
城市公共交通常乘客通勤出行提取方法
2021-04-28 03:28:14彭飞宋国华朱珊
交通运输系统工程与信息 2021年2期
彭飞,宋国华*,朱珊
(1.北京交通大学,综合交通运输大数据应用技术交通运输行业重点实验室,北京100044;2.北京交通发展研究院,北京100073)
0 引言
城市交通系统中乘客出行需求时空特征分布不均衡,易引发高峰时段交通拥堵,通过面向城市公共交通乘客提出“预约出行”计划能够有效缓解公共交通高峰拥堵和交通资源紧张状况[1]。城市公共交通常乘客指经常使用公共交通出行的乘客,对城市公共交通具有较高的依赖程度和使用程度。通勤出行作为城市公共交通中乘客的主要出行需求,能够反映公共交通出行效率,故面向城市公共交通常乘客精确挖掘通勤出行特征尤为重要。
国内外针对公共交通通勤乘客识别和通勤特征提取的研究较多,主要方法包括聚类、关联规则、阈值判定、机器学习等。翁剑成等[2]通过设定判别规则定义乘客在1 周中最大刷卡时间间隔大于7 h 的天数达到3 d 以上即为公共交通通勤出行者。梁泉等[3]面向公共交通乘客分类的BP 神经元网络模型对通勤人群进行辨识。孙世超[4]使用基于问卷调查数据结合公交刷卡数据构建朴素贝叶斯分类器模型辨识通勤人群,并分析通勤人群的辨识结果。Gain 等[5]基于连续隐马尔可夫模型的机器学习方法识别出首尔市区通勤行为。刘耀林等[6]通过1 周工作日的公交上车刷卡数据,构建出行模型和职住地识别规则。Long[7]结合公交刷卡数据和土地利用图,综合决策树法和关联规则法识别通勤人群,并在通勤距离可视化的基础上分析居住区和工作区的通勤特征。Ji[8]利用出行调查数据生成通勤识别规则,结合工作日地铁数据识别通勤人群,根据地铁通勤人群的时空特征,采用高斯混合模型的聚类方法将其分为经典模式、非高峰期模式和长距离模式。
现有的多数研究中存在以下问题:①城市公共交通中公交和轨道交通之间不断融合发展,乘客通勤出行方式已经不能单一考虑公交或轨道交通;②实际中不同通勤个体的出行稳定性可能不一致[9],通勤乘客的出行行为存在较大的差异,其中也包含大量的非通勤出行,面向通勤乘客对通勤出行特征挖掘的准确性存在潜在影响,缺乏能够精准反映通勤出行特征的状态;③针对通勤乘客的识别方法往往需要结合调查问卷数据来判断,调查问卷获取训练数据集的质量不一定能够完全学习各种通勤情况,而且调查样本结果本身有一定的时效性,动态特征分析时不易避免时间变化造成样本偏差带来的影响。
