
基于残缺数据的煤与瓦斯突出预测系统
2021-04-23 12:48汝彦冬吕兴凤郭继坤张洪全陈丽娟
哈尔滨商业大学学报(自然科学版) 2021年2期
汝彦冬,吕兴凤,郭继坤,张洪全,陈丽娟
(1.黑龙江科技大学 电子与信息工程学院, 哈尔滨 150027; 2.黑龙江大学 计算机学院, 哈尔滨 150080)
煤与瓦斯突出是在压力作用下,短时间内粉碎的煤与瓦斯突然向采掘空间大量喷出的现象[1],煤与瓦斯突出给煤矿安全生产和井下工作人员的生命安全带来了极大威胁.我国是煤与瓦斯突出灾害严重的国家之一[2],迄今为止还不能有效遏制煤与瓦斯突出事故的发生[3].因此,预测煤与瓦斯突出,对于煤矿安全生产意义重大.
很多学者根据煤与瓦斯突出的主要影响因素,提出预测方法,其中最常采用的方法是提取和煤与瓦斯突出关系密切的特征数据,利用机器学习模型进行预测[4].数据分为事故数据和非事故数据,实际当中非事故数据很容易得到,数据量大并且完整,事故发生后很难找到事故数据导致事故数据较少[5].在实际应用中,收集到的数据经常缺少部分变量,导致数据不完整[6],从而导致这些预测系统精度低、不稳定和易过拟合等问题.因此,本文选择对煤与瓦斯关系密切的5个指标作为特征数据,对数据中的异常值进行处理,针对数据中缺少变量的问题,采用多种方法完成了缺失数据的插补工作,采用多种机器学习方法完成煤与瓦斯突出的预测,通过实验找出最适合煤与瓦斯突出预测的数据插补方法和预测模型.
1 预测系统
1.1 煤与瓦斯突出预测系统
本文设计了煤与瓦斯突出预测系统,结构框图如图1所示.建立基于完整事故和非事故数据的训练集,并建立预测模型,应用在煤与瓦斯突出预测任务中.对现场采集的数据,完成数据预处理后,利用预测模型完成事故和非事故的预测.根据煤矿安全专家的建议,将预测时采用的数据和预测结果补充到训练集,扩大训练集的容量,定期更新预测模型,让预测模型泛化性更强.
1.2 特征选择
煤与瓦斯突出是多因素相互耦合的突发性动力灾害,成因复杂,影响因素多[7].本文根据现有的研究成果,认为影响煤与瓦斯突出的因素包括煤层地质条件、煤体自身的物理力学性质及煤体中所含的瓦斯情况[8],选择瓦斯含量、瓦斯压力、孔隙率、煤层坚固系数和瓦斯放散初速度作为数据特征[9].
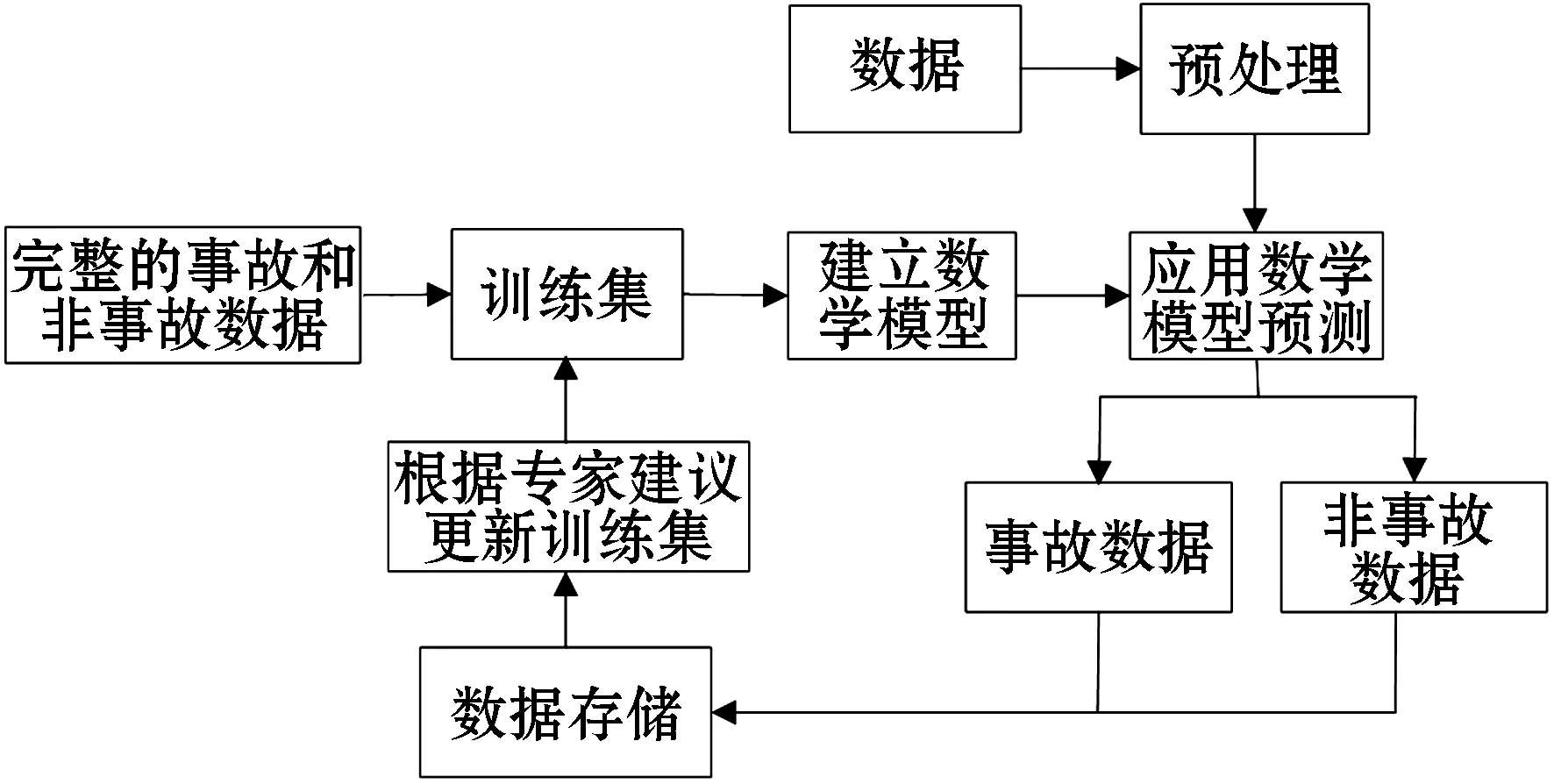
图1 煤与瓦斯突出预测结构框图Figure 1 The Structure of coal and gas outburst prediction
1.3 数据预处理
