
基于改进型YOLOv3的SAR图像舰船目标检测
2021-04-07 07:21句彦伟
系统工程与电子技术 2021年4期
陈 冬, 句彦伟
(南京电子技术研究所, 江苏 南京 210013)
0 引 言
人工智能的兴起引发了计算机视觉领域的快速发展,深度学习在光学图像诸多任务(如分类、检测、分割等)上取得了突破性的进展,而其在合成孔径雷达(synthetic aperture radar,SAR)图像上的运用远未普及,在精度、速度等方面均存在着严重的限制。
SAR图像舰船目标检测具有极广的应用,在民用领域上,有助于海运检测与管理;在军事领域上,有利于战术部署,提高海防预警能力。传统的SAR图像舰船目标检测方法多采用恒虚警率法[1]、模板匹配法[2]、尾迹检测法[3]等。这些方法多依赖于人工手动设计提取复杂的特征,且取得的效果泛化能力较差。
神经网络的优点在于自动提取特征而不需要手动设计,这对于未来的雷达智能感知来说具有重要的意义。基于深度学习的新兴SAR图像舰船检测依赖于计算机视觉已取得的成果,然而SAR图像与光学图像特性存在诸多不同,因此研究基于神经网络的SAR图像舰船检测仍有许多科学问题需要解决。
当前光学图像中目标检测方法主要有以下两种:双阶段检测、单阶段检测。以R-CNN系列[4-6]为代表的双阶段检测方法具有非常高的检测精度,主要思想是先对输入的图像进行区域划分,获取候选框,对每个候选框分类,相同类别的合并,回归出最终每个目标的检测框。其存在的主要问题是区域划分耗时耗力,Faster R-CNN[6]通过卷积网络实现区域划分,第一次实现了R-CNN[4]系列的端到端训练,降低了检测时间。尽管如此,Faster R-CNN检测速依旧较慢。
单阶段的检测方法具有非常高的检测速度,典型代表有SSD系列[7-9]与YOLO系列[10-12]。其主要思想通过神经网络直接回归出目标的类别、可信度以及坐标框,由于未采用二阶段候选框生成的概念,虽然检测速度取得了很大的提升,但检测精度却有所下降。而YOLOv3[12]检测方法的出现改变了这一状况,其在取得快速检测的同时保证了检测精度。
以上提及的方法大部分基于锚框(anchor)的思想,即预先设定大小的框。这一anchor的设定亦成为了检测速度再次提高的桎梏,当前,已有研究提出无锚框(anchor free)的概念。最先提及该概念并用于检测中的是百度提出的人脸检测方法DenseBox[13],现如今出现的方法有FCOS[14]、CornerNet[15]。虽然其是未来检测的趋势,但当前其发展运用远不及基于anchor的方法。