因此,本文研究面向公交和轨道交通中的常乘客,从非集计模型的角度,通过一定周期的出行链数据挖掘乘客出行链的时空分布规律[10-12],利用其中包含的内在关系和客观规律提出常乘客职住地识别算法,并根据出行链起讫站点和职住地空间位置匹配关系提取通勤出行链,分析常乘客通勤出行需求的时空分布及出行方式选择特征。该方法不受限于问卷调查,能够更准确地提取常乘客通勤出行。研究结果可为北京市公共交通出行个体的动态出行特征精细化挖掘提供依据,对于提高职住分离地区的公共交通通勤出行效率具有重要意义。
1 数据基础
1.1 出行链数据描述
本文获取公交IC(Integrated Circuit)刷卡数据、地铁AFC(Automatic Fare Collection)系统刷卡数据和车辆GPS(Global Positioning System)位置数据在内的北京市公共交通多源数据。北京市公交乘车刷卡数据包含乘客出行上下站点空间位置和时间信息,数据采用已经完成公交与轨道换乘识别的出行链数据,该数据考虑了两种出行方式之间的衔接,能够完整展现出行乘客的出行时空信息。以某位乘客1 d 的数据为例,出行链数据如表1所示。出行链数据字段包括乘客ID号、出行链编号、上下站时空信息、换乘信息和交通方式等。

表1 乘客1 d出行链数据Table 1 Passengers'daily travel chain data
1.2 出行链结构
出行链结构特征变化能够反映公交与轨道交通之间客流转移变化特征。一条出行链数据代表了乘客一次出行(包括换乘出行和不换乘出行),换乘出行至少由两个出行阶段组成,不换乘出行仅有一个出行阶段。每个出行阶段选择公交或轨道交通中的一种出行方式分别用B 和S 表示,其中,轨道交通不同线路之间换乘为一个出行阶段。出行链结构按照出行方式选择划分为4种,分别为仅乘公交、仅乘轨道交通、公交和公交之间换乘、公交和轨道交通之间换乘,分别表示为B、S、B-B、B-S。
2 居住地识别算法设计
2.1 选取潜在居住地
根据出行需求和出行时间特征客观规律认为:一般情况下出行乘客单日首次出行为离开居住地,单日末次出行为到达居住地,故从常乘客单日出行链数据起讫站点提取首次出行起始站点和末次出行到达站点分别作为潜在居住地h1和h2。考虑到存在出行乘客单日出行仅有1 次且该次出行即是首次出行又是末次出行,为确定该次出行需求,在选取潜在居住地时设定首次和末次出行的时间范围,首次出行出发时间为上午时段(4:00-12:00),末次出行出发时间为晚间时段(16:00-0:00)。
