
改进AFSA算法优化TWSVM的火焰识别方法
2021-04-23 04:32:36高一锴徐龙壮
计算机工程与应用 2021年8期
高一锴,彭 力,徐龙壮
物联网技术应用教育部工程研究中心(江南大学物联网工程学院),江苏 无锡214122
如何更准确、更及时地探测火灾一直是人们研究的热门课题。由于环境的多样性、火灾发生的随机性和各种干扰,火灾的检测和预测通常是不容易的。近年来,随着计算机技术的快速发展,结合机器视觉和模式识别算法的图像火灾检测方法得到了广泛的研究,并成功应用到实践当中。
图像火灾探测的核心问题是从各类火焰干扰中对火焰进行分类和识别。近年来,出现了越来越多的火灾模式识别算法,其中常用的方法有支持向量机[1-3]、神经网络[4-6]、马尔可夫模型[7]等。基于统计学习理论和结构风险最小化的支持向量机(Support Vector Machine,SVM)是继人工神经网络对火焰识别之后出现的一个新的发展方向,SVM 能够很好地处理高维度以及局部极值等问题,而且具有直观的数学模型和简洁的数学理论,其得到的解为全局最优解,从而解决了人工神经网络容易陷入局部极小值等问题[8]。曹勇[9]分别用LVQ神经网络和BP 神经网络以及SVM 对火焰特征向量进行识别分析,实验结果表明SVM 的火焰识别准确率最高。杨娜娟等人[10]在每帧火焰图像中都用SVM 进行识别,识别效果优于BP 神经网络和RBF 神经网络,克服了神经网络容易过学习、容易陷入局部极小点等不足。张兴坤[11]同时将SVM和深度卷积神经网络(CNN)应用于火焰检测,实验结果表明SVM可以进行火焰的有效分类识别,效果良好,而CNN 模型对火焰干扰物体的分辨能力较弱,泛化能力较差。虽然SVM 在火焰识别领域取得了较好的成果[1-3,8-11],但是SVM 分类算法在面对规模较大的数据时通常需要进行大量的二次规划计算,这可能导致分类计算量大、分类速度慢。孪生支持向量机(Twin Support Vector Machines,TWSVM)是2007 年由Jayadeva提出,TWSVM的训练学习速度更快,计算复杂度更低,时间开销上仅为SVM的1/4[12],并且TWSVM已经成功应用于发动机故障识别[13]、图像分类[14]、手势分类[15]等领域。本文将基于SVM且性能更优的TWSVM理论应用于火焰识别这个领域,这样做不仅能够得到优于SVM 在火焰识别中的检测效果,而且大大降低了算法的时间复杂度。另外,火焰样本数据经常存在不平衡的情况,也就是一个样本数据少,一个样本数据多,SVM往往无法很好地处理这种情况,而TWSVM还能有较好的分类效果,这是因为TWSVM可以分别对正负样本设置不同的惩罚参数,从而克服SVM 在处理样本不平衡问题时的缺点。
尽管TWSVM 算法在跨区域数据集上的性能通常优于传统的SVM算法,但是仍存在不足之处,其中之一就是TWSVM无法很好地处理参数选择问题。参数对分类结果有很大的影响,不适合的参数将造成TWSVM分类精度大大降低。参数选择的困难将会极大地限制TWSVM在火焰识别问题中的应用,要想将TWSVM应用到火焰识别上,TWSVM参数选择是一个不可回避的问题。一种最常见的方法为网格搜索法(Grid)[16],但是这种方法非常耗时。近年来一些学者利用群体智能优化算法来实现TWSVM 的参数选择,遗传算法(GA)是目前应用最广泛的优化方法之一,然而遗传算法中有四个参数需要选择和优化[17],这种算法往往使得计算成本变高。粒子群算法(PSO)[18]是另一种基于随机轨迹的搜索模型,但它偶尔会收敛到局部最优点或任意点,而不是全局最优点。Ding 等人采用果蝇算法(FOA)和萤火虫算法(GSO)对TWSVM的参数进行优化,但是这两种优化算法依然存在陷入局部最优解的可能[19-20]。2019年李景灿等人首次将TWSVM与人工鱼群算法[21](AFSA)结合来解决TWSVM 的参数选择问题[22]。但是不足之处在于,人工鱼群算法寻优速度较慢,这使得TWSVM无法快速准确地得到全局最优解[22],TWSVM 的分类性能并不是很理想。
