
改进YOLOv3在机场跑道异物目标检测中的应用
2021-04-23 04:33:22郭晓静隋昊达
计算机工程与应用 2021年8期
郭晓静,隋昊达
中国民航大学 电子信息与自动化学院,天津300300
机场跑道异物(Foreign Object Debris,FOD)指的是任何不属于机场道面,却因各种原因被遗留在机场运行区域的外来物质,典型的有金属器件、机械工具、防水塑料布、碎石块、瓶子、动植物等[1]。机场跑道异物会对航空器的安全造成巨大危害,许多航空事故都是由于跑道异物引起的,因此对机场跑道异物检测算法的研究具有重要价值。
机场的外界环境是不断变化的,出现在跑道上的异物类型是不确定的,如何在变化的背景条件下有效检测不确定的异物目标是需要解决的关键问题。传统的FOD 目标检测算法主要采用人工设计的特征来进行异物检测,需要运用大量的先验知识和技巧来设计一个特征提取器[2]。但由于外部光照条件的变化、异物类型的复杂性以及视频设备的缺陷等因素,道面背景及异物目标的图像特征通常是不确定的,对于某种特定背景及异物目标,或许研究出的算法具有较好的检测效果,而当约束条件改变,尤其当主要的异物目标图像特征发生变化时,算法就会失去效果[3]。
与传统的目标检测算法不同,基于卷积神经网络(Convolutional Neural Network,CNN)的目标检测算法可以通过已有数据自动学习目标特征,相比于HOG、SIFT、LBP 等特征有更好的表达效果,可以适应多样化背景与目标类型[4]。基于CNN 的目标检测算法可以分为两类:一类是以Fast-RCNN(Region-Conventional Neural Network)[5]、Faster-RCNN[6]、Mask R-CNN[7]等为代表的基于候选区域的目标检测算法,这类算法通常具有良好的检测精度,但普遍存在检测速度较慢的缺点;另一类是以YOLO(You Only Look Once)[8]、SSD(Single Shot Multi-box Detector)[9]、YOLO9000[10]、YOLOv3[11]等为代表的基于回归的目标检测算法,这类算法的优点是实时性好,缺点是检测精度相对偏低。
