
环状扫描的强深度森林
2021-04-23 04:31:40周博文
计算机工程与应用 2021年8期
周博文,皋 军,,邵 星
1.江苏科技大学 计算机学院,江苏 镇江212003
2.盐城工学院 信息工程学院,江苏 盐城224002
神经网络算法因其强大的泛化能力和非线性映射能力而被人们所青睐,同时也存在着明显的不足,比如需要大量调参,才得以找到最合适的参数来发挥最大性能,而且需要大量的数据来训练模型。近年来,周志华老师提出的深度森林模型一定程度上避免了以上问题[1]。文献[1]的实验结果已经说明了深度森林的优越性能。
但是深度森林模型也存在不足:(1)在多粒度扫描阶段,每个特征子集是按照滑动窗口选取的,假设数据集总的特征维数为n,窗口大小为m,m>2,则窗口第一次滑动生成的特征子集是从第1维到第m维,窗口第二次滑动生成的特征子集是从第2 维到第m+1 维,显然,第一维的特征只被扫描了一次,第二维的特征被扫描了两次……最后一维同理仅被扫描到一次。只有第m维到第n-m+1 维,每一维的特征才可被充分扫描到。由此可以看出,原始模型的多粒度扫描阶段不能充分得到特征子集,忽略了数据两端子集所携带的信息,若被忽略的子集经转换后生成的新特征的重要度非常大,那么就势必会影响后续的级联阶段,随着级数的增加,这种影响会逐渐变大,最终降低深度森林模型的预测准确率。(2)在级联阶段,仅仅是把前一层级生成的类分布向量作为增强特征,没有重视之前级联层的类分布向量,会降低收敛速度,从而降低算法的效率。而且,每层概率携带的信息是逐层递减的,只将前一层的类概率向量拼接,模型的准确率提高有限。
对于以上问题,本文做出两点改进,一是针对原始深度森林模型在多粒度扫描阶段不能充分得到每个特征子集的问题,提出一种较全面的环状扫描的方法,此方法对数据两端的信息加以重视,可得到每个特征子集,进而进行充分的特征转换;二是对于级联阶段不能充分重视之前级联层输出类向量的问题,在文献[2]的基础上进一步改进,即对将要堆叠的类向量做个判断,若属于有效表征,则将其并入原始特征,反之则舍去。
1 相关工作
深度森林模型因其优越的性能和便捷性,被应用在多个领域。文献[2]提出一种深度堆叠森林模型,先在扫描阶段采用随机抽样的方法得到特征子集进行特征转换,然后在级联阶段拼接每一层的类向量,加强级联结构的表征学习能力,将新模型用于软件缺陷检测任务;但是也无法全面提取特征子集,不能进行充分的特征转换,而且级联阶段也导致了特征维度增加,只是无选择的拼接,会使时间和空间开销增大。文献[3]构建了一种具有双视角、深层多粒度扫描的模型,将其用于火焰检测,此模型适用性有限。文献[4]在文献[5]的基础上进一步改进级联森林的输入,即对之前每一层生成的类向量求和取平均值,然后拼接,从而提升性能,应用在情感分类任务上,但取平均会改变生成类向量的原始信息。文献[6-10]在图像和火焰识别上有较好应用。文献[11]通过调整子树权重来提高性能。本文在两个阶段分别做出改进,首先通过环状扫描,重视数据边缘的信息,充分得到特征子集,然后在级联阶段加入一个有效特征选择过程,从两方面来提高模型性能。
