
适用于林区机载LiDAR点云的多分辨率层次插值滤波方法
2021-04-10 03:56陈传法王梦樱
山东科技大学学报(自然科学版) 2021年2期
陈传法,王梦樱,杨 帅,王 珍
(1.山东科技大学 测绘与空间信息学院,山东 青岛 266590;2.北京市勘察设计研究院有限公司,北京 100038)
随着激光雷达技术的发展,机载激光雷达(light detection and ranging,LiDAR)已成为采集地面点信息的主流工具[1]。与传统摄影测量技术相比,LiDAR能够快速获取高精度、高分辨率的真实地面三维坐标数据,已广泛应用于数字高程模型(digital elevation model,DEM)构建、水文分析[2]、森林清查[3]、城市三维可视化[4-5]、土地覆盖和土地利用分类等[6]。其中,LiDAR点云使用前一般需要将地面点从原始点云数据中分离出来,即滤波[7]。然而,原始LiDAR点云数据中通常包含许多建筑物、植被等非地面点,特别是对于地形起伏变化较大的林区,分类地面点与非地面点仍是一项挑战。
目前,许多学者对LiDAR数据滤波展开了一系列研究,并提出了相应的滤波算法。根据滤波原理,现有滤波算法可大致分为:形态学滤波[8-9]、坡度滤波[10]、分割滤波[11-12]和内插滤波[13]。实际应用中各种滤波算法各有优缺点,其中插值滤波方法因原理清晰、能更好地模拟真实地表以及滤波可靠性高等优势被广泛关注。例如,Axelsson[14]提出渐进不规则三角网(triangulated irregular network,TIN)加密滤波方法(progressive TIN densification,PTD),根据局部低点构造初始的稀疏TIN,并根据每个点与TIN的距离和角度判断地面点。Haugerud等[15]提出一种虚拟森林砍伐算法,用原始点云构建TIN,然后计算采样点及其对应表面的曲率。Evans等[16]提出一种多尺度曲率分类方法,该方法采用正规化样条代替TIN插值并在不同分辨率下构建栅格曲面。Chen等[17]提出多分辨率分层点云滤波算法(multi-resolution hierarchical classification,MHC),用局部最低点作为地面种子点,通过薄板样条函数(thin plate spline,TPS)构造地面参考面。分析表明,基于插值的滤波在地形相对平坦、地形较为简单的地区表现良好,但在地形复杂林区由于获取的初始地面点少,插值迭代计算受初始DEM影响增大且误差累积增大,其滤波效果并不理想。为此,提出一种适用于林区机载LiDAR点云的多分辨率层次插值滤波方法,该方法首先借助形态学滤波和稳健的标准分数(z-score)方法提高地面种子点数量和质量,以提高初始地面参考面的精度;然后从低层到高层滤波过程中,借助自适应坡度阈值选择地面点,以保证滤波在地形崎岖林区的适应性。
