
基于YOLOv3检测和特征点匹配的多目标跟踪算法
2021-04-07 08:49:38穆平安马忠雪
计量学报 2021年2期
谭 芳, 穆平安, 马忠雪
(上海理工大学 光电信息与计算机工程学院, 上海 200093)
1 引 言
行人目标的检测与跟踪在交通、安防等领域具有重要的实用价值,一直都是计算机视觉与图像处理领域的研究热点。传统的行人目标跟踪算法主要分为判别类算法和生成类算法。基于检测的判别类算法主要有背景差法、阈值分割法、帧差法、光流法以及HOG特征结合SVM分类器等方法[1~4]。这些方法中有些算法计算量较大,实时性较差(如背景差法、光流法、HOG+SVM);有些算法虽然计算速度快,但检测效果易受到光照变化、噪声干扰、目标形变的影响,导致行人目标检测精度低(如帧差法、阈值分割法)。而基于概率统计的生成类算法主要有卡尔曼滤波(Kalman filter)、粒子滤波、均值漂移(meanshift)等方法[5~8]。虽然其实时性强,但由于目标快速移动及误差累计造成的目标漂移,大大降低了跟踪的准确率。
针对这些传统算法中的缺点,本文将结合深度学习与行人目标特征展开行人间的多目标跟踪研究。首先采用YOLOv3算法在Darknet-53网络结构下训练行人目标检测模型,获得一个精度与速度优良的YOLOv3检测器,然后结合FAST角点检测算法和BRISK算法对检测到的行人目标进行特征点提取与匹配,最终实现行人目标在背光、快速移动、部分遮挡等各种复杂情况下良好的跟踪效果。将YOLOv3算法、FAST 角点检测算法以及BRISK 特征匹配方法相结合,有效提升了传统多目标跟踪算法的性能及鲁棒性。
2 基于YOLOv3的多目标检测
基于检测的行人目标跟踪中,优良的检测器对最终的跟踪效果有着至关重要的影响。目前,基于深度学习的目标检测算法主要分为两类:一类是one-stage的YOLO(YOLO、YOLO9000、YOLOv3)[9~11]和SSD(SSD、DSSD、DSOD)系列算法[12];另一类是two-stage 的R-CNN(R-CNN、Faster R-CNN、Mask-RCNN)系列算法[13~15]。前者在处理速度上虽快于后者,但平均准确率却低于后者。其中YOLO系列算法经过不断改良,最新版本的YOLOv3在COCO数据集上,精度达到与R-CNN系列相当的同时,速度却快了好几倍。YOLOv3与其他基于深度学习的检测器在COCO数据集上测试速度和精度的对比见表1所示。
