
公共自行车使用时空特性挖掘及租还需求预测
2021-04-28 03:28:34陈红陈恒瑞史转转张敏刘至真
交通运输系统工程与信息 2021年2期
陈红,陈恒瑞,史转转,张敏,刘至真
(长安大学,运输工程学院,西安710064)
0 引言
在“互联网+”的政策背景和“共享经济”的市场推动下,共享单车作为一种新兴的出行方式,依靠智能定位技术、移动支付、无桩化随借随还的优势迅速成为市场的宠儿,对传统公共自行车系统产生了较大冲击,主要表现在车辆周转率下降和用户转移等问题。因此,提升其系统服务水平是维持公共自行车市场竞争力的重要手段。随着信息技术快速发展,公共自行车系统内贮存的海量数据成为运营服务水平提升的有效支撑。为加快大数据落地应用和解决单车租还难等问题,有必要通过现实数据资源对城市公共自行车系统时空需求特征进行探索,从宏观层面掌握区域内出行需求总体分布,以期为新阶段下优化设施配置提供决策依据;从落地层面建立站点级租还需求量预测模型,作为未来站点平衡调度的依据并推广应用于共享单车系统,为改善服务水平提供技术和理论支撑。
目前,公共自行车租还需求预测主要集中在系统整体需求和站点需求。高效且便于操作的回归模型是公共自行车系统整体需求预测的主流方法,其考虑了人口,经济和社会条件,节假日,天气和土地利用情况等重要的需求影响因素[1]。站点是公共自行车系统的基本单位,对站点的需求预测直接影响系统的规划、设计和调度。面向站点层面的需求预测研究,大多数采用影响因素分析法和时间序列预测法。Kaltenbrunner[2]等利用时间序列分析方法(如自回归滑动平均模型(ARMA))对站点需求进行预测。陈思浓[3]基于纽约市Citi Bike出行数据和历史逐小时天气数据,增加天气滞后影响变量,建立带误差的多因素回归模型(MFR-ARMA)。