
基于相似历史信息迁移学习的进化优化框架
2021-04-24 12:33郝国生巩敦卫
自动化学报 2021年3期
张 勇 杨 康 郝国生 巩敦卫
进化优化是模拟生物进化行为和机制产生的一类迭代搜索算法,目前已广泛应用于模式识别、经济管理、电气工程和生物学等众多领域[1].典型进化优化技术包含遗传算法(Genetic algorithm,GA)、进化策略(Evolution strategy,ES) 和进化规划(Evolutionary programming,EP) 等.由于同样启发于生物进化行为,部分学者也将粒子群优化和蚁群优化等群体智能优化算法归为进化优化技术.该类算法都是从选定的初始种群出发,通过不断迭代更新种群中个体位置,直至搜索到最适合问题或任务的解.通常,这些算法所依赖的初始种群都是在问题可行域中生成的随机位置.换句话说,现有进化优化算法,如文献[2-8],都是从问题的零初始信息开始搜索,并没有考虑是否以前优化过类似问题,是否可以从历史信息中获得解决当前相似问题的能力.例如,在车间调度问题中,当前月份的生成任务可能与往年某一月份的任务相同或相似.在利用进化优化寻找当前月份最佳调度序列时,如果能够充分利用相似任务的历史信息,势必可以提高其搜索能力.
迁移学习(Transfer learning) 是一种人性化的机器学习方法,其目的是把一个领域(即源领域) 的知识迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果,即使用以前解决相似任务时获得的信息来帮助解决新问题[9].目前迁移学习已广泛应用于图形识别、文本分类、网页分类等诸多问题[10-15].但是,将迁移学习应用于进化优化中,相关研究仍然很少.Dinh 等[16]和Ko¸cer等[17]在使用遗传算法处理源域任务时,保存得到的最优、中等和最差等个体;当处理新的目标任务时,迁移这些个体并随机代替初始种群中的部分个体;Feng 等[18]将迁移学习融合到进化优化中,提出了一种新的文化基因进化框架;最近,Jiang 等[19]成功地将迁移学习用于解决动态多目标优化问题,显著提高了进化优化算法对环境变化的响应速度.
上述方法的成功应用充分说明了利用迁移学习提高进化算法性能的可行性.然而,相关研究起步较晚,仍然存在如下不足或可改进之处:1) 在构造迁移学习的源域样本时,已有工作仅保存种群中最优、中等或者最差的个体,没有考虑所保存个体的多样性.受益于进化优化的优胜劣汰机制,种群中的所有个体往往会收敛到搜索空间中的一个点或一个很小的区域.此时,种群中的最优、中等和最差可能十分相似.在源域中保存诸多相似的个体,不免造成样本空间分布的过拟合现象.2) 现有工作大都假设源域和目标域已经相似或匹配,并未给出源域和目标域相似性或匹配程度的判断标准.通常决策者可以获得的相似历史问题或任务往往较多,如何从众多的历史问题或任务中选出最为相似的一个,将直接影响到迁移学习的效果;相反,当源域问题和目标域问题完全不同时,强制迁移可能会污染目标域,产生负面的影响[20].3) 由源域到目标域的知识迁移方法研究不够.文献[16-17]将源域中保存的个体样本直接替代目标问题的初始种群,没有考虑源问题与目标问题之间的差异性.尽管文献[18-19]所设计的知识迁移方法考虑了历史问题与目标问题之间的差异性(或映射关系),但其所得成果皆立足于车辆路径规划和动态多目标优化问题的自身特点,难以用于本文考虑的静态全局优化问题.
鉴于此,本文研究一种基于历史相似信息迁移学习的进化优化框架,用以解决复杂优化问题.针对某一待处理的新问题,该方法首先从模型库中找到与其最为匹配的历史模型;接着,从历史模型对应的源域知识中提取有用信息,构建源域到目标域的映射关系,并基于该映射关系产生新问题下进化算法的初始种群.本文主要工作如下:1) 提出一种基于多分布估计的最大均值差异指标,用来评价新问题与历史问题之间的相似程度;2) 基于模型的相似程度,给出一种(历史问题对应的) 源域到(待优化问题对应的) 目标域的自适应知识迁移策略,初始化当前进化种群中的部分个体,加快进化算法的搜索速度;3)为不断更新和丰富历史模型库,给出一种基于迭代聚类的代表个体保存策略,形成源域的样本集合,同时保证个体样本的多样性和质量;4) 将自适应骨干粒子群优化算法嵌入到所提框架,给出一种基于相似历史信息迁移学习的骨干粒子群优化算法.
本文结构如下:第1 节介绍相关工作,包括迁移学习和粒子群优化的基本理论;第2 节给出所提基于历史相似信息迁移学习的进化优化框架,以及基于迁移学习的改进粒子群优化算法;第3 节给出相应的对比实验,验证算法的有效性;第4 节对本文工作进行总结.
1 相关工作
1.1 粒子群优化算法
粒子群优化(Particle swarm optimization,PSO)[21]算法是一种仿生物群体觅食行为的全局随机搜索算法.在求解优化问题时,每个粒子通过记忆和追随两个最优位置,来不断更新自身的位置[22].一个是该粒子到目前为止自己发现的最好位置Pbest=(pbesti,1,pbesti,2,···,pbesti,N),即通常所说的粒子个体最优点或局部引导者;另一个是目前为止邻域粒子发现的最好位置Gbesti=(gbesti,1,gbesti,2,···,gbesti,N),即通常所说的粒子的全局最优点或全局引导者.设粒子i在N维空间的位置为矢量XXXi=(xi,1,xi,2,···,xi,N),飞行速度为矢量VVV i=(vi,1,vi,2,···,vi,N),该粒子位置更新式为
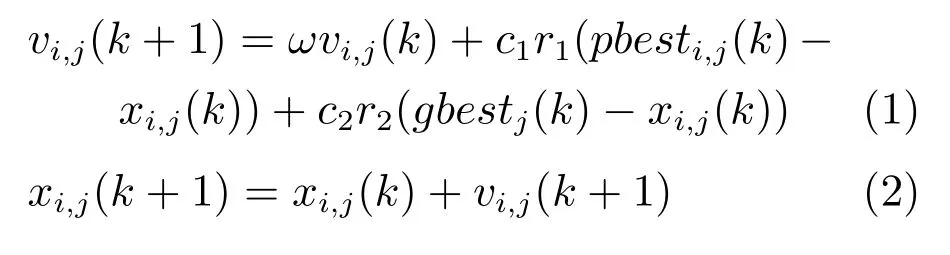
其中,k为算法迭代次数,ω为惯性权重,c1和c2为学习因子,r1和r2为服从均匀分布U(0,1) 的随机数.