2.2 设置高频居住地
为排除单日特殊情况下提取的潜在居住地站点为非真实居住地的干扰,从多日的潜在居住地站点中选取出现频率最高频站点作为高频居住地。考虑到离开和到达居住地这两种出行需求在出行方式的选择上受时间约束有不确定性,故根据不同出行需求提取的潜在居住地设置两类高频居住地H1和H2,从多日中提取的潜在居住地h1和潜在居住地h2中选取出现频率最高的站点分别作为集合H1和H2中元素。
2.3 构建居住地识别条件
为提高居住地识别准确性,从潜在居住地中进一步挖掘有代表性的站点和高频站点进行比较来构建有效的识别条件。从提取多日的潜在居住地h1中选取出发时间最早的两个作为集合H3中的元素,从潜在居住地h2中选取到达时间最晚的两个潜在居住地作为集合H4中的元素。当有些站点出现频率相同时集合中元素可能不唯一,当高频居住地集合中站点元素唯一时,该元素作为真实居住地的可能性就越大;同时该元素应在其他集合中也存在,表明所设置的高频居住地更加符合出行需求从居住地出发或者到达的客观规律。例如:当H1集合中仅有唯一元素h1,且该站点在集合H2,H3,H4中存在;当H2集合中仅有唯一元素h2,且该站点在H1,H3,H4集合中存在,鉴于此构建识别条件为
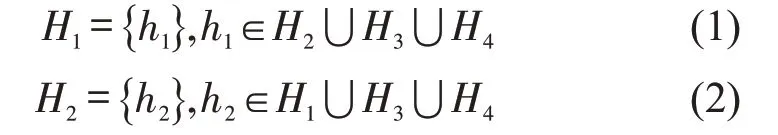
2.4 居住地识别流程
潜在居住地选取中不考虑工作地和工作日之间的差异,因此为增加数据样本量,提高识别准确度,居住地识别选取的出行链数据包括工作日和非工作日。输入多日常乘客出行链数据,选取潜在居住地并设置高频居住地。当高频居住地集合H1满足识别条件式(1)时,H1中唯一元素为居住地;满足识别条件式(2)时,H2中唯一元素为居住地。居住地识别条件判断顺序如图1所示,最后输出该常乘客居住地为Sh,若不能满足识别条件则无法识别其居住地。
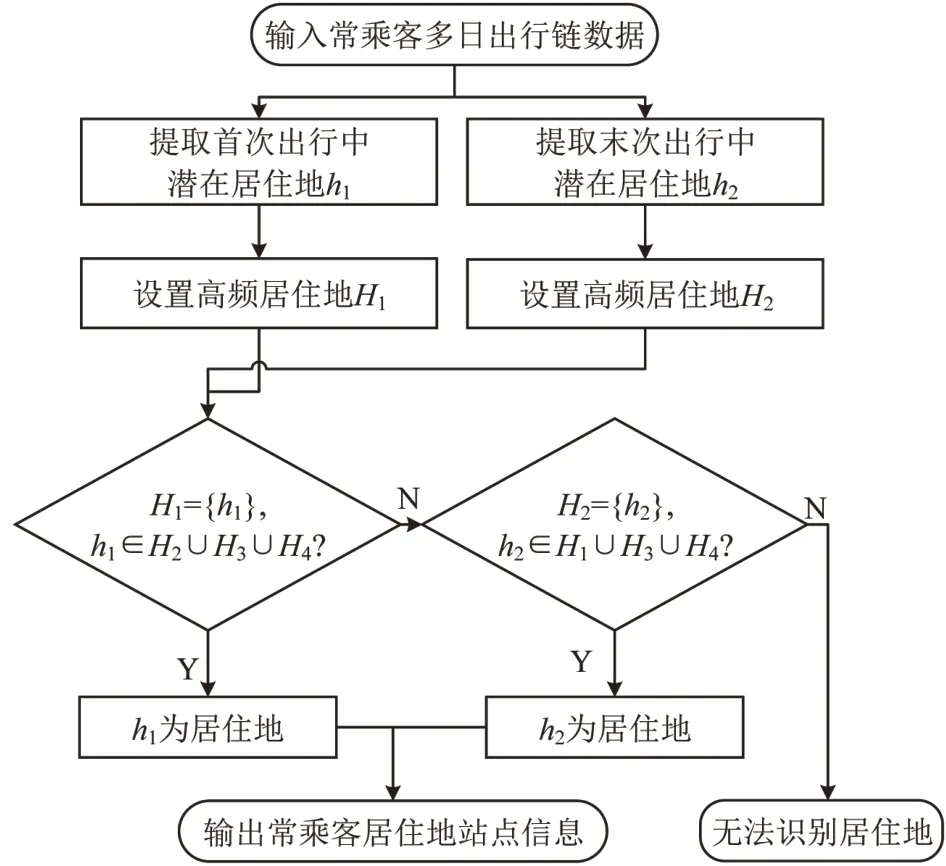
图1 居住地识别流程Fig.1 Residence identification process
3 工作地识别算法设计
3.1 选取潜在工作地