周敏[4]通过引入小波分析,基于BP 神经网络搭建公共自行车站点租还量预测模型,研究发现,DE-BP 神经网络在历史数据间隔为30 min 以内且具有相似性的公共自行车站点租还需求量预测问题上具有一定的推广性。以上研究本质上是考虑公共自行车站点自身特征,以及外部环境因素进行需求预测,但不同位置的站点因周边的用地性质呈现不同的属性特征,故还需要关注站点的功能,分析不同类型站点的自行车使用特性,基于站点周边的用地性质,对站点进行分类预测,为高峰期间的区域平衡调度奠定基础。
充分挖掘不同类型站点的自行车租还时空特性是提高预测准确性的前提。基于此,本文采用聚类算法将站点按照租还特性进行聚类分析。提出基于兴趣点(Point of Information, POI)数据的站点用地类型识别方法,构建以天气质量、时间特征、站点位置为特征变量,以60,30,15 min时间粒度的站点租还车需求为目标的随机森林模型,并利用宁波市公共自行车实际运行数据对模型进行验证。
1 公共自行车时空特性分析
1.1 站点需求时间特征聚类分析
城市公共自行车系统规模大、站点数目多,逐个分析效率低下且无法有效掌握各站点间的内在联系,以及不同类型站点的租还车规律,故采用KMeans[5]聚类算法对站点分类,利用DBI 指数(Davies-Bouldin Index)[6]确定最佳聚类结果,为站点需求预测提供基础。
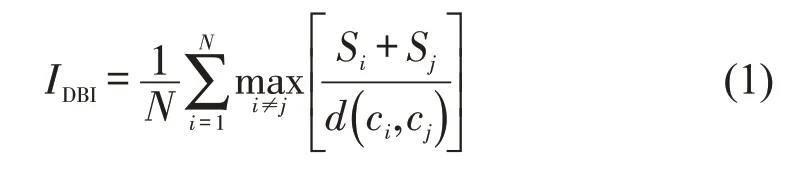
式中:IDBI为刻画不同种类之间离散程度和同一类内数据对象的紧密程度的综合型指标,其值越小,表示各类内对象相似度越高,类间的差异越大,聚类效果越佳;N为聚类个数;Si,Sj为第i,j类数据到其簇中心的平均距离;d()ci,cj类i与类j质心的距离;ci,cj为第i,j类的质心。
1.2 站点土地利用类型识别方法
