
用户情感分类和话题推荐的图片语义应用实证
2021-04-11 05:14陈新元谢晟祎
宁德师范学院学报(自然科学版) 2021年1期
陈新元,谢晟祎,张 力
(1.福州墨尔本理工职业学院 信息工程系,福建 福州 350121;2.福建农业职业技术学院 实验实训中心,福建福州 350300;3.福州理工学院 文理学院,福建 福州 350506 )
情感是人们对某一特定事件的感觉或反应,例如高兴、悲伤、生气等.情感分析指辨别人们交流时的情绪状态,判断和评估其态度、意见和情绪,目前多个行业都有相关应用案例.一些研究按照时间线,分类型总结了该领域研究的思路、方法、数据集、实验和成果[1-3].
随着科技和社交网络的进步,人们的交流呈现在线化、数字化的趋势.微博是国内的主要社交网络平台之一,类似国外的Twitter.截至2018 年,活跃用户数达到4.62 亿(数据来源:微博数据中心《2018 用户发展报告》),人们可以在微博上以多种形式分享观点和情感,寻找志同道合的伙伴,用户/话题推荐也成为研究的热点.
传统的用户推荐大多基于用户热度,即根据用户粉丝数、微博回复数、转发数、评论数等指标进行推荐[4].但本文认为不能简单地根据影响力高低进行排序,用户间的情感可能相同或迥异,态度也可能是赞成、中立或反对,即同意度取值不同.微博用户影响力示意图(如图1),左右两组多边形分别表示A、B 用户在不同话题上的影响范围,显然A 的影响力较大;但对于C 用户,其与A 用户具有一致情感的话题较少,处于A 影响力范围的边缘地带,但与B 用户在多个话题上具有相同情感.本文观点:C 与B 的情感一致性较高;对C 用户而言,B 比A 更具吸引力;用户间的相对影响力越高,越可能“倾盖如故”,用户推荐也越可能获得成功.

图1 微博用户影响力示意图
本文的主要工作是将融合图片语义的微博情感分类结果应用于生成用户和话题推荐,创新点在于:1)将情感一致性和同意度因素引入用户影响力和话题影响力的计算;2)在此基础上提出新的用户和话题推荐思路,以提高推荐结果与当前用户的情感匹配度.
1 相关工作
情绪模型的定义多元化,现有模型大致可以分为“分类”模型和“维度”模型[5].分类情感模型,如Ekman 模型[6]、Shaver 模型[7]和Oatley 模型[8],将所有人类情感分为几个主要类别(愤怒、厌恶、恐惧、快乐、爱等);维度情感模型的数据结构大致包括列表、树、轮子、立方体等,如Plutchik 模型[9],在Ekman 基本情绪的基础上加入饱和度/强度因素,以及相邻情绪的复合效应、环型模型[10]、OCC 模型[11]、Loveim 模型[12],从多个维度和强度出发将模型细化分类,英国心理学家Parrott 设计了一种基于树结构的分层情绪分类模型[13].此外,Xu 等在Ekman 模型的基础上提出了4 层的情绪模型[14],本文使用该模型进行情感分类.
无论Twitter 还是微博,关于用户影响力计算或在此基础上进行用户推荐的研究大多是基于用户热度,即根据用户粉丝数、微博回复数、转发数、评论数等指标进行推荐[15-18],也有研究围绕中介中心度、接近中心度和自定义的H-index 等中心性指标开展[19-21],或对Google 的PageRank 算法进行修改,提出了诸如TunkRank[22]/UserRank[23]算法以发现人气用户,或通过指数、影响力分类等数学或逻辑上的方案计算用户影响力[24-25];另一方面,关于话题推荐的研究较少,国内如任星怡在LDA 模型的基础上利用地理信息、社会关系幂律分布和概率矩阵进行用户兴趣推荐[26]等.
本文的核心在于基于情感分类的用户/话题影响力计算,热门账户并非对所有用户都具有相同的吸引力,传统观念的“物以类聚,人以群分”更符合社交诉求.所以本文首先进行情感网络的辨识以区分用户群体;其次在情感模型的基础上根据转发、评论、点赞操作等因素计算情感一致性和同意度,结合其他指标,量化判定用户的整体情感影响力和话题影响力,用于用户和话题推荐.
2 基于情感分类的用户/话题推荐
通过数据抓取、预处理和清洗等操作构建数据集,使用Hash 算法实现图片去重,根据PMI 点互信息迭代提取表情符号和图片的情感信息,生成带强度标记的图片情感词典,连同台湾大学中文情感极性词典(NTUSD)、清华大学李军中文褒贬义词典(TSING)、知网词典(HOWNET)和2014 版《网络用语词典》共同实现微博的情感分类.
在情感分类的基础上,使用K-means 聚类辨析用户群体,计算情感一致性和同意度,汇总得到用户整体情感影响力和话题影响力.据此计算相对特定用户的影响力,进行用户/话题推荐,以期获得更好的用户推荐效果.
2.1 用户情感影响力和话题影响力
本节用到的符号及其释义见表1.