2 深度森林
2.1 多粒度扫描森林
深度森林模型是通过多级多层结构来增强表征学习能力的,和深度神经网络类似,以此提升学习能力。深度森林主要由两部分组成,第一部分是多粒度扫描森林,第二部分是级联森林。多粒度扫描过程是为了进行特征转换,来构建更加有效的特征,从而提高级联森林结构的分类能力。原始数据经过不同尺度窗口的扫描,对原始的特征进行一系列的转换,可以得到更加丰富、更加具有差异性的特征子集,特征子集作为输入进入分类器,会产生对应的类概率向量,并将其作为新的特征成为级联森林的输入,特征转换过程到此结束。多粒度扫描图像数据的过程如图1所示。
对于n×n的图像数据,模型首先以大小为m×m的窗口进行滑动,会生成(n-m+1)2个窗口,把这些窗口分别送入一个随机森林和一个完全随机森林,假设是c分类的话,每个窗口都会生成一个c维类概率向量,共生成2(n-m+1)2个类向量,在将向量拼接,成为一个1×2c(n-m+1)2的输入,把n×n的图像数据用1×2c(n-m+1)2的序列数据来表示。多粒度扫描序列数据的过程如图2所示。
同样,对于1×n的序列数据,以大小为1×m的窗口进行滑动,产生n-m+1 个窗口,产生2(n-m+1)个类概率向量,把它们拼接成为一个1×2c(n-m+1)的序列数据作为级联森林的输入。

图1 多粒度扫描图像数据

图2 多粒度扫描序列数据
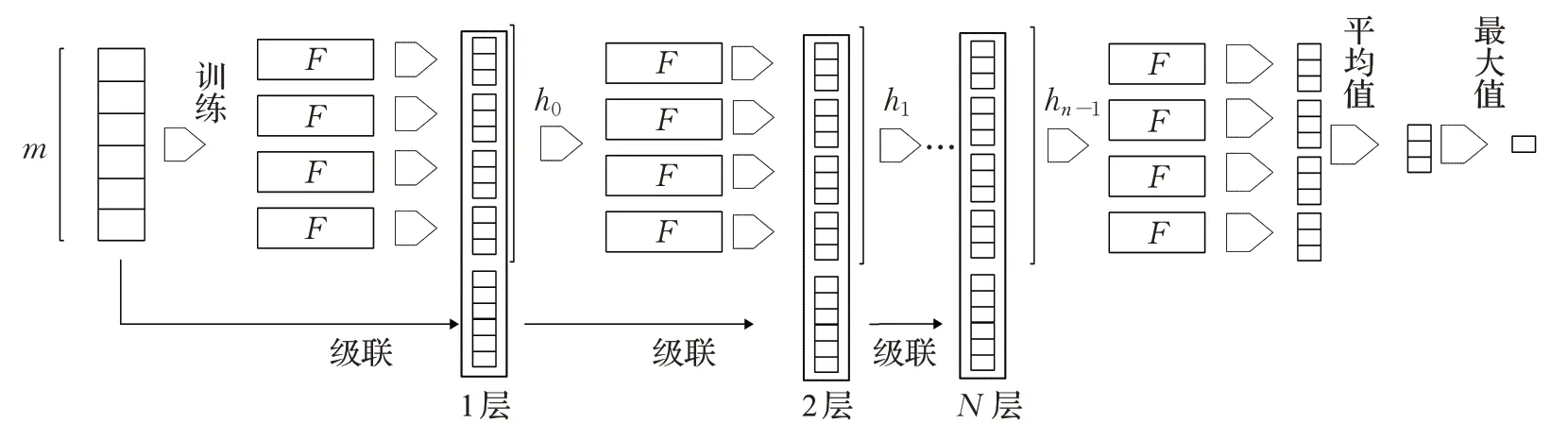
图3 级联森林

图4 流程图
2.2 级联森林
级联部分将多粒度扫描结构的输出作为输入,用转换后的特征向量作为级联部分的输入特征,进入每一层训练层,并经过交叉验证来避免过拟合现象,每层都会验证当前层的分类准确率,如果性能在设定的层数阈值内没有提升,则停止生成下一层,此层成为最后一层,在对真实数据预测时,会级联到此层停止,根据最后一层的预测概率,把每个分类器生成的类分布向量求和,然后取平均值来作为最终的预测结果。假设多粒度森林输出了n维向量,且是c分类任务,首先经过四个随机森林生成4c维类概率向量,之后每层的输入都为n+4c维,直至级联到最后一层,模型停止。级联森林的部分如图3所示。
3 环状扫描的强级联深度森林
从上述模型可以发现,传统的方法在多粒度扫描过程中对边缘数据不够重视,若总的特征维数为n,窗口大小为m,m>2,则第一个窗口生成的特征子集是从第1维到第m维,第二个窗口生成的特征子集是从第2维到第m+1 维……显然,第一维的特征只被扫描了一次,第二维的特征被扫描了两次,最后一维也是如此。只有从第m维到第n-m+1 维,每一维的特征才被充分扫描到;级联森林每一层得到的新特征有限,故表征学习能力得不到有效提高,降低了模型的收敛速度。CSDF 分别从这两方面做出改进,首先通过环状扫描重视边缘数据,继而通过有效特征选择来提高表征学习能力。总体流程如图4所示。
3.1 环状扫描森林