1.2 迁移学习
迁移学习主要包含域和任务两个概念[23-24].通常,域可以表示为D={Z,Pob(Z)},即特征空间Z和特征空间的边缘分布Pob(Z).在给定一个域D={Z,Pob(Z)}的情况下,一个任务可以表示为T={Y,f(·)},即标签空间Y和一个目标预测函数f(·).考虑存在一个源域Ds和一个目标域Dt的情况,不妨设源域Ds={(zs,1,ys,1),(zs,2,ys,2),···,(zs,ns,ys,ns)},zs,j ∈Zs表示源域样本,ys,j ∈Ys表示源域样本zs,j对应的标签.目标域Dt={(zt,1,yt,1),(zt,2,yt,2),···,(zt,ns,yt,nt)},zt,j ∈Zt表示目标域样本,yt,j ∈Yt表示目标域样本zt,j对应的输出.基于以上的符号定义,迁移学习的目的是:在给定源域Ds和源域学习任务Ts、目标域Dt和目标域任务Tt,且满足DtDs和Tt Ts的情况下,通过迁移学习使用源域Ds和Ts中的知识,提升或优化目标域Dt中目标预测函数f(·) 的学习效果[9].史数据的利用和模型库的更新.针对上述三个关键算子,下面分别给出详细解决方案.
2 基于历史相似信息迁移学习的进化优化框架
现有进化优化算法大都从给定问题的零初始信息开始,随机产生初始种群,并通过迭代搜索找到问题的最优解.为充分利用相似问题的历史信息,本节提出一种基于迁移学习的进化优化框架,如图1 所示.在图1 中,模型库(Model library,ML) 保存着进化优化算法所解决过的相似历史问题信息.该模型库保存的信息单元是mli=(fi,),其中,fi和分别为所保存的第i个历史问题及其最优解集信息.由于需要利用历史问题的解信息来指导新问题的求解,因此,模型库中保存的历史问题应该与待求解问题属于同一种(类) 问题,两者应该具有相似的编解码策略和问题特征.
当决策者获得一个新的优化问题时,首先,对模型库进行预处理,分析并判断每个历史问题是否与新问题具有相似的编解码策略和特征,并删除不相似和相似程度低的历史问题;接着,利用模型匹配方法匹配模型库中的信息,计算新问题与模型库中已有历史问题的相似度;找到匹配程度最高的历史优化问题,获取其历史数据,并将历史问题的高质量解迁移到新问题的进化过程中,用来初始化新问题进化种群中的部分个体;若没有与之匹配的历史优化问题,则直接使用进化算法求解优化问题.在优化当前新问题时,将问题求解过程中得到的代表信息存储到模型库中,如此循环,随着所解决问题数目的不断加入,模型库不断增大,进而有助于解决更多的优化问题.分析上述进化优化框架可知,该框架存在如下三部分直接影响其最终性能,即模型匹配、相似历
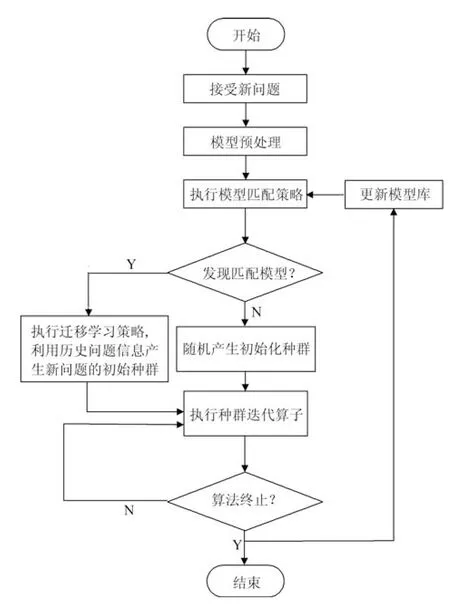
图1 所提基于迁移学习的进化算法框架Fig.1 Evolutionary algorithm framework based on transfer learning
2.1 基于多分布估计的模型匹配策略
将模型库中保存的历史问题信息作为源域知识,待解决的新问题看作目标域任务,本文旨在利用已知源域知识去求解目标域中的新问题.通常源域模型库中存有的历史问题或任务较多,如果历史问题模型和目标域中新问题的相似度较低或完全不同时,强制迁移可能会污染目标域,产生负迁移现象.因此,如何准确判断源域和目标域中问题的相似程度,从众多的历史问题或任务中选出最为相似的一个,将直接影响到目标域优化问题的求解效率.