站点的活跃度与城市用地功能息息相关。骑行者基于不同出行需求所引发的站点租还车特征通常由城市用地功能所致,而POI点的分布是城市用地功能的直观体现。本文利用百度地图API 获得宁波市区的POI 数据,共14 类,根据骑行用户对各类POI 的显著性认识来确定与POI 类型相关的土地利用类型。基于我国土地利用现状分类标准,结合相关研究成果[7],将宁波市公共自行车站点划分为住宅、交通设施、办公和商业休闲4 类。每类POI 权重的确定参考文献[8]中各类POI 公众认知度的调查结果,并着重考虑骑行者对各类POI的认知度进行权重调整。具体分析步骤如下:
(1)以公共自行车站点所在的地理位置为圆心,统计50 m(根据公共自行车换乘轨道交通车站的最大距离设定)半径范围内交通设施类POI 点的数量n1,若n1>0,则该站点为交通型。
(2)以公共自行车站点所在的地理位置为圆心,统计300 m(依据宁波市公共自行车服务半径设定)半径范围内除交通类其余各类POI点的数量。
(3)根据步骤(2)的统计结果,计算各站点300 m范围内各POI类型比例,即
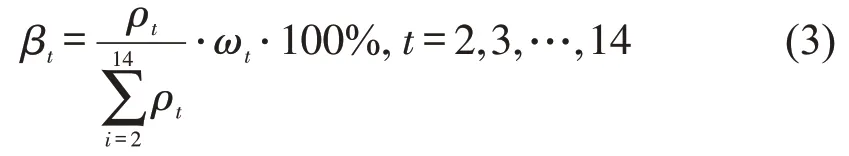
式中:t为POI类型;nt为300 m范围内第t种类型POI 数量;Nt为第t种类型POI 总数;ρt为300 m范围内第t种类型POI数量占该类型POI总数的比例;ωt为第t类POI 权重系数;βt为300 m 范围内第t类POI占比。
2 公共自行车站点需求预测分析
2.1 随机森林回归预测
基于站点的公共自行车租还量需求预测多采用基于时间序列的BP 神经网络方法,但本文数据量大且变量涉及离散和连续型数据,若采用BP 算法不仅运行效率低且容易出现过拟合现象。随机森林模型能够捕捉不同类型数据间的内在关系,适应性强,故本文采用随机森林模型预测站点租还车需求,其算法流程及原理可以参考文献[9]。