根据工作日中的通勤出行需求和出行时空特征客观规律认为:出行乘客早晚高峰出行分别为到达和离开工作地。从常乘客工作日单日出行链数据起讫站点提取出发时间在早高峰(6:00-10:00)的出行到达站点和晚高峰(17:00-20:00)的出行起始站点作为潜在工作地w1。考虑到受时间约束较小的通勤出行不一定在早晚高峰,故根据早晚高峰时段的出行选取潜在工作地只适用于典型的通勤乘客;对于非典型的通勤乘客,一般情况下工作日中通勤出行往往是连接居住地和工作地,故提取从居住地出发的到达站点和到达居住地的起始站点作为潜在工作地w2。
3.2 设置高频工作地
为排除单日特殊情况下提取的潜在工作地站点为非真实工作地的干扰,同样从多日的潜在工作地站点中选取出现频率最高频站点作为高频工作地。从工作日多日提取的潜在居住地w1和潜在居住地w2中选取出现频率最高的站点分别作为集合W1和W2中元素。
3.3 构建工作地识别条件
通过两个高频工作地的比较来构建工作地识别条件,当高频工作地集合中站点元素唯一时,该元素作为真实工作地的可能性就越大。同时该元素应在另一个高频工作地集合中同样存在,表明所设置的高频工作地更加符合常乘客通勤出行需求的客观规律。例如:当W1有唯一元素w1,且站点w1在W2中存在;当W2有唯一元素w2,且站点w2在W1中存在。构建判别条件为

实际中,居住地和工作地周边有多个公共交通站点提供出行服务,不同出行乘客在同一出行需求下具有交通方式、线路、站点选择的多样性。鉴于此,根据公交、地铁站点服务半径及乘客可接受的步行距离范围设定距离约束ε,当两个高频工作地集合中站点元素都唯一但不相同时,通过两站点经纬度数据计算空间距离l,其表达式为
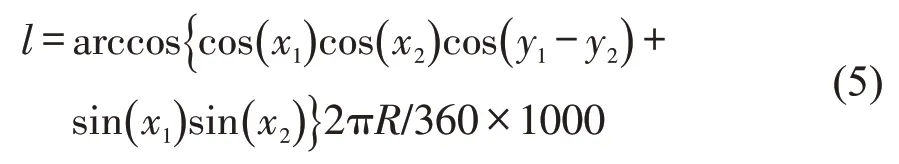
式中:R为地球平均半径(R=6371 km);x1,x2分别为出发和到达站点所在经度坐标;y1,y2分别为出发和到达站点所在维度坐标。
当空间距离l满足距离约束ε时,若满足将其识别为同一工作地的两个不同工作地站点。即W1和W2有唯一元素但w1和w2不相同,两者间的欧式距离l不大于距离约束ε,增加识别条件为

3.4 工作地识别流程
针对已识别出居住地的常乘客,输入多日工作日出行链数据,选取潜在工作地并设置高频工作地。判断高频工作地W1和W2是否满足识别条件,当满足识别条件式(3)或式(6)时,W1中唯一元素为工作地;满足判别条件式(4)时,W2中唯一元素为工作地。工作地识别条件判断顺序如图2所示,最终输出识别结果为该常乘客工作地Sw,若不能满足识别条件则无法识别其工作地。