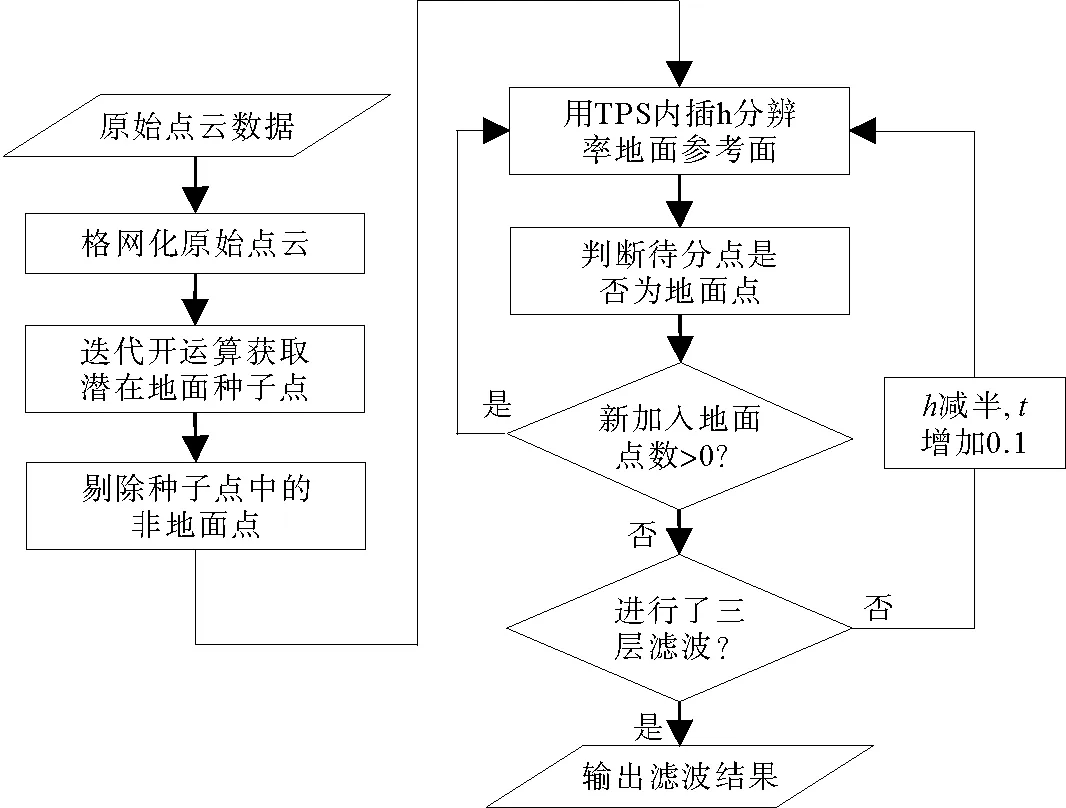
图1 多分辨率层次插值滤波算法流程图
1 算法原理及流程
首先格网化原始点云,并使用形态学迭代开运算获取潜在地面种子点;然后借助稳健“z-score”准则剔除潜在地面种子点中的非地面点;最后分三层滤波,每一层用薄板样条内插构建一定网格分辨率的地面参考面,并通过待分类点与参考面的距离判断该点是否为地面点;滤波出的地面点用于更新参考面,直到该层没有地面点加入。算法的流程如图1所示,其中涉及到的重点环节介绍如下。
1.1 初始地面种子点的选取
1) 点云格网化。以c作为格网大小(例如c=1 m),落入每个网格内的最低点作为对应的格网值(图2)。格网大小取决于点云密度,一般取平均点间距。对于剩余的未被填充的格网,利用弹簧质子图像修复技术填补,修复后形成的最小值表面作为迭代开运算的初始表面。
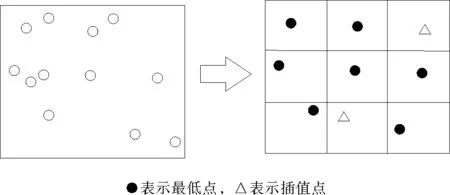
图2 点云格网化
2) 迭代开运算。开运算为先腐蚀后膨胀。开运算结构元素的选取直接影响运算的质量,因此选择各向同性并且不会对运算结果产生偏移的圆盘形作为开运算结构元素的形状,同时采用多尺度结构元素以避免结构元素过大或过小造成的误分类。为此,定义两个参数:最大窗口半径(Wmax) 和坡度值(s)。其中,由Wmax形成一个动态变化窗口的开运算器,并计算用于分类格网的高程阈值:
ET=s×Wi。
(1)
其中:Wi=1,2,…,Wmax,表示每次迭代开运算的窗口大小;ET表示每次迭代开运算前后两个表面之间对应格网的差值阈值。如果开运算前后格网高差阈值大于ET,则标记该格网为非地面格网。每次开运算后得到的表面被当作下一次开运算的初始表面(图3),迭代全部完成后形成一个新的最小值表面。由于选择最低点时可能会选中极低的无意义的点,这会对开运算结果产生影响。因此,要翻转最后得到的表面并用单一的窗口半径再进行一次开运算。最后,将未标记为非地面格网中的点作为潜在的地面种子点。
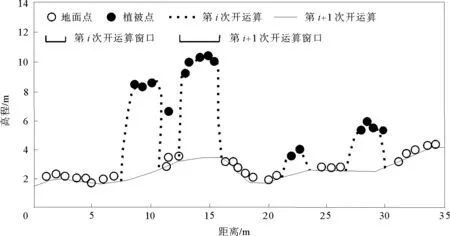
图3 迭代开运算示意图
1.2 种子点粗差剔除
种子点粗差剔除旨在剔除潜在地面种子点集中的非地面点,以提高初始构建的地面参考面精度。异常值检测的方法有许多,本研究拟基于z-scores来检验异常值,即
(2)
(3)
式中,
其中,常数1.483是使MAD正态分布无偏的校正因子;median为取一组数据的中位数。
1.3 地面点选择
在获取地面种子点之后,通过多分辨率插值滤波选择剩余采样点中的地面点。该方法包括三个层次,其中参考DEM分辨率和残差阈值从低到高逐渐增大。在第i层(i= 1,2,3…)地面点选取步骤如下:
总辐射年最大值为1 112.I7 W/m2:观测期间净辐射年平均 48.24 W/m2,春季 65.01 W/m2,夏季93.79 W/m2,秋季 30.39 W/m2,冬季 2.42 W/m2,最大 807.98 W/m2,最小 186.99 W/m2。
1) 利用TPS对地面种子点插值生成分辨率为h的参考DEM。
2) 计算每个采样点与其对应DEM网格点所在3×3移动网格中9个点的残差。如果9个残差中至少有5个小于设定阈值,则该点判断为地面点。经典MHC方法仅考虑高程差,因此在陡坡和地形变化剧烈的区域容易导致点的错分。为此,本研究在残差阈值中引入坡度因子,以提高滤波方法对各种地形区域的自适应性。每个网格的残差阈值T计算如下:
T=ti+e×SF,
(4)
其中,ti为每一层中固定的阈值(i= 1,2,3);e为尺度缩放因子;SF为每个点云对应的DEM上的近似坡度,计算公式为:
(5)
其中,F是X、Y和Z之间的函数,Z=F(X,Y)。
如图4所示,在陡坡上固定阈值易将地面点误分类为非地面点,而自适应坡度阈值可以减少误分类。
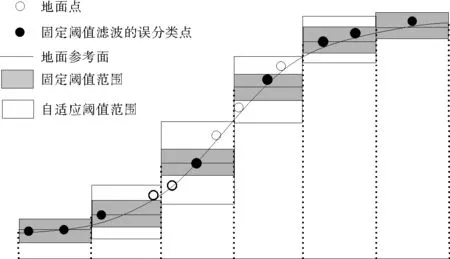
图4 适应坡度阈值和固定阈值分类点示意图
3) 更新地面点和地面种子点。地面种子点是分辨率为h的网格单元中局部最低点。
4) 重复步骤1)~4)直到没有地面点加入。
2 实验及结果分析
分别采用基准数据和林区数据验证新方法的滤波精度,并将结果与常用滤波方法比较。采用的滤波精度评价指标为I类误差(T.I)、II类误差(T.II)、总误差(T.E)和Kappa系数,计算公式如下:
T.I=b/(a+b)×100%,T.II=c/(c+d)×100%,T.E=(b+c)/e×100%,κ=(p0-pc)/(1-pc)×100%。
(6)
其中:a表示正确分类的地面点数;b表示误分为非地面点的地面点数;c表示误分为地面点的非地面点数;d表示正确分类的非地面点数;e=a+b+c+d;p0=(a+d)/e;pc=((a+b)×(a+c)+(c+d)×(b+d))/e2。
I类误差表示地面点错分为非地面点比例,II类误差表示非地面点错分为地面点比例,总误差为衡量两类误差的综合指标,I类、II类误差和总误差越小以及Kappa系数越大表示滤波精度越高。
2.1 ISPRS基准数据
采用国际摄影测量与遥感协会(International Society for Photogrammetry and Remote Sensing,ISPRS)提供的6个山地区域(samp51-samp71)样本来测试新算法性能。其中,每个样本的点云数据都通过半自动过滤和人工编辑分类出地面点和非地面点。山地区域一般地势复杂且有植被覆盖,因此新算法将其视为林区进行滤波处理。为了测试算法的最佳性能,通过重复试验确定新方法的滤波参数如表1所示,其中初始分辨率h均为2 m。为了增加算法在各类地形的适应性,规定最优参数设置准则:最大窗口半径(Wmax)应稍大于数据处理区域最大非地面物尺寸;初始高差阈值(t)应稍小于低矮植被高度;坡度(s)为0.2;坡度系数(e)可设置为1。根据此准则给出单参数集(Wmax=13 m,s=0.2,t=0.29 m,e=1)及其滤波结果如表1所示。