最大均值差异(Maximum mean discrepancy,MMD) 是一种用来判断两个数据分布是否相同的指标,最初主要用于双样本的检测问题.近些年,学者们开始将其用于迁移学习中,利用源域数据集和目标域数据集的均值差来表示源域和目标域样本之间的分布差异[25].MMD 的基本原理如下:假设有一个满足Q1分布的源域数据集和一个满足Q2分布的目标域数据集Xt=令H为再生希尔伯特空间(Reproducing kernel Hilbert space,RKHS),并且存在一个从原始空间到希尔伯特空间的映射函数F(·) :X →H,那么,当n和m趋于无穷时,Xs和Xt在RKHS 上的最大均值差异可以表示为
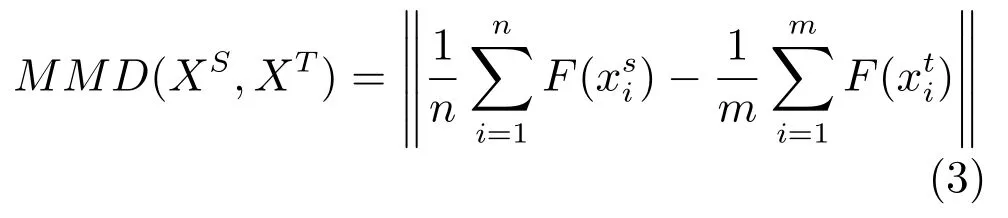
然而,不同于传统意义上的采样数据(如传感器数据、图像数据等),对于进化种群产生的源域或目标域样本而言,由于所优化问题通常包含若干个峰值,此时将源域或目标域中所有样本看成服从同一分布的整体,并采用MMD 判断源域和目标域问题的相似性,将很难准确评价出它们的相似程度.
鉴于此,本文提出一种基于多分布估计的最大均值差异指标,用来评价新问题与历史问题之间的匹配程度,思想如下:首先,采用K-means 算法对源域和目标域中样本分别进行聚类,并假设聚类后每一类中的样本服从同一分布(注:传统方法假设源域(目标域) 中所有样本服从同一分布);随后,针对目标域中的每一类,从源域中找到与其最为匹配的类,即MMD 值最小的类;最后,利用目标域中所有样本类的MMD 值的平均值,作为源域和目标域样本的整体相似性程度.


算法1.模型匹配策略

步骤4.2 利用目标域中所有样本类的最大均值差异的平均值,表示源域和目标域的整体相似性程度.该平均值越小,源域和目标域中样本的分布越相似,进而历史问题和新问题越相似.循环执行步骤2~4,直到计算出新问题与所有历史问题相似程度值.最后,步骤5 选择相似程度值最高(即最大均值差异的平均值最小) 的历史问题,作为最终匹配结果.注意:当源域和目标域样本数据具有不同的量纲时,需要对这些样本进行归一化.式(4) 中映射函数选择最为简单的单位映射.
本文通过运行一定迭代次数(Tlow) 的智能优化算法产生目标样本.一方面,对于不同规模、不同操作流程的算法来说,它们通常具有不同的求解速度;另一方面,求解问题的复杂程度也对算法的迭代效率产生较大影响.因此,很难准确估计出可以产生高质量样本(即可以高精度刻画出问题解分布特性的个体) 的迭代次数.算法1 利用少量迭代后的种群进化结果作为目标域样本,具有如下特点:1) 执行少量迭代次数后,种群中的部分个体会接近多个最优区域,而不会集中收敛到某个最优区域,此时的种群样本不仅具有较好的适应值,而且多样性相对较高;相反,如果迭代次数设置过大,在很大程度上种群中的大部分个体会集中收敛到某个最优区域,此时的种群样本虽然具有较好的适应值,但其多样性相对较差.2) 尽管通过加大种群的迭代次数,可以找到更为接近问题最优解的样本,但是,需要付出的计算代价也会随之增加.更重要的是,在很多情况下,只需要找到较为接近问题最优解的样本,即可判断出两个问题的相似性.因此,在满足样本基本需要的基础上,所提目标域样本产生方法还可以显著减少样本的产生代价.
关于算法1 中迭代次数Tlow,一方面,由于无法事先判断不同智能算法处理不同问题时的迭代速度与精度,很难给出适合所有算法的固定Tlow值;另一方面,如前所述,在很多情况下只需要找到较为接近问题最优解的样本,即可估计出两个问题的相似性.因此,在一定程度上,可以放松对迭代次数Tlow取值的要求,本文建议Tlow取值为最大迭代次数的[1%,5%].具体而言,对于收敛速度较快的智能算法,可以取值为上述区间的下限值;相反,针对收敛速度较慢的智能算法,可以取值为上述区间的上限值.
2.2 源域匹配信息的利用
为加快进化算法的搜索速度,给出一种基于源域匹配信息的种群初始化策略.当从源域中找到与目标域问题相匹配的历史问题后,迁移源域中相似历史问题的信息(解集信息),用其生成新个体,并利用这些新个体替换目标域中进化种群的部分个体;为了增加种群多样性、防止出现过迁移和欠迁移现象,根据历史问题与新问题的相似度自动设置替换初始种群的比例,即种群中被初始化个体的比例,具体计算式为
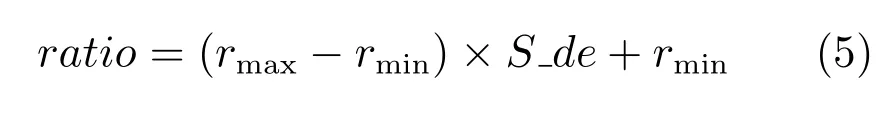

算法2.基于源域匹配信息的种群初始化策略

2.3 历史模型库的更新
对于已经解决的历史问题,保留求解问题过程中产生的历史解信息,用于模型库的更新.由于种群的进化过程通常产生大量个体信息,保存所有个体信息代价较大.更为重要的是,这些个体信息中可能存在大量低价值甚至冗余的信息.
为此,本文给出一种基于迭代聚类的代表个体保存策略.该策略采用一种简化的迭代K-means 算法,选择种群迭代过程中产生的适应值高且多样性好的代表解集.进一步,为减少模型库更新的计算代价,设定一个更新频率0≤μ ≤1,每间隔「μ ×Tmax代采样一次种群进化信息,用来更新所保存的代表个体.针对当前优化问题,基于迭代聚类的代表个体保存策略的步骤如下.