在煤与瓦斯突出预测中,异常值和缺失值是影响数据质量的主要原因,数据质量直接影响了预测性能[10].为此,提高数据质量对提高煤与瓦斯分类性能意义重大.本文通过数据预处理提高数据的质量.数据预处理方法如图2所示.

图2 数据预处理框图Figure 2 The Structure of data preprocessing
首先检查5个特征缺失的变量个数,如果缺失变量个数大于2个,则认为数据质量达不到要求,直接删除该数据,否则,采用异常值检测方法,检查每个属性是否存在异常值,如果存在异常值,则认为异常值的存在会影响整体的检测效果,把异常值删除掉后继续检查缺失变量个数.如果缺失值个数为1或者2,则采用数据插补方法完成数据插补,否则,抛弃该数据.
1.3.1 异常值处理
实际当中由于设备精度的限制、噪音的干扰或者其他原因,存在数据异常的情况,这种情况下,必须对数据进行纠正,否则异常数据会直接影响分类性能.为此,本文采用拉依达完成异常数据的处理工作[11].
拉依达准则描述如下:当第i点样本值Xi满足:
(1)

(2)
(3)
本文根据拉依达准则完成数据检查,如果数据显示为异常数据,则删除该数据,继续检查缺失变量值个数,如果达到3,则认为该数据质量达不到处理要求,将其删除.
1.3.2 缺失值插补
数据插补算法分成2类:一类是基于统计学的;另一类是基于机器学习模型的[12].不同插补方法有各自的优势和不同的应用场合,本文选择统计学中具备代表性的均值插补、多重插补和机器学习中具有代表性的K近邻插补、随机森林插补完成数据插补.均值插补就是计算该变量的数值平均值,并将其作为缺失值的插补值.多值插补是在同一插补算法下对缺失值插补M次,得到M个完整数据集,然后根据融合准则计算最后插补结果[13].随机森林数据填补就是将缺失值作为未知量,将其他值作为特征属性,将通过随机森林模型预测得到的值作为缺失值[14].K近邻插补基本思想是:如果一个样本在特征空间中的K个最相似(即在特征空间中最接近)的样本中的大多数属于一个类别,那么该样本也很有可能属于这个类别,将这K条记录的加权均值作为缺失值[15].
2 实验部分
2.1 数据介绍
本文针对事故数据和非事故数据采用不同的方法进行处理.在初始训练集建立时,非事故数据量大并且完整,遇到数据不完整情况,直接删除数据,事故数据采用数据预处理方法完成数据处理.系统实际运行时,对所有接收到的数据进行数据预处理.本文共选择246条非事故数据和62条事故数据作为实验数据,部分数据如表1所示.表中“-”表示数据缺失.

表1 数据示例(部分)
2.2 数据插补
本文分别采用采用均值插补、多重插补、随机森林插补、K近邻数据插补方法完成数据的插补,对缺失数据的插补结果如表2所示.