深度学习在SAR图像上的检测目前已取得相当的成果,基于Faster R-CNN的思想,文献[16]提出了改进模型,检测精度达到了78.8%;基于SSD的思想,文献[17]提出了一个改进型模型,适用于小舰船目标检测,精度可达到88.1%;基于轻量化模型、注意力机制等思想,文献[18]设计了一个新的舰船检测模型,降低了参数量,可实现检测的实时性。
相较于光学图像,SAR图像中不包含丰富的特征信息,舰船目标尺寸变化大、干扰源多,这些对检测都会产生一定的影响。YOLOv3的方法在光学图像中取得了很好的效果,但光学图像和SAR图像的成像原理存在着本质上的区别,直接将该方法运用到SAR图像中存在识别不准确、召回率低、检测框偏移较大等问题。基于常规卷积方案的原YOLOv3模型无法对舰船目标尺寸适应性地调整且网络过深不适用于SAR图像,同时可能会引起过拟合问题,因此很有必要对其特征提取部分进行改进。
本文的创新点主要如下:
(1)YOLOv3的方法本身对于小目标检测有很好的效果,本文将该方法引入到SAR图像舰船目标检测中,重新设计了特征提取网络,有效地提高了检测精度,降低了虚警概率和漏检概率。
(2)本文采用参数量较少的ResNet50来实现特征提取并防止过拟合,避免无用以及重复特征的提取。为进一步降低参数以及提高性能,在跳跃连接过程中使用了平均池化,具有计算量更少、检测更快的优点。
(3)为在特征提取过程中引入更多的舰船形状等信息,本文在特征提取网络部分加入了可变形卷积,通过与检测任务的共同学习,适应性地改变采样点,使其获得类舰船目标形状的感受野范围,能够更好地帮助网络实现检测。
(4)使用ShuffleNetv2对YOLOv3特征提取网络进行轻量化设计,在牺牲些许精度的情况下,拥有了更快的检测速度,为轻量化研究提供参考。
1 基于改进YOLOv3的舰船检测
本文的改进方案对于YOLOv3网络效果很好的部分进行保留:其一,融合了特征金字塔结构[19]可以在多尺度进行预测,有助于识别不同尺度的舰船目标;其二,损失函数对小目标的偏重思想,可以防止小舰船目标预测错误对整体损失函数并没有太大影响,使网络注意到小舰船目标。本文的网络结构如图1所示,其可大体分为两部分:特征自动提取网络与目标检测分类(特征解码)网络。
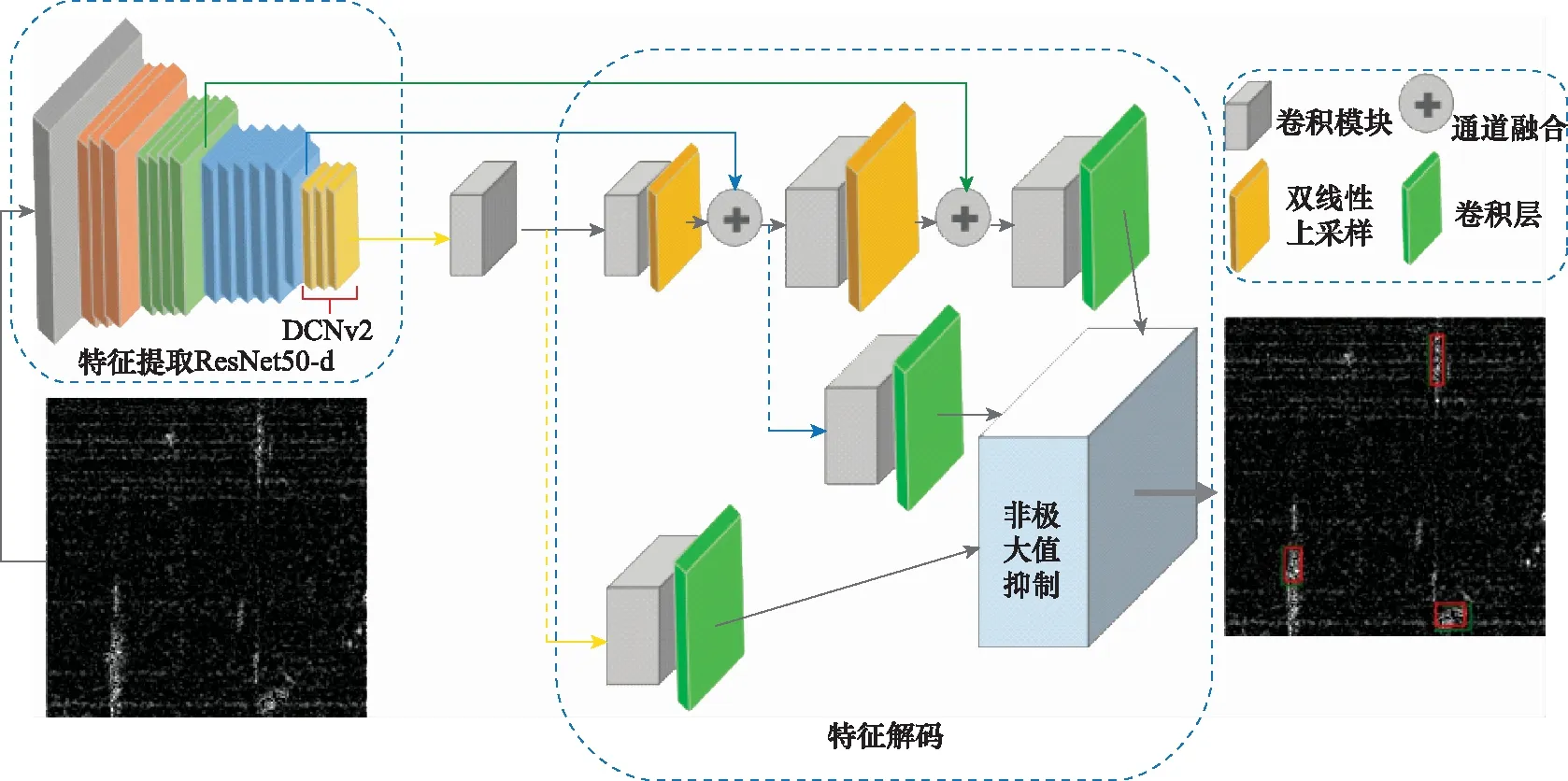
图1 本文网络结构
1.1 特征提取网络
1.1.1 舰船ResNet50-d特征提取
对于光学图像采用的神经网络而言,一般情况下,网络越深,提取特征的能力越强,感受视野范围越大,获取的高级语义信息越多。但由于网络过深,梯度反向传播过程中过小以致网络难以迭代更新,因此不能简单的对神经网络进行堆叠。ResNet[20]网络采用残差连接的方式解决了神经网络增加深度的同时梯度消失的问题,使得训练数百层的神经网络成为了可能。
