
基于自然语言处理的故障应急事故报告自动生成研究
2021-04-22 09:17张锋明陈武军陈明强
浙江电力 2021年3期
钱 钢,金 鑫,张锋明,朱 峰,陈 楠,陈武军,陈明强,汪 力
(1.国网浙江省电力有限公司绍兴供电公司,浙江 绍兴 312000;2.宁波天灵信息科技有限公司,浙江 宁波 315000)
0 引言
为掌握故障应急事故发生情况,采取有效的防控方案,需对故障应急事故实施常规分析[1],各级故障应急事故管理单位需依据相关标准,结合当前监测数据对故障应急事故实施分析并编写报告[2]。由于故障应急事故报告中包含大量数据,且需对这些数据进行多次统计分析,导致报告中容易出现大量重复内容和错误数据[3]。同时由于检测报告来源不同,其内容与格式也有所差异,相关学者对此进行了研究,周启等人[4]以大坝安全监测资料分析报告自动生成系统为研究对象,以系统方案、实现技术、功能要求等为研究内容,实现监测资料整编分析报告生成的自动化、规范化和专业化,该系统科学高效,满足水库大坝安全管理需要;杨梦、周恩波[5]构建了一个基于专家系统的煤矿事故现场处置报告自动生成系统,系统整合了应急预案、安全规章制度、领域专家和事故案例的救援处置方法以及经验知识,在发生事故时可以根据事故现场实时信息,匹配规则进行推理,得到所需处置措施,指挥人员还可以输入查询信息,搜索符合查询条件且与当前事故特征最相似的历史事故案例,获取真实历史救援经验知识支持。但上述方法受时间与需求影响,应急报告内容与格式会有所变化,因此需要提出一种更加有效的故障应急事故报告自动生成方法。
作为计算机科学领域和人工智能领域的主要研究内容之一,自然语言处理技术包含语言学、计算机科学等数门科学内容,通过研究日常使用的自然语言,利用计算机正确处理人类自然语言,实现人与计算机间自然语言有效沟通[6]。因此,本文基于自然语言处理技术对故障应急事故报告自动生成方法进行了研究。
1 故障应急事故报告自动生成方法
1.1 故障应急事故报告自动生成方法结构设计
基于自然语言处理的故障应急事故报告自动生成方法主要由数据来源、数据标准处理、资料分析、报告生成等环节组成,具体结构如图1 所示。
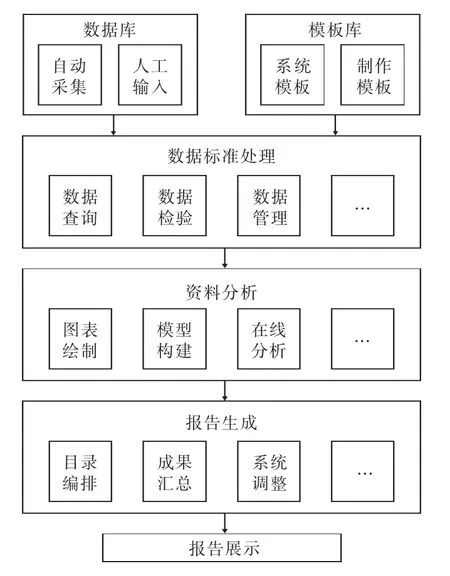
图1 故障应急事故报告自动生成结构
基于自然语言处理的故障应急事故报告自动生成方法中,数据来源由数据库与模板库共同组成[7],将所采集的监测数据纳入到数据库内,同时依照相关标准定制可配置的模板库,数据来源是故障应急事故报告自动生成的基础[8]。