步骤1.初始化代表个体保存集合,以及初始类半径.对第Tlow次迭代产生的种群,使用K-means算法(在决策变量空间中) 对其个体进行聚类,将其划分到ck个不同类中;从每一个类中选出适应值最好的个体(即目标函数值最小的个体),保存到代表个体保存集合.计算集合中个体之间的两两距离,取距离最小值为初始类半径.
步骤2.每间隔max代采样一次种群进化信息,更新代表个体保存集合中的元素(解) 及类半径,直到算法结束.以某次更新为例,设现有代表个体集合为A={a1,a2,···,ack},类半径为r′,当前种群为P={p1,p2,···,pN},从P中第1 个个体起,依次检查它与集合A中元素的位置和优劣关系,由下述策略更新A中元素,直到检查完种群中所有N个个体.以P中第i个个体pi为例,更新策略如下:先计算个体pi与集合A中每个元素之间的距离,从A中找到距离pi最近的元素,不妨设为amin,记两者距离为d(pi,amin);接着,判断两者之间的位置和优劣关系:1) 如果d(pi,amin)≤r′且pi的适应值优于amin的适应值(即pi的目标函数值小于amin的目标函数值),那么利用pi代替A中元素amin;2)d(pi,amin)≤r′,但pi的适应值劣于amin的适应值(即pi的目标函数值大于amin的目标函数值),保持A中元素amin;3) 如果d(pi,amin)>r′,且pi的适应值优于A中最差元素的适应值(即pi的目标函数值小于A中最差元素的目标函数值),那么,利用pi替换A中最差元素;4) 否则,删除pi,保持A中元素不变.最后,计算集合A中个体之间的两两距离,取距离最小值为新的类半径.
一方面,上述方法采用K-means 思想来更新代表解集,可以保持所选代表个体的多样性;另一方面,当新个体与A中某个元素同属一个类时,只保留适应值大的个体或元素,这样可以保证所选代表个体具有高的适应值.另外,除在开始阶段采用传统K-means 算法来产生初始化代表个体外,在后续更新A中元素时,上述方法采用简化的K-means 算法,无需反复更新类中心,可以有效减少模型库更新的计算复杂度.
2.4 基于相似历史信息迁移的骨干粒子群优化算法
为了进一步说明所提进化优化框架的有效性,将一种改进的骨干粒子群优化算法(Bare-bone PSO,BBPSO)[26]嵌入到所提框架,给出一种基于相似历史信息迁移的骨干粒子群优化算法(Adaptive bare-bone particle swarm optimization based on transfer learning,TL-ABPSO).骨干粒子群优化算法(BBPSO) 是一种改进版本的粒子群优化算法[27].与采用更新式(1) 和式(2) 的传统粒子群优化算法相比,BBPSO 删除了粒子速度项、加速系数、惯性权值等控制参数,是一种少控制参数的新型粒子群优化算法,算法结构更为简单,更加易于操作.然而,由于删除了粒子速度项,BBPSO 算法存在易于陷入局部收敛的不足[27-28].为此,在先前工作中作者提出了一种改进BBPSO 算法,即自适应骨干粒子群算法(Adaptive bare-bone PSO,ABPSO)[26].该算法利用当前粒子Xi与最佳粒子Gbest之间适应值的差值,自适应扰动新生粒子位置,显著提高了算法的全局搜索能力.以粒子Xi=(xi,1,xi,2,···,xi,N) 为例,ABPSO 所提粒子位置更新式为


其中,rand为[0,1]之间的随机数,Pbestn1(t) 和Pbestn2(t) 为随机选择的两个粒子的局部引导者;同上,Pbesti(t) 和Gbest(t) 分别为当前粒子的局部和全局引导者,ft为目标域中被优化的新问题.
鉴于ABPSO 具有控制参数少、全局搜索能力强的优点,本文将其嵌入到上述所提进化框架,算法3 给出了基于相似历史信息迁移的改进骨干粒子群优化算法的执行步骤.对于一个新的优化问题,首先随机初始化粒子群,运行Tlow代ABPSO,产生一个目标域样本;接着,利用第2.1 节方法从模型库中寻找相匹配的历史问题.如果发现匹配模型,利用第2.2 节方法迁移源域中相似历史问题的信息,初始化第Tlow代粒子群中部分粒子的位置,继续执行ABPSO 相关算子,更新粒子位置;否则,直接执行ABPSO 相关算子.在算法迭代过程中,每间隔「μ×Tmax代运行一次第2.3 节方法,产生问题的代表个体集合.所提算法结束后,将被优化问题及算法输出的最终代表个体集合保存到模型库中.
算法3.基于相似历史信息迁移的骨干粒子群优化算法
输入.模型库ML,粒子群规模N,代表个体集合的更新频率μ,进化代数Tlow,算法终止代数Tmax,聚类数目ck.
输出.问题最优解,模型库.
步骤1.初始化.随机初始化规模N的粒子群,初始化每个粒子的局部引导者为其自身;评价每个粒子的适应值,设置所有粒子的全局引导者为种群最优粒子的位置;初始化迭代次数为k=1.
步骤2.产生目标域样本.运行Tlow代ABPSO,得到粒子群P(Tlow),利用P(Tlow) 中粒子产生目标域样本.
步骤3.利用第2.1 节方法从模型库ML中寻找相匹配的历史问题.如果发现相匹配的历史问题,执行步骤4;否则,执行步骤5.
步骤4.执行第2.2 节方法,初始化P(Tlow) 中个随机粒子的位置.
步骤5.k=Tlow,循环执行ABPSO 中相关粒子更新算子,不断更新粒子群,方法如下:
步骤5.1.评价粒子群P(k) 中所有粒子的适应值;
步骤5.2.判断Tmax/「μ×Tmax是否为整数.如果是,利用第2.3 节方法更新代表个体保存集合;否则,执行步骤5.3;
步骤5.3.采用常规方法更新粒子的局部引导者和全局引导者,具体更新方法可参加文献[29];
步骤5.4.利用式(8) 更新粒子的位置;
步骤5.5.判断算法是否得到终止代数Tmax.如果是,终止算法;否则,k=k+1,返回步骤5.2.