原始的深度森林模型在多粒度扫描阶段不能充分得到每个特征子集,会导致两端的信息特征转换不够充分,换言之,有一部分子集未被转换,倘若被忽略的子集可以转换成有效特征的话,那么这种忽略必定会对转换后产生的新向量产生一定影响,最终导致分类结果的偏差,使分类器的准确度下降。假设图像数据大小为n×n,窗口大小为m×m,会忽略图像四周的信息,只有从第m行、列到第n-m+1 行、列才能被充分扫描。序列数据同理,若窗口大小是1×m,那么第一维和最后一维特征只被扫描一次,从第m维到第n-m+1 维才能被充分扫描。文献[2]通过随机抽样来解决这一问题,但是也不能充分得到每个特征子集,所以本文提出了一种环状扫描的方法来解决此问题,如图5、图6所示。
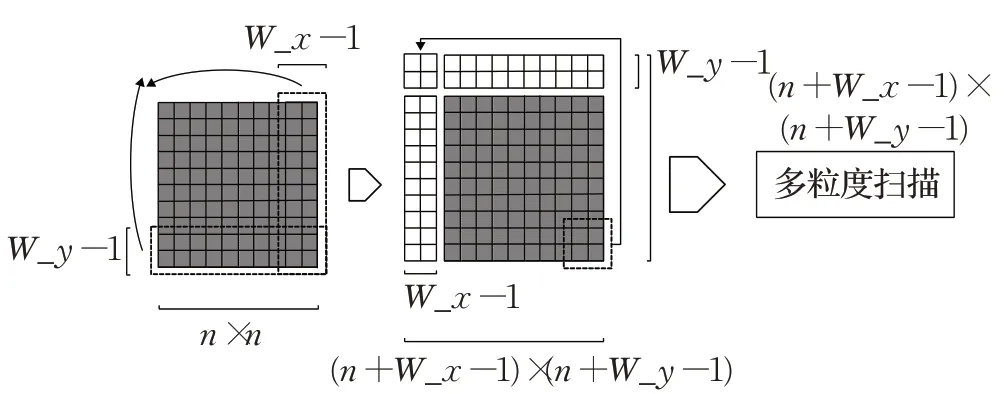
图5 环状扫描图像数据

图6 环状扫描序列数据
对于图像数据,假设滑动窗口大小为W_x×W_y,仅以宽度为第一行到第W_y行的数据为例说明,传统方法扫描每张图片会得到n-W_x+1 个子窗口,每个窗口又会被转换成一个类概率向量,但是转换不够充分,分析可知后端的W_x-1 维数据和前端的第一维数据也可以作为一个窗口,同样后端的W_x-2 维数据和前端的前两维数据也可以作为一个窗口,故为了使模型充分将边缘数据所携带的信息也转换成类概率向量,可将图像改进成为一个左右相接,上下相连的图像,使其成为一个球状数据面,把尾部的W_x-1 列拼接到首部,把下部的W_y-1 行拼接到上部,同时将右下角的数据拼到左上方,显然,变换后数据的每个子窗口都可以被充分提取到,进而转换成类概率向量,更充分、更全面地构建级联森林的输入特征向量。宽度为第n行到第n+W_y-1 行的数据不再赘述。
序列数据同理,假设扫描的窗口大小为1×W_x,传统方法扫描每条数据会得到m-W_x+1 个子特征集,每个特征集被转换成一个类概率向量,转换同样欠充分,后端的W_x-1 维数据和前端的第一维数据可作为一个子集,后端的W_x-2 维数据和前端的前两维数据也可作为一个子集,故将尾部的W_x-1 维特征拼接到首部,使得原始信息成为一个环状数据带,改动之后,可以使两端的特征和中间部分的特征被同等重视,即可被扫描同样的次数,从而使模型把每个数据子集都转换为对应的类概率,将其聚合为较全面的特征向量。
3.2 强级联森林
在级联阶段,仅把前一级生成的类向量作为增强特征,每层只得到较少的增强特征,而且没有重视之层级的类向量,使准确率不稳定,文献[5]称此为疏通连贯性,为防止信息削弱,把之前每层向量拼接,但会引发两个问题,一是必定会引起更大的空间复杂度,降低效率;二是不能选择有效表征,若加入冗余特征,既增大了空间和时间复杂度,又降低准确率。为解决此问题,提出一种强级联森林,在拼接类向量前,先通过前层准确率判断一下此概率向量是否会提高模型的准确率,若可提高,则将其加入初始的特征向量,使其成为特征向量的一部分,反之,初始特征不变。此方法既不会增加维度,又对每层生成的类向量做一个选择,挑选有效表征。