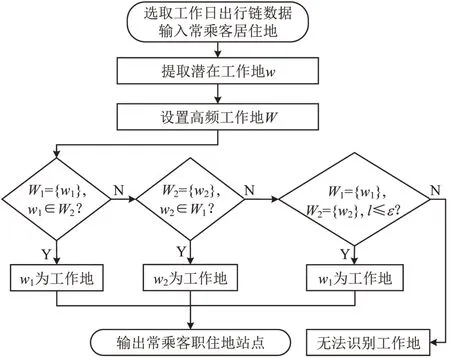
图2 工作地识别流程Fig.2 Workplace identification process
4 通勤出行链提取
4.1 通勤出行分类
在常乘客职住地识别的基础上提取通勤链,综合考虑时间和空间上的通勤规律。无法识别职住地的常乘客,其通勤出行规律不明显且稳定性较低或是没有固定职业,故出行链空间信息匹配只针对职住地已识别的常乘客。根据出行链的起讫站点和职住地站点的空间位置关系匹配将通勤出行链分为home-work(HW)出行链和work-home(WH)出行链两种类别:HW出行链表示从其居住地前往工作地的通勤出行,WH出行链表示出行者从其工作地前往居住地的通勤出行。
4.2 出行链空间信息匹配
定义出行乘客的所有出行数据由n条出行链构成,出行链对应一次出行中的起讫站点So,Sd构成的向量,结合居住地站点Sh和工作地站点Sw空间位置信息,提取HW出行链和WH出行链的起讫站点分别构成向量和构建条件判断式为
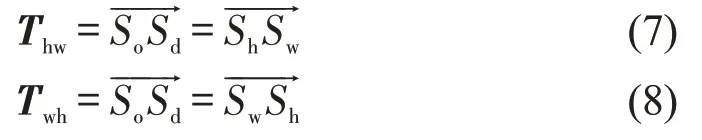
提取通勤链时,同样考虑不同出行乘客在同一出行需求下具有线路、站点选择的多样性。如图3所示,当职住地站点与出行链起讫点不同但距离很近时,可视为同一地点。因此,根据站点服务半径设定距离约束ε,为避免无法分类通勤距离小于服务半径的出行链,增加提取HW、WH出行链的条件判断分别为

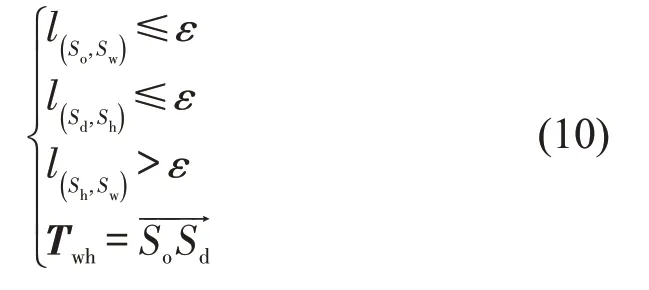
式中:l(So,Sh)为出行链起点与居住地之间距离;l(Sd,Sw)为出行链终点与工作地之间的距离;l(So,Sw)为出行链起点与工作地之间距离;l(Sh,Sw)为出行链终点与居住地之间的距离;l(Sh,Sw)为居住地和工作地之间距离。

图3 通勤出行链与职住地空间位置匹配Fig.3 Commuter travel chain matches home-work locations
5 应用案例分析
5.1 通勤出行链提取方法应用
