
基于多模态深度学习的流量分类识别方法
2021-04-22 07:38焦利彬霍永华
无线电通信技术 2021年2期
焦利彬,王 猛,霍永华
(1.中国电子科技集团公司第五十四研究所,河北 石家庄 050081;2.火箭军装备部驻廊坊地区军代室,河北 廊坊065000)
0 引言
流量分类是网络流量异常负载检测和入侵检测等工作中至关重要的一步,是网络管理(尤其是网络安全领域)的关键研究方向之一。将网络流量与特定应用程序关联的过程被称为流量分类(Traffic Classification,TC)。流量分类是实现流量管理的基本功能之一,支撑了流量处理(如流量策略、流量整形等)到安全管理(如流量过滤、异常检测等)的全流程。
由于现代互联网流量的多样性和复杂性,网络流量的构成更加趋向于异质化,同时对用户流量数据进行深入剖析以得到有价值信息的需求激增,流量分类的难度与必要性持续增加。同时,随着加密技术的广泛采用,也使现有流量分类方法面临着巨大的挑战,例如,对于基于更强大的加密协议(尤其是QUIC和TLS 1.3等加密协议)的流量分类问题尚待深入研究。
流量分类已经广泛应用到各个领域,在流量分类领域主要有以下方法[1-2]:基于端口匹配、基于深度包检测(Deep Packet Inspection,DPI) 、基于行为特征以及基于机器学习(Machine learning,ML)等分类方法。但是,随着网络应用数目逐渐增多,随机端口和伪装端口的出现使得传统基于端口的流量分类方法已经无法对流量特征进行准确识别。同时由于加密协议的广泛使用(例如TLS等),也使DPI不再适用。基于传统机器学习的流量分类方法解决了端口匹配和深度包检测无法解决的问题,例如针对加密流量的分类和极高的计算成本,但标准ML分类器需要领域专家进行特征标注,无法适应动态和具有挑战性的网络环境。
为解决传统ML分类器在网络流量高速发展情况下的局限性,采用基于深度学习的分类器,通过自动获取结构化特征表示,将其直接输入原始数据训练分类器,可以实现端到端的特征提取。深度学习在流量分类领域已经取得了显著的成果,例如Wei Wang等人将CNN运用在未加密流量数据集上,准确率、召回率和F值均达到89%以上[3-4]。文献[5]中比较了LSTM和2D-CNN的组合模型与标准CNN、LSTM在RedIRIS数据集上的性能差异,结果显示,性能表现最优异的是2D-CNN和LSTM层的组合,达到了96.32%的准确率和95.74%的F值。文献[6]提出了一种基于2D-CNN的新型多任务学习系统,Chen[7]等人提出了基于CNN的在线流量分类框架Seq2Img。BSNN[8]提出了由LSTM和GRU等模型组成的分类器对数据报文进行流量分类。
尽管深度学习已经在流量分类领域取得了不错的效果,但在高速发展的网络流量环境中,现有ML流量分类器仍缺乏灵活性和适应性,在端到端的深度学习分类器中仅使用单一模式,而没有充分利用流量数据异质化的特征,这将导致结果具有偏差性[9]。因此,与现有的基于单模态输入的深度学习流量分类器相比,本文中提出基于多模态的流量分类框架,旨在将不同的模态(输入)融合并进行流量识别,从而适应动态变化的网络环境。
1 基于多模态和深度学习的流量检测和分类方法
1.1 多模态流量数据分析
深度学习中的多模态数据融合技术(Multimodality Fusion Technology,MFT)是模型在完成分析和识别任务时处理不同形式数据的过程。多模态数据的融合能建立处理和关联来自多种模态信息的模型,缩小模态间的异质性差异,从而为模型决策提供更多的信息,提高决策总体结果的准确率。MFT已逐步成为深度学习的研究热点。
本节将先分析现有流量分类器的流量输入单位,然后分析基于单个流量单位的输入数据类型,再对不同的模态(即同一流量单位的不同类型输入)分别进行训练,融合多个模型输出结果,从而集成不同类型的特征来提高机器学习模型性能,实现多模态流量数据分析和识别。
流量单位分割可以将原始流量数据分割成多个离散流量单位作为分类器输入。在文献[3]中定义,flow包括具有相同五元组的所有数据包的序列(即源IP地址、源端口、目的IP地址、目的端口和网络传输协议),并以此作为输入分类器和进行训练的最小单位。而biflow表示双向flow(即共享同一五元组但方向相反的flow)。Wei Wang在文献[3]中讨论了不同流量单位对分类结果的影响,研究表明相较于flow选择biflow作为流量单位,其分类结果输出更准确。