第0层的输入是多粒度森林的输出,第1层的输入是第0层的输出和原始向量的拼接,从第2 层开始,在每次拼接之前都会先判断增强向量是否会提高模型的准确率。假设模型此时准备进入第2 层,首先比较0 层和1 层的准确率,若后者较大,则说明0层的输出类向量有效,将其并入原始特征向量,特征向量得到更新,反之,特征向量不做任何改变。在之后的层级时,更新特征向量的判别条件会自动更改为与当前层级中准确率最高的作比较,以此来决定更新特征向量与否。直到模型的准确率不再提升,或者达到设定的阈值时,训练终止。在测试数据时,通过置位标志来决定增强向量的取舍。理论上来说,当类别越多,即c越大时,类概率向量的维数就会越多,故增强向量的维数随之越多,进而在分类任务中的影响就会越大;c越少时,影响就会越少。仅以二分类问题为例,假如级联森林由两个随机森林和两个完全随机森林组成,那么增强特征只是一个8 维特征,而经过扫描阶段转换出的特征维数通常会远远大于这个数字,只有当面对多分类问题时,增强特征才会一定程度上起到更大的作用。强级联森林如图7 所示。级联森林选择增强特征向量的算法1 如下所示。其中X为待输入的特征向量,X'为更新后的特征向量。
算法1 特征选择
输入:X
输出:X'
1. 进入到i层
2. 置位标志=No
3. ifi==0
X'=多粒度扫描森林的输出
elifi==1
X'=(X原+类向量0)
else
if 准确率i-1 >准确率i-2
X'=(X原+类向量i-2)
置位标志=Yes
else
X'=X原
4. end
综上,整个模型完整的过程如算法2所示。
算法2 CSDF
输入:训练集T,测试集S
输出:预测结果的准确率H
1. ifT是高维数据
X'=环状扫描(T)
2.H=强级联森林(X')
3. if没有到达停止条件
调用算法1,训练决策树
4. 输出H,训练结束。
5. ifS是高维数据
X'=环状扫描(S)
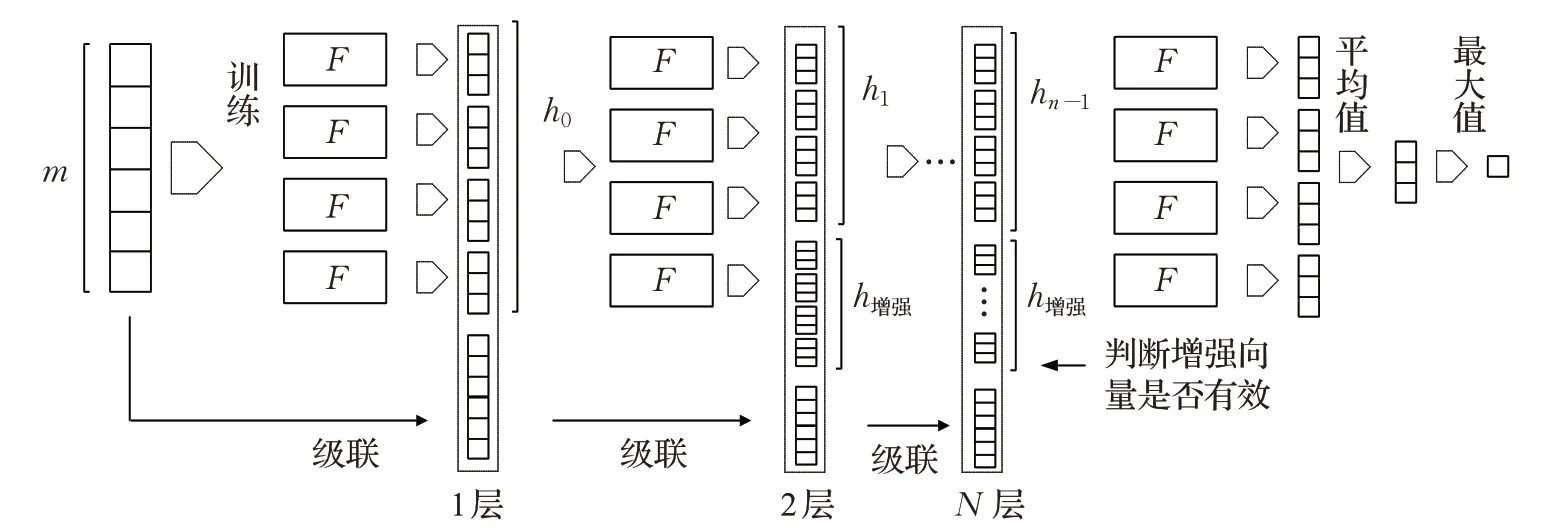
图7 强级联森林
6.H=强级联森林(X')
7. 根据训练时的置位标志,来决定生成类向量的取舍
if 置位标志=Yes
X'=(X原+类向量i-2)
else
X'=X原
8. 到达停止条件时,输出预测结果。
3.3 时间和空间复杂度分析
通过环状扫描,数据的边界部分也会扫描出特征子集,因此会比原始的深度森林模型得到更多的特征子集,从而降低模型的训练效率。深度森林模型的滑动窗口大小是一个超参数,对于原始模型来说,窗口设置得越大,那么生成的窗口数量就会越少,被忽略的信息会越多,扫描后聚合特征的维数会越少。窗口大小设置成和原始数据同样大时,达到极端情况,即子窗口就是原数据的特征集,那么多粒度扫描阶段将毫无意义,仅仅用一个类概率向量作为原数据集的特征,此时就可以根据类概率大小直接判断类别,无需后续的级联森林再次分类。窗口设置得过小,那么生成的窗口数量会增多,虽然被忽略的信息会越少,但是由于每个窗口扫描出的子集都会作为一条数据通过随机森林和完全随机森林产生类概率向量,故窗口变多显然会加大时间和空间复杂度。