ResNet按照网络层数不同主要分为5类,其中最常用的是50层结构的ResNet50(见图2)。由于ResNet50网络具有比较好的特征提取能力,且网络相对于Darknet53而言层数少,参数量更小,运用也更加灵活;同时考虑到SAR图像不同于包含丰富特征信息的光学图像,本文最终采用ResNet50网络的基本结构作为特征提取网络,相比较于原YOLOv3可以有效地降低参数量和重复特征数量。

图2 ResNet50结构
另外,本文参照文献[21]使用了ResNet50-d的思想,将在跳跃连接过程中使用的通过步长进行降维的方法更改为平均池化形式(对比见图3)。平均池化即对邻域内的特征点求平均值,往往能够很好地保留背景信息,有助于网络对特征的提取,另一方面也可以有效地降低参数量,节约算力。
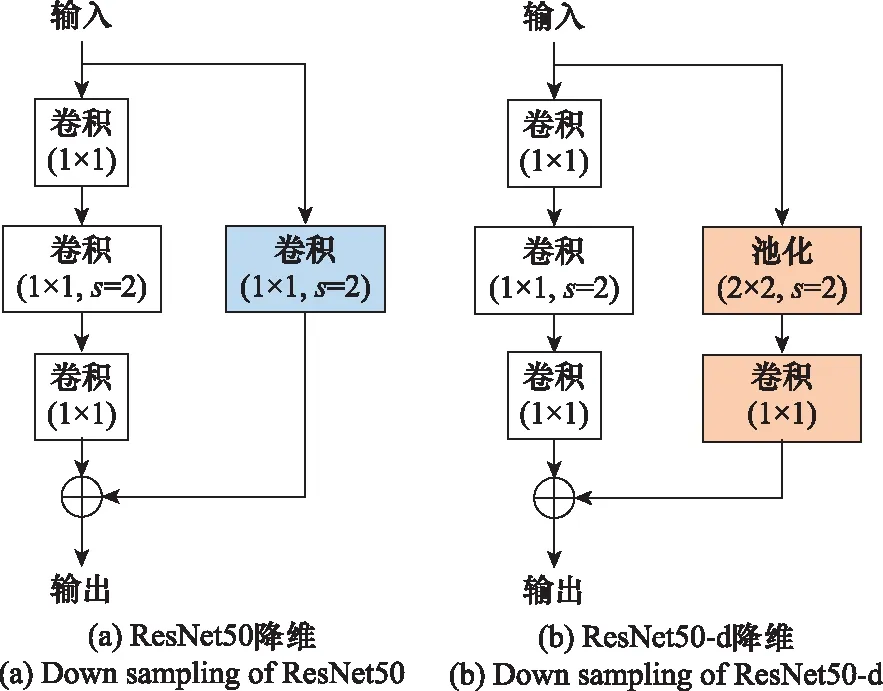
图3 ResNet50与ResNet50-d降维对比
1.1.2 适用于舰船检测的可变形卷积
舰船目标尺度不统一,目标形状多变,采用普通的卷积神经网络对于大尺度和未知形状的舰船目标检测存在固有的缺陷,该缺陷来源于卷积神经网络固有的几何结构:卷积核对输入特征图的固定位置进行采样;池化层以固定的比例进行池化。
本文采用的可变形卷积[22]对普通卷积进行修改,其基本思想对采样点学习一个偏移,使卷积核专注于感兴趣区域或者目标而不是固定位置的采样。普通卷积采样和可变形卷积采样的对比如图4所示。
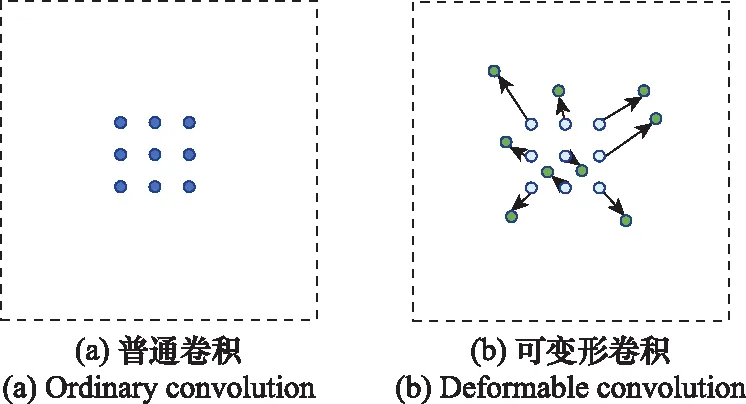
图4 普通卷积与可变形卷积对比
定义膨胀率为1的普通3×3卷积,R={(-1,-1),(-1,0),…,(0,1),(1,1)}。对于输入特征图x,对应的特征图位置p0的输出y有
(1)
式中,w为每个采样值的权重。
而对于可变形卷积来说,额外增加了一个偏移值:
(2)
实际操作中,对得到的非规则抽样位置进行限定,使其保持在特征图内。由于偏移值Δpn通常是小数,可采用双线性插值法进行实现。可变形卷积的实现依赖于不规则的抽样位置,可通过平行的卷积网络对特征图进行偏移位置的学习,再通过双线性插值实现端到端的训练。
由于可变形卷积打破了常规的抽样区域形状,在模型运用过程中可能会将采样点拓展至感兴趣区域之外的部分,纳入更多的无关信息与上下文信息,影响模型的性能。因此,可变形卷积v2[22]提出改进方案,平行网络不仅仅学习每个位置的偏移值,还学习每个采样点的权重,避免极端抽样点对网络特征提取的影响。通过权重的控制可以有效地降低过多上下文信息的影响,增加了更大的自由度,对于可能不需要的采样点权重可以学习成为零。其计算公式变为
(3)