表1 影响力符号及释义

续表1
文献[27]中,作者基于用户相似度的理念进行用户推荐,将用户相似度细分为微博内容、交互行为和社交关系等属性,使用余弦公式分别计算,最后综合多源信息总相似度;但关注领域/社交行为大致重叠或相似的两名用户,其观点、看法和情感却可能大相径庭.Wolny 基于用户的整体情感倾向做出用户推荐[28],但没有考虑两名用户在公共主题上的情感一致性和同意度.
本文在Sailunaz 影响力公式的基础上进行调整,保留账户影响力和话题影响力的定义区分,在此基础上添加情感一致性和用户同意度的乘法系数[29].情感向量一致性的计算使用余弦相似度:

即使情感一致性完全相反(positive 与negative),也保留0.3.一方面部分用户可能希望看到不同情感的表达;另一方面无法否认对立情感产生共鸣的可能.ScoreAD分为5 个等级,“完全同意”“赞同”“中性/模糊”“疑问”“反对”,量化以1,0.5,0,-0.5,-1 表示.相关权重参数的计算中,将账户类和话题类的影响因素分别进行两两匹配比较,使用AHP 匹配比较量度如图2.

图2 AHP 匹配比较量度
生成两个独立的比较矩阵,使用归一的特征化向量生成权重系数优先矩阵见表2(账户情感影响力参数的计算方法相同).

表2 比较矩阵与话题参数权重向量
账户类因素和话题类因素在与对应的ScoreEA(A,B)和ScoreAD加权计算后,最终得出账户情感影响力ISA和话题影响力ISS;为减小影响力的量级差异,对影响力进行归一化处理,对ISA使用公式(2),MINA和MAXA分别是所有账户影响力的最小值和最大值,ISS同理.

ISA取值越大,该节点在情感网络中越重要;但在进行具体的用户推荐时,由于不同用户之间情感倾向存在较大差异,不能简单地根据ISA或ISS进行匹配,还需计算用户相对影响力ISRA.
2.2 基于相对影响力的用户和话题推荐
本文在微博官方话题分类的基础上,根据情感模型分类设定k 值,使用主流K-means 聚类方法,根据Level3[14]的情感分类构建情感网络;在候选Top 用户池中使用双方在公共话题转发数、评论数和点赞操作数的分值计算ISRA,再辅以数据收集和清洗阶段记录的用户关联度(包括无法辨别情感一致性的直接关联,双方的地理定位和用户标签匹配情况)作为乘法系数进行微调,得到最后的推荐得分,降序排列.具体算法见表3.