窗口大小设置为1 时,达到另一个极端情况,每一维特征都会产生一个类概率向量,若是一个c分类任务,一方面由于每个窗口都会作为一条数据,扫描时相当于将原始数据集扩大了c倍,导致特征转换时加大了训练量,另一方面会使聚合特征的维数也扩大c倍,降低级联森林的特征筛选效率,从而会带来额外的时间和空间开销。假设对于n×n的图像数据,原始模型以大小为m×m的窗口进行滑动,会生成(n-m+1)2个子窗口,环状扫描模型会生成n2个子窗口,从而充分将每个子集都转换成对应的类概率向量。对于1×d的序列数据,窗口设置为x,那么传统模型会生成(d-x)+1 个特征子集,本文的模型重视每一维特征,生成d个特征子集,充分进行特征转换。
以上转换方法之所以会一定程度上带来空间和时间复杂度的增大,是因为每张图片或每条数据都会生成多个特征子集,每个特征子集作为一条新的数据,输入分类器中,得到类概率向量,原本一条数据,扩充成了多条数据,无疑加大了时间和空间复杂度。以上分析可知,特征子集过多是根本问题所在。故通过调节窗口滑动的步长来减少子集的数量,从而弱化此问题。对于图像数据,选定第1行到第m行,首先横向扫描窗口,若设置步长为p,那么第一个窗口是第1维到第m维,第二个窗口是第1+p维到第1+p+m维,则共生成n/p个特征子集,接着会选定第1+p行到第1+p+m行开始横向扫描,同样生成n/p个特征子集,直到最后共扫描得到(n/p)2个子集,子集数量变为原来的1/p2;对于序列数据,若设置步长为p,第一个窗口是第1 维到第x维,第二个窗口是第1+p维到第1+p+x维,则共生成d/p个特征子集,子集数量变为原来的1/p,这无疑降低了算法的时间和空间复杂度。此方法在重视每一维的特征向量的同时又减少了子集数量。
其次,当进入强级联阶段时,传统模型经过窗口滑动生成的类概率,送入两个随机森林,图像数据经转换后的特征维数为[(n-m+1)2]×2c维,序列数据为[(d-x)+1]×2c维,而环状扫描后,特征维数分别为2cn2、2cd维,若设置步长为p时,转换后的特征维数分别为2cn2/p2、2cd/p维,所以很大程度上减少了级联森林的输入维数,由于两种随机森林训练时会对特征进行筛选,选择可以使划分后基尼指数最小的特征作为划分点,所以特征维数减少会一定程度上降低时间和空间复杂度。理论上来说虽然准确率和特征维数之间有一定的联系,但是这并不意味着维数越多,准确率就越高,若特征足够好的话,维数较少时也可以达到一个比较理想的准确率。
文献[2]的算法是在扫描阶段随机抽取特征进行转换,同样面临着特征转换不充分的问题,抽取到的特征向量若恰好可转换出有效特征的话,那么就会提高准确率,反之,则不会有明显的优势。其次因为是有放回的抽取,所以公平起见,抽取次数应该和传统模型生成的窗口数相同,所以有很小的概率会抽到同样的特征,假如抽到,就会减少此特征转换成类概率的时间,从而减小少量的运算复杂度。综上,文献[2]的算法一定程度上存在着不稳定性。