
计及经济因素的随机森林电量预测
2021-04-22 09:17屠一艳徐久益杨晓雷李自明姚剑峰
浙江电力 2021年3期
屠一艳,徐久益,杨晓雷,李自明,姚剑峰
(1.国网浙江省电力有限公司嘉兴供电公司,浙江 嘉兴 314000;2.国网浙江桐乡市供电有限公司,浙江 桐乡 314500)
0 引言
用电量是经济发展的“晴雨表”。经济增长对电力具有很强的依赖性,而经济的快速增长也会刺激用电量的迅速增长。用电量预测是实现区域电力电量平衡、电网精准投资、规范电力现货市场交易的主要依据。因此,用电量的准确预测既是电网发展规划、生产经营的基础,又是地区经济社会发展变化趋势的“风向标”[1-2]。
目前,各行各业对电力能源的依赖性日益显著,加之国内各地区居民电气化水平差异大,导致对电能消费需求变化趋势不同,用电量呈现多因素化、变化复杂的特点,这对准确预测月用电量提出了挑战[3]。传统的月度电量预测方法如趋势外推法、时间序列预测法、半参数统计法和BP神经网络等预测方法[4-7]虽然成熟,但多以历史纯电量数据为预测依据,预测模型难以适应当前电力需求增长的诸多因素。一些学者对月度用电量的预测方法不断进行改进,并取得了一定成果。文献[8]在传统多元回归预测模型的基础上,构建温度和经济增长因素为输入的月用电量预测模型,对历史数据拟合得较好,但预测方法中的经济因素只考虑到规模以上工业增加值,不足以表现经济因素的影响。文献[9]综合了灰色关联分析法、多变量时间序列法优势,将区域用电量相关影响因素进行关联分析,虽然预测精度较高,但输入的社会经济变量较少,预测结果呈现出季节性波动。文献[10]利用多元线性回归与神经网络算法各自的优势,提出组合优化预测方法,既把握了用电量的整体趋势,又抓住了细节波动变化,预测精度得到有效提高,但预测模型只验证了短期预测的精准性,中长期电量预测精度还有待验证。因此,在充分考虑各经济因素发展趋势及“新常态”下的中长期用电特点,研究区域用电量精确预测方法具有重要现实意义[11]。
本文以区域历史用电量数据和多种经济因素为基础,挖掘两者的关联规律和特点,采用随机森林算法构建电量预测模型,并检验预测模型的优越性,为地区月度用电量预测和电网建设提供参考依据。
1 数据分析与挖掘
电量预测的核心是依据历史用电量数据,以及对用电量产生决定性作用的区域经济、气候等因素的历史数据,利用科学的算法进行分析,并建立预测模型来描述未来一段时间的用电量发展规律。因此,在选择合适的算法以及建立预测模型之前,对各类原始数据进行分析和处理(通过研究和处理历史数据,挖掘原始数据内在关联性和规律性)至关重要[12-13]。
1.1 数据分析
本文数据来源于南方某区域电网公司近4 年的月用电量数据(见表1)及该区域统计局公布的四类主要月度经济指标(见表2),原始数据中用电量为一维,相关经济数据为四维。由表1 可知,该地区的月用电量整体呈上升趋势,每年的月用电量变化特性基本一致,具有周期性和惯性特点。鉴于篇幅,本文只列出上半年和全年的四类经济数据,利用已知的数据来预测该区域2019年1—12 月的用电量。
作为一个多输入系统,考虑的输入量越多对系统的输出预测越准确,但为了简化电量预测模型,需要找到影响程度较大的因素,这就需要进行相关性分析[14]。相关系数是表示2 个变量(x,y)之间线性关系密切程度的指标,用r 表示,其定义为:

表1 南方某区域电网公司近些年各月电量情况(已脱敏处理)

表2 南方某区域相关经济数据(已脱敏处理)

式中:xt为月用电量数量;yt为四类经济数据;分别为xt和yt的平均值。
其中r 的绝对值越接近于1,说明相关关系越显著。通过分析用电量与经济因素的关系可以发现(见表3),用电量与相关四类经济数据具有较强的相关性,相关系数r 均大于0.9,说明它们之间相关关系较显著。因此,本文将这四类经济因素作为电量预测建模研究的关键因素。