通过平行的卷积神经网络可将采样点偏移值和权重值纳入网络学习的过程中,由最终检测的损失函数监督学习最佳的偏移值和权重值。假设平行网络的输入特征图为N通道,采样点偏移部分对应于两个维度的偏移值,因此输出通道数对应于2N;而权重网络是每个采样点的权重值,通道数对应于输入通道数N,其实现的框图见图5。
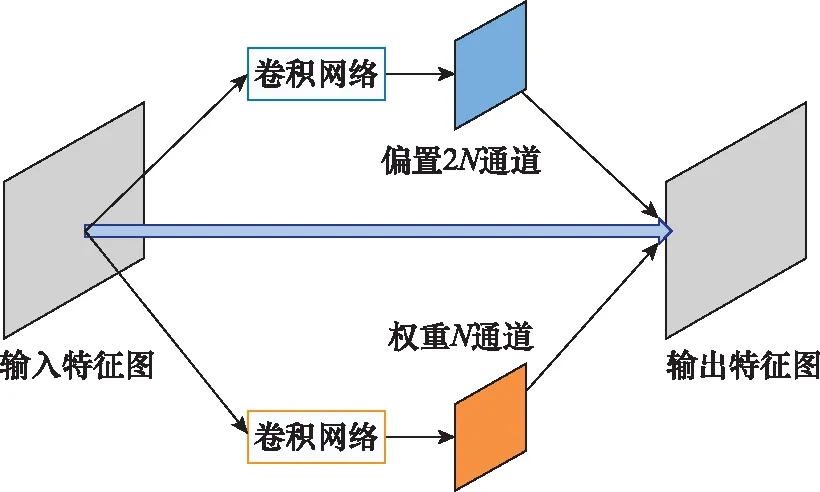
图5 可变形卷积实现
可变形卷积虽能适应性地提取特征信息,但引入一个平行网络加入了很多额外的计算量。若全采用可变形卷积设计网络,会导致参数量的巨大、网络难以训练等问题。
综合考虑,本文对改进的ResNet50-d特征提取网络最后一个降采样阶段(见图1特征提取部分)使用可变形卷积(DCNv2),在特征提取与参数量之间取得一个比较好的平衡。
1.2 舰船检测网络解码
在网络实现过程中,目标检测分类网络可分为3部分:类别解码、置信度解码和坐标框解码。SAR图像舰船检测仅为舰船一类可不考虑类别解码;置信度解码可在输出维度中占据固定位置,使用sigmoid函数激活,限制在区间0~1。
检测的关键点在于坐标框的解码,本文采用YOLOv3方案的解码结构,通过网络得到的坐标值(tx,ty,tw,th)并不是最终的坐标框结果,而是经过网络编码的形式,因此需要对该形式进行解码。解码公式如下:
bx=σ(tx)+cx
(4)
by=σ(ty)+cy
(5)
bw=pwetw
(6)
bh=pheth
(7)
式中,cx和cy代表的是检测中心点所处网格区域的左上角坐标;pw和ph代表的是anchor的宽和高,σ(tx)和σ(ty)代表的是检测中心点和左上角的偏移值(使用sigmoid激活函数将范围限定在当前网格区域内);etw和eth代表预测的宽高偏移量。
得到的bw和bh即为最终坐标框的宽和高,再将检测的bx和by乘以所采用的采样率(8、16、32)即得到坐标框的中心坐标。
1.3 损失函数
单阶段目标检测过程中的损失函数由3部分组成:框位置损失、目标性损失以及分类损失。对于SAR图像舰船目标检测不需要对其进行分类,因此损失函数应由前两者组成。
框位置损失即检测框位置带来的损失,由检测框相较于特征图位置的损失和高宽损失组成,前者损失为
(8)
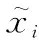
宽度和高度损失为
(9)
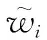
为了提升小目标所占比重,权衡大框和小框之间的框坐标损失,最终采用的框位置损失函数乘以一个系数,即
w=2.0-tw×th
(10)
式中,w为框位置损失函数的系数;tw和th分别代表网络模型预测的编码宽和高(见式(6)和式(7))。编码宽和高越大对应检测框越大,框损失函数系数越小;编码宽和高越小,框损失函数系数越大,由此动态调整大框和小框的不同比重。
