
人口老龄化对人口集聚的影响
——基于面板数据模型
2021-04-22 09:01廖文琪田秋红
农业与技术 2021年7期
廖文琪 田秋红
(贵州财经大学,贵州 贵阳 550025)
引言
根据人口普查的结果显示,我国的老龄人口占比从第五次人口普查的6.69%到第六次人口普查的8.9%,比同期其他国家的老龄化平均水平更高。作为世界上老年人口最多的国家,对于人口老龄化的研究,大多数学者研究其对经济增长[1]、居民消费[2]、资源配置[3]、住房需求[4]等方面的影响。人口向着经济发达地区流动,生存条件更好、发展机会更多,吸引着青年人向着这些区域集聚,这是存在于世界各国经济社会发展的普遍状态,如中国的北京、上海,日本的东京,美国的纽约等均是各国人口集聚的重要区域。人口集聚提供了大量适龄劳动力,常常能够促进当地经济的快速发展。对于人口集聚的研究,杨东亮根据人口集聚地区的特点,通过建立面板数据模型研究了人口集聚对于区域经济发展的影响[5];陈心颖利用空间回归和门槛面板回归模型研究了人口集聚对于区域劳动生产率的影响[6];于潇认为地区差异、婚姻、教育、收支比等因素是人口流动的重要因素[7];王胜今认为经济因素是人口集聚的最重要因素[8]。
通过对以上文献的梳理,可以发现对于人口集聚影响因素方面的研究,从人口老龄化角度来考虑的文献较少。本文利用2005—2020年的面板数据,通过F检验、LR检验、Hausman检验判别模型的类型,建立合适的面板数据模型,从人口老龄化的角度考虑其对人口集聚的影响作用。
1 研究方法与变量描述
1.1 研究方法
1.1.1 面板单位根检验
面板单位根检验的目的是排除不平稳数据对模型造成的伪回归和虚假相关问题,因此对于面板数据的单位根平稳性检验是回归分析前的必要操作。因此,对数据建立以下过程:
yit=ρiyit-1+Xitδi+εit,i=1,2,…,N,t=1,2,…,Ti
(1)
式中,N、Ti、Xit、εit分别表示所有截面的总数、第i个截面的所有时期的总数、外生变量、相互独立的误差项;ρi表示自回归系数,序列平稳时,|ρi|<1,若序列不平稳时,|ρi|=1。单位根的检验方法可分为同质单位根检验和异质单位根检验2类,前者主要有LLC、Breitung2种检验;后者主要有IPS、ADF-Fisher、PP-Fisher3种检验。
1.1.2 面板数据协整检验
协整检验的目的是检验变量在同阶单整的情况下,是否在长期存在稳定的均衡关系。其检验方法主要有Fisher、Kao协整检验2类,前者是以不存在协整关系作为原假设,利用pi作为单个截面Johansen协整检验的P值,原假设的统计量:
(2)
式中,N表示截面个数。计算出样本统计量后与临界值进行对比,其值大于临界值时,拒绝原假设,认为变量之间存在着协整关系。
1.1.3 面板模型估计
面板数据模型可分为无个体影响的不变系数模型、变截距模型和变系数模型3类。其形式分别如下:
yit=α+β'xit+uit,i=1,2,…,N,t=1,2,…,T
(3)
yit=αi+β'xit+uit,i=1,2,…,N,t=1,2,…,T
(4)
(5)
截距、斜率在参数不随时间变化的情况下,有以下2种假设:
H1:β1=β2=…=βN
(6)
H2:α1=α2=…=αN,β1=β2=…=βN
(7)