数据标准处理是以数据来源为基础,对相关数据进行数据查询、管理与检验等操作,其中数据管理采用OLE(对象链接和嵌入)服务功能,利用该功能可将采集于不同应用程序的数据信息创建为复合文档[9],适用于大部分类型数据。Visual C++完全支持OLE 自动化,通过Visual C++能够有效编译自动化控制器,控制Word 等文字处理应用程序,协同完成报告自动生成任务。采用这种方法,可在无须人工操作的条件下,令两个应用程序自动相互作用。
资料分析环节依照数据标准处理、模板格式与内容要求,基于相关数据进行图表绘制、模型构建与在线分析,考虑故障应急事故专业需求,可在部分有需要的条件下提供在线分析,完成专业数据分析。数据在线分析过程中采用自然语言处理技术,利用基于词典与规则的语法分析算法,可令生成的故障应急事故报告具有更强的适应性[10]。
报告生成环节依照资料分析结果与模板需求,自动进行监测数据分析报告配置与生成,用户可依照实际需求与自身习惯在Web 端设计模板报告样式,在服务器终端自动生成报告并展示。
1.2 数据检验
由于数据库内的数据来源于不同应用程序,为保障生成报告内数据的准确性与统一性,需要数据进行检验处理,利用得分匹配法对数据进行缺失值借补处理[11]。
由于数据管理过程中不同变量间具有一定相关性,因此考虑故障应急事故统计数据的纵向数据集的变量特点,选取得分匹配法实施借补,即在包含完整数据的时间点记录内,确定与缺失数据时点记录内未缺失变量取值得分匹配度最高的时点记录,基于该完整时点记录内的对应变量值,结合实际变量完成数据借补,详细过程如下。
以Xit表示变量,其中,i=1,2,…,I 表示变量数量,t=1,2,…,T 表示变量取值的时点数量。在X11缺失的条件下,可在包含完成数据的记录内确定一个t 值,由此令匹配值k 为:

其中,∂i表示依照第i 个变量观测数据确定的标准差。不同时点下变量的取值差异除以∂i的主要目的是消除不同变量的量纲差别。
基于式(1)得到借补值为:

检验完成后,利用OLE 服务功能,将采集于不同应用程序的数据信息创建为复合文档。
1.3 自然语言处理技术
利用计算机准确处理人类自然语言,分析并明确自然语言的含义是自然语言处理技术的主要目标[12]。基于上述创建的复合文档,利用自然语言处理技术能够提升故障应急事故报告的适应性。自然语言处理流程图如图2 所示。