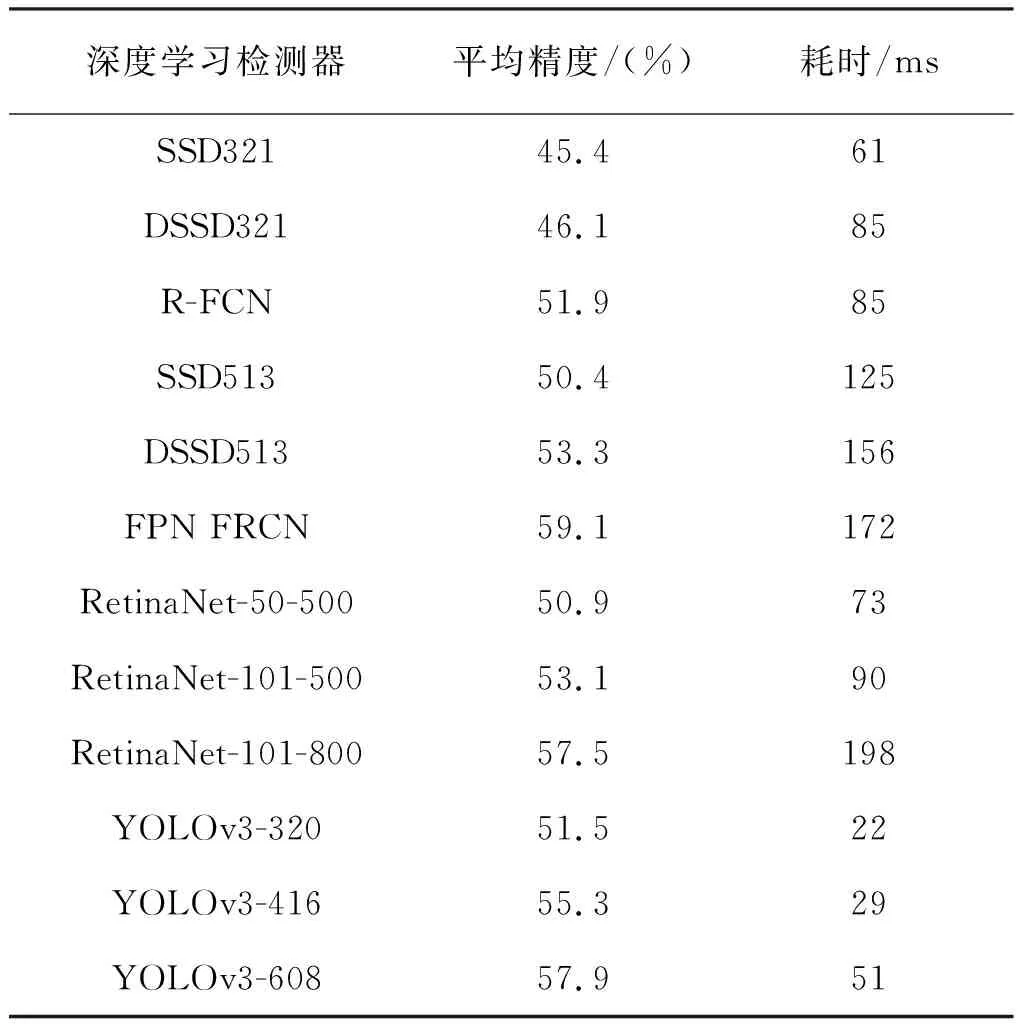
表1 YOLOv3检测器与其它深度学习检测器的性能对比Tab.1 Comparison of the performance of the YOLOv3 detector with other deep learning detectors
YOLOv3采用新的网络结构Darknet-53,借鉴残差网络块构成的全卷积网络作为骨干架构,在层与层之间设置快捷链路,以形成更深的网络层次。利用多尺度特征进行目标检测,以提升小目标检测的精度。同时采用多标签的Logistic取代了Softmax单标签方式,减少了检测目标的重叠情况。YOLOv3的网络结构模型见图1所示。
网络训练时,在ImageNet 预训练好的权重基础上,使用USC行人数据库训练行人目标检测模型。将该数据库提供的XML格式标注信息转换为YOLO格式的TXT文件,将YOLOv3.cfg文件中的识别类别改为1。通过实验分析,将权重衰减因子设为0.000 5,学习率设为0.001,动量参数设为0.95,训练批次取64。用训练好的YOLOv3检测器对一个时长8 s, 24帧/s,尺寸640×480像素的行人视频进行测试。截取部分帧行人检测效果见图2所示。

图1 YOLOv3网络结构模型Fig.1 YOLOv3 network structure model

图2 第37帧到第45帧的行人检测结果Fig.2 Pedestrian detection results at frames 37 to 45
测试集视频共导出192张图片,由于只考虑部分遮挡的行人目标检测,未对遮挡超过60%的行人目标进行大量训练,所以将遮挡超过60%的行人目标认为是无效目标,检测结果统计见表2所示。
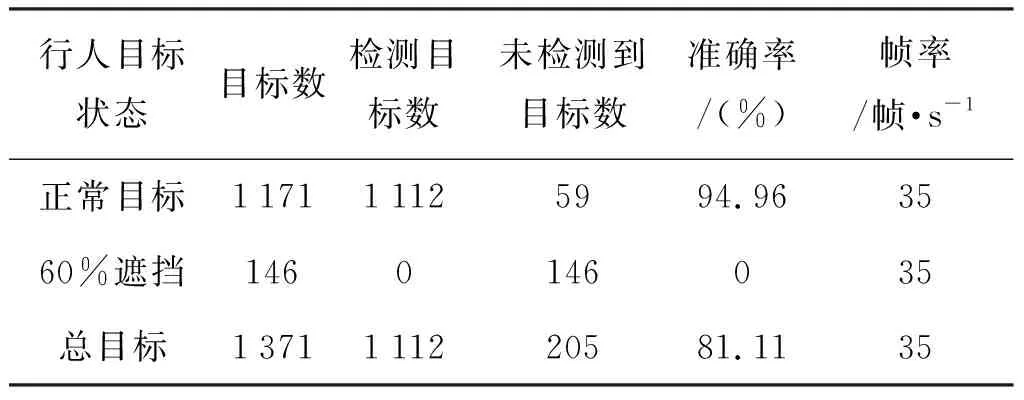
表2 YOLOv3检测器测试结果Tab.2 YOLOv3 detector test results
3 基于特征点匹配的多目标跟踪