应用于TWSVM参数优化的GA算法[17]、PSO算法[18]、FOA算法[19]、GSO算法[20]大多存在陷入局部最优解的缺点,而人工鱼群算法有着很强的逃离局部极值的能力,并在寻找全局极值点时也有着非常好的效果[23]。但是由于基本的人工鱼群参数设置为固定值,缺乏自适应性和动态调整能力,造成后期收敛速度较慢,另外在搜索后期存在大量人工鱼聚集在非全局最优解附近,或仍在漫无目的随机游动的现象,导致鱼群算法的求解效率较低[24-25],本文利用一种改进人工鱼群算法(Improved Artificial Fish Swarm Algorithm,IAFSA)对TWSVM的参数进行优化。首先,在鱼群初始化时,利用基于聚类的鱼群初始化方法来使鱼群在空间上分布均匀;其次,利用自适应参数动态调整人工鱼群的视野范围和移动步长,平衡了AFSA的全局搜索能力和局部搜索能力之间的矛盾;最后,为了提高算法的收敛性,除了经典的人工鱼群行为如觅食行为、聚群行为和追尾行为外,还提出了两种新的行为:跳跃行为和淘汰重生行为。通过以上对基本人工鱼群算法的改进,得到一种性能更加优良的人工鱼群算法,克服了基本人工鱼群算法中寻优精度低和寻优速度较慢的缺点,实现对TWSVM参数的快速准确选取,从而帮助TWSVM 获得更高的分类精度,为TWSVM 应用到火灾火焰识别领域提供了可行有效的思路。
1 孪生支持向量机
孪生支持向量机是基于支持向量机而提出来的,由于TWSVM所求解的二次规划问题的规模是原SVM的1/4,所以从理论上来说计算效率是传统SVM的4倍,极大地提高了分类效率[12]。
假设在n维实空间Rn有m个训练样本,m1个样本属于正类,m2=m-m1个样本属于负类,矩阵A∈Rm1×n代表正类的训练样本,矩阵B∈Rm2×n代表负类的训练样本,A和B的每一行代表一个样本。TWSVM 的训练过程是寻找两个不平行的超平面如式(1):
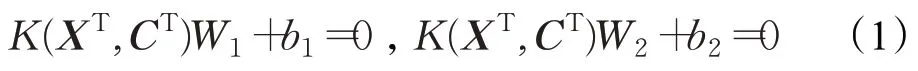
K是待确定的核函数,CT=[A,B]T,通过求解下面两个二次规划问题可以得到这两个超平面如式(2)、(3):

e1是一个单位列向量,其行数与K(A,CT) 核函数相同。e2是一个单位列向量,其行数与K(B,CT)核函数相同。c1和c2是惩罚参数,与线性模型的情况相似,测试样本属于哪一类,取决于它们更接近哪一个分类超平面。
2 基于改进人工鱼群算法的孪生支持向量机
2.1 基本人工鱼群算法
人工鱼群算法(AFSA)主要是通过人工鱼个体的觅食、聚群和追尾3种行为进行寻优的。在AFSA中,每条鱼的位置被看作是待优化问题的一个可行解,每个解都有一个由适应度函数评估的适应度值,根据待优化问题的不同,合理的选择不同的适应度函数。定义初始人工鱼有N条,每条人工鱼状态为Xi=[x1x2…xm]T,食物浓度(适应度)函数定义为Yi=f(Xi),将向量Xi代入适应度函数便能得出该位置相应的适应度值Yi,通过适应度值来评价个体人工鱼的好坏。dij=‖Xi-Xj‖为两个人工鱼之间的距离。在每次迭代中,人工鱼通过觅食、聚群和追尾等行为来更新自己,具体的行为描述如下。