文献[4]算法是在级联阶段将每层的概率求和取平均得到的,所以维数不会改变,仅仅是多了一个类概率求平均的步骤,即时间和空间复杂度基本持平。文献[2]和文献[5]的算法在级联阶段做出的改进相同,都是聚合了每一层的类概率,特征维数逐层递增,换言之,层数越深,特征维数越大,时间和空间复杂度越大。通过上述分析,理论上来说,扫描阶段时,本文方法通过设定合适的步长来减少空间和时间开销,使模型效率均优于传统算法和文献[2]的算法;级联阶段时,文献[5]的算法效率最低,其他几种方法的效率基本持平,传统方法效率最高。
4 实验
4.1 数据集和算法选择
4.1.1 参与实验的数据集
实验的图像数据集选择手写数字识别Mnist[12],十分类,分别为数字0到9;人脸识别Olivettiface[13],四十分类,四十张不同的人脸;下面列举出了部分图像数据,如图8、图9所示。高维数据集选择手部运动数据Semg[14],六分类;影评数据Imdb[15],二分类。低维数据集选择收入预测数据Adult[16],二分类;字母识别数据Letter[17],二十六分类;酵母菌种类预测数据Yeast[18],十分类。其中Semg 数 据 集 选 取Database 2 中 的male_day_1.mat、male_day_2.mat 进行实验,数据集和测试集以0.8 的比例来划分;Mnist、Imdb数据集均选取原数据集的一万条数据进行训练,两千条数据进行测试。本文数据集的具体描述如表1所示。

表1 数据集具体描述
4.1.2 参与实验的算法
目前深度森林的改进算法已有多种,其中文献[2]和文献[3]对多粒度扫描部分改进,但是后者只针对于图像数据做出了改进,适用性较小,故选择文献[2]的算法参与实验,和CSDF滑步值分别取1、2、3时的CSDF-1、CSDF-2、CSDF-3 的算法,文献[4]和文献[5]的算法对于级联部分做出改进,故也将其加入对比实验,共7 种算法,分别是DF 算法、文献[2]、文献[4]、文献[5]的算法以及CSDF 的3 种算法。低维数据由于特征数量较少,则没有必要进行环状多粒度扫描。文献[2]和文献[5]的算法在级联阶段改进方法是相同的,故低维数据集上的实验算法共4 种,分别是DF 算法、文献[4]、文献[5]的算法以及CSDF算法。所有实验结果均为平均结果。
4.2 实验参数
每个森林包括100棵子树,随机森林随机选取高维数据的特征数为(d为特征数量),为了公平起见,实验采用和传统模型同样的窗口设置,Mnist 数据集的窗口大小分别为13×13、10×10、7×7,Olivettiface数据集的窗口大小分别为32×32、16×16、8×8,其他数据集的窗口大小分别为d/4、d/8、d/16,并且文献[2]模型每次抽取的窗口大小和抽取窗口次数都应与传统深度森林模型相同。级联森林中,每层包含2 个随机森林和2 个完全随机森林,高维数据实验均采用3 折交叉验证,低维数据实验均采用5 折交叉验证。实验的窗口大小如表2所示。

表2 数据集窗口大小设置