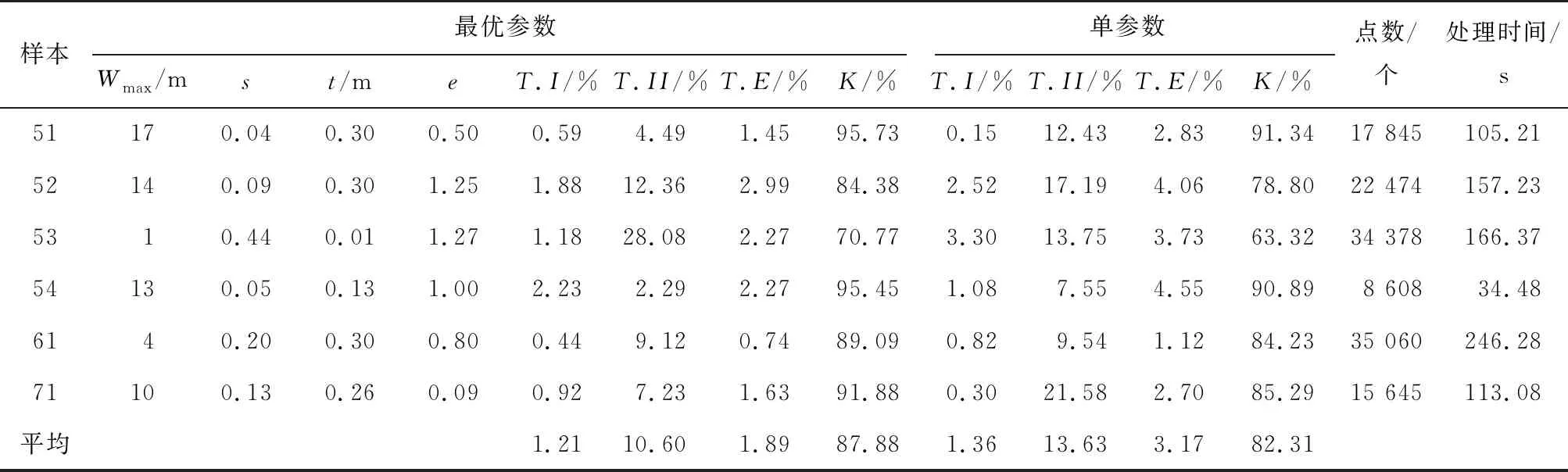
表1 新方法滤波误差及处理时间
由表1可得,单参数集取得的样本平均Kappa系数和总误差分别为82.31%和3.17%,最优参数取得的样本平均Kappa系数和总误差分别为87.88%和1.89%。单参数与最优参数的总误差仅相差约2%,说明该方法对参数设置不敏感。由处理时间可以看出,该方法运算效率整体较好,运算效率与点数相关,点数越少,处理时间越短。表1中samp51的Kappa系数最大,高达95.73%,samp61的总误差最小,仅为0.74%。samp52的总误差最大,samp53的Kappa系数最小。图5和图6展示了这两个样本滤波前后DEM的对比以及I类和II误差的空间分布情况。由图5(a)可见,samp52中断的陡坡、沿河低矮植被及河岸高低变化的地形造成了II类误差增大;分布在河道两侧的错分的地面点(图5(c))造成了滤波后DEM中河道两侧凸起问题。由图6(a)可见,samp53具有不连续和陡峭的梯田,其中西南角地形变化明显,导致II类误差较大(图6(c))。

(空心圆点表示Ⅰ类误差;实心圆点表示Ⅱ类误差)
将新方法与近5年提出的10种滤波算法[17-26]进行比较见表2,可见:新方法在6个样本中有4个总误差最小,样本samp52和samp71的总误差与最佳结果接近,仅比相应最佳滤波方法误差高0.07%和0.30%。新方法的平均总误差为1.89%,明显优于其他滤波方法。
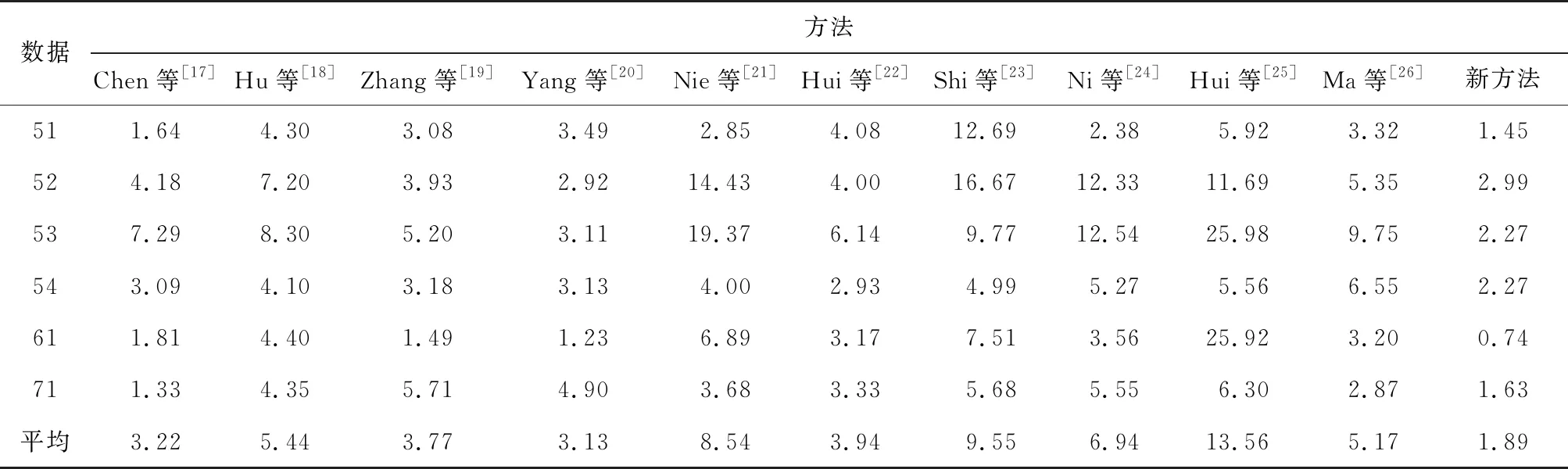
表2 新方法与10种滤波算法总误差对比
2.2 林地区域数据
本研究从美国国家科学基金会提供的开放地形数据网站(http://www.opentopography.org/)下载了6个具有不同地形特征和植被覆盖的样本(图7),以进一步验证新方法在不同景观下的适应性。这6组样本均按照1∶1 000标准图幅大小取样。数据1为美国犹他州中南部垂直悬崖样本,地形陡峭有较多陡坡及悬崖,覆盖植被低矮且稀疏(图7(a))。数据2(图7(b))和3(图7(c))为美国科罗拉多州缓慢移动的滑坡样本;数据2地形平缓,覆盖植被高且分布较密集,数据3地形较平缓,包含较多褶皱,覆盖植被高且分布不均匀。数据4(图7(d))为新西兰惠灵顿森林样本,地形陡峭,覆盖植被高且密集。数据5(图7(e))和数据6(图7(f))为加利福尼亚州猛犸湖熔岩表面样本,包含高低起伏较大的山包,覆盖植被较高且分布较密集。