觅食行为:假设人工鱼当前状态为Xi,并且相应的适应度为Yi=f(Xi),在Xi的视野范围内随机选择另外一个状态Xj,如果对应的适应度Yj >Yi,则按式(4)向Xj移动一步,否则,重新选取新的Xj判断是否满足前进条件,如果尝试Π次仍然无法前进,则按式(5)随机移动到一个新的状态,rand(0,1)是[0,1]内的随机正数,Step是移动的步长。
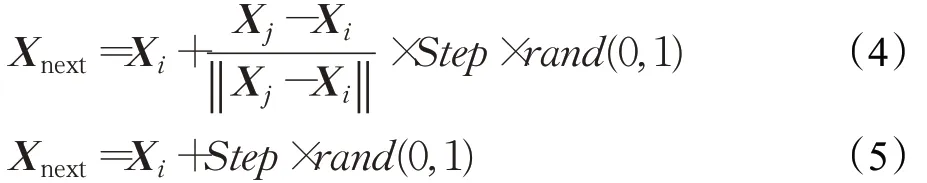
聚群行为:假设人工鱼当前状态为Xi,以Xi为中心的视野范围内共有nf个人工鱼伙伴,当nf≥1,根据式(6)计算出鱼群中心位置Xc,若满足Yc/nf >δYi条件,表示鱼群中心状态较优且不太拥挤,故根据式(7)向该鱼群中心所对应的方向移动一步,若不满足该条件,则选择执行觅食行为。
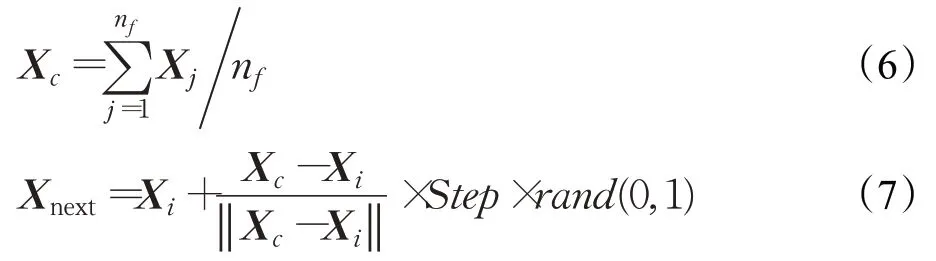
追尾行为:假设人工鱼当前状态为Xi,其相应的适应度函数为Yi,人工鱼在当前视野范围内搜寻到的具有适应度最大值的人工鱼伙伴所在位置为Xmax,则该位置所对应的适应度值为Ymax。若满足Ymax>Yi,则以Xmax为中心点搜寻在其视野范围内的所有人工鱼,数量为nf,如果满足Ymax/nf >δYi,说明Xmax位置较优且不太拥挤,则根据式(8)朝Xmax移动一步,若不满足该条件,则选择执行觅食行为。
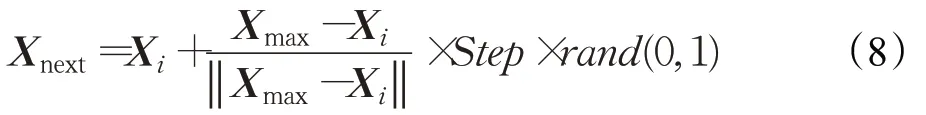
2.2 改进人工鱼群算法
虽然AFSA 算法具有鲁棒性强、收敛性好的优点,但在搜索效率上仍存在着后期盲目搜索、算法速度慢、优化结果精度低等缺点。在本小节中,针对以上问题,本文对基本人工鱼群算法进行如下改进,并且详细阐述了改进人工鱼群算法(IAFSA)的核心改进步骤。
(1)基于聚类的种群初始化
基本AFSA的初始化是在可行范围内随机生成的,随机初始化可能导致初始种群的不均匀分布,这使得启发式算法陷入局部最优并影响它们的收敛性。为了克服这个缺点,提出一种基于聚类的鱼群初始化方法来使鱼群在空间上分布均匀,假设初始种群规模为N,误差精度为ω,该聚类初始化步骤具体如下:
步骤1随机产生N个个体作为初始人工鱼群(初始中心点),迭代计数器s=0。
步骤2随机产生M个个体,并把它们归到离自己最近的中心点,形成N个簇。
步骤3计算这N个簇的中心点,更新中心点的位置。
步骤4判断条件‖Xi(s+1)-Xi(s)‖<ω是否成立i=1,2,…,N,若满足条件执行步骤5,否则执行步骤2。
步骤5输出这N个中心点,就产生了N条分布均匀的人工鱼作为初始鱼群。
(2)视觉范围和步长的改进
在标准人工鱼群算法中,视野范围和步长在整个迭代过程中保持不变。如果设定的视野范围和步长较大,人工鱼群更有可能跳出局部最优解,但同时,人工鱼难以进行精确的局部搜索,降低了全局搜索的精度。如果使用较小的视野范围和步长,它能够进行精细的局部搜索,但必须降低收敛速度才能达到全局最优。
为了平衡AFSA 的全局搜索能力和局部搜索能力之间的矛盾,本文利用式(9)和(10)自适应地调整人工鱼的视野范围和步长。在AFSA的早期,更大的视野范围和步长可以加快聚群行为和追尾行为的收敛速度,使得人工鱼经过较少次数的迭代后能够快速收敛到局部和全局最优位置。在后期,较小的视野范围和步长使觅食行为占主导地位,围绕在极值点附近的人工鱼可以准确地找到极值点的位置,从而找到最优值。

Visualmin为视野范围的最小值,Stepmin为步长的最小值,t∈(1,2,…,t_max)为当前迭代次数,t_max 为最大迭代次数,0.5<η <1。从式(9)和(10)可以看出,视野范围和步长随着算法的迭代不断变小并且最终趋于Visualmin和Stepmin,如果没有设定Visualmin和Stepmin值,Visual和Step在迭代后期将下降到一个接近零值的值,如果发生这种情况,人工鱼将会失去搜索能力,算计将无法继续迭代下去。