表3 用户推荐与情感推荐算法
用户推荐进行至第10 步,list1返回为止;话题推荐进行至最后一步,list4返回为止.
在进行话题推荐时,传统方案往往分析用户的历史数据,在最关心的微博类别下推荐热度最高的话题,但这种算法扩展能力不足,在增加用户黏度、延长用户浏览时间方面效果有限.因此本文利用相对影响力筛选出与当前用户匹配度较高的用户账户后,挑选ISS较高且不在当前用户常访问分类中的话题,若SOT 与UOT 相符,则向当前用户进行推荐.
3 研究方法和实验结果
3.1 数据收集及预处理
本文自建数据集收集了2019 年9—10 月182 万余条来自近42 万个账户归属于11 个不同话题的微博数据(含表情符号和图片)、后续评论内容和转发数据、点赞操作数和收藏数,以及相关用户的公开信息.使用10 折NB 对完整文本进行分析,平均情感分类准确率为68.7%,尽管不同话题的准确率存在1.5%至9%的差异,但在用户推荐验证实验中,并未表现出明显的差别,因此相关数据略.
3.2 影响力计算和可视化
用户ISA及归一化结果示例见表4.
为更清晰地表示用户情感影响力,通过简单的对数处理,气泡图可以将微博数、粉丝数和影响力量级差异较大的不同账户在同一张图片里显示并进行比较,示例如图3,图中右上方的2 个较大的圆圈是话题中担任影响力核心的用户.
在此基础上计算账户相对影响力ISRA,如图4 所示.经过用户关联度、地理定位、标签匹配度修正的ISRA和最终排序见表5.
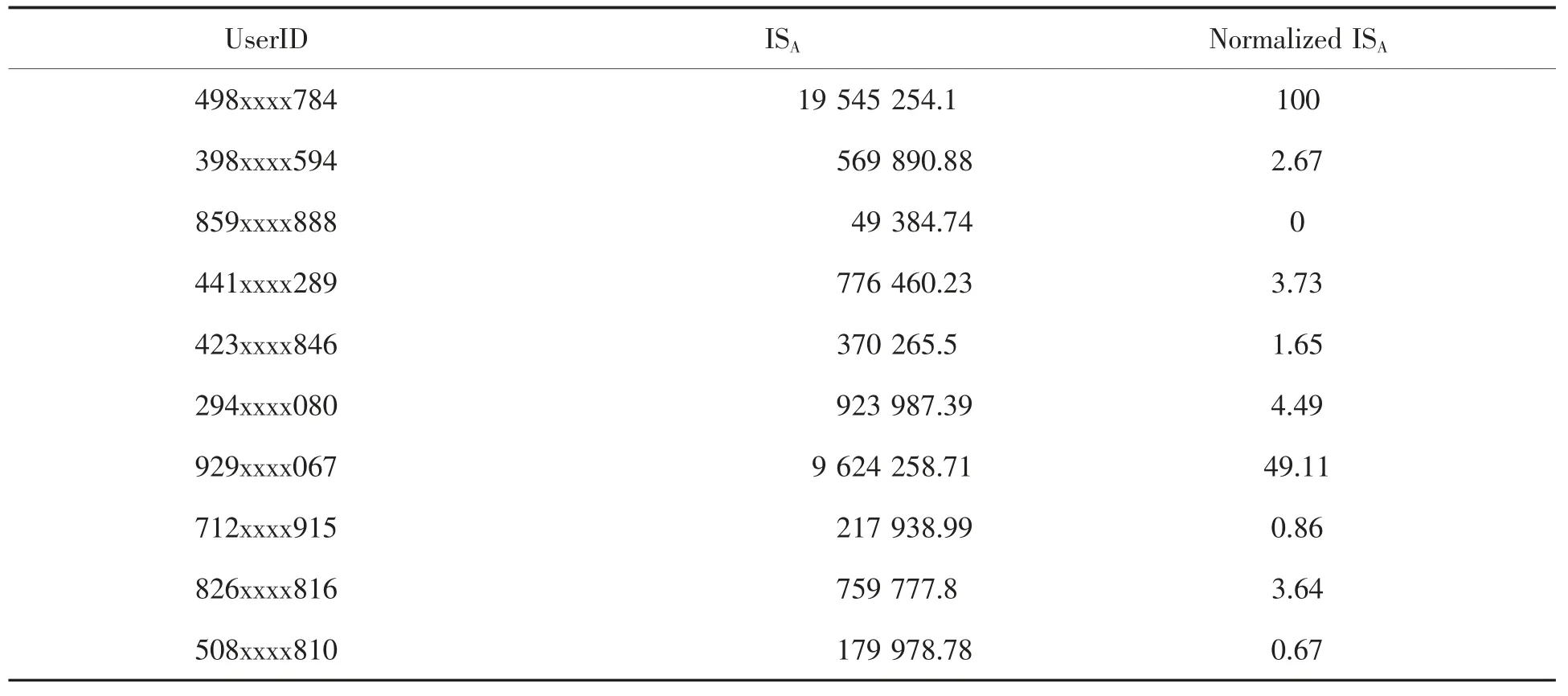
表4 ISA及归一化结果示例
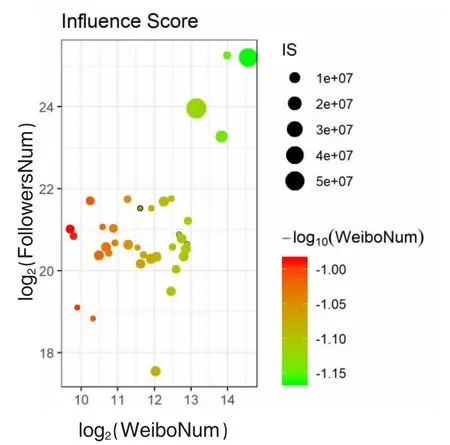
图3 ISA气泡图示例