当接受H2时,应建立混合效应模型,即选择模型(3);当拒绝H2,接受H1时,应建立个体固定效应模型,即选择模型(4);当拒绝H2、H1时,应建立变系数模型,即选择模型(5)。
1.1.4 F检验和Hausman检验
F检验的原假设为应建立混合效应模型,表示模型中不同的个体截距相同;备择假设为应该建立个体固定效应模型,表示不同的个体截距不同。因此,F统计量可用于面板数据模型混合效应和固定效应的判断。在原假设成立的情况下,服从自由度为(N-1,NT-N-k)的F分布。
Hausman检验的原假设H1为应该建立个体随机效应模型,表示模型中的解释变量皆为外生变量,若该假设成立,则该统计量应渐进服从λ2(m)分布;备择假设H2为应建立个体固定效应模型,表示模型中的解释变量皆为内生变量。因此,H统计量可用于面板数据模型随机效应和固定效应的判断。
两者结合起来看,分别计算出F统计量和H统计量,当统计量比给定置信度下的临界值大时,2个统计量都拒绝原假设,应该建立个体固定效应模型;当统计量比给定置信度下的临界值小时,则接受原假设,前者建立混合效应模型,后者建立个体随机效应模型。一般顺序是先进行F统计量的检验,再进行H统计量的检验。
1.2 数据来源与变量说明
本文选取的样本区间为2005—2020年,共16a,数据来自31个省(自治区、直辖市)。本文选取老年抚养比代表该地区人口老龄化程度;选取人口密度代表地区人口集聚程度。人口密度的计算为:
(8)
式中,Pi表示该地区的年末人口总数;Ai表示该地区的行政区域面积;N表示31个省份。数据主要来源于2005—2020年的《中国人口统计年鉴》和《中国统计年鉴》,样本量为496个。
2 实证分析
2.1 面板单位根检验
对变量old和pop进行单位根检验,再进行后续的面板数据回归分析。在单位根检验中,当原始数据平稳时可直接进行面板数据回归分析;当数据一阶差分趋于平稳时,需要再进行协整检验。本文使用常见的5类面板单位根检验方法对old、pop变量进行检验,结果如表1所示。
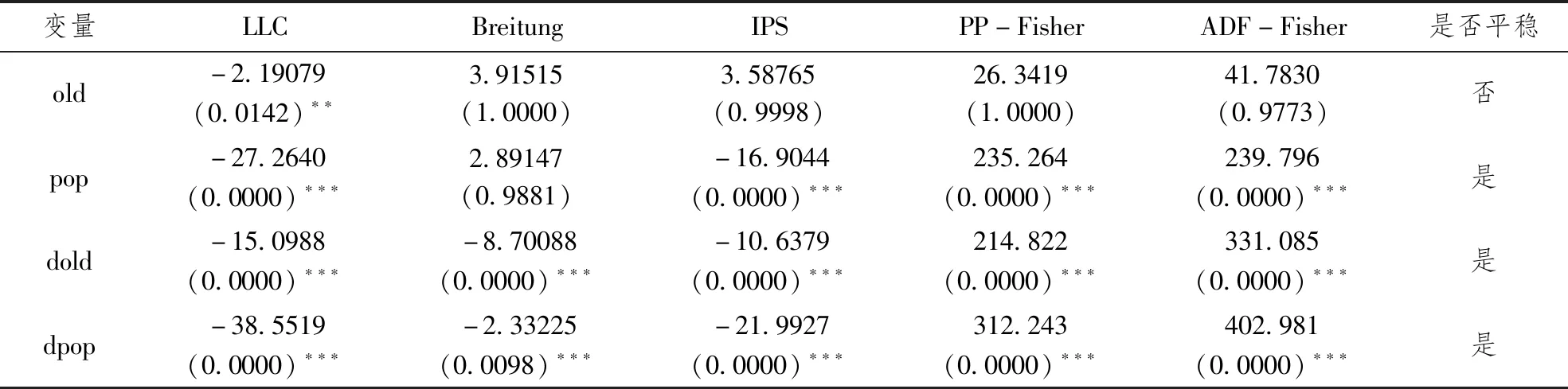
表1 面板数据的单位根检验结果
由表1可知,对old的水平值而言,其P值均大于0.05,接受原假设,认为该指标的水平值不稳定,存在单位根。在一阶差分之后,old、pop两指标均在1%水平下显著拒绝原假设,即不存在单位根。因此,可进行下一步的协整检验。
2.2 面板数据协整检验
由上文可知,old、pop变量均在一阶单整的情况下不存在单位根,现将old和pop进行面板数据的协整检验,本文分别选取Kao检验和Fisher检验来进行面板协整检验。Kao检验的结果显示t统计量为3.794251(0.0001),Fisher检验的Fisher统计量(迹检验)为172.7(0.0000)、Fisher统计量(最大特征根检验)为121.1(0.0000)。这2种检验的原假设均为“没有协整关系”,由检验结果可知,Kao检验和Fisher检验的P值均小于0.05,因此拒绝原假设,表明老年抚养比与人口集聚度之间存在协整关系,即这2个变量长期存在稳定的均衡关系。也说明通过误差纠正可以使得由各种因素导致人口集聚在短期内发生的各种变化也能在长期保持稳定的均衡关系。
2.3 面板数据模型类型判别