Visualmin和Stepmin的设置影响着算法的性能。如果设置大的Visualmin和Stepmin值,它可能影响局部搜索的精度,如果设置小的Visualmin和Stepmin值,可能会消耗更多的时间来获取最优解,影响收敛速度。因此,本文设置在阈值t_des迭代次数内,Visualmin和Stepmin值保持一定值,当迭代次数大于阈值t_des时,Visualmin和Stepmin的值按照式(12)和(13)梯度下降的方式发生变化。

(3)引入了跳跃行为和淘汰重生行为
在基本人工鱼群算法的觅食行为中,人工鱼在尝试Π次后如果仍然不能前进,则选择随机移动,这种盲目的随机行为会导致算法收敛缓慢,人工鱼陷入局部最优解无法跳出。在这种情况下,如果以概率选择一定数量的人工鱼,并使其位置显著地发生改变,人工鱼群往往会跳出局部极值区域,有利于提升算法的全局搜索能力和收敛速度。这种人工鱼位置的显著性变化称为跳跃行为,具体描述如下。
当迭代次数t大于阈值t_jump且人工鱼迭代后的适应度值增量小于阈值Yχ时,为每个符合条件的人工鱼生成一个介于0和1之间的随机数。随机数大于跳跃阈值ρ的人工鱼在视野范围内执行跳跃行为,如式(14),μ为跳跃系数,函数random(1,m)产生一个1 行m列的随机数矩阵。
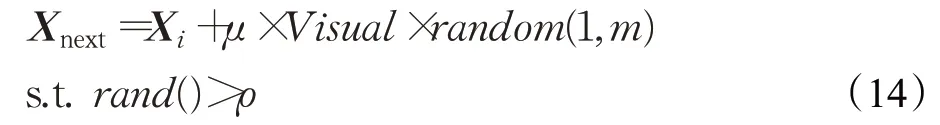
跳跃行为是以概率选择一定数量的人工鱼,一部分人工鱼仍在漫无目地随机游动,甚至出现退化现象。因此,在算法每迭代Γ次以后,如果人工鱼的适应度值小于淘汰重生阈值Yreb,这种人工鱼被认为竞争力较弱,应该在可行解范围内随机重生。淘汰重生阈值Yreb由式(15)来定义:
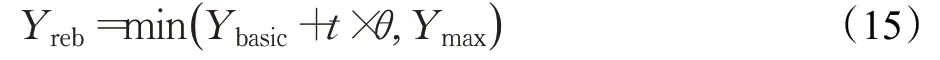
θ是适应度值的增量系数,Ybasic是淘汰适应度初始值,淘汰重生阈值Yreb随着算法迭代增加,但是它的最大值不能超过Ymax。在自然环境中,鱼通常在死前尽力挣扎。类似地,这个算法中的每一条人工鱼在被淘汰之前都有机会通过跳跃行为存活下来。如果人工鱼跳跃行为后的食物浓度高于阈值Yreb,它将继续生存,否则将被淘汰并重生。每隔Γ次迭代,每个人工鱼都会被评估是否需要淘汰重生。每个人工鱼都有足够的时间搜索最优值,同时遵循适者生存、弱者淘汰的原则。淘汰重生行为具体描述如下:
当迭代次数t大于阈值t_rebirth时,计算每个人工鱼迭代后的适应度值Yi,判断人工鱼是否满足跳跃行为的条件,若满足条件,执行跳跃行为并计算跳跃后的适应度值Yj,否则令Yj=Yi并执行下一步判断;判断是否执行淘汰操作,如果Yj <Yreb,淘汰该人工鱼,并重生新的人工鱼,否则人工鱼位置保持不变。每隔Γ次迭代,利用式(15)计算淘汰重生阈值Yreb,重新评估每条人工鱼是否需要淘汰重生。
2.3 IAFSA-TWSVM算法
与SVM 相似,惩罚参数与核参数的选择问题直接影响到TWSVM 的性能。TWSVM 常用的核函数是线性核函数、多项式核函数和高斯核函数,其中以高斯核函数最为普遍。高斯核函数具有以下优点,表达式简单,即使输入多个变量,复杂度也不会明显增加;它的任何阶的导数都存在并且具有良好的光滑性;它具有良好的性能和很强的学习能力,能够适应各种维度和样本量。大量实验结果表明,高斯核函数在TWSVM中的应用效果良好[17-20,22]。所以本文选取该函数作为核函数进行实验,高斯核函数表达式如式(16):