4.3 实验平台
计算机配置如下:Intel®CoreTMi7-6700,3.40 GHz处理器,16 GB内存,8核CPU。软件环境为Windows 7系统下的Python3.5。
4.4 实验结果
4.4.1 高维数据结果及分析

图8 Mnist数据集部分数据

图9 Olivettiface数据集部分数据
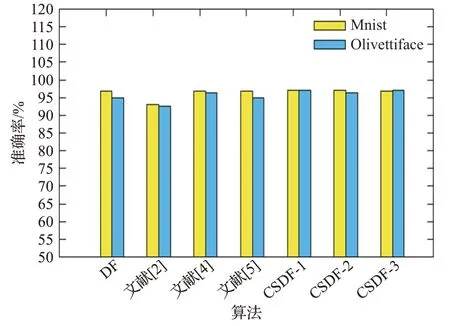
图10 图像数据的准确率对比
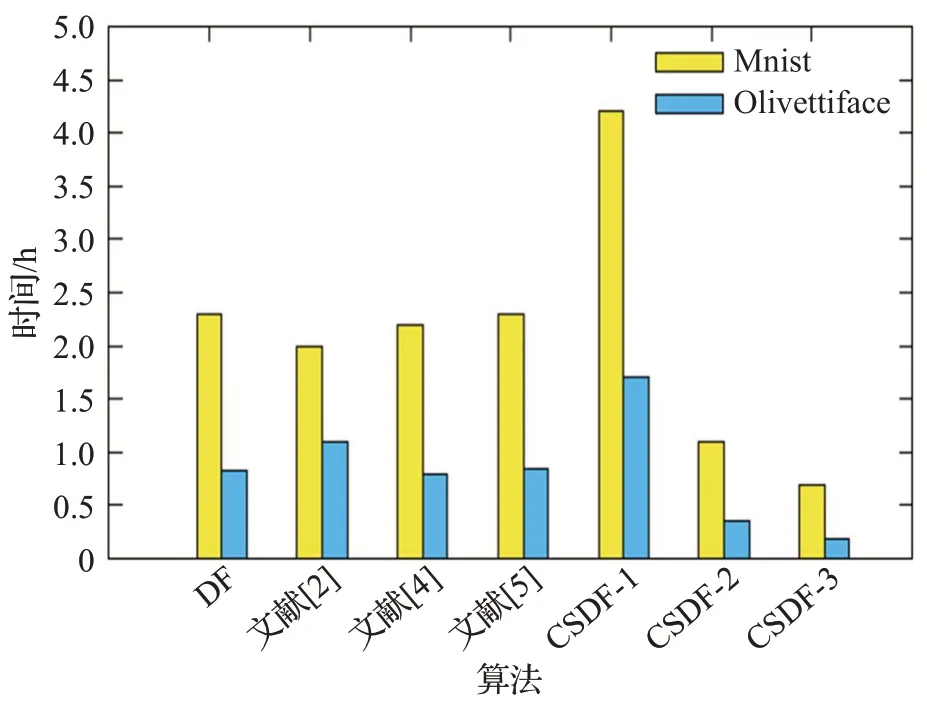
图11 图像数据的运行时间对比

图12 序列数据的准确率对比

图13 序列数据的运行时间对比
从图10~图13 可看出,对Mnist 数据,文献[2]算法准确率在93.00%左右,而另外几种算法的准确率在96.90%左右;对于Olivettiface 数据集,文献[2]算法准确率在92.50%左右,另外几种算法的准确率在96.25%左右,文献[2]较低的原因是处理维数较多的数据时,由于特征是随机抽取,无法判断转换后特征的有效程度,故维数越多时,不确定性越大,对准确率的影响也会越大。本文算法对高维数据中的图像数据集的准确率提升幅度较小,究其原因,一是图像数据的特征之间有关联,二是边缘部分所携带的信息基本相同,非冗余信息大部分位于图像中间,所以转换出的特征不够有效,导致算法准确率的提升有限。对于序列数据,Semg 数据集在传统模型上约为71.25%,文献[2]模型上有所降低,66.00%左右,其他模型的结果基本与原模型持平,本文算法最高可达到73.54%左右。Imdb 数据集在传统模型上约为54.10%,在文献[2]模型上52.00%左右,其他模型的结果同样基本与原模型持平,本文算法最高可达到57.85%左右。由于充分关注了每一维的特征,并转换出对应的概率向量,所以提升比较乐观,文献[4]、文献[5]的算法基本持平的原因在于二者在扫描阶段时方法是相同的,故转换的特征向量也基本相同。运行时间方面,以图像数据Minst 为例,当步长取值为1时,原模型运行时间为2.3 h左右,文献[2]的模型由于产生的特征子集数量和原模型相同,故时间也大致相同,本文算法由于重视了边缘数据,所以产生了更多的特征子集,时间达到了4 h 左右。当步长取值设置为2 时,虽然准确率较前者有所降低,但仍高于原始模型,而且时间仅需1.1 h。究其原因,步长为2 的新模型生成的特征子集数量少于原模型,只是原来的1/4,这大大降低了送入级联森林的特征维数。当步长为3时,准确率已较为接近原始模型。高维数据仅以Semg为例,步长为1 时,原始模型运行时间为9.5 h 左右,文献[2]的模型是随机抽取子集,时间为6.5 h 左右,本文算法产生了更多的特征子集,时间达到了13 h 左右。当步长取值设置为2 时,时间为3.6 h。充分说明了当数据的维数越多时,本文的算法优势越明显,时间复杂度越低。综合考虑,步长为2 的模型更优越,既通过重视每一维特征提高了准确率,又减少了时间和空间复杂度,而且当特征维数越多、数据量越大时,这种优势越为明显。