将训练好的YOLOv3检测器用于各种复杂情况下的行人目标检测,根据YOLOv3检测器检测的结果,对检测出的行人目标进行特征点提取与描述,然后将前后两帧中的行人目标进行特征点匹配以达到多目标跟踪的目的。如果当前帧检测到的目标无法与上一帧中目标匹配,则判定此目标为新目标,在下一帧中继续进行检测跟踪,直到无可匹配目标为止。多目标跟踪算法总流程见图3。
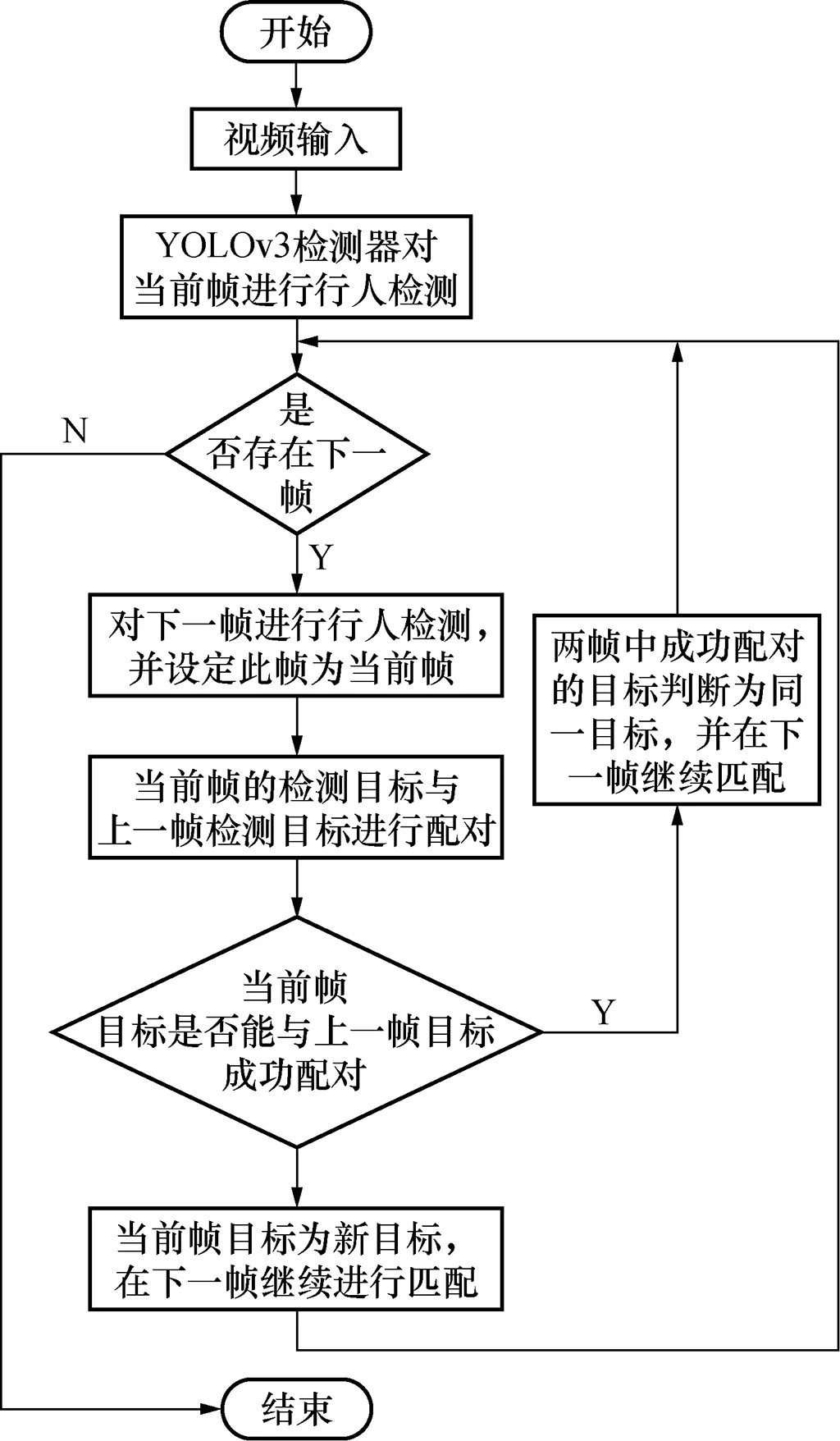
图3 多目标跟踪算法流程图Fig.3 Flow chart of multi-target tracking algorithm
3.1 基于FAST 角点检测算法的特征点提取
FAST角点的定义为:若某像素点与其周围邻域内足够多的像素点相差较大,则该像素可能是角点[16](特征点)。
如图4所示,以某一点p为圆心,以3个像素点距离为半径,得到像素点p1,p2,…,p16。根据情况设定一个阈值,特征点必须顺序满足下面3个条件,否则舍弃。
1) 计算p1,p9与中心p的像素差值,绝对值都大于阈值;
2) 计算p1,p9,p5,p13与中心p的像素差值,绝对值有至少3个超过阈值;
3) 计算p1~p16这16个点与中心p的像素差值,绝对值有至少9个超过阈值。

图4 FAST特征点Fig.4 FAST feature points
4) 对图像进行NMS(非极大值抑制),消除紧挨在一起的角点。在特征点p为中心的一个邻域内,计算FAST特征点的得分值(16个点与中心差值的绝对值总和)。若p的响应值在该邻域内的特征点中最大,保留该特征点,否则舍弃。若邻域内只有一个角点(特征点),则保留。计算得分公式为如式(1)所示(其中v表示FAST特征点的得分,pv为像素点灰度值)。
v=max∑|pv-p|
(1)
通常将阈值设为50,利用FAST算法快速得到图像的特征点。截取视频中的相邻2帧见图5所示。

图5 特征点提取Fig.5 Extraction of feature point
3.2 基于BRISK算法的特征点匹配
在得到特征点之后,选择在尺度不变性、旋转不变性、鲁棒性方面表现较好的BRISK算法得到特征点的描述子,然后利用PROSAC算法比较特征点之间的描述子,将特征点进行匹配。