图4 ISA网络结构示例

表5 ISRA及修正排序示例
随机抽取某主题的用户评论关联,其ISA网络结构示例如图4.根据评论数可以辨识核心用户,即周围线条最密集的少数用户,也可以看到,大部分发出评论的用户持有和发微博用户相同的情感/观点,只有少部分(蓝色圆圈)的用户持有异议,验证了在线用户希望寻找情境相似人群的理论.
在此基础上计算账户相对影响力ISRA,以及经过用户关联度、地理定位、标签匹配度修正的ISRA和最终排序见表5.
推荐系统优化:本文推荐方案在每次推荐时,都需要重新进行数据抓取并计算,延时较长,可达700~3 000 ms.故设计并实现了两套并行的性能优化方案:一套基于缓存和增量更新;另一套方案使用分级改进推荐精确度的方法,使得推荐方案可以在100 ms 内示出结果.
3.3 推荐结果验证
用户推荐算法的验证使用随机双盲平行对照实验,被试人群为大一至大三共3 个年级的225 名学生,均有微博使用经验,曾进行过关注、转发、评论和点赞等操作.其中男生125 名,女生100 名,分别来自福建、江西、浙江、广西、陕西、天津、四川、河北等11 个省、自治区或直辖市,除福建生源较多外,地域分布较为平均;大一学生为53 名,大二学生为103 名,大三学生为69 名;年龄平均值为20.12,标准差为1.33.
将样本人群随机分为三组,每组75 人,分别为实验组、对照组1(使用微博默认的推荐算法)、对照组2(使用文献[29]设计的算法).实验在不同日期进行2 次,间隔1 周,每次3 组同时进行;3 种方案为每位参与人员单独生成Top10 推荐清单.主持实验的人员向受试人群介绍微博基本操作,不做其他提示,也不允许受试人员彼此交流.受试人员打开的第1 个页面设置为推荐清单,但并不要求用户停留在推荐清单或其页面;60 min 后实验结束,统计样本人群的相关用户关注数、微博评论数、转发数和点赞操作数.
实验发现,除用户关注数外,观察对象在浏览微博时的习惯差异较大,评论、转发或点赞3 种操作的选择有明显的倾向差异,但总体强度较为稳定,故使用本文公式计算以上操作的得分并累加,将结果作为推荐算法的一个独立衡量指标.根据实验结果,该指标与用户关注数的Pearson 相关性达到0.79,两次实验的重测相关系数达到0.66.用户关注数数据统计见表6.
用户转发、评论及点赞等操作数据统计见表7.可见使用本文推荐方案后的用户关注数、转发、评论和点赞操作数,均有一定提高.