步骤6.输出问题的最优解,以及代表个体保存集合.
2.5 进一步分析
将迁移学习的思想融入到进化优化框架,从已解决的相似历史问题中提取有价值的历史信息,用来指导新问题的进化求解,上述进化框架可以加速种群的进化过程,提高算法的搜索效率.具体地,1)在利用相似历史问题的迁移信息来初始化种群个体时,本文根据历史问题与新问题的相似程度,自适应确定迁移信息的使用程度,即种群中被迁移信息初始化的个体比例,可以有效防止出现负迁移或过迁移的现象,避免算法性能的退化;2)在更新和丰富历史模型库时,所给出的基于迭代聚类的代表样本保存策略,在保证历史样本质量的同时,还可以增强它们的多样性,进而能够提高历史迁移信息的多样性,防止对单一历史信息的过度学习;3) 由于历史迁移信息仅用来初始化种群中的部分个体,且初始化比例受新旧问题相似程度的严格限制,因此,在第3.4节中自适应变异因子Δ,以及粒子全局引导者更新策略的作用下,本文所提TL-ABPSO 算法仍然能够以概率1 收敛.具体收敛性证明,可参考我们先前的工作[26].
3 实验分析
3.1 实验环境及测试函数
本节将所提TL-ABPSO 算法用于10 个改进的标准测试函数,与包括ABPSO 在内的4 种代表算法进行比较,验证其性能.所用对比算法包括:标准的PSO 算法(Standard particle swarm optimization,SPSO)、基于突变和交叉的改进骨干PSO 算法(Bare-bone particle swarm optimization with mutation and crossover,BBPSO-MC)[30]、基于跳跃策略的骨干PSO 算法(Bare-bone particle swarm optimization with jump,BBJ)[31]以及自适应骨干PSO 算法(ABPSO)[26].所用实验采用相同环境,即Intel Core(TM)2 Duo、2.80 GHz 的CPU、2.00 GB RAM 存储.
采用MATLAB 2014b 实现所提算法,并构建模型库.表1 展示了模型库中存储的5 个经典历史测试函数.首先,针对表1 给出的基本测试函数,运行文献[31]所提BBJ 算法,并采用第2.3 节方法保存迭代过程中适应值高且多样性好的代表解,产生初始模型库信息.表2 给出了需要求解的10 个新的问题.这些新问题皆是表1 中函数的变形,在处理这些新优化问题时,同样采用第2.3 节方法将新问题的求解信息保存到模型库中.表2 中测试函数可分为两组,其中,F1~F5 为第1 组函数,该组函数在不改变测试函数的特点基础上,对函数的参数进行调整,使其全局最优值发生变化.F6~F10 为第2 组函数,该组函数直接选自CEC2005 测试集合[32],在整个搜索空间内,其全局最优值被任意移动,具有旋转、漂移和多模态等特点.

表1 源域中保存的历史优化函数Table 1 Historical optimization functions saved in the source domain

表2 目标域中新的优化函数Table 2 New optimization functions in the target domain
3.2 评价标准及参数设置
本文采用三种不同的评价指标,分别从成功率、收敛速度和精度方面来评价算法的有效性.
1) 成功率(SR).即算法找到全局最优解的次数与实验总次数的比值.当算法所得最优解与真实最优解误差达到ε时,即认为算法成功找到全局最优解,其具体计算式为

其中,Sn′为算法找到全局最优解的次数,Sn为实验总次数,本文取30 次.
2) 收敛速度(Time).算法的收敛速度由两部分组成:a) 算法找到问题全局最优解时所需要的平均评价次数Fave;b) 算法找到问题全局最优解时所需要的平均时间(算法达到最大迭代次数时的平均运行时间)Time.
算法找到问题全局最优解时所需要的平均评价次数,计算式为
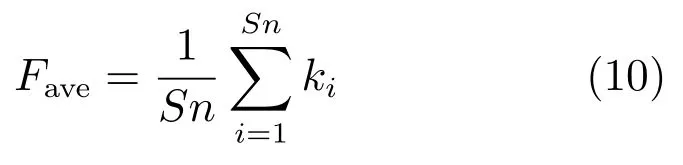
其中,Sn为实验总次数,ki为第i次运行算法时找到全局最优解的代数.
3) 精度(AC).算法所得全局最优解与函数真实最优解之间的误差,计算式为
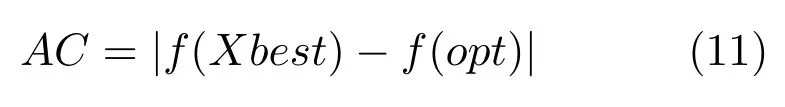
其中,Xbest为算法找到的全局最优解,opt为优化函数的真实最优解.当两者差值的绝对值小于误差值ε时,表示算法已经找到函数的真实最优值.
本文的参数设置如下:实验中的所有算法,其种群或粒子群的规模为30,算法的最大评价次数为30 000 次.其他对比算法的参数设置参照相应文献,其中,SPSO 算法的惯性权重从0.9 线性递减0.4;BBJ 算法采用全局邻域,其尺度参数设为α=0.75;BBPSO-MC 算法中,其邻域大小为2;ABPSO 算法中,突变概率为0.7;本文算法TL-ABPSO 中,聚类数目ck取为5.为便于比较算法的收敛速度,对于函数F8 和F9,设置成功误差ε分别为100和10-3,其他函数皆设置误差ε为10-8.
3.3 实验结果分析
3.3.1 第1 组测试函数的实验结果分析
1)对于比较简单的单模态优化问题F1,SPSO、ABPSO 和TL-ABPSO 算法均能以100% 的成功率找到其全局最优解,BBPSO-MC 和BBJ 算法的误差精度也在很小的范围之内.但是,通过比较Fave指标可以看出,得益于所迁移相似历史问题信息的帮助,本文算法TL-ABPSO 的收敛速度更快,其平均收敛代数为1.574×103,其他四种比较算法的最小迭代次数为2.635×103.