利用改进人工鱼群算法优化TWSVM 的惩罚系数c1、c2和高斯核参数σ,优化目标是寻求最优的参数组合(c1,c2,σ)使TWSVM的分类正确率达到最大化。参数组合(c1,c2,σ)视为人工鱼的位置,采用K-折交叉验证法(K-CV),将平均分类准确率作为目标函数值。在计算人工鱼适应度值时,将人工鱼的当前位置作为参数组合(c1,c2,σ)构建TWSVM 模型,将训练样本随机分成大小相同的K(K=10)份,进行十折交叉验证,把平均分类准确率作为该人工鱼当前位置的适应度值。对于给定的训练样本,利用改进人工鱼群算法优化TWSVM参数的算法(IAFSA-TWSVM)详细流程如下:
步骤1初始化。设定最大迭代次数t_max、种群规模N、视野范围最小值的初始值Visualmin、移动步长最小值的初始值Stepmin、觅食最大试探次数Π、拥挤度因子δ、阈值t_des、阈值t_jump、阈值t_rebirth、适应度值增量阈值Yχ、跳跃阈值ρ、淘汰重生行为执行相隔代数Γ、适应度值的增量系数θ、淘汰适应度初始值Ybasic等参数,并且设置TWSVM 中参数组合c1、c2、σ取值范围。
步骤2利用2.2 节中基于聚类的方法来初始化N条人工鱼。
步骤3计算初始鱼群中每条人工鱼的适应度值。对于每条人工鱼,以当前位置作为参数组合(c1,c2,σ)建立TWSVM 模型,对训练样本进行五折交叉验证,将平均分类准确率作为该鱼的适应度值。
步骤4将鱼群中适应度值最大值作为当前鱼群的最优值,并将对应人工鱼的位置保存在公告板中。
步骤5鱼群更新。每条人工鱼分别进行觅食、聚群和追尾行为,按步骤3 的方法计算各行为的适应度值,选择较优的行为作为鱼的移动方向并更新每条人工鱼的位置。
步骤6首先利用2.2 节中式(9)、(10)对视野范围、移动步长进行修改;判断条件t >t_des是否满足,若条件成立,Visualmin和Stepmin值按照式(12)和(13)梯度下降的方式发生变化,否则Visualmin和Stepmin值保持不变;判断条件t >t_jump是否满足,若条件成立,对符合条件的人工鱼执行跳跃行为,否则不执行任何操作;判断条件t >t_rebirth是否满足,若条件成立,对执行过跳跃行为的人工鱼执行淘汰重生行为,并且每隔Γ代后,通过式(15)计算淘汰重生阈值Yreb,重新评估每条人工鱼是否需要淘汰重生,否则不执行任何操作。
步骤7鱼群最优值的确定。将各鱼的适应度值与公告板中的值进行比较,如果较优则替换,并保存相应的位置,公告板中始终保持历史最优的值。
步骤8判断是否满足终止条件,若是,输出公告板中的值,即TWSVM的平均分类准确率和最优参数组合(c1,c2,σ)。否则跳转执行步骤5。
IAFSA-TWSVM的流程图如图1所示,通过这个流程图可以直观地看出本文所提出算法的过程。
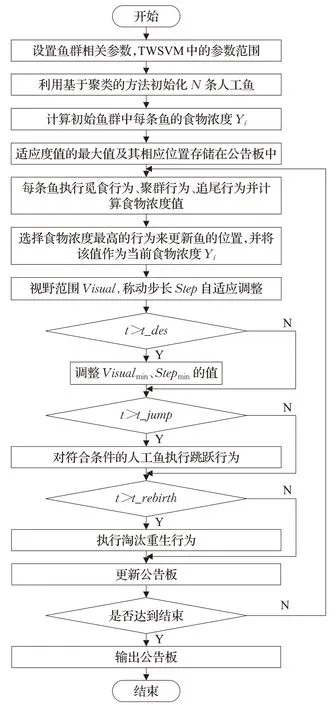
图1 IAFSA-TWSVM算法流程图
3 火焰图像分割与特征提取
火灾火焰图像识别需要获得图像相关特征量,因此还需要经过火焰图像分割和特征提取的步骤。
3.1 火焰图像分割
由于火灾在燃烧时其现场相对很复杂,所以单一的颜色模型可能无法很好地把火焰区域从背景区域分割出来。因此本文提出了一种RGB-YCbCr混合颜色空间模型方法,将RGB颜色空间模型和YCbCr颜色空间模型结合在一起,对火焰区域进行分割。
Wang等人[26]在实际的火焰数据集上将YCbCr颜色空间模型每个通道中的火焰像素值与相应通道中的平均像素值进行比较,得出了YCbCr颜色空间模型中火焰像素的分布特点:在Y通道中火焰区域的像素值明显大于整个图像的平均像素值;在Cb通道中,火焰区域的像素值小于整个图像的平均像素值;在Cr通道中,火焰区域像素值大于整个图像的平均像素值。上述分布特点可用式(17)~(19)表示:

Y(i,j)、Cb(i,j)、Cr(i,j)分别为(i,j)位置的Y 通道像素值、Cb 通道像素值、Cr 通道像素值,Ymean、Cbmean、Crmean为对应通道的平均像素值。
申小龙等人[27]通过对随机选取的134幅火灾图片和945幅未发生火灾的图片进行RGB值统计分析,分析发现对于火焰区域的RGB 值其红色分量值普遍较高,而绿色通道的值偏低,从而得出了在RGB 颜色空间模型中火焰像素的分布特点:R通道上的火焰像素的像素值大于G通道上的像素值。该特点可用式(20)表示:

R(i,j)、G(i,j)分别表示在RGB颜色空间模型中(i,j)位置的R通道像素值和G通道像素值。
为了更好地分割火焰图像,本文分别根据YCbCr和RGB 颜色空间模型中的火焰像素分布特点来提取火焰。然后对同时满足以上两种条件的像素点进行整理,最终得到完整的火焰目标区域,火焰图像分割的流程图如图2所示。
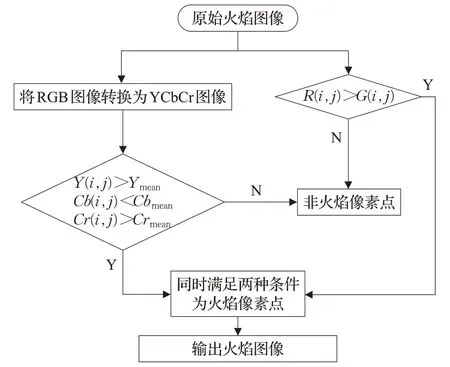
图2 火焰图像分割流程图
RGB-YCbCr 混合颜色空间模型的火焰图像分割效果示例图如图3 所示,从中可以看出,本文所使用的RGB-YCbCr混合颜色模型能够有效地从背景区域分割出火焰目标区域。
3.2 火焰图像特征提取
早期火灾火焰的颜色、形态和纹理不断变化,对火焰的这些特殊特征进行提取,能够作为很好的火灾火焰识别依据。本文选取常用的颜色矩、圆形度、纹理特征作为火焰图像识别的判据。

图3 RGB-YCbCr混合颜色空间模型的火焰图像分割效果示例图
(1)颜色矩。利用火焰图像的低阶颜色矩就能够描述颜色的存在状态,因为图像的颜色分布主要集中在低阶矩。图像的一阶颜色矩M1、二阶颜色矩M2、三阶颜色矩M3分别表示图像的平均颜色、标准方差以及二次根非对称性,其表达式如式(21)~(23):

其中,L代表的是图像的总像素集合,Y(p(i,j))代表的是在YCbCr颜色空间模型中,火焰目标区域p的(i,j)位置的Y通道分量值。
(2)圆形度。火焰的形状相对于干扰物(如蜡烛火焰、照明灯等)则显得不是那么有规律,所以圆形度可以作为火灾火焰识别的另一个重要的判据。圆形度是图元面积和周长之比,其表达式如式(24):

其中,Ai、Pi、Mi分别是第i个图元的面积、周长、圆形度。周长为物体的边界长度,从边界链码中得到,面积通过统计亮点数获得。
(3)纹理特征。纹理特征是表示目标区域像素灰度空间分布的另一个重要特征,本文利用灰度共生矩阵中的能量(ASM)、熵(ENT)、关联度(COR)和惯性矩(CON) 四个量来表示火焰识别问题的纹理特征,如式(25)~(28)所示。ph(i,j)为目标火焰区域的灰度值分别为i和j的像元对的概率,μx、σx、μy、σy分别为px(i)=的均值和标准方差。

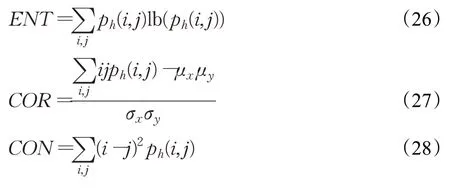
4 实验结果和分析
在本章中,从互联网网站下载327幅火焰图像进行火焰识别测试,其中223 幅火焰图像,其余104 幅为蜡烛、灯光等干扰图像。实验选取了样本总数的70%,即229幅图像(156幅火焰图像和73幅干扰图像)作为训练集,30%的样本(67 幅火焰图像和31 幅干扰图像)作为测试集。如3.1节所述,根据RGB-YCbCr混合颜色空间模型中火焰像素的分布特点对火焰图像进行分割,然后提取每个图像的各个分量的颜色矩、圆形度和纹理特征作为特征向量,作为TWSVM 分类器模型的训练和测试样本。实验在Matlab 环境下实现,硬件配置为Windows 10 操作系统,8 GB 内存,1 TB 硬盘,i5-4210H和2.90 GHz主频CPU的计算机。