基于CNN 的目标检测算法可以有效检测背景复杂、种类繁多的异物目标。文献[12]首次将其应用于机场跑道异物检测领域,提出一种基于候选区域的FOD目标检测算法,在没有考虑检测速度的情况下取得了较好的检测结果。文献[13]提出了一种基于改进区域候选网络(Region Proposal Network,RPN)和空间变换网络(Spatial Transformer Network,STN)的FOD 目标检测算法,取得了比Faster-RCNN更好的检测效果。文献[14]使用加权金字塔网络(Weighted Pyramid Network,WPN)进行目标检测,通过不同比例的多尺度层生成区域建议,提高了对FOD目标的检测精度。文献[15]先采用Faster R-CNN 生成输入图像的候选区域,然后使用DenseNet 网络代替传统的VGG16Net 网络进行特征提取,减少了网络参数,提高了对小尺度FOD目标的检测精度。
上述FOD目标检测算法均采用基于候选区域的方法,检测速度普遍较慢,无法满足实时性要求。比较而言,YOLOv3 既可以保证检测精度,也可以保证检测速度,且针对小目标物体的检测,国内外诸多研究者提出了不同的改进方案。鞠默然等[16]在YOLOv3 的基础上对模型的网络结构进行了改进,有效提高了对小目标物体的检测能力。邹承明等[17]通过改进YOLOv3 的损失函数,有效解决了其对小目标物体检测边界框定位不准确的问题。金瑶等[18]针对城市道路视频中的小像素目标,提出了一种改进YOLOv3的卷积神经网络Road_Net检测方法,能有效检测出诸如纸屑、石块等在视频中相对路面较小像素的目标。本文综合考虑YOLOv3 在小目标检测领域的各种优化方式,提出一种基于改进YOLOv3的FOD目标检测算法,主要工作如下:
(1)改进YOLOv3 网络结构。使用Darknet-49[19]代替Darknet-53作为特征提取网络,并增加特征融合的尺度以便获取更多的小目标特征信息。
(2)改进K-means聚类算法以获取更加合理的先验框尺寸,利用基于马尔科夫链蒙特卡罗采样(Markov Chain Monte Carlo sampling,MCMC)的K-means++算法[20-21]确定初始聚类中心。