从表2可以看出,采用4种方法分别完成了缺失数据的插补工作,从数值上看,4种数据插补方法结果存在较大差距,具体哪种插补效果更好,迄今为止没有统一的衡量标准,特别是针对数据量很少的事故数据,最可靠的方法就是通过和预测模型配合使用,通过预测结果来判断在煤与瓦斯突出预测任务中数据插补方法的优劣.

表2 数据缺失值插补结果(示例)
2.3 数据分类
本文采用精确度、敏感度、特异度作为模型性能评价指标.三种评价指标定义如下:
(4)
(5)
(6)
其中:TP是正确分类非事故数据的个数,FP是把非事故数据错分成事故数据的个数,FN是把事故数据错分成非事故数据的个数,TN是正确分类事故数据的个数.
本文采用机器学习方法中具有代表性的随机森林,支持向量机和K近邻三种模型完成预测,采用网格搜索法对预测模型参数进行优化,采用10折交叉验证的方法进行交叉验证,使用R语言实现预测,预测性能如表3所示.
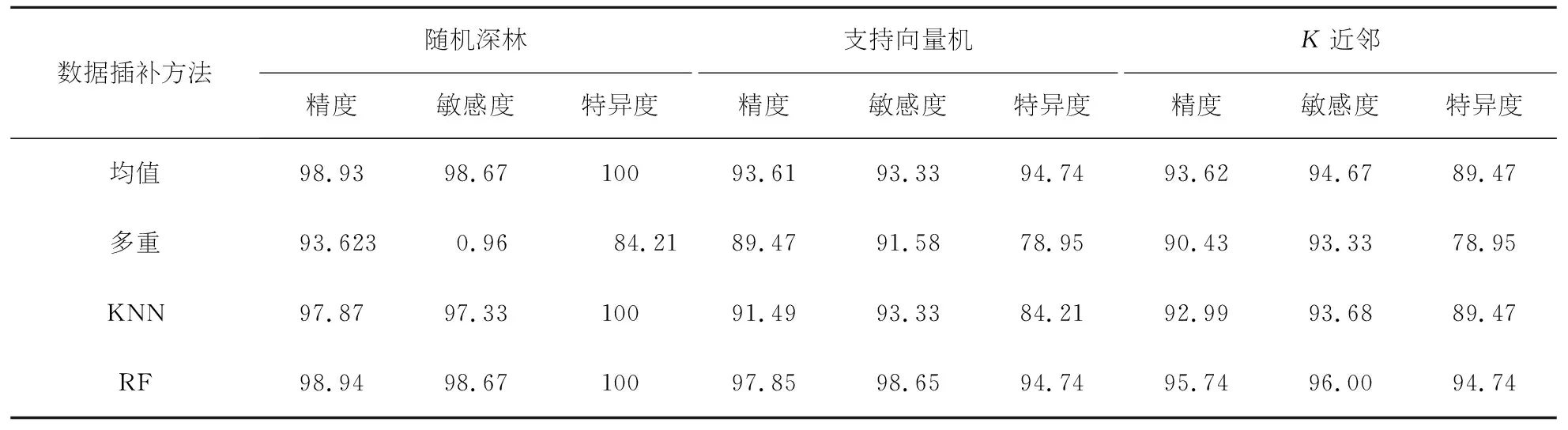
表3 预测性能(%)
从表3可以看出,如果采用相同的数据插补方法,随机森林模型完成的预测性能整体上要优于支持向量机模型和K近邻模型.采用相同的预测模型,利用随机森林数据插补法完成数据插补得到的性能最好.综上所述,在煤与瓦斯突出预测应用中,采用随机森林模型完成数据插补后利用随机森林模型完成的预测性能最好.
3 结 语
本文选取了和煤与瓦斯突出相关的5个特征,完成了特征数据的异常值处理和缺失变量的数据插补工作,分别采用随机森林,支持向量机和K近邻三种模型完成煤与瓦斯突出预测.实验结果表明,采用随机森林作为数据插补方法和预测模型的煤与瓦斯突出预测系统,取得了精度98.94%、敏感度98.67%和特异度100%的优越性能,是所有插补方法和预测模型组合中性能最好的,可以应用在煤矿安全生产中.
猜你喜欢
材料与冶金学报(2022年2期)2022-08-10
温州大学学报(自然科学版)(2022年2期)2022-05-30
煤炭科学技术(2022年2期)2022-03-26
小学生学习指导(低年级)(2021年9期)2021-10-14
粉末冶金技术(2021年3期)2021-07-28
建材发展导向(2021年23期)2021-03-08
煤(2020年5期)2020-12-02
科技视界(2020年22期)2020-08-14
小学生学习指导(低年级)(2019年9期)2019-09-25
学生导报·东方少年(2019年27期)2019-01-14