以北京市职住分离严重的超大型居住区——回龙观和天通苑地区(简称“回天地区”)为例。该地区通勤需求时空分布高度不均衡,每天产生大量的钟摆式通勤需求,进站上车排队拥堵严重造成大量的时间及资源损耗,在该地区开展“预约出行”首先要掌握通勤出行需求。选取2019年9月在“回天地区”有乘车记录的约7万名乘客的公共交通出行链数据。定义月出行天数不少于15 d 的乘客为常乘客,站点服务半径距离约束ε设定为1500 m。本文算法得到的居住地、工作地识别率分别为95.7%、85.9%,其职住地分布如图4所示。针对识别出职住地的常乘客进行通勤出行提取,非通勤出行、HW通勤出行、WH 通勤出行比例分别为14%、46%、40%,其中,工作日中比例分别为12%、47%、41%,非工作日中比例分别为22%、42%、36%。
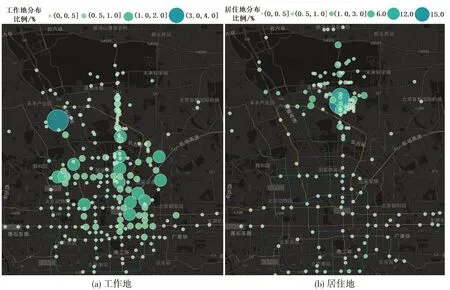
图4 常乘客职住地分布Fig.4 Distribution of frequent passengers'home-work locations
5.2 通勤与非通勤出行方式选择特征
对比常乘客提取出的通勤与非通勤出行链结构,如图5所示。可知:非通勤出行和通勤出行在出行方式选择上有较大差异,HW和WH通勤出行在出行方式选择上无明显差异。
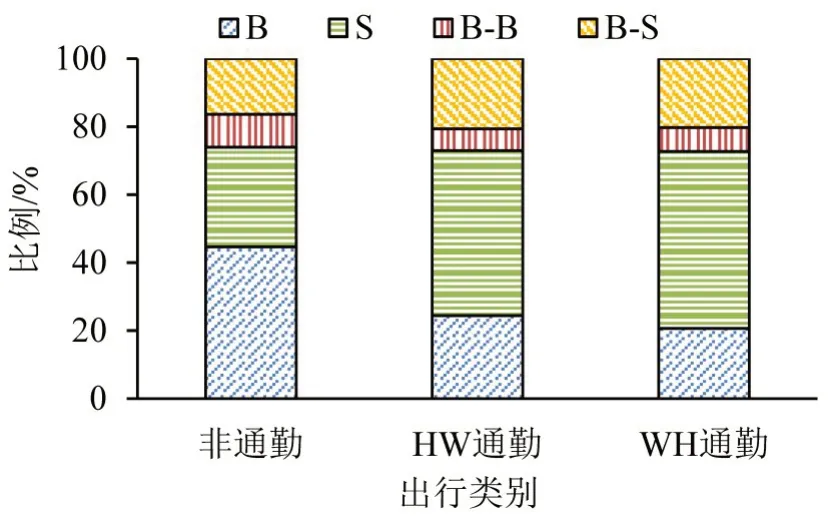
图5 出行链结构比例Fig.5 Proportion of travel chain structure
5.3 通勤与非通勤出发时间分布特征
对比常乘客提取出的通勤与非通勤出发时间分布,工作日和非工作日结果分别如图6和图7所示。可以看出:早晚高峰期间的出行以通勤出行为主,同时还包括一定比例的非通勤出行,在非工作日的非早晚高峰期间同样有一定比例的通勤出行。工作日中,HW通勤集中分布在6:00-10:00,其中,7:00-9:00 出行比例最高;WH 通勤集中分布在16:00-22:00,WH 通勤因下班后常乘客受时间约束更小出行方式选择更加灵活,与HW通勤出行时间相比没有那么集中,同时下班后增加了娱乐购物等出行目的,故晚高峰期间非通勤出行占比明显增加。非工作日中非早晚高峰期间通勤出行相比与工作日中的比例明显增加,HW 通勤主要分布在5:00-9:00,WH 通勤主要分布在15:00-22:00,通勤出行早晚高峰期相比工作日分布相对分散、范围更大。
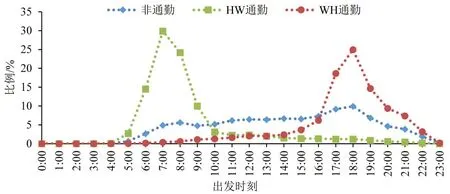
图6 工作日出发时间分布比例Fig.6 Percentage of departure time distribution on working days