为了证明所提出的IAFSA-TWSVM 的有效性,选取传统支持向量机(SVM)、基于网格搜索的孪生支持向量机(Grid-TWSVM)、基于遗传算法的孪生支持向量机(GA-TWSVM)[17]、基于粒子群算法的孪生支持向量机(PSO-TWSVM)[18]、基于果蝇算法的孪生支持向量机(FOA-TWSVM)[19]、基于萤火虫算法的孪生支持向量机(GSO-TWSVM)[20]、基于人工鱼群算法的孪生支持向量机(AFSA-TWSVM)[22]作为对比实验,与IAFSA-TWSVM进行比较。为了保证算法对比的公平性,如2.3节所述,实验中所有智能优化算法的适应度函数为采用十折交叉验证方法得到的平均分类准确率。由于启发式算法得到的结果对于每个运行周期可能不完全相同,因此每个算法运行5 次,每次算法最大迭代次数为100,并将5次中的最优适应度值相对应的(c1,c2,σ)作为TWSVM的最优参数。表1 给出了不同算法寻找到的最优参数(c1,c2,σ),最优参数对应的最优适应度值,算法运行5次的平均参数寻优时间。
图4给出了IAFSA-TWSVM、AFSA-TWSVM、PSOTWSVM、GA-TWSVM、GSO-TWSVM、FOA-TWSVM 6种智能优化算法运行5次最优的参数寻优过程曲线。
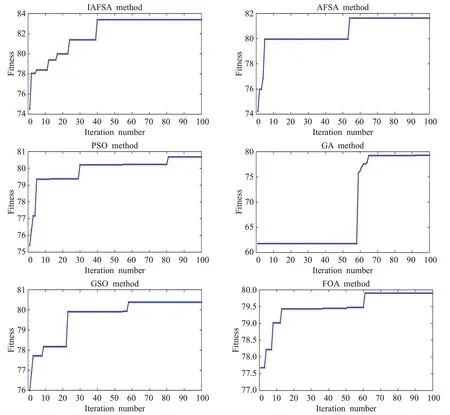
图4 不同算法参数寻优过程曲线
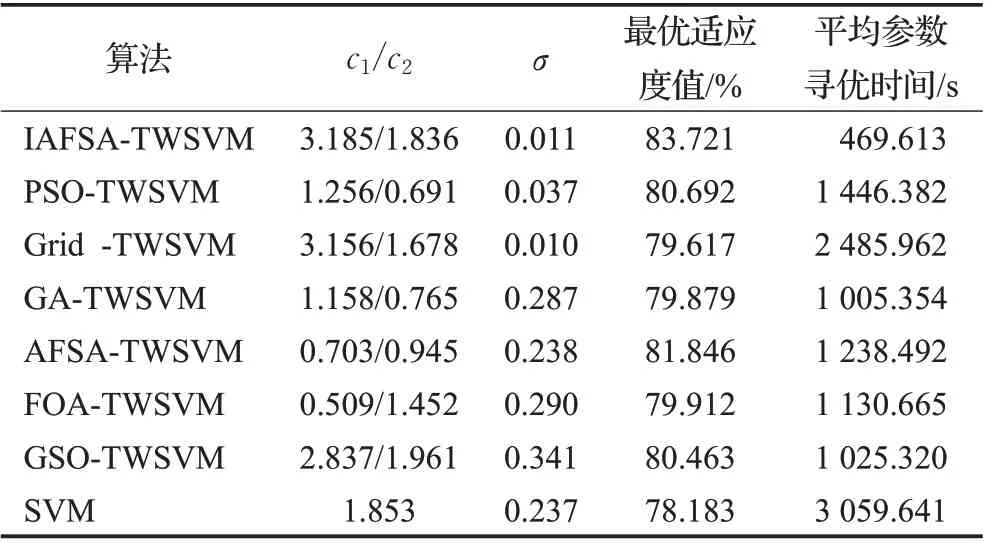
表1 不同算法参数寻优结果比较
实验利用参数寻优得到的最优参数(c1,c2,σ)作为最终选定的TWSVM参数,在全部训练集上建立TWSVM模型,并对剩余的30%测试集进行测试。
考虑到近年来深度学习的快速发展,以及卷积神经网络(CNN)在图像分类上的卓越表现,本文将其应用于火焰识别作为对比实验。为了与SVM和TWSVM算法进行比较,该对比实验使用3.1 节火焰分割方法获得火焰目标区域,减少了无关干扰物的影响同时压缩了输入CNN 模型的图像大小和数据量,然后送入卷积神经网络进行训练。本实验选用具有很强扩展性且泛化能力良好的VGGNet-16[28]深度卷积神经网络来构建火焰图像识别网络模型。另外由于火焰目标可能只存在火焰图像的某些位置,本实验将适用于实时目标检测的Fast R-CNN 算法[29]和YOLO 算法[30]也作为对比算法进行比较。
对于二分类问题,ROC(Receiver Operating Characteristic)曲线分析和混淆矩阵(Confusion Matrix)是分类器比较的重要性能指标。实验利用测试集的分类结果可以获得混淆矩阵的四个基本指标:TP(True Positive)即真阳性、FP(False Positive)即假阳性、FN(False Negative)即假阴性、TN(True Negative)即真阴性。基于以上四个基本指标,利用式(29)~(32)可以计算出准确率(Accuracy)、精确率(Precision)、召回率(Recall)、精确率和召回率的调和平均数F1分数(F1score)。

ROC 曲线的纵坐标为TPR(True Positive Rate)即真阳性率,横坐标为FPR(False Positive Rate)即假阳性率,TPR和FPR可以利用混淆矩阵中的基本指标得到,如式(33)、(34)。