(3)引入GIoU回归损失函数[22],提高算法的准确率和目标边界框的定位精度。
1 YOLOv3目标检测算法
YOLOv3的网络结构如图1所示,主要包括Darknet-53网络与YOLO 层两部分。Darknet-53 作为骨干网络主要用于提取图像特征,它是全卷积网络,包含53个卷积层,并引入了残差结构。当输入图像尺寸为416×416时,Darknet-53 特征提取网络输出三个尺度的特征图,大小分别为13×13、26×26、52×52。将三个不同尺度的特征图通过FPN(Feature Pyramid Network)[23]进行融合,利用多尺度策略帮助网络模型同时学习不同层次的特征信息,最后将融合后的特征输入YOLO层进行类别预测和边界框回归。
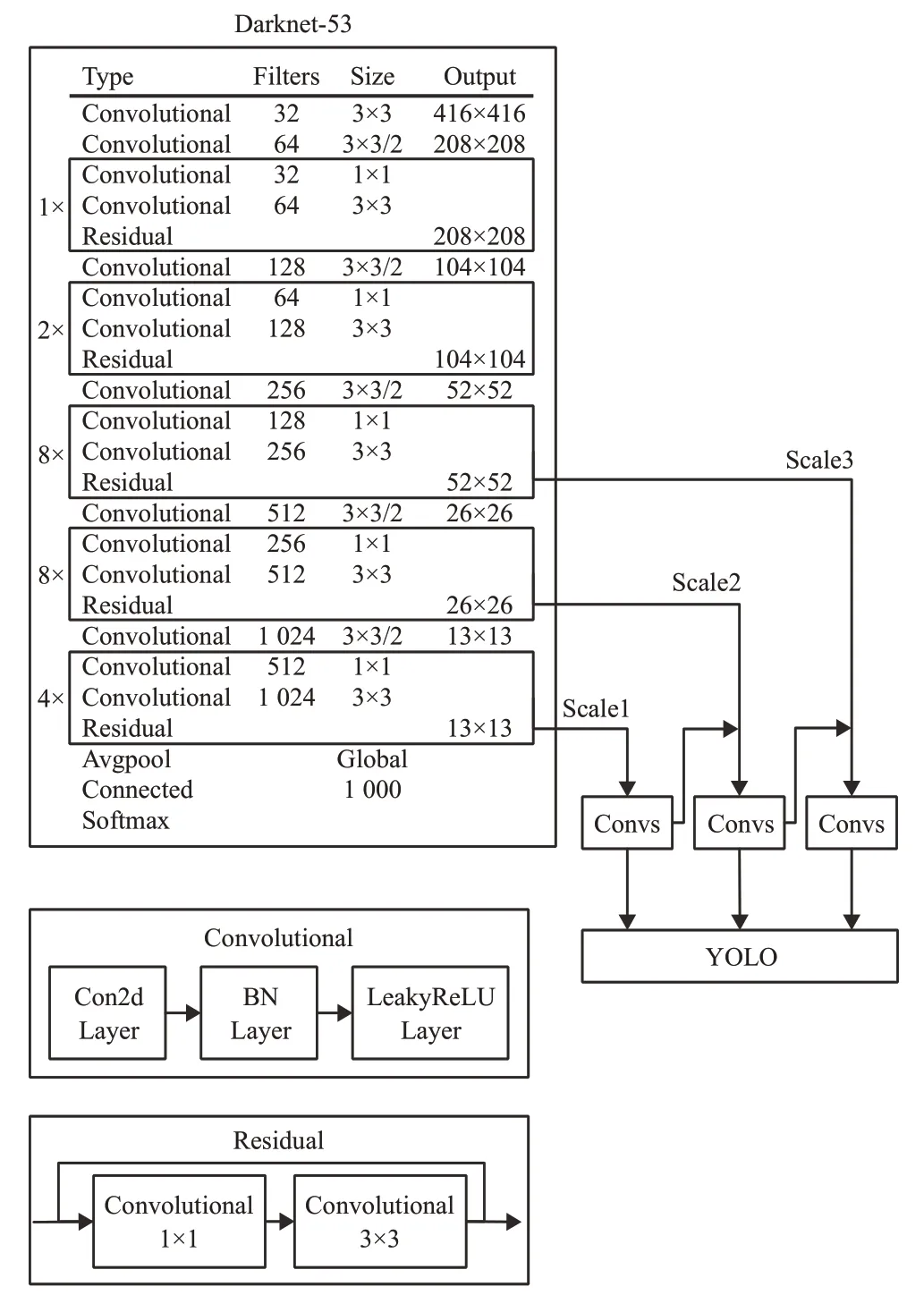
图1 YOLOv3网络结构示意图
YOLOv3采用先验框(anchor box)机制来预测目标边界框,对标注边界框尺寸进行K-means聚类得到一组尺寸固定的初始候选框。先验框尺寸与特征图尺度大小成反比,在较大的特征图上应用较小的先验框,用于检测较小的目标,在较小的特征图上应用较大的先验框,用于检测较大的目标。如表1所示,YOLOv3为每种特征图尺度设定3种先验框尺寸,在COCO数据集上聚类共得到9种尺寸的先验框。

表1 YOLOv3的先验框尺寸
对于输入图像,YOLOv3按特征图尺度将其划分为S×S个网格,当目标的中心位置落在某个网格中时,由该网格负责预测目标的边界框信息,输出B个边界框的相对位置(tx,ty)、相对尺寸(tw,th)及置信度信息。其中,置信度用于衡量边界框内是否包含目标以及预测边界框定位的准确性,用于判断边界框是否应该保留,其计算公式为:
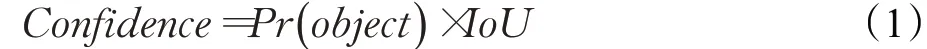
式中,Pr(object)用于判断预测边界框中是否包含待检测目标,包含时为1,不包含为0,IoU为预测边界框和标注边界框的交并比。
得到全部预测边界框后,设置阈值将置信度较低的边界框去除,其余边界框经过非极大值抑制(Non-Maximum Suppression,NMS)得到如图2所示的目标边界框。