表3 相关性分析
1.2 数据预处理
高质量的输入数据是整个预测工作的前提,历史数据的平滑性直接关系到模型拟合与预测结果的精度。因此,本文将对原始数据进行预处理,主要是清洗原始数据,即选择合适的方法对原始数据中的明显错误值、异常值和可疑值进行“处理”。
本研究数据预处理的整体流程如图1 所示。首先对原始电量数据进行观察分析,发现没有缺失点和重复数据;其次使用统计量χ2检测原始数据中的异常值。统计量χ2可以用来检测一组数据中的离群点,对于某个对象,χ2统计量是:χ2=(xi-μ)2/μ,其中,μ 是所有对象的均值。如果对象的χ2统计量大于选取的阈值,那么该对象就被认为是离群点。通过该方法可以检测出2016 年2 月和2017 年2 月的用电量值为异常数据。
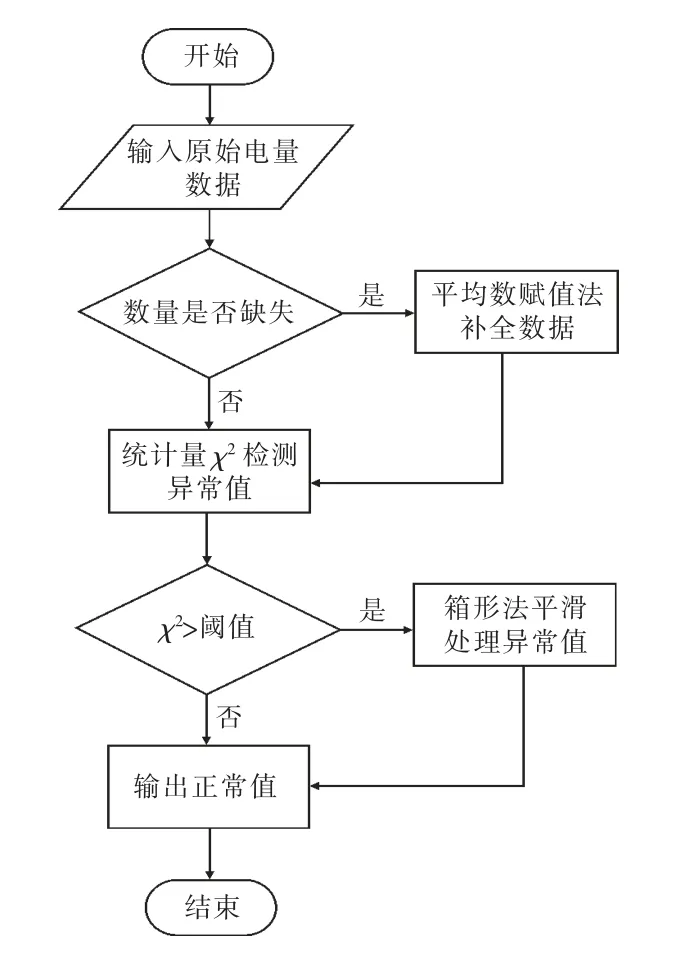
图1 数据预处理流程
检测出异常值后还需对其进行处理,异常值的处理方法主要采用数据平滑技术,按数据分布特征修匀源数据。具体方法有分箱、聚类和回归等[15-16]。本文采用分箱方法,通过考察相邻点来平滑异常数据值,即取异常值的纵向和横向相邻数据的均值来替换异常值,从而进行局部平滑。
2 电量预测模型
2.1 算法分析
目前,基于经济因素的中长期电量预测方法应用广泛的主要有多元回归预测算法和时间序列自回归预测算法,其中多元回归预测算法中用电量的影响因素很难量化,即使能够量化,量化指标的获取一般也相对滞后,因此在实际预测中具有一定的局限性;而基于时间序列的自回归等预测算法应对某个因素波动较大时,不能及时将其变化作用在预测结果上,导致短期预测结果偏差可能较大。鉴于原始用电量数据惯性和周期性等波动特点,以及1.1 节分析的相关性较高的四类经济数据特点,需要寻找适合多维原始数据输入且符合数据特性的预测方法,以得到比较准确的预测结果。
因此,充分考虑了用电量与经济指标之间的相互影响,本文选用随机森林算法[17]作为数学模型的主要预测方法,并与指数平滑法相结合。在整个预测过程中的每一步都会根据实际需求而选用不同的算法模型,既符合原始数据规律特点,又充分发挥了各模型算法的优势,使预测效果最优化。首先,通过指数平滑法,利用其算法适合于历史电量数据在短期内波动保持惯性的特征优势,对用电量进行初步预测;其次,通过随机森林算法相比传统回归算法具有不容易过度拟合、不限制于数据维度大小和可处理高维度数据的优点,把与用电量相关性很高的四类经济因素作为随机森林算法的输入进行训练,对初步纯电量预测的用电量数据进行修正,从而得到最终贴近实际的预测值。
随机森林算法是基于投票法构建多棵决策树对样本进行分类的集成学习算法[18],原理如图2所示。其核心思想是将每棵决策树的分类结果进行统计,最终将样本划分为得票最多的类别。随机森林随机选择样本、特征,降低了决策树之间的相关性。

图2 随机森林原理
2.2 预测模型
区域用电量曲线特征大致具有一定的周期性、时序性,一般以月为单位,每年电量曲线变化趋势相同。选取多项式分别拟合历史年的用电量曲线,再通过指数平滑法,即采用线性指数平滑模型Ft+m=at+btm(Ft+m为t+m 月的用电量预测值;at为平滑值序列差;bt为一次平滑步长参数),利用预测数据的变化在短期内保持惯性的特征,得到2019 年用电量初步预测值,如表4 所示。