首先利用图像金字塔对原图像进行多尺度表达(见图6),构造n个octave层(用ci表示)和n个intra-octave层(用di表示),n=4,i={0,1…n-1}。假设有图像I,c0层为原图像,c1层通过对c0层的2倍下采样生成,c2层通过对c1层的2倍下采样生成,以此类推产生octave层。而d0层通过对图像I的1.5倍下采样生成,d1层通过对d0层的2倍下采样生成,d2层通过对d1层的2倍下采样生成,以此类推产生intra-octave层[18,19]。
然后对每层图像进行空间上的NMS:特征点在尺度空间(上下层2×9个点)和位置空间(8邻域点),共26个邻域点的FAST得分值要最大,否则舍弃。
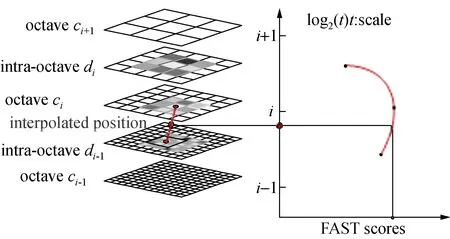
图6 尺度空间特征点检测Fig.6 Feature point detection in scale space
对极值点的所在层和相邻上下层之中对应的像素点的FAST得分值作二维二次函数插值,得到极值点的坐标位置;在尺度方向上进行一维插值,得到极值点所对应的特征尺度。
以特征点为圆心,做半径不同的同心圆,在每个圆上获得一定数目等间隔采样点,并对同心圆上采样点进行高斯滤波。高斯滤波的中心为采样点,方差设置为δ,滤波半径与高斯方差成正比,最终使用的N个(N一般设为60)采样点是经过高斯平滑后的采样点。采样点两两一对,所有组合方式通过下面的集合表示:
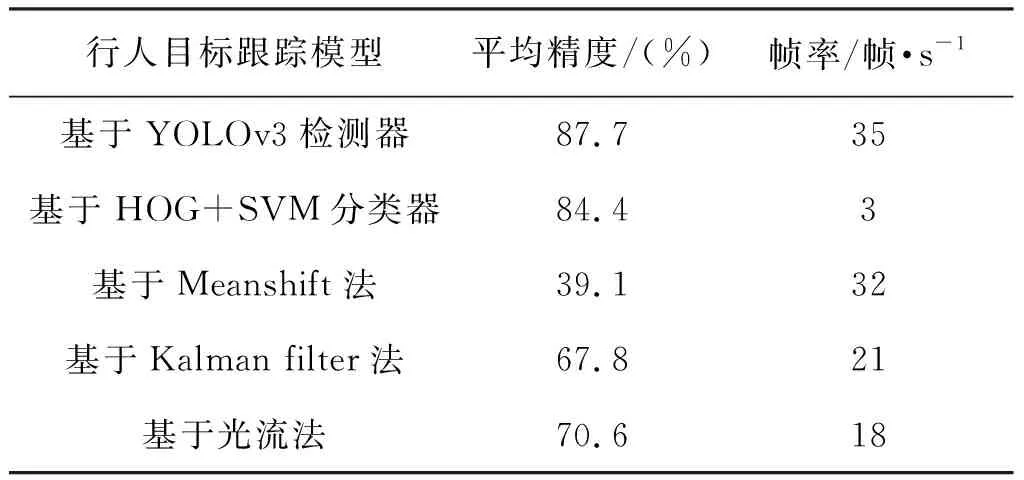
A={(pi,pj)|i (2) 用I(pi,σi)、I(pj,σj)表示不同采样点对在不同尺度的像素灰度值,σ表示尺度,g(pi,pj)表示局部梯度集合,则有: (3) 短距离点对和长距离点对的定义: (4) (5) 特征点主方向的获得: (6) α=arctan 2(gy,gx) (7) 旋转特征点周围的采样区域至主方向,对新的采样区域进行采样。BRISK算法获得的特征描述子为二进制描述子,上述过程得到的长、短距离子集,考虑其中短距离子集的512个短距离点对,进行二进制编码: (8) (9) PROSAC算法对特征点与模型之间的匹配质量进行衡量。利用PROSAC算法进行特征点提纯(见图7),有效提高了匹配精度。 