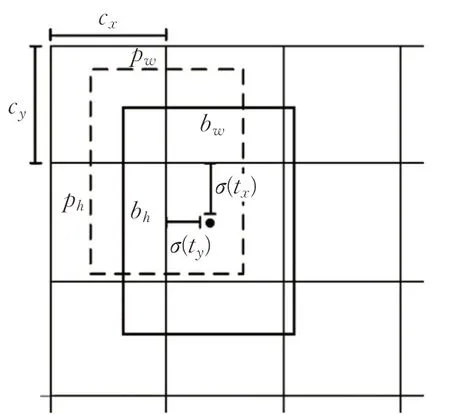
图2 目标框位置预测示意图
对每个网格,根据其坐标偏移(cx,cy)和先验框尺寸pw、ph对实际预测框的中心位置(bx,by)和尺寸bw、bh进行计算:

式中,tx、ty为边界框中心点相对该网格边界的偏移量,tw、th为边界框的尺寸相对于先验框的比例。
2 改进的YOLOv3算法
针对原YOLOv3 对远距离多个小目标物体检测存在的定位精度偏低和漏检问题,从网络结构、K-means聚类算法和损失函数三个方面进行改进。
2.1 网络结构改进
YOLOv3 使用Darknet-53 网络进行特征提取,使用的是步长为2、大小为3×3的卷积核来进行下采样,虽然感受野较大,但是牺牲了空间分辨率,导致深层网络的小目标信息丢失。
本文工作是检测机场跑道异物,如金属器件、混凝土块、塑料等,这些物体均具有小目标的特点。对小目标物体的检测更依赖于浅层特征,为了更加充分地利用浅层特征信息,本文使用运算复杂度相对更低的Darknet-49 作为特征提取网络。Darknet-49 网络由5 个残差块组成,每个残差块间使用1×1的卷积核来降低维数,并在第一个卷积层上使用线性激活函数,以减少对图像信息的损坏。
Darknet-49 对输入图像进行5 次下采样,每次下采样得到一个尺度的特征图。具有大分辨率的浅层特征图包含更多的位置信息,具有小分辨率的深层特征图包含更多的语义信息。将深层残差块采样得到的特征图与浅层残差块采样得到的特征图进行融合,可以增强浅层特征的语义信息,同时在最浅层的特征图上给目标分配更为准确的边界框,提高对小目标物体的检测性能。因此,本文在YOLOv3原有3个检测尺度的基础上进行扩展,增加一个尺度的特征图进行融合。
改进后的网络结构如图3 所示,其中Convolution set包含3次卷积操作,upsampling是步长为2的上采样,Concatenate 是深层特征与浅层特征的拼接。当输入图像大小为416×416 时,在Darknet-49 网络中进行5 次下采样,得到最底层13×13 尺度的特征图,对该特征图进行上采样,然后与26×26 尺度的特征图进行拼接,融合后的特征图再进行上采样,与上一尺度的特征图进行拼接,直至完成4 个尺度特征图的融合。最后,提取融合后13×13、26×26、52×52、104×104 四个尺度的特征图对FOD 位置和类别进行预测。改进后的网络结构可以防止有效信息的丢失,提高对小目标FOD的检测精度。