2) F2~F4 函数是多模态问题,随着决策变量维数的增加,函数局部最优解的数量呈指数增加.由表3 可知,对于函数F2,只有本文算法TL-ABPSO以100% 的成功率收敛到全局最优点;对于函数F3和F4,只有ABPSO 和TL-ABPSO 算法的成功率是100%;与其他四种比较算法的Fave指标相比,TL-ABPSO 算法明显优于其他四种算法.
3) F5 函数是一个单峰函数,决策变量之间具有很强的相关性,且梯度信息经常误导算法的搜索方向.如表3 所示,所有算法均没有成功找到全局最优解,但是,比较算法的精度误差指标AC可知,ABPSO 和TL-ABPSO 算法明显好于其他三种算法.这其中得益于本文采用的历史问题迁移学习策略,TL-ABPSO 算法精度又好于ABPSO 算法.
4) 在算法运行时间方面,由于增加了模型匹配等测试,在相同迭代次数下,本文算法TL-ABPSO的运算时间要高于其他四种比较算法,如函数F5;然而,通过剩余4 个函数的运行结果可以看出,由于显著缩短了种群找到最优解的迭代次数,TLABPSO 找到最优解的时间花费并不比其他算法高;对于函数F3 和F4,TL-ABPSO 甚至取得了最小的时间花费值.好于其他三种算法,其中得益于本文所采用历史迁移学习策略,TL-ABPSO 算法的精度又好于ABPSO 算法.
3.3.2 第2 组测试函数实验结果分析
针对表2 中F6~F10 等5 个复杂测试函数,分别运行每种比较算法30 次,表4 给出了本文算法TL-ABPSO、SPSO、ABPSO、BBPSO-MC 和BBJ 等所得评价指标的平均结果.可以看出:
1) 对于相对简单的函数F6,SPSO、ABPSO、TL-ABPSO 算法都能以100% 的成功率找到它们的全局最优解;但是,通过比较Fave指标可以看出,得益于所迁移相似历史问题信息的帮助,本文算法TL-ABPSO 的收敛速度更快,其平均收敛代数为1.421×102,其他四种比较算法的最小迭代次数为1.065×102.
2) 对于函数F7,ABPSO 和TL-ABPSO 的成功率分别为72% 和100%,高于BBPSO-MC 和BBJ 的成功率(33.33% 和50%);进一步,得益于本文所采用的历史问题迁移学习策略,TL-ABPSO算法的收敛速度明显好于ABPSO 的收敛速度,TLABPSO 算法找到问题全局最优解时所需要的平均评价次数(即Fave指标) 为7.467×103.
3) 对于函数F8 而言,五种算法均没有100%地找到其全局最优解,其中,TL-ABPSO 算法的成功率最高,为63.33%;进一步,比较ABPSO 和TLABPSO 算法的结果,类似于函数F7,TL-ABPSO算法的收敛速度好于ABPSO 的收敛速度,且TLABPSO 算法的误差指标AC高于ABPSO 算法.
4) 对于具有多模、旋转和不可分离等特点的复杂函数F9 和F10,五种算法均没有成功地找到其全局最优解;五种算法的成功率都是0;但是,比较其精度误差指标AC可知,ABPSO 和TL-ABPSO算法明显好于其他三种算法,其中,得益于本文所采用历史迁移学习策略,TL-ABPSO 算法的精度又好于ABPSO 算法.
5) 对于复杂函数F8~F10,在相同迭代次数下,尽管本文算法TL-ABPSO 的运算时间要高于其他四种比较算法,但是,其结果的精度皆优于其他四种比较算法;SPSO 算法的运算时间最短,但其运行结果的精度较差.对于函数F6 和F7,由于显著缩短了种群找到最优解的迭代次数,本文算法TL-ABPSO找到最优解的时间花费要小于其他四种比较算法.