将新方法与形态滤波算法(morphological filtering algorithm,MF)[27]和渐近不规则三角网加密滤波算法(PTD)[14]滤波结果比较(表3)可知:新方法的总误差低于其他方法,Kappa系数最大。新方法的滤波精度最高,平均总误差为6.82%,Kappa系数为85.61%,其次是PTD,MF滤波结果最差。因此,与经典滤波方法相比,新方法更适合于森林地区。

图7 6组样本数据卫星影像

表3 新方法与两种常用滤波算法误差对比
三种方法构建的DEM精度表明(表4):新方法生成的DEM精度整体较好,6组数据中有5组数据误差最小。数据2的DEM中误差大于其他方法,这是由于新方法II类误差较大(表3),即滤波结果中非地面点较多引起的。数据集中各方法对数据2构建的DEM中误差最小,这是由于在平缓和较光滑的地形上各类滤波算法运行良好;各方法在数据4构建的DEM中误差最大,这是由于太过密集的植被易被认为是地面点造成的。由表4可知,本方法获得的DEM平均精度优于其他方法。

表4 各个区域DEM中误差对比
以数据1为例,图8展示了各个方法构建的DEM。结果显示:新方法生成的DEM与标准DEM相似,而MF和PTD在地形复杂的区域会保留较多植被点造成DEM表面粗糙。

图8 数据1标准DEM以及新方法、MF和PTD获取的DEM
3 结论
为了提升林区点云滤波算法精度,本研究提出一种多分辨率层次插值滤波方法。该方法借助形态学开运算和稳健z-score方法来精确地获取大量地面种子点,并提出了一种考虑地形坡度的自适应残差阈值。借助ISPRS山区数据分析表明,该方法滤波平均总误差和Kappa系数分别为1.89%和87.88%;对森林数据集结果分析表明,该方法平均总误差为6.80%,Kappa系数为85.61%。而且新方法精度均明显优于常用的插值滤波方法。然而,本研究构建的滤波方法滤波结果中II误差明显大于I类误差,这将导致滤波后的地面点中含有大量非地面点,进而影响DEM建模精度。因此后续研究将借助对II类误差有抵抗力的滤波算法进一步提升本文算法的精度。
猜你喜欢
全球定位系统(2022年2期)2022-05-19
测绘地理信息(2022年2期)2022-04-02
地理空间信息(2022年3期)2022-04-01
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
智能计算机与应用(2020年4期)2020-08-31
北京航空航天大学学报(2019年9期)2019-10-26
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
电子制作(2019年9期)2019-05-30