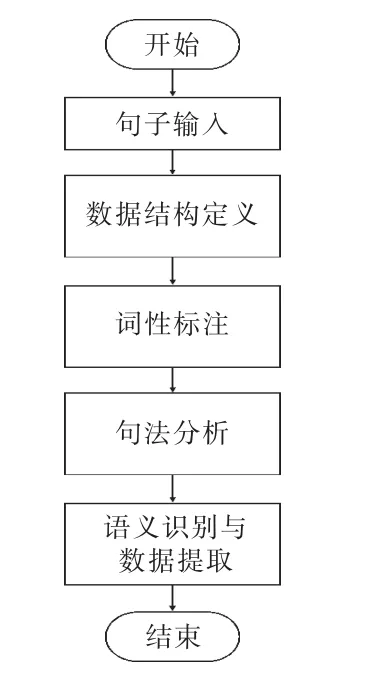
图2 自然语言处理流程
对复合文档内的句子进行自然语言处理的过程包括数据结构定义、词性标注、句法分析、语义识别与数据提取等。
1.3.1 数据结构定义与词性标注
数据结构定义是将复合文档内的数据信息划分为单词与句子两个数据结构。
单词结构所体现的是单词内的文字、词性与句子成分等属性,并对单词的基本操作实施定义。单词词性可通过单个字母代表,如表1 所示。词性标注可依照故障应急事故报告的详细要求进行对应的修正与扩展[13]。
句子结构内存在一个哈希表,其主要功能是存储句子内的全部单词,并对句子的基本操作(如句子长度、附加单词等)进行定义。

表1 词性分析
1.3.2 句法分析
可将一个给定的输入句子确定句法分析树的过程理解为是句法分析过程[14]。例如复合文档的输入语句为:“The machine is running”。其句法分析树如图3 所示。

图3 句法分析树
输入语句由名词短语和动词短语共同组成,两者分别由冠词、名词和动词、形容词组成。
句法分析算法使用改进的图句法分析算法,有n 个词语的语句的图由n+1 个顶点与数条连接顶点的边组成,若一条边与相邻边匹配,则可将其扩展后置入图内,初始边则定义为新边的孩子边。这样,句法分析结束后,仅需确定由第一个节点至最后一个节点的边,即可获取一棵语法分析树,利用这棵树能够实现全部边的遍历。
1.3.3 语义识别与数据提取
由于报告中所用信息来源于不同应用程序,因此普遍存在信息重复的问题,考虑故障应急事故报告内容清晰性与简洁性要求,需要通过一致度比较算法确定一致度较高内容,并清除多余内容。一致度描述的是两者间的共性与区别[15],两者间的共性与一致度之间呈正比例相关;两者间的区别与一致度之间呈反比例相关。
一致度计算过程中采用基于向量空间模型的文本一致度算法,向量空间模型内,可将故障应急事故报告定义为由相互独立词条组(C1,C2,…,Cn)组成,统计单个词条Ci的数量,确定Ci的词频,确定整个故障应急事故报告内Ci词条所占的权重,以Qi表示。由此可将故障应急事故报告文本间的一致度转换成向量间夹角的余弦值,通过夹角描述一致度,两者间呈反比例相关,即夹角越大,对应的一致度值(余弦值)越小,文本间一致度越低。以P1和P2分别表示两份来源不同应用程序的信息文档,则可通过式(3)描述P1和P2间的一致度:

利用式(3)可确定两份来源于不同应用程序的信息文档的一致度,设定一致度阈值。当两份文档一致度计算结果低于设定阈值时,还需进行自然段落的一致度计算,具体计算流程如下:
流程1:对P1和P2进行自然分段处理,针对自然分段后获取的各段文档实施分词、去除停用词等预处理,同时确定各段文档内词的权重。
流程2:设定一个阈值,利用式(3)计算P1文档内的自然段落P1i同P2内全部自然段落的一致度S,对比S 与阈值,若前者大于后者,需记录P2文档内的段落与对应的S 值,若前者小于后者,需进行流程。
流程3:重复流程2,至P1文档内全部段落同P2文档内全部段落对比完成。
流程4:确定所记录的段落数量,进行标记,获取一致度较高的自然段落。
一致度计算具体流程如图4 所示。
2 实验分析
为验证基于自然语言处理的故障应急事故报告自动生成方法的应用性能,以某发电厂为应用对象,在其中某项设备发生故障的条件下,采用所提方法自动生成故障应急事故报告测试,结果如下。
2.1 数据采集精度
对比所提方法中数据库内采集故障设备数据与故障设备原始数据,所得结果如图5 所示。
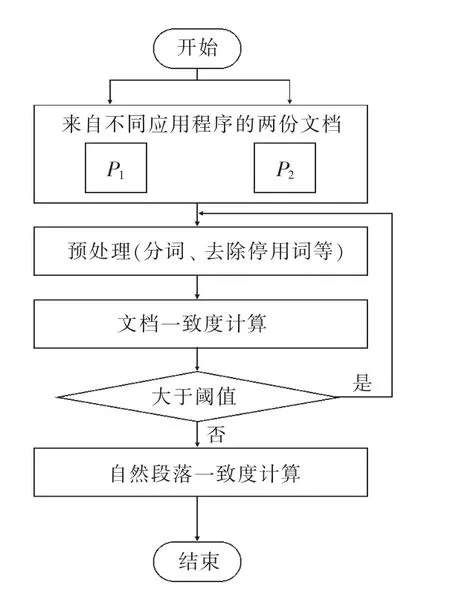
图4 一致度计算流程

图5 数据对比结果
图5 内所提方法采集数据大体上与故障设备原始数据走势相同,部分区域存在一定差距的原因主要是应用对象中的设备发生故障,导致监测数据(即采集数据)存在一定缺失现象。
2.2 数据借补测试
以基于水晶报表的报告自动生成方法和基于专家系统的报告自动生成方法为对比方法,采用所提方法和对比方法对上一实验中缺失的数据进行借补处理,记录任意时间点下不同方法借补处理后所得数据与实际数据间的绝对偏差,结果如表2 所示。
分析表2 得到:随着数据缺失比例的提升,不同方法对采集数据实施借补处理后,数据的绝对偏差也呈不同程度的上升趋势。采用所提方法对采集数据进行借补处理后,不同时间点下数据的绝对偏差始终低于另外两种对比方法,且不同时间点下与两种对比方法相比差异达到50%以上,由此说明所提方法具有较高的数据借补精度。

表2 数据借补测试结果
2.3 词性标注测试
统计所提方法对故障应急事故报告内信息的不同词性实施标注后的查准率、查全率与准确度,结果如表3 所示。
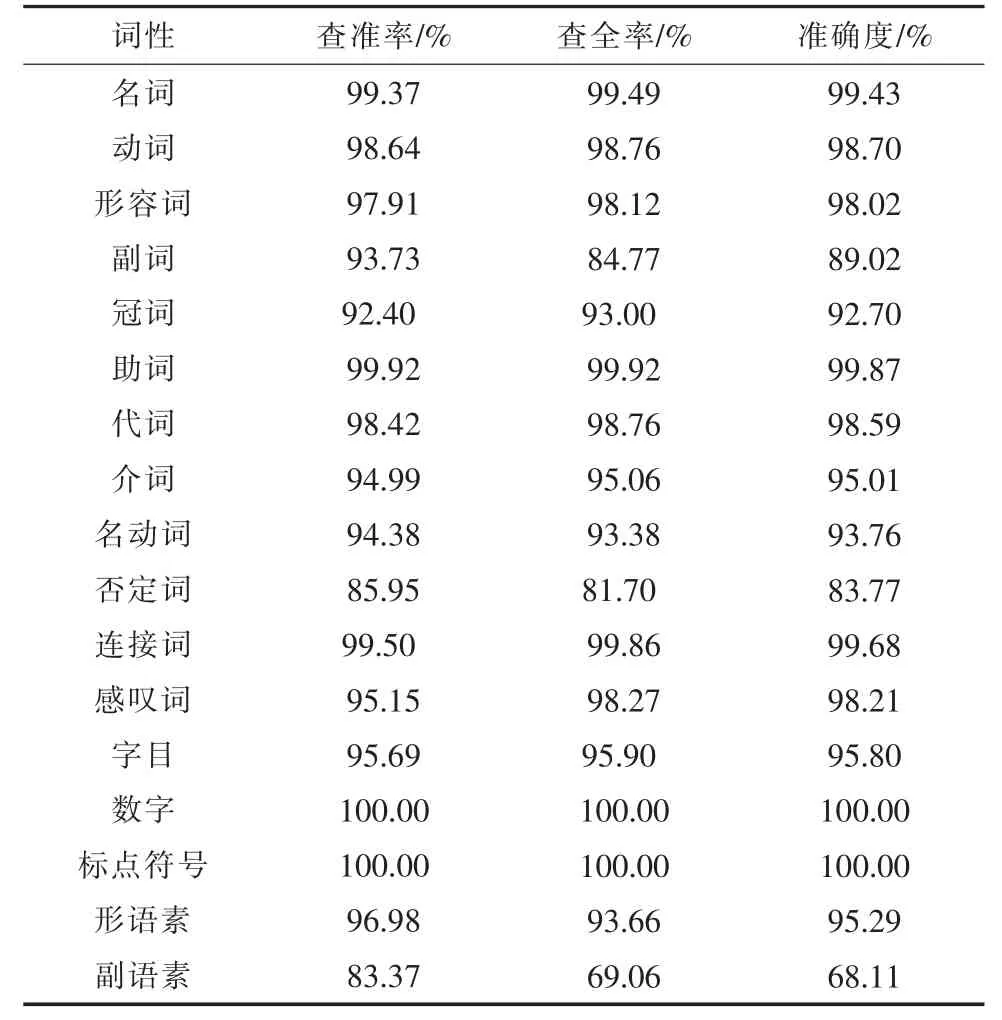
表3 词性标注测试结果