表4 电量初步预测结果
由表4 可知,虽然指数平滑法能将经济因素的影响作用反映在预测的变化趋势中,但用电量的影响因素在电量预测过程中不能得以充分反映,当某个因素发生突变时,就会导致短期预测结果偏差较大,所以需要对初始电量预测值进行修正。引入经济数据的影响后,把四类经济数据输入随机森林算法进行训练,利用初步预测的用电量与各经济因素之间的关联性预测2019 年1—12 月的四类经济数据。图3 所示为2015—2018 年数据的部分运行结果。

图3 规模以上工业增加值实际值与预测值对比
由图3 可知,通过初始电量预测值可以较为准确地预测出规模以上工业增加值。鉴于预测最终用电量模型是多输入单输出,输入2019 年1—12 月初步预测的经济指标数据和月用电量数据,完成对初步纯电量预测值的修正,从而输出2019年1—12 月的最终用电量预测数据。这种预测方法能直接反映用电量与各类经济因素的影响关系,在数据完善的情况下,预测结果比较贴近实际值。月用电量变化曲线如图4 所示。

图4 月用电量变化曲线
3 算例分析
为验证该预测方法的实际效果,将目前使用最广泛的时间序列预测、灰色预测[19-20]方法与本文方法进行预测对比,3 种算法对比结果见表5。

表5 不同预测方法结果对比
由表5 可知,本文研究电量预测MAPE(平均绝对百分比误差)为2.34%,而采用时间序列预测法和灰色预测法的预测误差均高于本文方法。由此可见,本文研究方法预测精度得到了有效提高,且采用经济数据对预测结果进行修正后,预测误差由3.74%降低到2.34%,具有更高的稳定性和精确性,预测结果更加合理,也更加贴近实际值,如图5 所示。
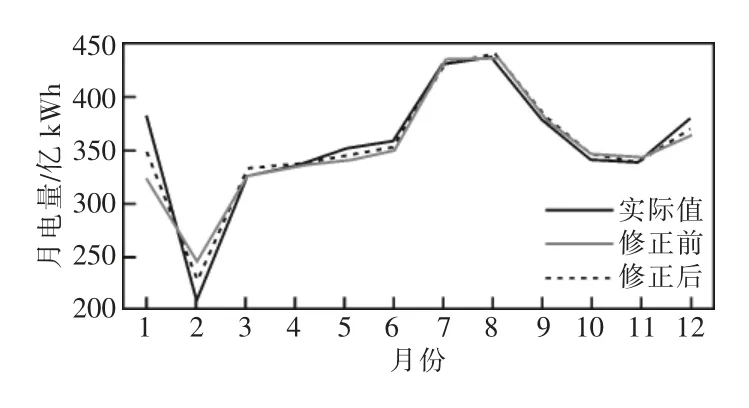
图5 经济数据修正前、后电量预测曲线
与此同时,本研究收集了西部两省份相同的月用电量数据与四类经济数据,将该模型运用于与南方区域电量波动、气候条件以及经济结构差异较大的西部两省份进行预测,以便对模型的预测精度及通用性进行验证。验证结果见表6。

表6 不同省份预测结果对比
由表6 可知,该模型在西部两省份预测的MAPE 分别为3.44%和2.75%,证明了该预测方法通用性强、具有较高的预测精度,可适用于不同地区的电量预测。
4 结论
本文首先引入了经济因素对电量预测的影响,在建立用电量预测模型前对原始数据进行分析和处理;其次采用指数平滑法对月用电量进行初步预测;再通过随机森林算法用四类经济数据对月用电量预测值进行修正;最终得到更加接近于实际值的月用电量。通过实际算例仿真验证,得出以下结论:
(1)充分考虑经济因素与用电量之间的关联性。加入与用电量相关性很高的经济因素变量的输入,有利于模型预测精度的提高。
(2)采用随机森林算法进行预测。随机森林算法具有不容易过度拟合,不限制于数据维度大小,可处理高维度数据,并检测维度间的相互关联,通过高维映射、记忆等手段大量挖掘数据的内在规律,得到用电量变化的波动趋势等优点,符合预测模型要求,使预测精度有进一步的提高。
在预测过程中,本研究根据实际需求选择不同的算法模型,发挥模型算法的优势,使预测效果最优化。算例证明了该预测方法通用性强,为地区中长期电量预测提供了一种新思路。
猜你喜欢
电力设备管理(2022年16期)2022-11-26
电力设备管理(2022年8期)2022-11-25
China Report Asean(2022年8期)2022-09-02
军事文摘(2022年16期)2022-08-24
物联网技术(2020年12期)2021-01-27
电力勘测设计(2020年4期)2020-12-14
四川水力发电(2018年4期)2018-03-25
汽车零部件(2017年4期)2017-07-12
铁道通信信号(2016年8期)2016-06-01
电测与仪表(2014年16期)2014-04-22