2.2 K-means聚类算法优化
K-means 聚类算法采用随机选取的方式确定初始聚类中心,随机确定的初始聚类中心位置会影响后续的聚类效果。为避免随机初始化带来的缺陷,本文使用马尔科夫链蒙特卡罗采样(Markov Chain Monte Carlo sampling,MCMC)算法进行初始化,以选取更加合理的初始聚类中心,得到更具代表性的先验框尺寸。
首先,在包含n个数据点的标注边界框尺寸数据集X中,随机选取一个数据点作为初始聚类中心,计算其与X中每一个数据点x的距离dx。
由于采用欧氏距离来度量数据点间的相似性,无法准确反映先验框尺寸与标注边界框尺寸的接近程度,因此,将样本到聚类中心距离的判定方法重新定义为:

式中,box表示标注的目标框,centroid表示聚类得到的先验框,IoU(box,centroid)表示标注边界框与先验框的交并比。
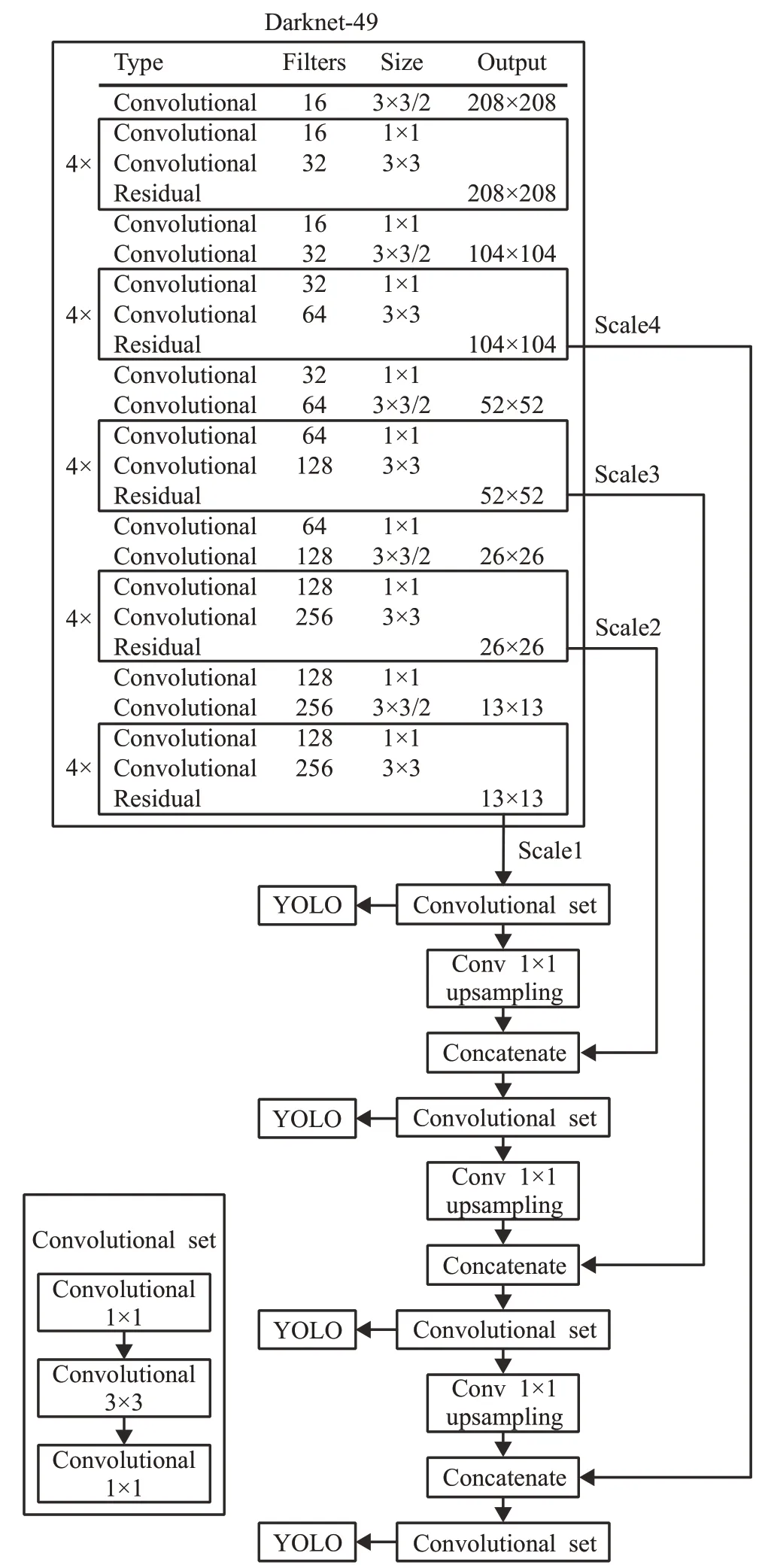
图3 改进的网络结构示意图
然后,使用q(x)分布下的Metropolis-Hasting 算法构造一个长度为m的马尔科夫链,以p(x)分布进行采样,取最后k-1 个点作为初始聚类中心。其中q(x)和p(x)分别为:

最后,对数据集中的每个样本,计算其到k个初始聚类中心的距离,使用K-means 算法进行聚类,得到k个先验框尺寸信息。
使用改进后的算法对FOD数据集中的样本进行聚类分析,针对四种尺度的特征图,共得到12种尺寸的先验框,其结果如表2所示。

表2 改进YOLOv3的先验框尺寸
2.3 损失函数
YOLOv3中的损失函数由坐标回归损失、置信度损失和分类损失组成,其中坐标回归损失使用均方误差(Mean Square Error,MSE)进行计算,置信度损失和分类损失使用交叉熵进行计算。