分析表3 得到,所提方法对报告信息的不同词性进行标注后,不同词性标注的查准率、查全率与准确度均值分别为95.67%,94.10%和94.47%,由此说明所提方法在词性标注方面具有较高的精度,能够令所提方法具有更好的性能。
2.4 语义识别精度测试
图6 为所提方法在实际报告生成过程中的语义识别精度测试结果。

图6 语义识别精度测试结果
分析图6 可得到,所提方法对不同自然段落进行语义识别所得的一致度结果与实际一致度值大致相同,计算结果误差控制在1.5%以内。由此说明所提方法具有较高的语义识别精度。
结合2.2 节、2.3 节和2.4 节实验结果可知,所提方法对于自然语言处理具有较高的精度,可实现故障应急事故报告自动生成,规范报告编制内容。
2.5 实时能耗测试
图7 为所提方法实际报告生成过程中的实时能耗。
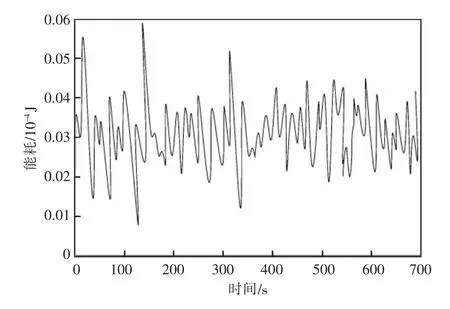
图7 实时能耗曲线
分析图7 得到,所提方法在实际报告生成过程中的实时能耗基本控制在0.01×10-4~0.06×10-4J/s,平均能耗约为0.032×10-4J/s。实验数据表明所提方法在实际报告生成过程中具有较低的实时能耗。
2.6 报告规范性验证
在上述验证基础上,对生成的报告规范性进行了测评,测评结果如表4 所示。
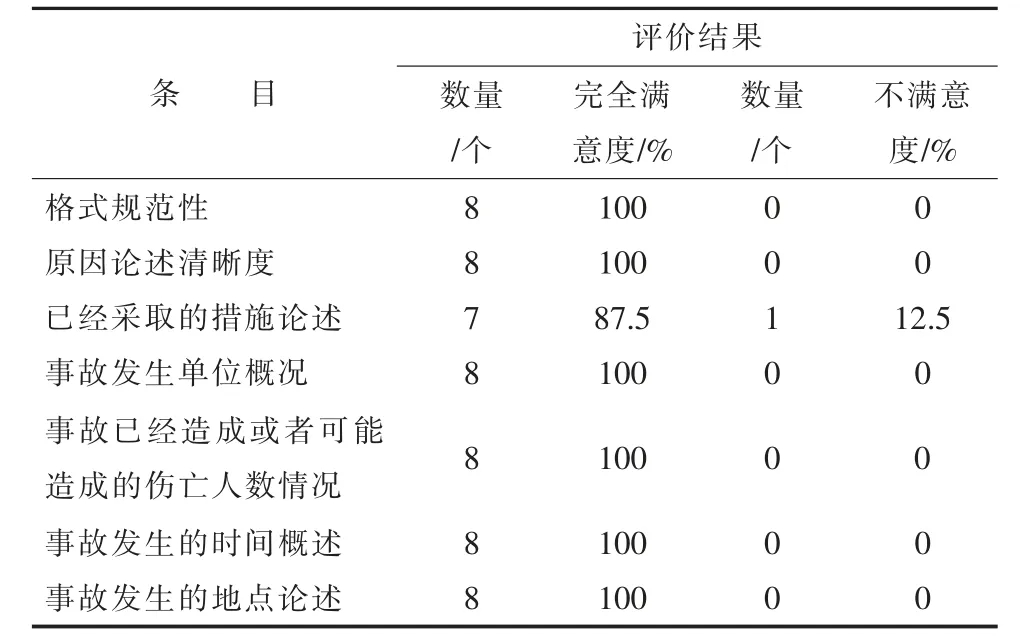
表4 故障应急事故报告规范性评价
如表4 所示,所生成的报告规范性满意度较高,平均完全满意度在98%以上,可以应用在实际中。
3 结语
研究基于自然语言处理的故障应急事故报告自动生成方法,根据所采集故障设备数据,采用自然语言处理技术中的数据结构定义、词性标注、句法分析、语义识别与数据提取等过程自动生成故障应急事故报告,实验结果显示所提方法中自然语言处理技术具有较高的精度。
猜你喜欢
江苏安全生产(2022年7期)2022-08-24
客联(2022年3期)2022-05-31
汉语世界(The World of Chinese)(2021年4期)2021-09-05
中国新闻周刊(2021年26期)2021-07-27
江苏安全生产(2020年6期)2020-07-28
青少年科技博览(中学版)(2019年1期)2019-04-25
好日子(2018年9期)2018-10-12
劳动保护(2018年5期)2018-06-05
灾害医学与救援(电子版)(2017年3期)2017-02-06
信息安全研究(2016年4期)2016-12-01