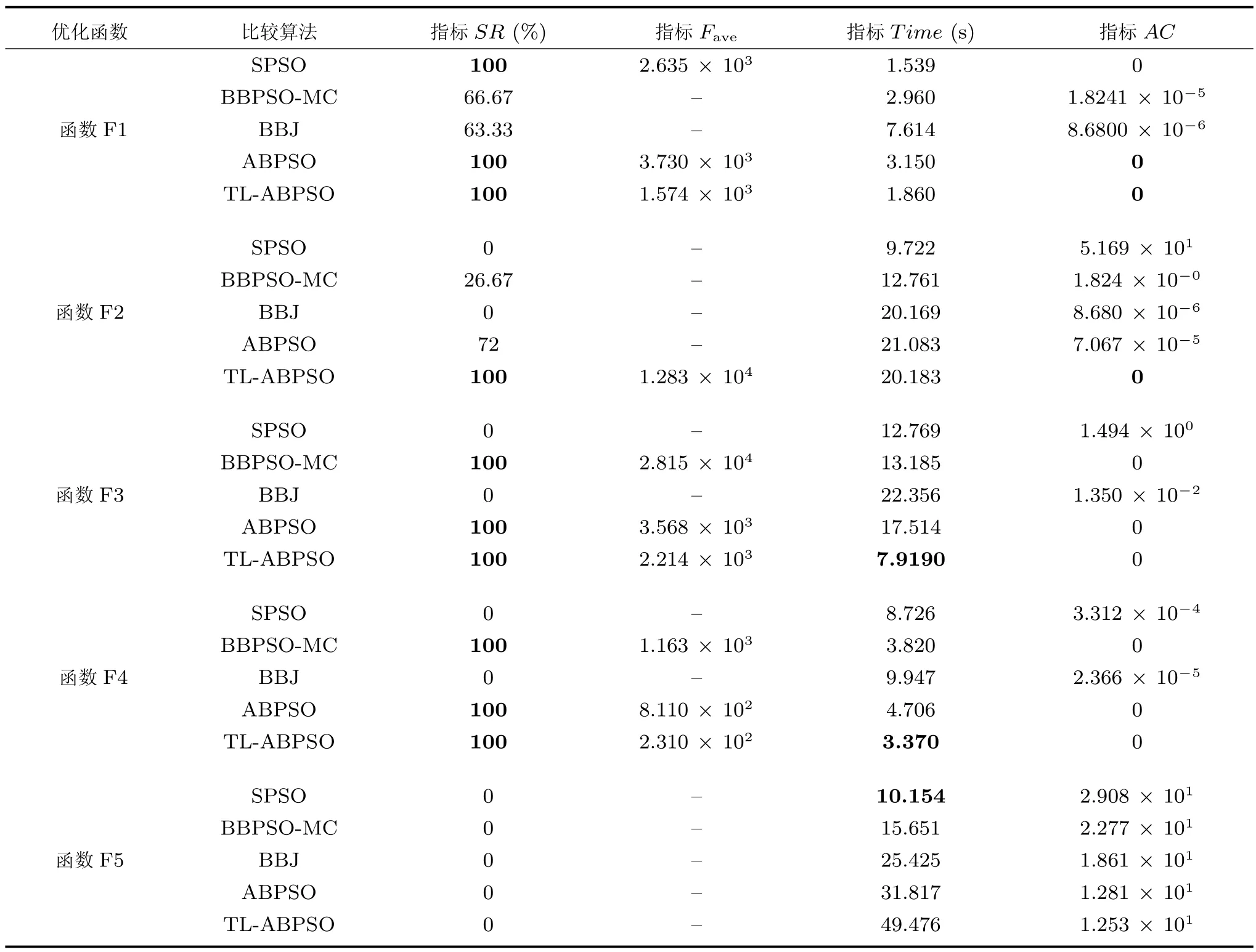
表3 比较算法优化第1 组测试函数所得实验结果Table 3 Experimental results obtained by comparison algorithm for the first set of test functions
3.3.3 ABPSO 和TL-ABPSO 算法比较
本小节单独比较ABPSO 和TL-ABPSO 的收敛效果.如前所述,本文所提TL-ABPSO 是ABPSO 算法和历史问题迁移学习策略的结合体.通过比较两种算法的收敛效果,可以反映出所提历史问题迁移学习策略的有效性.图2 展示了优化第1 组测试函数时两种算法的收敛曲线.可以看出,TL-ABPSO 算法的进化趋势和ABPSO 算法大致相同,加入迁移策略后并没有影响算法本身的搜索机理;但是,得益于所迁移历史问题最优解信息的帮助,TL-ABPSO 算法的收敛速度始终明显好于ABPSO 算法.
3.4 实验拓展及补充
3.4.1 迁移学习策略在差分进化算法中的应用
上述工作成功地将迁移学习策略加入到了骨干粒子群优化算法中,实验结果也说明了迁移学习策略的有效性.本小节尝试将所提迁移学习策略加入到另一种典型的优化算法,即自适应差分进化算法[33]中,以验证迁移学习策略在不同进化算法中的效果.由此,给出一种基于相似历史信息迁移学习的自适应差分进化算法,简称TL-DE 算法.
为了验证TL-DE 算法的有效性,选择在第1 组测试函数上进行实验,算法参数设置为种群规模50,使用“DE/rand/1”变异策略,缩放因子为0.5,交叉概率为0.9,最大进化代数为3 000.图3 展示了优化第1 组测试函数时两种算法的收敛曲线.可以看出,在进化初期,TL-DE 算法的收敛速度明显好于DE算法;在进化后期,对于大部分函数,TL-DE 算法所得结果也明显好于DE 算法.这进一步说明,加入迁移学习的进化算法不仅可以节省进化成本,加速种群的进化过程,而且可以提高算法的求解精度.因此,本文所提于历史信息迁移的进化优化框架同样适用于差分进化算法.

表4 比较算法优化第2 组测试函数所得实验结果Table 4 Experimental results obtained by comparison algorithm for the second set of test functions
3.4.2 聚类数目ccckkk 的敏感性分析
由于影响历史问题与新问题的匹配精度,聚类数目ck的取值非常关键.聚类数目ck设置过小,聚类结果不能有效反映解分布的多样性;而聚类数目过大,每一类中保存的样本较少,利用少量样本学习得到的解分布模型通常不精确.基于优化问题的复杂程度和解分布特点,可以设置合理的ck值,但是准确获取这些信息往往需要决策者具有一定的问题先验知识,这在很多实际情况下是不可能或者需要花费太多代价的.本节通过实验分析聚类数目ck值对算法性能的影响,旨在给决策者提供一个较为合理的ck取值范围.
鉴于此,选择第1 组测试函数为例,参数ck分别取值为3,5,7,10,运行TL-ABPSO 算法30 次,图4 给出了在不同参数ck取值下,TL-ABPSO 找到问题最优解所需平均迭代次数.可以看出,聚类数目ck取3 或者10 时,TL-ABPSO 算法可以找到问题的全局最优解,但其所需迭代次数要大于ck取5 和7 的情况;当聚类数目ck取5 或者7 时,TL-ABPSO 算法能够以较快的速度找到问题的全局最优解.这在一定程度上归功于由聚类数目ck间接决定的种群初始化比例ratio,合适的种群初始化比例明显提高了算法的搜索速度.