对于坐标回归损失函数,使用均方误差进行计算会存在对目标尺度敏感的问题,目标尺度的变化会影响坐标回归的准确性。而IoU 具有目标尺度上的鲁棒性,更能体现回归得到的目标边界框质量。但使用IoU 作为损失函数有以下两个问题:一是当预测边界框与标注边界框没有交集时损失函数梯度为0,无法进行优化;二是当预测边界框与标注边界框的IoU 相同时,检测效果会具有较大差异。
与IoU 只关注重叠区域不同,GIoU 不仅关注重叠区域,同时关注非重叠区域,可以更好地反映边界框的重合度。其计算公式如下:
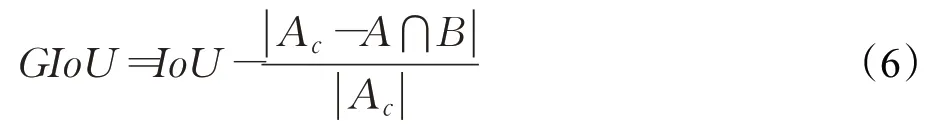
式中,A代表预测边界框,B代表标注边界框,Ac为两边界框的最小闭包区域面积。
相比于采用边界框中心坐标和尺寸的均方误差回归损失,基于GIoU 的坐标回归损失与边界框的形状和大小无关,可以更加准确地反映预测边界框与标注边界框之间的距离。因此,本文采用GIoU 边界框坐标回归损失函数,其计算公式如下:
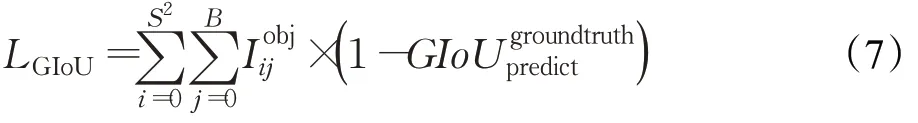
置信度损失使用交叉熵进行计算,其计算公式如下:

分类损失同样使用交叉熵进行计算,计算公式如下:
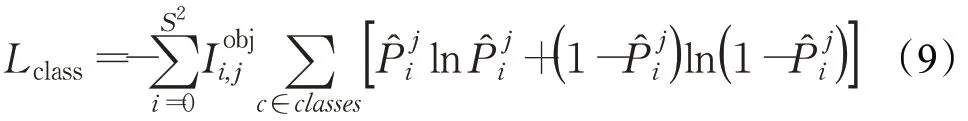
最终损失函数定义如下:
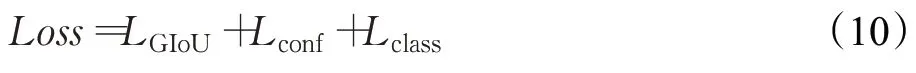
3 实验结果与分析
本文实验环境为:Intel Core i7-9750H CPU,16 GB内存,NVIDIA GeForce RTX 2060 GPU,PyTorch 版本为1.3.0,torchvision 版本为0.4.1,CUDA 版本为10.1,CUDNN版本为7.6.1。
3.1 实验数据集及模型训练
在FOD检测领域,目前没有公开的图像数据集,因此本文自行构建了实验数据集。其中包含200 张实际机场跑道上的FOD 图像及1 000 张模拟道面环境下的标准样件图像。最后得到如图4所示的由1 200张图片组成的FOD图像数据集,使用LabelImg进行标注。

图4 FOD图像数据集示意图