表6 用户关注数统计
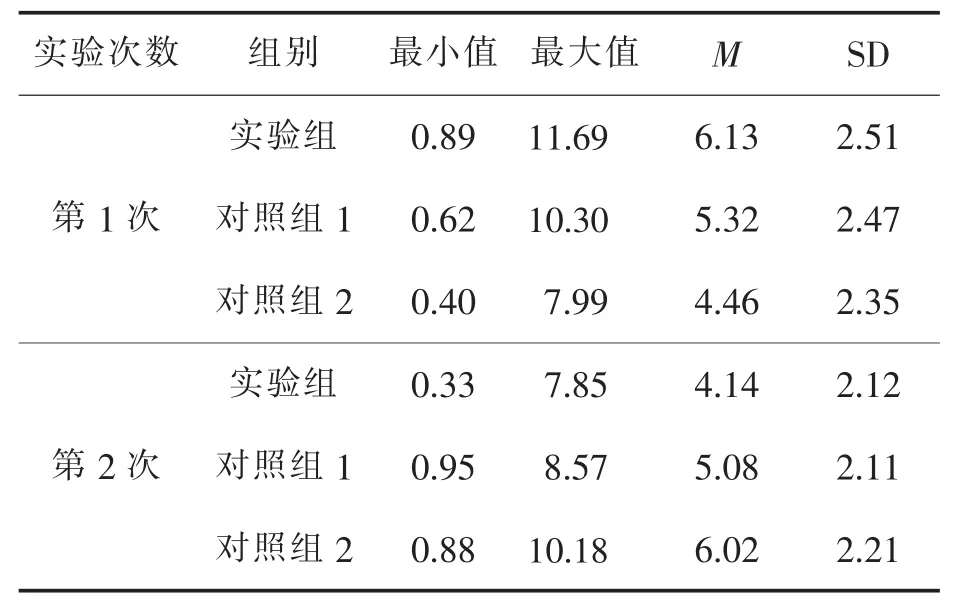
表7 转发、评论及点赞等操作数据统计
征得被试者同意后,在135 名学生的安卓设备上安装记录程序,统计每次实验后1 周内微博App在内存中的驻留时间(以秒为单位),用以计算效标效度,该因素受多种条件影响,波动较大,但相关系数仍达到0.526.
独立样本t 检验的结果表明,用户推荐结果不存在性别差异,P 值在0.13 至0.88 之间;不存在地域差异,P 值在0.25 至0.54 之间;不存在年级差异,P 值在0.49 至0.77 之间.
4 结论
传统用户/话题推荐的算法大多基于用户热度,忽视了用户寻找同伴的心理需求,因而本文在情感分类结果的基础上,将情感一致性和同意度因素引入ISA和ISS计算,并在此基础上将用户/话题推荐的粒度进一步缩小至只对用户关联数据的匹配.小范围双盲实验验证了该推荐算法在用户关注数、微博数、转发数和点赞操作数等结果指标上相较以往算法有一定改进.
今后的研究方向可能包括:推荐算法的有效性验证样本容量较小,过程较简单,受试人群兴趣爱好不一,可能对实验结果造成干扰,可尝试大规模规范化验证;相反情感的影响力衡量需要深入研究;将情感一致性、同意度在时间轴上的变化纳入考量;对任意话题的即时推荐算法和适应不同粒度的推荐思路也需要改进,等等.
猜你喜欢
汽车实用技术(2022年9期)2022-05-20
教学考试(高考物理)(2021年5期)2021-11-08
历史教学问题(2021年4期)2021-11-05
数学小灵通(1-2年级)(2021年4期)2021-06-09
NBA特刊(2018年14期)2018-08-13
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
人大建设(2017年11期)2017-04-20
燕山大学学报(2015年4期)2015-12-25
少儿科学周刊·少年版(2015年3期)2015-07-07