4 结论

图2 优化第1 组测试函数时ABPSO 和TL-ABPSO 算法的收敛曲线Fig.2 Convergence curves of ABPSO and TL-ABPSO algorithms for the first set of test functions
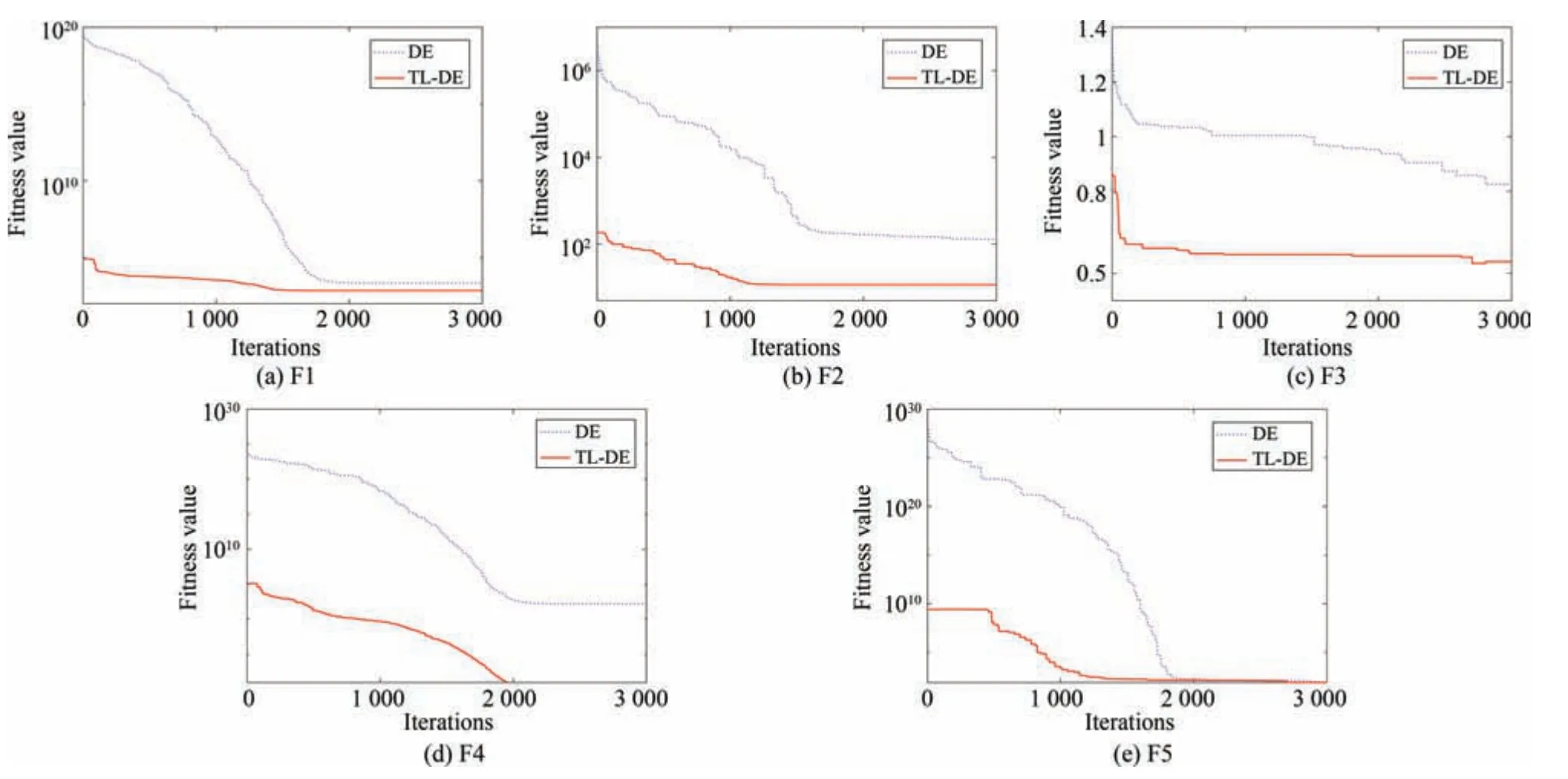
图3 优化第1 组测试函数时DE 和TL-DE 算法的收敛曲线Fig.3 Convergence curves of DE and TL-DE algorithms for the first set of test functions
本文研究了一种基于相似历史信息迁移学习的进化优化框架.针对框架中历史模型匹配、历史信息的迁移学习和模型库更新等关键算子,分别提出了基于多分布估计最大均值差异的历史模型匹配策略、基于模型匹配程度的进化种群初始化策略,以及于基于迭代聚类的模型库更新策略.通过从模型库中找到与新问题匹配的历史问题,并将其知识迁移到新问题的进化优化过程中,该框架明显提高了算法的搜索效率.将已有的粒子群优化算法和差分进化算法分别嵌入到所提进化优化框架,给出了基于相似历史信息迁移学习的骨干粒子群优化算法和基于相似历史信息迁移学习的自适应差分进化算法.两种算法在10 个典型测试问题上的应用表明,本文所提基于相似历史问题的迁移学习机制,不仅可以明显加速种群进化过程,而且能够提高算法的求解质量.
然而,不可否认,本文所提策略需要历史和新问题同属一种问题,而且它们应该具有相似的编解码策略和特性,这限制了所提进化框架的应用范围.是否可以在两种不同问题(如背包问题和设施布局问题等) 之间进行求解信息或求解规则的迁移,将是我们今后研究的重点;此外,如何降低模型匹配等策略带来的计算复杂度问题,也是今后需要研究的内容.

图4 在不同参数ck 取值下,TL-ABPSO 找到问题最优解所需平均迭代次数Fig.4 The average iteration time required by TL-ABPSO to find the optimal solution under different ck value
猜你喜欢
今日农业(2022年15期)2022-09-20
中原商报·科教研究(2021年4期)2021-03-03
计算机技术与发展(2020年11期)2020-12-04
红土地(2018年7期)2018-09-26
湘潭大学学报(哲学社会科学版)(2015年5期)2015-11-25
电子与信息学报(2015年12期)2015-08-17
会计之友(2014年28期)2014-10-13
当代畜禽养殖业(2014年10期)2014-02-27
测绘工程(2013年6期)2013-12-06
中学生物学(2008年6期)2008-08-29