选择平均绝对误差(EMAE)、均方根误差(ERMSE)和拟合优度(ER2)这3个指标评估模型性能,计算公式分别为
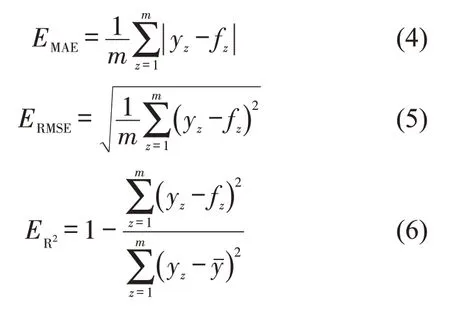
式中:yz为第z个样本的真实值;为真实值的平均值;fz为第z个样本的预测值;m为样本数。
2.2 特征变量的选择
公共自行车的需求量在不同时间呈现出规律性差异,故结合其变化的实际情况及预测目标,将每天5:00-22:00 按照15,30,60 min 的时间间隔进行站点的租还量需求预测。以30 min间隔为例,则1 d 分为34 个时间间隔,分别用1~34 表示,1 代表5:00-5:30,以此类推,34 代表21:30-22:00。本文选取预测因子包括:气象因子、时间特征和站点位置特征,表1为具体包含的特征变量。
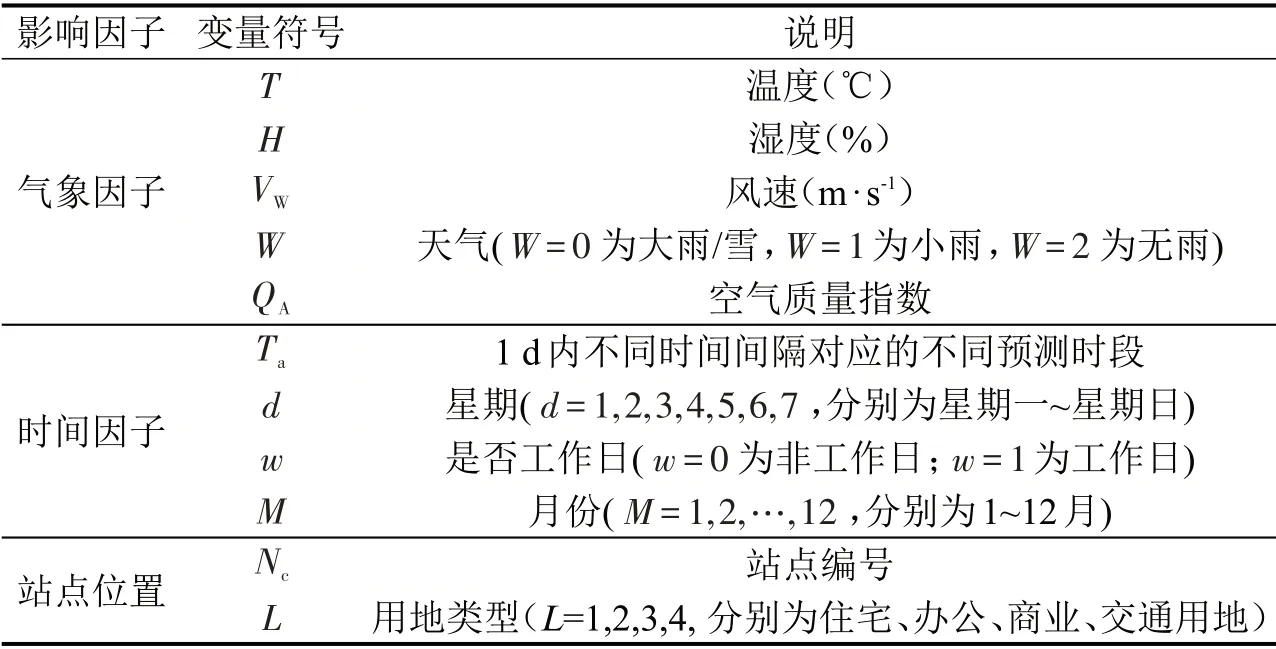
表1 变量描述Table 1 Variable description
3 案例分析
采用宁波市公共自行车系统2016年7月-2017年6月的IC 卡刷卡记录作为原始数据,共3336.39 万条有效骑行记录,研究区域为宁波市主城区范围。
3.1 基于租还时间特征的站点聚类分析
按照1.1 节的分析方法计算得到DBI 值如图1所示,当聚类数设为5时,对应的DBI值最小,聚类效果最佳。图2为不同类型的站点聚类分布,图3为不同类型站点的借/还系数时间分布情况。

图1 不同聚类数对应的DBI值Fig.1 DBI value corresponding to different cluster numbers
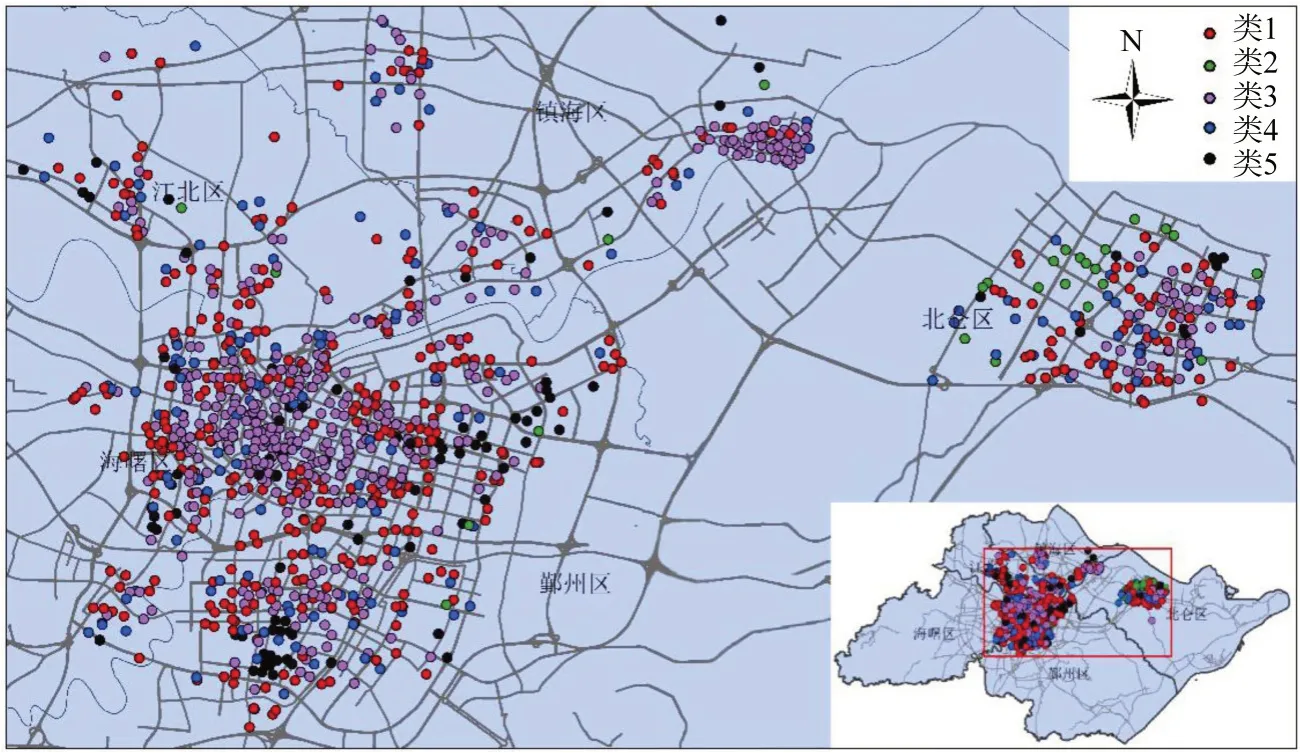
图2 站点聚类分布Fig.2 Cluster distribution of stations