图7 非工作日出发时间分布比例Fig.7 Percentage of departure time distribution during non-working days
5.4 通勤与非通勤出行距离分布特征
对比常乘客提取出的通勤与非通勤出行距离分布,工作日和非工作日结果分别如图8和图9所示。可以看出:通勤和非通勤出行距离分布比例有明显差异,通勤出行中出行距离大于8 km 的比例明显高于非通勤出行,非通勤出行中出行距离小于8 km 的比例明显高于通勤出行。通勤距离小于3 km时,WH和HW通勤的出行距离分布比例有明显差异,WH比HW通勤少了较强的时间约束且出行距离较短,往往有更多交通选择方式,故在工作日和非工作日中HW 通勤出行都明显高于WH 通勤出行的比例;通勤距离大于3 km 时,HW 通勤和WH通勤在不同出行距离的比例基本一致。
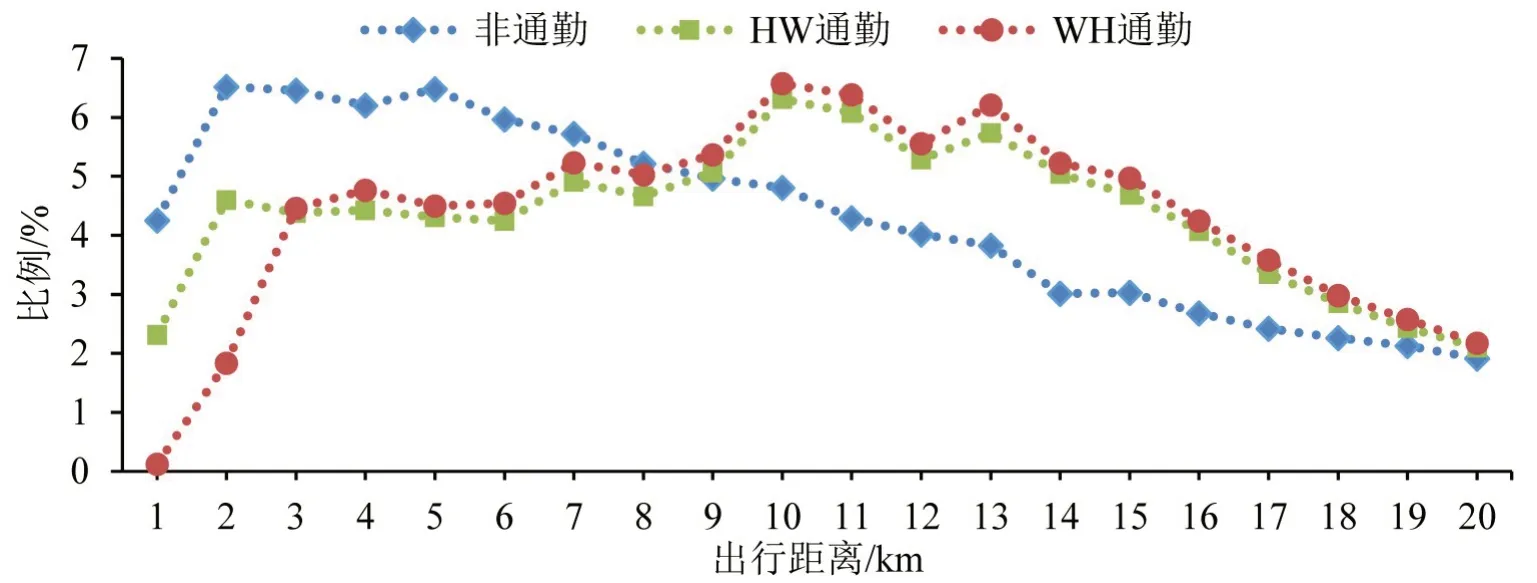
图8 工作日出行距离分布比例Fig.8 Percentage of travel distance distribution on working days

图9 非工作日出行距离分布比例Fig.9 Percentage of travel distance distribution during non-working days
5.5 通勤出行链提取方法应用误差分析
结合案例数据,分析新方法与原有方法(将识别通勤者作为通勤)应用结果的差异,提取通勤特征包括出发时刻、出行距离及出行方式,对比两种方法提取出20 d 工作日中单日通勤特征相对误差分布,如图10所示。可以看出:原有方法将通勤者的出行提取为通勤出行,会给通勤特征提取带来显著误差,特别是在出行方式为公交出行和出发时间在11:00-17:00 及出行距离不足3 km 的出行,存在较大误差。
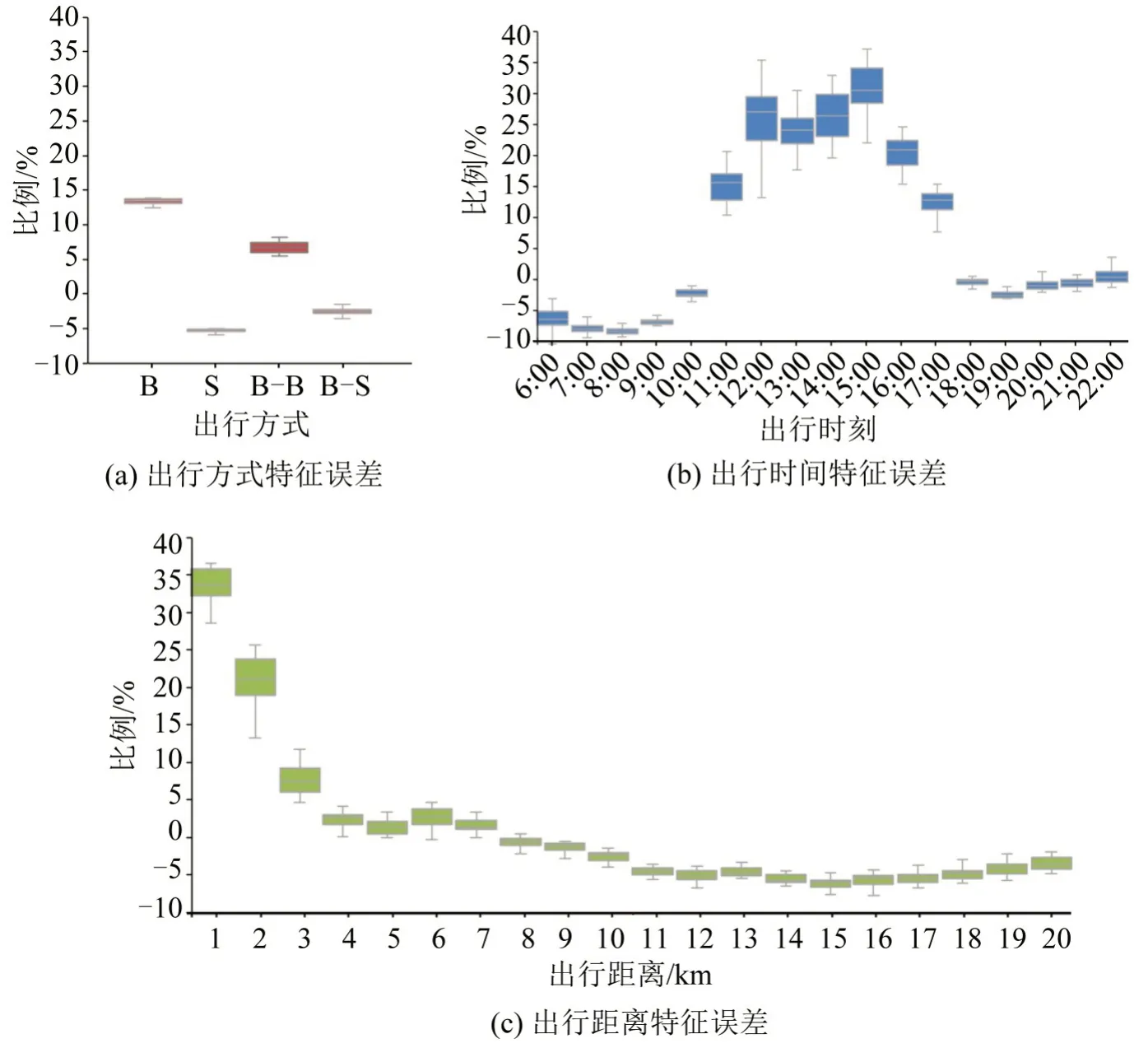
图10 工作日单日通勤特征相对误差分布Fig.10 Relative error distribution of single-day commuting characteristics on working days
6 结论
本文提出利用公交与轨道出行链数据提取常乘客通勤出行的方法,以北京市“回天地区”2 万多名常乘客30 d 的出行链数据为例进行通勤特征挖掘。