将实验数据集按7∶2∶1的比例随机划分为训练集、测试集和验证集。在训练阶段,批尺寸(batch_size)设置为16,动量参数(momentum)设置为0.9,权重衰减正则项(decay)设置为0.000 5,初始学习率(learning_rate)设置为0.001,使用小批量随机梯度下降进行优化。
训练过程中的GIoU 损失和置信度损失变化如图5所示,经过200个epoch后,损失值逐渐趋于稳定。
3.2 对比实验
将本文提出的改进YOLOv3 算法与基于候选区域的Faster R-CNN 算法、同样基于回归的SSD 算法、原YOLOv3 算法以及同为改进YOLOv3 的Road_Net 算法进行定量评估。
使用精确率(precision)和召回率(recall)来衡量目标检测算法的性能,精确率P是指在所有预测为正确的目标中,真正正确目标所占的比例;召回率R是指在所有真正目标中,被正确检测出来的目标所占的比例。其公式分别为:

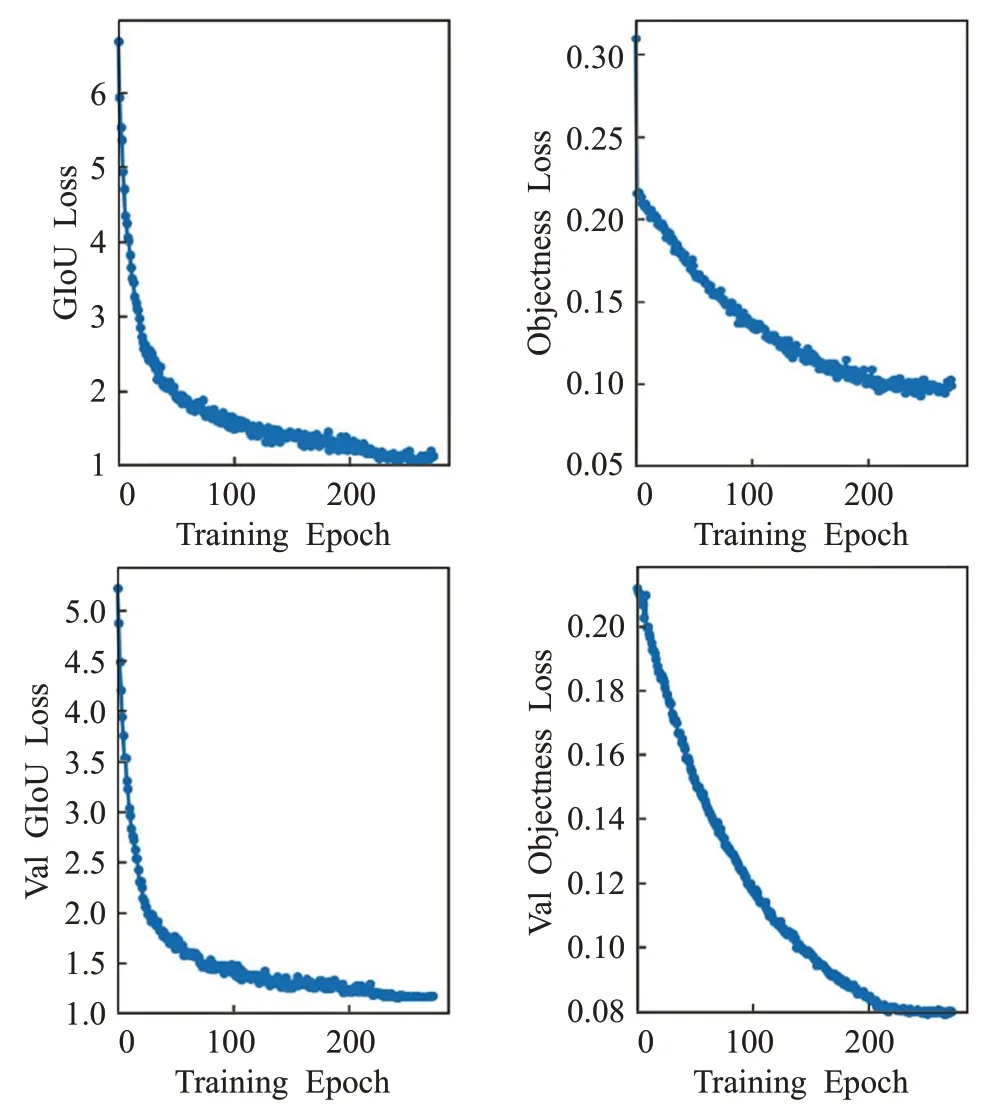
图5 网络训练损失函数曲线

式中,XTP表示被正确检出的目标数,XFP表示被错误检出的目标数,XFN表示没有被正确检出的目标数。
训练过程中,随着epoch数量增加,网络模型的精确率和召回率变化如图6所示。
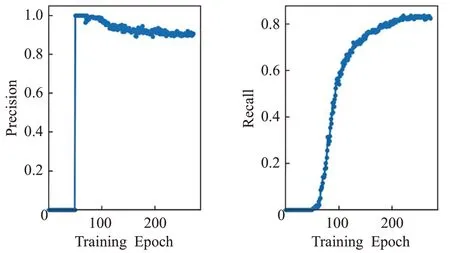
图6 网络训练结果曲线
最后,综合考虑精确率和召回率,使用平均精度(Average Precision,AP)来评价网络模型的检测性能,其计算公式为:

在FOD数据集上对本文算法和其他目标检测算法进行测试,性能比较结果如表3所示。在相同的测试集下,本文提出的改进YOLOv3 算法与Faster R-CNN 相比,对FOD目标检测的精确率、召回率及平均精度均低0.2%左右,但Faster R-CNN检测速度过慢,无法满足实时性要求。与SSD 相比,改进YOLOv3 的精确率、召回率及平均精度均有较大优势。与原YOLOv3 相比,改进YOLOv3 对FOD 目标检测的召回率提高了4.4 个百分点,平均精度提高了4.1 个百分点,检测速度由27.6 frame/s 增加到33.2 frame/s,在保持了原算法速度优势的基础上,召回率和平均精度均有较大提升。与同为改进YOLOv3 的Road_Net 相比,本文算法在召回率上有较大提升,有效改善了漏检现象,对FOD目标有更好的检测效果。