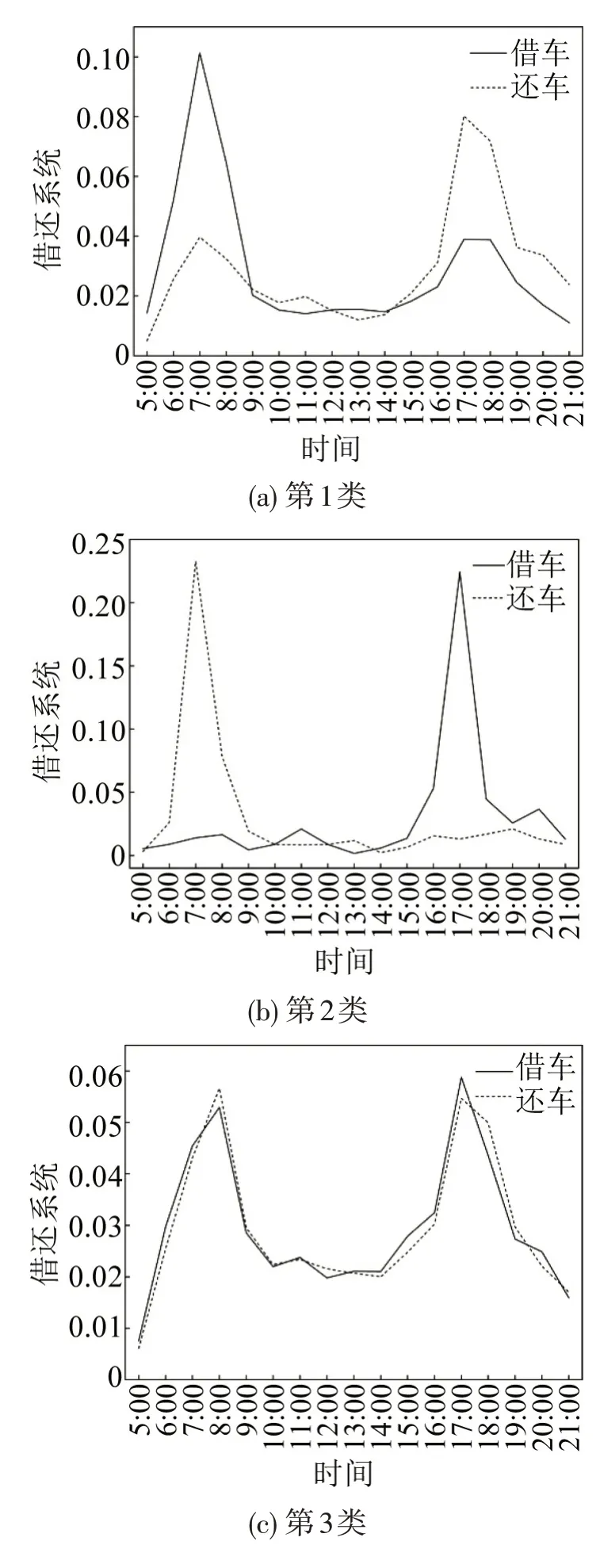
从图2和图3可以发现:第1 类站点共计368个,约占总数的33.67%,此类站点总体上均匀分布在宁波市外围区域,早、晚高峰期间站点借、还车量呈现明显的不均衡性。第2类站点共计26个,多分布于远离市区、较为偏僻的城市边缘地带,还车早高峰、借车晚高峰特征尤为明显。第3类站点共计450 个,约占总数的41.17%,主要分布于城市中心区;借、还系数曲线均呈现早晚高峰且互相良好吻合的特征,表明该类站点在早晚高峰期总体上能够达到租还平衡状态。第4 类站点共计159 个,该类站点聚类中心借/还系数随时间分布曲线均呈现早晚高峰特征。第5类站点共计90个,多分布于城市外围,少量位于市中心区,还车早高峰、借车晚高峰特征突出。
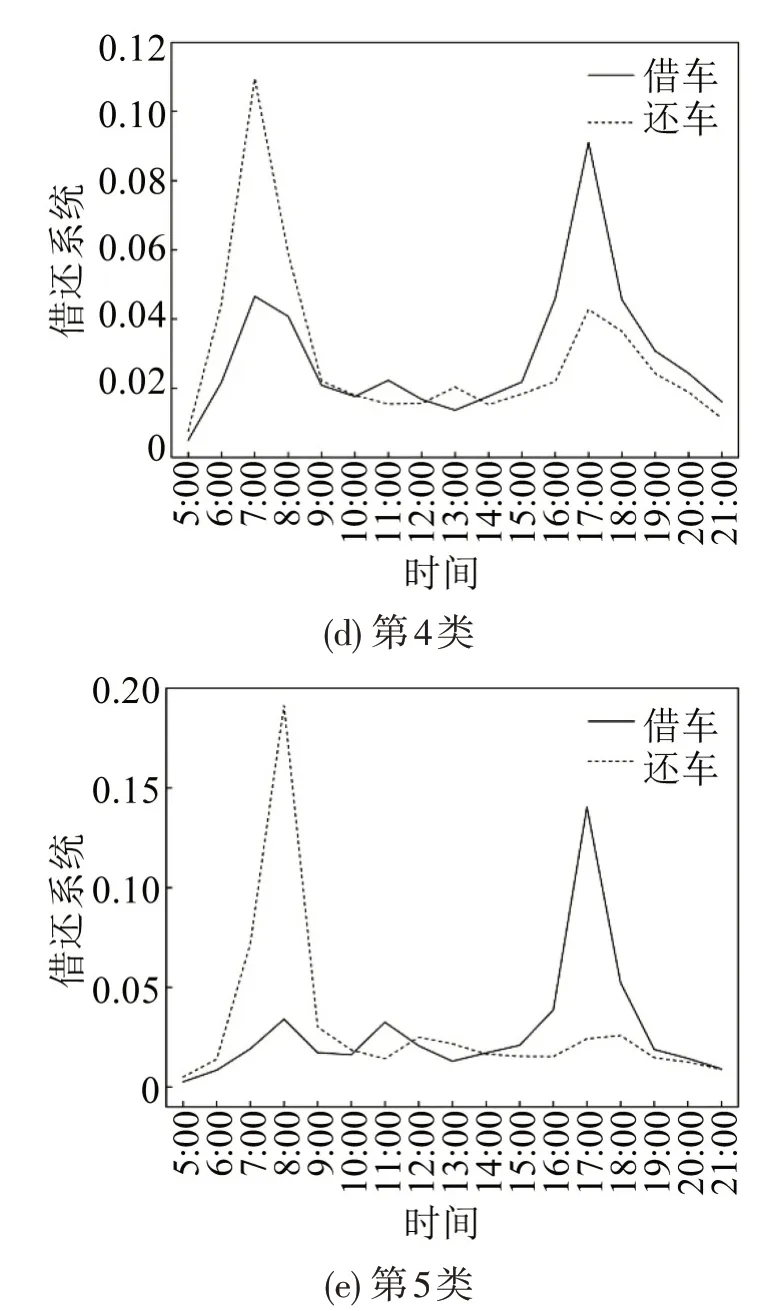
图3 不同类型站点聚类中心借/还系数时间分布图Fig.3 Time distribution of borrowing/returning coefficients of cluster centers of different types of sites
第5 类站点曲线特征与第2、4 类相近,但又存在明显差异。第3 类站点早晚高峰集中程度区别较大,第5 类站点还车早高峰有所滞后,这些差异的背后是不同出行行为所致,反映在空间上为站点所处城市功能区的差异,故需要进一步挖掘站点周边土地利用类型与自行车租还特性之间的关系。
3.2 基于POI数据的站点土地利用类型识别
图4为站点日租还总量核密度与百度POI核密度空间分布,站点活跃度与POI点密度之间存在一定的空间耦合性,表明站点使用度与POI密度存在一定的正相关,而POI类型往往是城市用地功能类别的象征。因此,通过挖掘站点周边土地利用类型有利于掌握该站点的使用规律特征。
