以及标签体系的管理、分析及优化方式;具体介绍机车标签体系的3 级结构、标签类型、标签内容和获取方法。特别针对聚类标签的获取方式,通过改进K-means算法初始质心的选取方法,将聚类的准确度由62.67%提升到89.33%。
在某铁路局开展机车设备画像理论的实际应用,获得多个标签维度下具体的3 级标签内容,形成完整的机车标签体系,实现为机车精准画像的目的,为开展机车类群画像、指标分析、运维优化和安全管控打下基础。
猜你喜欢
中国设备工程(2023年2期)2023-02-13
汽车实用技术(2022年14期)2022-07-30
小哥白尼(神奇星球)(2022年3期)2022-06-06
北京航空航天大学学报(2021年4期)2021-11-24
装备制造技术(2021年2期)2021-07-21
新世纪智能(高一语文)(2020年9期)2021-01-04
非公有制企业党建(2020年10期)2020-10-27
铁道通信信号(2019年2期)2019-03-26
中国铸造装备与技术(2017年3期)2017-06-21
航天器工程(2014年5期)2014-03-11