图7 利用PROSAC剔除误匹配点对提纯前后Fig.7 Before and after purification by removing mismatched point pairs with PROSAC 本文实验配置环境基于英伟达1080 Ti、CUDA9.0以及Win10系统,算法开发基于Python语言和Darknet-53深度学习框架,跟踪可视化基于OpenCV。实验样本选自洛桑联邦理工学院CVLAB数据库,分别为露台、楼前广场2个场景。本文仅选取与几个经典的方法进行对比分析,具体数据如表3所示。可以看出,传统基于HOG+SVM和光流法的行人目标跟踪模型,虽然取得了不错的平均精度,但较大计算量加上复杂的测试场景,造成了实时性不理想。露台测试场景中的背光视频,导致了基于颜色直方图的MeanShift行人目标跟踪模型的平均精度受到较大影响。基于Kalman滤波的行人目标跟踪模型,虽能克服光照变化的影响,但对于行人间的遮挡和行人快速移动会出现目标跟踪丢失的情况。不同复杂环境下,本文跟踪算法模型在精度和速度上表现都相对优越。截取本文跟踪算法部分帧不同环境下跟踪效果见图8~图10,实验结果表明本文算法在背光、行人目标快速移动、部分遮挡等条件下均能实现较好的跟踪。 表3 与不同经典行人目标跟踪模型性能对比Tab.3 Performance comparison with different classical pedestrian target tracking models 图8 背光条件下行人目标跟踪结果Fig.8 Pedestrian target tracking results under backlight conditions 图8为露台场景第1074帧至第1079帧背光下行人目标跟踪结果。露台场景由于摄像机角度的问题,视频背光严重,行人目标的颜色信息丢失严重,传统的基于颜色特征的跟踪算法就会受到很大的影响。但是由于本文跟踪算法中YOLOv3检测器对行人目标检测主要基于深度学习的方法,后续的行人目标匹配采用了行人的边缘轮廓信息,从而克服了颜色丢失这一问题,取得了较好的跟踪结果。 