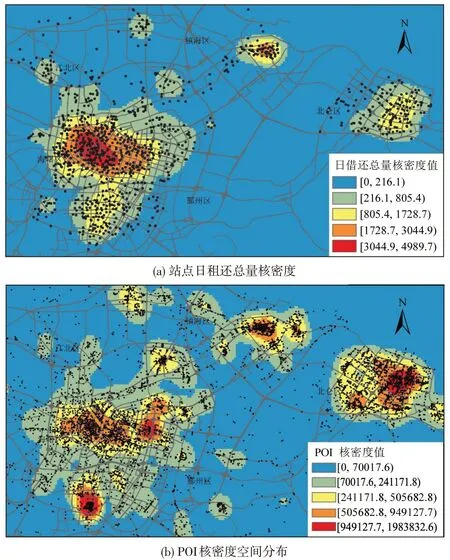
图4 站点日租还总量核密度与POI核密度空间分布图Fig.4 Spatial distribution of total daily borrowing and returning nuclear density and POI nuclear density of stations
根据1.2 节所述步骤,最终判断相应公共自行车站点的土地利用类型及POI 比例如表2所示。图5为宁波市不同用地类型的公共自行车站点分布图。图6为基于POI 数据识别的不同用地类型站点的租还车数量随时间分布图。从时间和空间角度观察可以发现,不同用地类型站点的租还车时间特性与前文基于站点租还时间特性聚类结果吻合度较高,从而验证了基于POI 数据站点方法的可靠性。

表2 基于POI数据的站点类型划分Table 2 Site type division based on POI data
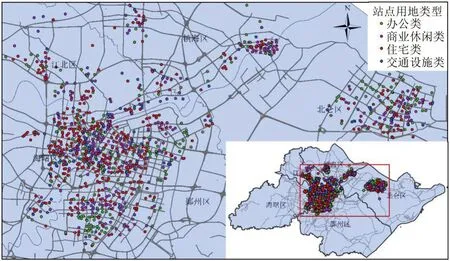
图5 不同用地类型的站点分布图Fig.5 Site distribution of different land use types

图6 不同用地类型站点租还车量随时间分布图Fig.6 Distribution of vehicle borrowing and returning volume with time at different land use types
3.3 站点租还需求预测