(1)考虑出行者全链条的出行行为,选用公交和轨道交通融合之后的出行链数据,同时研究对象由通勤个体转向通勤个体的通勤行为,能够精确提取通勤行为特征状态。此外,不需要大量问卷调查数据,避免了调查时效性带来的结果偏差,有利于通勤出行的动态变化特征分析。但该方法对数据量有较高要求,适用于至少以月份为周期的出行乘客全样本出行数据。
(2)针对常乘客出行链数据提出职住地识别算法,案例结果显示,常乘客居住地识别率达到95.7%,工作地识别率达到85.9%。根据常乘客职住地与出行链起讫站点空间信息匹配构建HW 和WH通勤出行链,提取得到已识别职住地的常乘客出行中非通勤出行、HW通勤出行、WH通勤出行的比例分别为14%、46%、40%。
(3)通勤与非通勤出行方式选择特征及出行时空特征分布的分析结果显示,通勤出行和非通勤出行方式、出发时间和出行距离特征上存在显著差异。通勤出行链提取方法应用误差分析结果显示,将通勤者的出行提取为通勤出行会对通勤特征提取带来显著误差,特别是在出行方式为公交出行,出发时间在11:00-17:00,出行距离不足3 km 的出行存在较大误差。本文方法提取HW 和WH 通勤能够有效消除通勤者的非通勤出行特征的差异性影响,确保通勤出行提取的准确性,同时能够精细化挖掘通勤出行特征。挖掘通勤出行时空特征、出行方式选择特征等精细化特征对公交和轨道系统两网融合协调优化具备重要参考价值,通勤出行提取可为北京市面向常乘客开展“预约出行”并分析其出行需求及客流转移动态特征变化提供依据。
猜你喜欢
城市公共交通(2021年3期)2021-04-15 06:39:16
小猕猴智力画刊(2018年5期)2018-05-25 07:59:42
阅读(快乐英语中年级)(2017年3期)2017-05-30 10:48:04
阅读(快乐英语中年级)(2017年5期)2017-05-30 10:48:04
自动化学报(2017年1期)2017-03-11 17:31:10
中国交通信息化(2016年3期)2016-06-05 02:21:43
绿色中国·B(2014年9期)2015-01-30 21:25:07
城市道桥与防洪(2014年6期)2014-02-27 07:27:24
商(2012年14期)2013-01-07 07:46:16
资源导刊(2011年4期)2011-08-15 00:51:44