4.4.2 低维数据结果及分析
图14~图17 的结果表明,Adult 数据集在四种算法上的准确度基本持平,分别为86.26%、86.23%、86.32%、86.37%左右;Letter 数据集在四种算法上的准确度约为97.31%、97.45%、97.38%、97.43%左右;Yeast 数据集在四种算法上的准确度约为61.62%、61.28%、61.58%、61.55%左右,并且波动较大,主要原因是此数据集的特征维数较少,并且训练样本不够多;总体来说,低维数据自身的维数较少,特征不够有效,对于相似的数据,不能达到准确的分类,故四种算法的性能相当。模型的收敛速度大致可以用模型进入的层数判断,进入的层数越少,也就意味着模型的收敛速度越快,可以尽早停止不必要的训练。从实验结果可以看出,传统的深度森林模型平均进入5 层,文献[5]的模型平均进入6 层,其他两种模型都平均进入5.3层。由此可知,对于低维数据,四种改进模型都有着相当的性能,而且后两种算法收敛速度略快于第二种算法。具体的实验结果准确率对比数据如表3、表4所示。
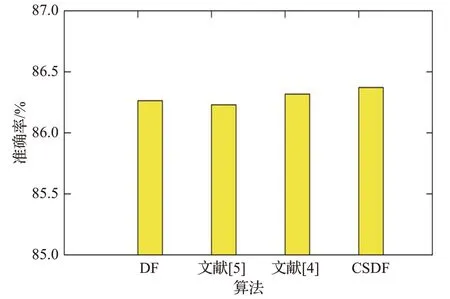
图14 Adult数据的准确率对比
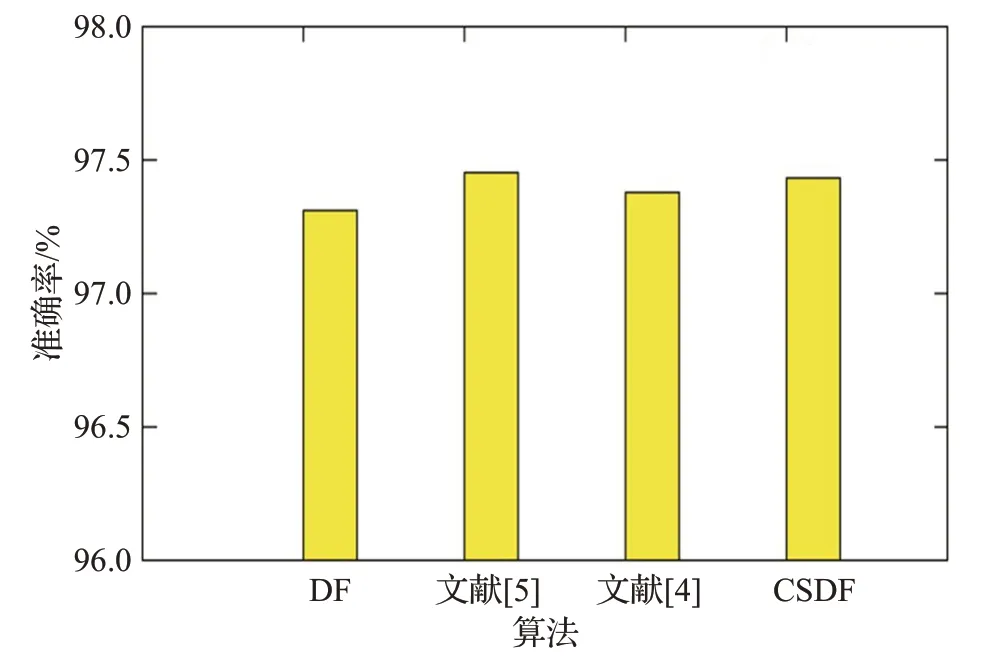
图15 Letter数据的准确率对比
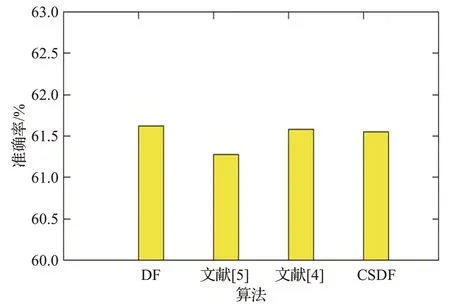
图16 Yeast数据的准确率对比

图17 低维数据的层数对比
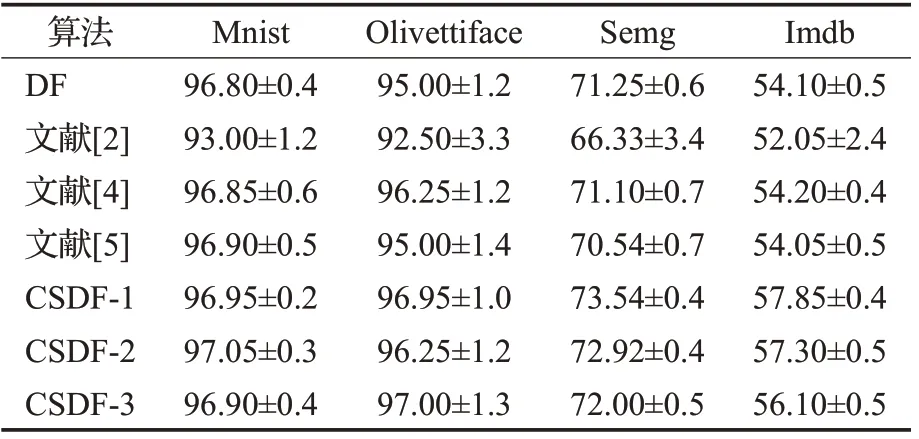
表3 高维数据实验结果对比 %
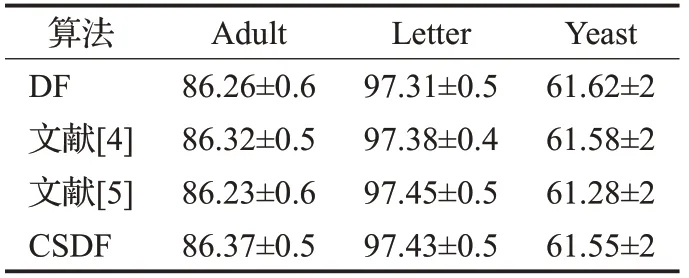
表4 低维数据实验结果对比 %
5 结束语
本文针对深度森林算法在多粒度扫描阶段不能充分将样本两端数据的信息转换成对应的特征以及在级联森林阶段每层获得增强特征较少的问题,提出了一种环状多粒度扫描的算法,通过此方法在一定程度上充分转换特征向量,构造出较完备的特征,并在不同数据集上的实验,验证了此方法可以提高深度森林模型的性能。但这种方法也存在着不足,首先CSDF方法若对原始数据进行充分转换,就会生成更多特征子集,一定程度上提高时间和空间复杂度;其次级联部分的表征阶段虽然选择了较为有效的特征,但是也不能对模型起到较大程度的影响,算法的性能仍然提高幅度有限。下一步将围绕如何兼顾扫描阶段的效率和准确率以及更有效、更全面地选择级联层的有效表征的问题来展开研究。
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子制作(2016年15期)2017-01-15 13:39:09
系统工程与电子技术(2016年2期)2016-04-16 05:16:51
都市丽人(2015年4期)2015-03-20 13:33:22