图5给出了十一种算法的ROC曲线图。AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积。AUC 为分类算法的性能对比提供了数字化依据,为了计算AUC,只需要得到ROC 曲线下的面积。表2给出了十一种算法在测试集上准确率、F1分数、AUC和算法运行时间(SVM、TWSVM 算法运行时间包含参数寻优时间)四种性能指标的对比情况。
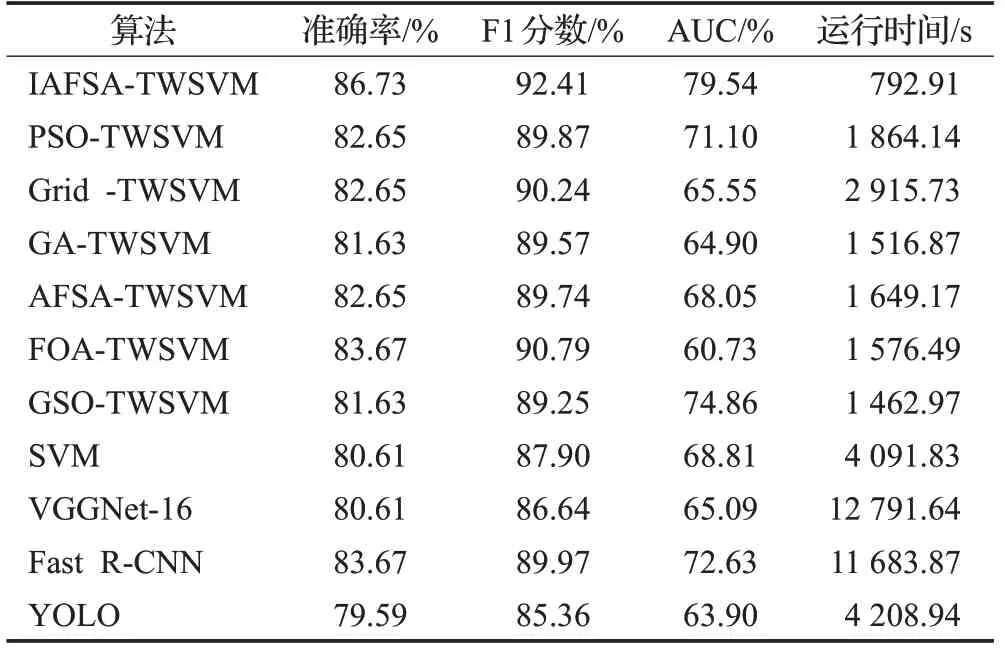
表2 不同算法性能指标比较
从表1和图4中可以看出,本文提出的IAFSA-TWSVM可以以更少的迭代次数,更快地寻找到TWSVM的最优参数。从表2可以看出,所提出的IAFSA-TWSVM在准确率、F1分数、AUC三种性能指标上均获得了最优的结果,同时所提的算法运行时间最短,实时性最好。从表2也可以看出,虽然Fast R-CNN 算法取得了较好的分类效果,但是由于该算法使用Selective Search方法提取候选区域,存在很多冗余运算使得算法比较耗时;YOLO算法实时性与SVM 算法比较接近,但是该算法的分类效果不是很理想,这是因为YOLO算法自身存在定位不准的问题,容易出现漏检的情况;VGGNet-16 深度卷积神经网络各项性能指标与SVM 算法比较接近,另外由于VGGNet-16卷积层计算量较大且相对于SVM算法参数数量较多,使得VGGNet-16 算法运行时间较长。值得注意的是,SVM算法也比较耗时达到了4 091.83 s,而七种基于TWSVM的算法相比SVM算法运行时间大大缩短。从理论上讲,TWSVM时间开销上为SVM的1/4,在实验中发现,实验结果和理论值存在一定的差距,但是依然可以验证TWSVM在火焰识别领域比SVM更有优势。在七种基于TWSVM 的算法中,所提的IAFSATWSVM 算法运算时间最短,分类性能指标最好。这主要得益于2.2 节对人工鱼群算法的改进,改进后的AFSA可以以更快的速度跳出局部最优解,寻找到适合TWSVM的全局最优参数,从而解决了TWSVM应用于火焰识别时参数选择困难、常用参数寻优算法寻优时间长等问题。
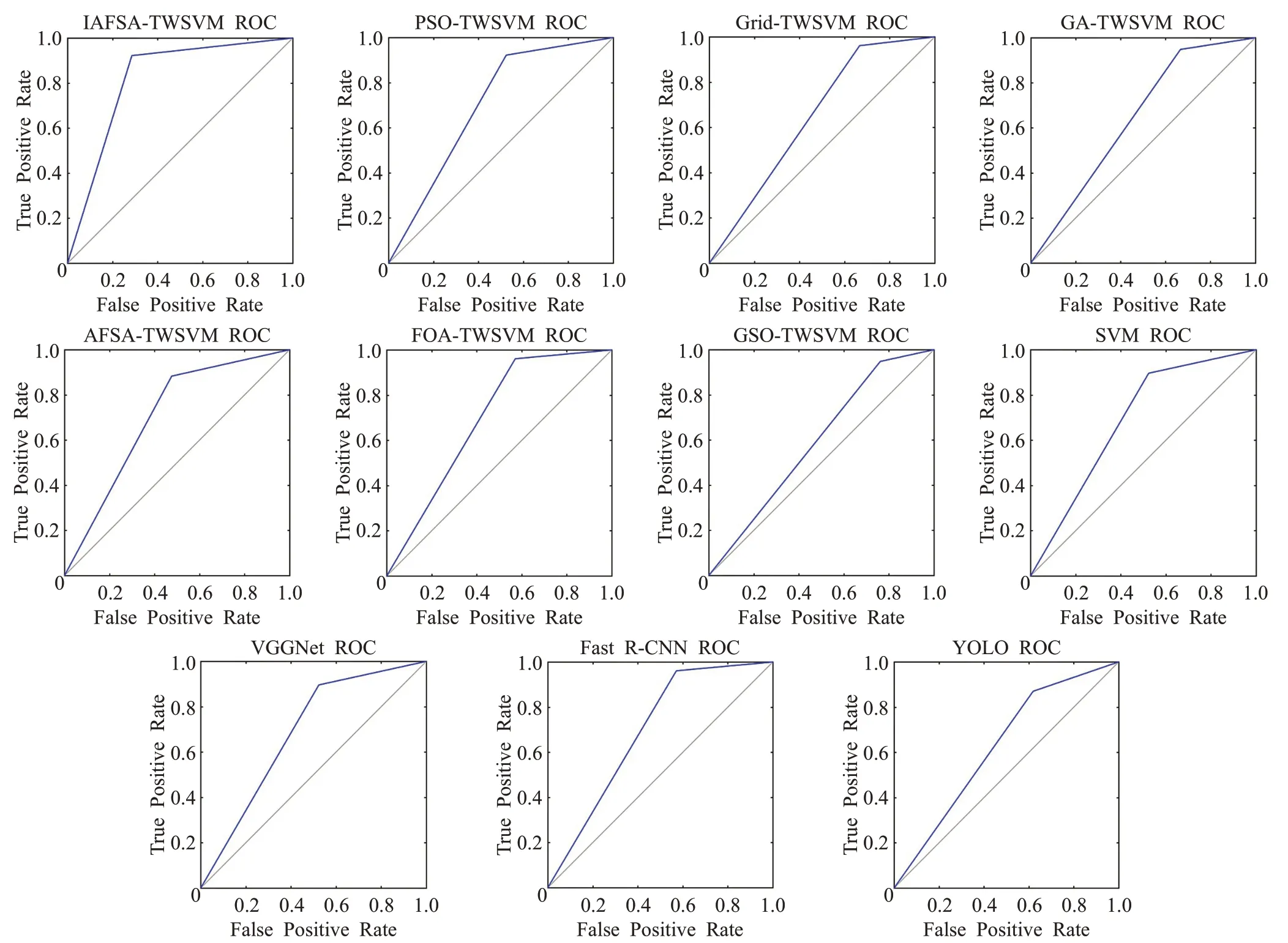
图5 测试集上不同方法的ROC曲线
5 结束语
本文针对孪生支持向量机应用到火焰识别领域时参数选择困难、常用参数寻优算法寻优时间长等问题,提出了一种改进人工鱼群算法优化孪生支持向量机参数(IAFSA-TWSVM)的火焰识别方法。该方法通过基于聚类的方法实现人工鱼群的均匀初始化,同时用自适应参数取代AFSA算法的固定视野范围和步长,引入新的跳跃行为和淘汰重生行为更好地帮助鱼群跳出局部最优解,提高了算法的收敛速度和识别率,克服了前人优化算法后期收敛速度慢、易陷入局部最优的缺点,为TWSVM应用到火焰识别提供了一种有效的新方法。
猜你喜欢
快乐作文(1.2年级)(2023年12期)2023-04-20 10:06:06
计算机仿真(2022年8期)2022-09-28 09:53:02
音乐天地(音乐创作版)(2022年1期)2022-04-26 13:51:04
动漫星空(兴趣百科)(2019年5期)2019-05-11 02:05:38
中外文摘(2017年19期)2017-10-10 08:28:41
学与玩(2017年6期)2017-02-16 07:07:22
中国塑料(2016年11期)2016-04-16 05:26:02
电测与仪表(2016年3期)2016-04-12 00:27:44
电测与仪表(2016年20期)2016-04-11 11:38:08
河南城建学院学报(2015年4期)2015-02-27 07:09:13