表3 5种算法的性能对比
3.3 检测结果分析
如图7所示,改进YOLOv3(见图7(b))相比原YOLOv3目标检测算法(见图7(a))对FOD目标的边界框定位更加精准,而原YOLOv3对小目标物体检测存在的漏检问题(见图7(c))在改进YOLOv3(见图7(d))中得到了有效改善。

图7 改进YOLOv3与原YOLOv3检测结果对比
图8显示了本文方法对标准FOD 样件在不同环境下的检测效果。在不同的道面环境和光照条件下,本文提出的方法均能得到良好的检测结果。
4 结语
本文将YOLOv3应用到机场跑道异物检测领域,提出一种基于改进YOLOv3 的FOD 目标检测算法,实现了对FOD 的实时有效检测。针对FOD 小目标的特点,对YOLOv3 的网络结构、聚类方法和损失函数进行改进。实验结果表明,改进的YOLOv3 算法将FOD 目标检测的平均精度从82.4%提高到86.5%,同时提高了对目标边界框的定位精度,相比原YOLOv3算法有更好的检测效果。在接下来的工作中,将继续优化算法以获得更高的精度和更低的时间成本,并继续采集更多的FOD图像来扩充现有数据集,以便更好的工程应用。

图8 测试图像和检测结果
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21 06:18:46
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
成都信息工程大学学报(2019年3期)2019-09-25 08:31:14
证券法律评论(2018年0期)2018-08-31 02:33:08
自动化学报(2017年5期)2017-05-14 06:20:44
太空探索(2016年5期)2016-07-12 15:17:55
探测与控制学报(2015年4期)2015-12-15 15:00:56
东南法学(2015年2期)2015-06-05 12:21:36
时代英语·高三(2014年5期)2014-08-26 17:01:17
外语学刊(2014年6期)2014-04-18 09:11:49