现有的深度学习模型将流量数据的不同类型表示作为输入。例如,将流量单位有效负载的前N个字节或者原始数据的前N个字节作为输入,文献[3]中,选择TCP/IP模型中应用层(L7)或所有的协议层(ALL)的前784个字节作为输入。或者,可以将流量单位中前Np个数据包的协议字段信息作为输入,例如在文献[5]中,采集流量单位(biflow)的前20个数据包,并且对于每个数据包,提取以下6个字段(因此每个流量单位都得到了维度为20×6的矩阵):源端口和目标端口、传输层有效负载中的字节数、TCP窗口大小、到达间隔时间和数据包传输方向等。
实际上,尽管流量业务数据可以是“多模态的”,即可以用不同的数据类型和字段描述同一概念,但传统基于深度学习的模型都集中于一种类型的输入信息(例如,有效载荷字节或报头字段),即只能对单模态数据进行处理。本文下节中将提出基于多模态的流量特征分类学习模型,能够自动学习并融合多模态的流量数据特征表示。所提出的模型通过捕获模态间和模态内的依赖性,有效利用流量数据的异构性,以“多模式”方式隐式地承载信息,克服现有单模态流量分类方法的性能限制,适应具有异构特征的流量数据分类需求。
1.2 流量数据时空特征提取技术
卷积神经网络(Convolutional Neutral Network,CNN)被广泛应用于计算机视觉、推荐系统、自然语言处理等应用领域。根据文献[2]的研究表明,通过卷积神经网络,可以将流量数据处理成具有局部强相关性的序列数据。
CNN通过多个卷积层实现特征学习。每一卷积层都包含一系列具有平移不变性、能够提取特定输入区域特征的滤波器。CNN层可以根据输入数据的性质以一维卷积(1D-CNN)或二维卷积(2D-CNN)呈现。据研究表明[4],1D-CNN相比2D-CNN更加适用于序列数据,因此本文中采用1D-CNN去提取“有效载荷”模态的特征(即应用层负载的前Nb个字节),同时在池化层后采用一定概率的随机失活和提前终止技术,以防止模型过拟合,在一定程度得到正则化的效果。
长短期记忆(Long Short-term Memory,LSTM)网络模型是循环神经网络 (Recurrent Neutral Network,RNN) 的一种变体,解决了循环神经网络梯度消失的问题。LSTM中引入3个门,即输入门(input gate)、遗忘门(forget gate)和输出门(output gate),以及与隐藏状态维度相同的记忆细胞,以记录额外的信息。其基本结构如图1所示。

图1 LSTM神经网络模型Fig.1 Neural network model of LSTM
如图1所示,给定时间步t的小批量输入Xt和上一时间步隐藏状态Ht-1,输出由sigmod激活函数计算得到。时间步t的输入门It、遗忘门Ft、输出门Ot可得:
(1)
(2)
(3)

(4)
(5)
当前时间步t的隐藏状态为:
Ht=Ot⊙tanh(Ct)。
(6)
LSTM网络比简单的循环架构更易于学习具有长相关性特征的时间序列,在此类任务处理上有显著优势。本文应用LSTM神经网络模型来提取协议的字段信息,即前Np个流量数据包的特征。
1.3 基于多模态输入的流量分类框架
本文所提出流量分类框架为2个不同类型的输入:I. 应用层有效载荷的前Nb个字节(将字节处理成[0,255]的数值,均归一化至[0,1]);II. 前Np个数据包的协议字段信息,即传输层有效负载中的字节数、TCP窗口大小(对于UDP数据包设置为零)、到达间隔时间和数据包方向∈{0,1}等。需要说明的是,为了不产生有偏差的结果,通道II并不使用端口信息作为输入。
图2为本文提出的基于多模态输入的流量数据分类框架。通道I为“有效载荷”模态的特征提取,是两个一维卷积层,分别由16和32个滤波器组成,内核大小为25,采用单位步长和ReLU作为激活函数。卷积层后均连有一个1-D最大池化层,其单位步长和空间范围均等于3。最后是全连接层,具有256个神经网络节点。这样设置的原因是一维卷积层能够从有效载荷中提取具有空间不变性的特征。
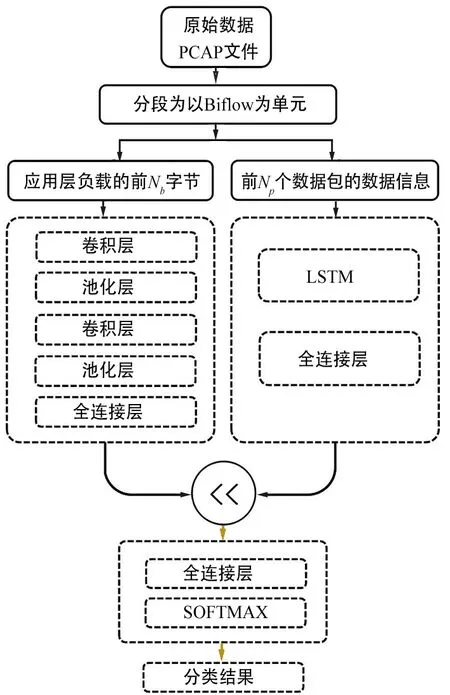
图2 基于多模态输入的流量数据分类框架Fig.2 Traffic data classification framework based on multimodal input
通道II为“协议字段”模态的特征提取,通过连接LSTM神经网络和一个全连接层(具有256个神经网络节点)。在通道II中设计采用LSTM神经网络模型,可以具备捕获与双流初始段有关的长期依赖关系的能力。在单模态层I和II后通过合并层将两个分支的中间特征连接起来,并在softmax分类之前馈入一个全连接(共享表示)层(具有128个神经网络节点)。所有层都通过ReLU获得输出,从而得到流量分类识别结果。