以宁波市自行车租还车需求量最大的东门口站点为例,提取1周的运营数据。将实验数据按照8∶1∶1划分为训练集、验证集和测试集,训练集用于模型学习训练,验证集用于模型参数调整,测试集用于模型性能评估。通过网格搜索和交叉验证的方法确定随机森林模型的参数组合,考虑到计算机运行效率和模型准确度,采用最大特征数为4,决策树为300 的参数组合构建模型。为验证随机森林模型的准确性,以站点借车需求为例,分别构建在不同时间刻度情况下随机森林和BP 神经网络、K最近邻的短时需求预测模型,表3为各模型的评价结果。
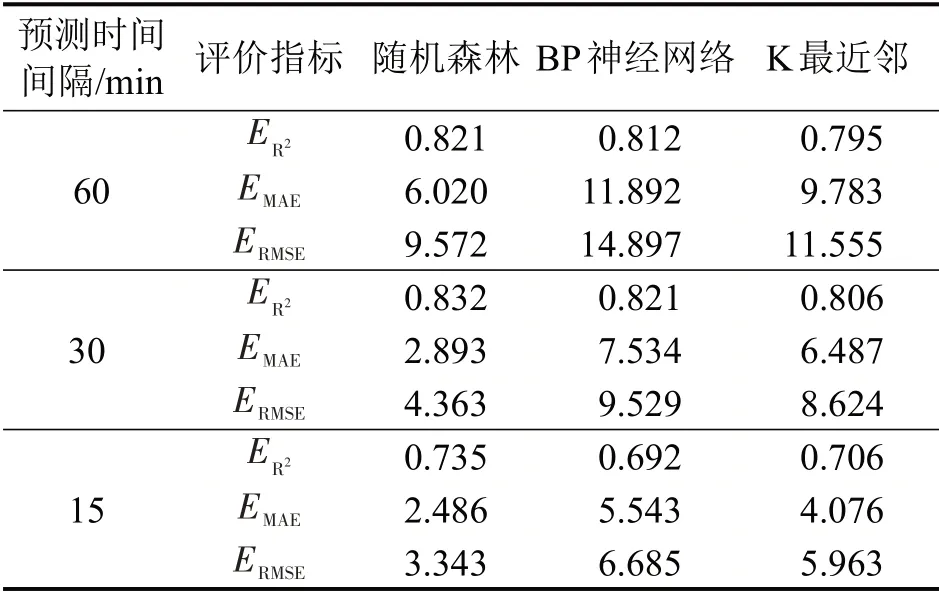
表3 不同模型预测精度比较Table 3 Comparison of prediction accuracy of different models
由表3可知:随机森林回归预测在所有时间间隔下的预测结果均好于其他算法,其拟合优度ER2在预测时间间隔为60 min、30 min 时均达到0.8 以上,说明模型拟合效果较好,预测准确度较高;15 min时间粒度预测模型的拟合优度有所降低,但其平均绝对误差(EMAE)、均方根误差(ERMSE)为各时间粒度模型中最小,分别达到2.48 和3.34,均在误差范围内,且以30 min为时间间隔的站点借车需求预测精度最高。
为验证考虑站点土地利用类型特征后,模型是否能提高预测精度,以30 min 为时间间隔,构建站点借车需求和还车需求随机森林预测模型。模型的评价效果如表4所示,预测结果如图7所示。可以发现:考虑站点土地利用类型特征变量后,租还车需求预测效果均有不同程度提升,说明土地利用类型是影响模型预测效果的重要特征之一;对于具体站点而言,其预测需求量和实际需求量非常接近,绝对误差多分布于-2.5~2.5之间。

表4 租还车需求预测精度比较Table 4 Comparison of forecasting accuracy of vehicle borrowing and returning demand