在使用面板数据进行回归之前,需要对面板数据模型的类型进行判别。选择固定效应模型进行估计,进行F检验和LR检验并查看统计量结果,选择随机效应模型进行估计,查看Hausman检验的结果。当前2个检验拒绝原假设时,选取个体效应模型;当后面的检验拒绝原假设时,则选取个体固定效应模型。F检验的统计量为2.7954(0.0000)、LR检验的统计量为988.9021(0.0000),结果均显示拒绝原假设,模型个体效应显著,即应该选择个体效应模型;Hausman检验的统计量为4.3972(0.0360),结果显示P值小于0.05,拒绝原假设,接受面板数据应该使用固定效应模型的假设,因此综合来看,应该建立个体固定效应模型。
2.4 面板数据模型参数估计
由前面的讨论可知,本文应该建立个体固定效应模型,模型以及参数估计结果如下:
popit=2.896721-0.004195*oldit+μit
(9)
式中,R2=0.9858,F=1036.381,D.W.=0.1462。仔细观察,DW统计量的值较小,说明模型中的误差项之间存在着自相关性,通常加入因变量(人口集聚度)的滞后项可以消除误差项之间的自相关性。因此,加入滞后项之后,方程变为:
popit=0.5974-0.0132*oldit+0.8593*pop(-1)it+μit
(10)
式中,R2=0.9987,F=10061.67,D.W.=2.0091。从模型的拟合优度、F值以及DW值来看,在加入人口集聚度的滞后一期之后,3个值都显著提高。因此,最终模型的形式为加入因变量滞后项的方程,即为式(10)。
整体来看,模型的拟合优度(R2)较高、F值较大,说明模型整体的拟合效果较好;且常数项、老年抚养比、人口集聚度的滞后一期均在1%水平下显著,说明模型比较可靠。就人口老龄化对人口集聚度的影响而言,从模型中可以看出,两者呈现负相关关系,每当老年抚养比增长1个单位时,该地区人口集聚度会下降1.32%,说明人口老龄化对地区人口集聚度有着抑制作用。
3 结论
本文基于2005—2020年中国31个省(市、自治区)的省级面板数据,通过建立个体固定效应面板数据模型对人口老龄化、人口集聚之间的关系进行了实证研究。结果发现,人口老龄化对人口集聚产生了显著的抑制影响,这意味着随着地区人口老龄化程度的加深,会对该地区吸引适龄劳动力的能力有着抑制的作用。根据以往的研究显示,人口集聚通过提供更多适龄的劳动力、创造更多的价值、带来更多的需求、带动更多的消费等促进地区的经济发展。但从模型结果来看,当地区的老年抚养比每增长1个单位时,该地区的人口集聚度会下降1.32%,说明不能只关注于人口集聚带来的福利,而忽略地区人口老龄化带来的对这些福利的抑制作用。因此,为了防止人口老龄化对于人口集聚的抑制作用,可以完善医疗保障制度体系、建立长期护理保险制度,为有着老年人口需要赡养的青年劳动力减轻压力,由此能够间接通过提升年轻劳动力的劳动参与度、生产效率、家庭储蓄和投资等,促进地区的经济发展。
猜你喜欢
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
智富时代(2018年3期)2018-06-11
智富时代(2018年3期)2018-06-11
统计与决策(2017年23期)2018-01-06
电子测试(2017年12期)2017-12-18
湖南大学学报·自然科学版(2015年1期)2015-04-20
统计与决策(2015年11期)2015-02-18
首都经济贸易大学学报(2013年3期)2013-03-11