方便起见,定义训练集的第m个流量单位为(训练集由M个样本组成,M表示所属类别的总样本数量)x(m),所属类别标记为(m)。
(7)
为了减轻类不平衡问题,损失函数中引入wm表示第m个样本的权重。
(8)
其中,预训练和微调阶段所用的损失函数Lp(·)和L(·)采用的是标准一阶局部优化器(SGD,ADAM等)。
2 实验与结果分析
2.1 流量仿真数据集简介
本文使用文献[10]采用的ISCX VPN-non VPN traffic dataset数据集,此流量数据集中有两种数据格式:流量特征和原始流量(即.PCAP格式)。该数据集中常用的流量有12类,包括6类常规加密流量数据和6类VPN协议封装流量数据,包括20 173个非VPN样本,12 264个VPN样本,共计32 437个样本。表1显示了该数据集的详细分类内容。

表1 ISCX VPN-nonVPN数据集Tab.1 ISCX VPN-nonVPN data set
2.2 对样本进行预处理
不同的分割粒度会产生不同的流量单位,流量单位的选择会影响模型最后的分类效果。使用biflow作为基本流量单位,从原始流量转化到biflow的过程如下:
I. 原始流量:所有数据包的集合为P={p1,p2,…,p|P|},单个数据包定义pi=(xi,bi,ti),i=1,2,…,|P|。xi代表五元组,分别为源IP地址、源端口、目的IP地址、目的端口和网络传输协议;bi∈[0,∞)为数据包大小,单位是字节;ti为数据包pi开始传输的时间。
II. 将原始流量转化为biflow:将原始流量集合P分割成多个子集的集合F={f1,f2,…,fi,…,fm},m为原始流量划分的子集个数,fi表示将原始流量划分为多个子集中的任一子流。子流fi=(xi,bi,di,ti)中的数据包以时间顺序排列,其中xi在biflow中表示具有源IP地址、源端口、目的IP地址、目的端口和网络传输协议的五元组;bi∈[0,∞)为子流fi中所有数据包的大小,单位是字节;di为子流fi传输的总时长;ti则为子流fi中的数据包序列的第一个数据包开始传输的时间。
对于同一个流量单位,采用两种不同模态的输入。对于模态I,输入为“L7-Nb”,即流应用层(L7)有效载荷的前Nb个字节[5];模态II输入则为“MAT-Np”[5],是指对每个biflow,提取前Np个数据包中每个数据包的4种协议字段信息组成的Np×4矩阵(不同于文献[5],只提取了有效负载的字节数量、TCP窗口大小、数据包到达间隔时间和数据包方向4个特征)。为了降低复杂性,均采用biflow中数据包应用层的载荷数据。根据大量分析,模态I中采用前Nb=576字节数,模态II中使用Np=12个数据包。
2.3 仿真分析
通过对样本集进行划分,随机分配90%的样本作为训练样本,10%的样本作为测试样本,使用训练样本训练模型,然后用测试集进行测试。为加强实验说服力,减少随机性,进行多次重复试验,最后将试验结果取平均值如表2所示。从表中可以看出本文提出的分类算法最终分类结果精度可达85%,准确率、F值均可达80%以上,相较于传统LSTM方法能对异质化、多模态的流量数据实现更为精确的分类。

表2 流量分类结果Tab.2 Classification results%
3 结论
针对流量数据分类的问题,提出了一种基于卷积神经网络与长短期记忆的多模态深度学习分类算法,充分利用了流量数据异质化、多模态的特征,针对同一流量分类单位的不同类型输入分别进行处理,再融合多模态的流量数据特征表示,最后得到更精确的分类结果,克服了现有深度学习流量分类器的局限性。
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
科学家(2021年24期)2021-04-25
民用飞机设计与研究(2020年4期)2021-01-21
应用科技(2020年1期)2020-06-18
网络安全和信息化(2018年4期)2018-11-09
网络安全和信息化(2018年2期)2018-11-09
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
航天返回与遥感(2014年5期)2014-07-31
中原工学院学报(2014年4期)2014-04-01