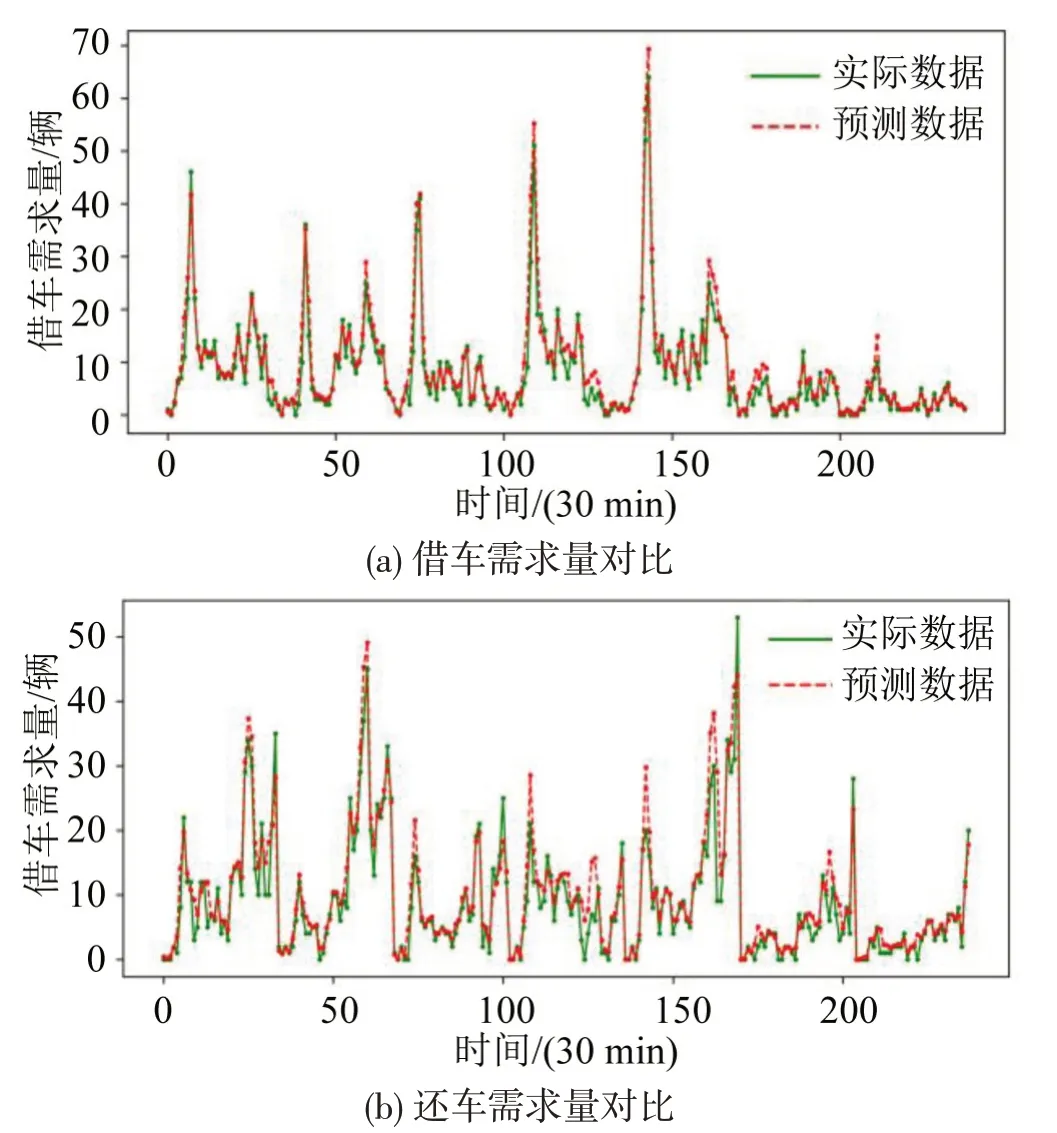
图7 东门口站点实际和预测租还车需求量对比图Fig.7 Comparison of actual and predicted demand for vehicle borrowing and returning at Dongmenkou station
4 结论
本文从时间特征的角度提出基于站点小时租还车系数的聚类方法;从空间特征的角度提出了基于POI数据的站点用地类型识别方法,并与租还时间特性聚类结果相互印证,验证方法的有效性。本文在对公共自行车使用时空特性挖掘的基础上,综合考虑站点的时间特征、天气因素、站点土地利用类型等数据,构建站点租还车需求预测的随机森林模型。以宁波市东门口站点为例对模型进行验证。结果表明:以30 min为间隔的站点租还车需求预测精度最高,考虑站点土地利用类型能有效提高模型预测精度,为改善服务水平提供技术和理论支撑,亦可服务于后期新一轮站点的布局规划。
猜你喜欢
吉林电力(2022年2期)2022-11-10 09:24:42
电子制作(2019年14期)2019-08-20 05:43:42
国际呼吸杂志(2019年1期)2019-01-28 09:37:02
自然资源情报(2017年4期)2017-11-26 07:51:42
中国自行车(2017年1期)2017-04-16 02:53:52
自动化学报(2017年1期)2017-03-11 17:31:10
故事会(2016年21期)2016-11-10 21:15:15
中国老区建设(2016年8期)2016-02-28 09:33:49
技术经济(2014年5期)2014-02-28 01:29:00
中国烟草学报(2012年4期)2012-04-09 07:11:52