图9 快速移动行人目标跟踪结果Fig.9 Tracking results of fast moving pedestrian target 图9为楼前广场第1678帧至第1683帧快速移动行人目标跟踪效果,由于行人目标较快速跑步进入视频采集区域,产生了一定的拖尾现象,造成行人目标模糊不清。但检测速度达到35帧/s的YOLOv3检测器能迅速地捕捉到快速移动的行人目标,防止了行人检测目标丢失的情况发生。 图10 部分遮挡行人目标跟踪结果Fig.10 Partially obscures pedestrian target tracking results 图10为露台场景中第1087帧至第1092帧存在部分遮挡时的行人目标跟踪效果。可以看到,person1逐渐被person2遮挡。当遮挡低于60%时,行人目标的跟踪是没有受到影响的。只有当遮挡超过60%以上时,才出现了行人目标的跟踪丢失。结果证明本文的跟踪算法对于处理行人目标部分遮挡时具有一定的鲁棒性。 本文通过YOLOv3算法快速检测行人目标,确定目标框,再结合FAST和BRISK算法对前后两帧中的行人目标进行特征点提取与匹配以达到跟踪的效果。实验证明算法在背光、行人目标快速移动、行人部分遮挡等条件下均能实现较好的跟踪。但在检测过程中,由于目标遮挡较大的问题造成后续目标跟踪的准确率有所降低,未来可在网络训练中增加60%以上遮挡的行人图片样本,以提高算法的鲁棒性。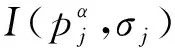
4 实验结果与分析



5 结 论
猜你喜欢
电子制作(2019年12期)2019-07-16 08:45:20
电子测试(2018年6期)2018-05-09 07:31:41
电脑知识与技术(2018年35期)2018-02-27 13:29:44
电子测试(2017年11期)2017-12-15 08:57:38
中国交通信息化(2017年9期)2017-06-06 07:14:57
自动化学报(2017年11期)2017-04-04 02:52:44
工业设计(2016年11期)2016-04-16 02:49:43
电视技术(2014年11期)2014-12-02 02:43:28
河南科技(2014年22期)2014-02-27 14:18:12
河南科技(2014年5期)2014-02-27 14:08:30