目标性损失即置信度带来的误差,损失函数形式为
(11)
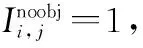
最终的损失函数形式为
l=w×(lxy+lwh)+lobj
(12)
2 实验验证
本文基于百度AI Studio云端实验室,采用百度paddlepaddle的深度学习框架,在jupyter notebook中完成实验。实验的云端硬件配置为8核CPU,内存为32 GB,显卡为Nvidia Tesla V100,显存为16 G。
2.1 实验数据
本文方法主要采用的数据集是海军航空大学李健伟教授等公开的SSDD[23-26]。该数据集包含1 160张图像、2 358只舰船目标,单张图像包含舰船数从1到29,平均每张图像中有2.03只舰船,包含7像素×7像素的小目标舰船到211像素×298像素的大目标舰船。该数据集中的图像具有多种极化模式、不同分辨率、远近海场景等,能够较好地验证算法有效性。由于当前该数据集并没有统一的划分形式,诸多其他文献提供的算法均依照其本身实验需要对数据集进行划分。本文所提算法均采用统一划分方式,可提现算法效果的提升。
2.2 训练策略
SSDD数据集按照7∶2∶1的比例随机划分为训练集、验证集和测试集,其中测试集包含267个舰船目标,相较于其他文献提及的数据划分,训练目标更少且包含更多的测试目标。训练过程中,采用RMSProp[27]优化器,设置的初始学习率为0.001。该优化器的特点是可以自适应地调整学习率,用于解决使用Adagrad[28]后,模型训练中后期学习率急剧下降的问题。
所有模型训练过程中均采用了迁移训练中预训练模型[29],训练200个epoch,训练的batch size取32。训练过程中,epoch为4的倍数或者超过150时,对模型进行验证,保存验证结果最优的模型直至训练完成。另外,保存最后一次训练模型,可加载进行再训练。
所有模型均使用了数据增广方法,其主要增加训练数据集,使得数据尽可能的多样化,有助于训练所得模型具有更强的泛化能力,主要采用了翻转、旋转、缩放、裁剪、平移、加噪声、改变对比度等随机方案。
2.3 实验结果
图6展示的是本文改进之后的方案ResNet50-d-DCN在SSDD数据集上的部分预测结果,图中的绿色框是真实标注的目标框,红色框是算法检测的结果。图6(a)展示了近海岸检测情况,图6(b)展示了远海小目标检测情况,图6(c)展示了远海大目标检测情况。可以看出,本文的算法能够很好地检测出目标,在远海小目标、近海小目标、陆地背景干扰下依旧取得很好的效果。

图6 基于本文方案的SSDD数据集检测结果
表1和表2中的模型即是本文逐步改进提升的验证结果,其中Darket53指的是原YOLOv3模型,ShuffleNetv2即轻量化设计YOLOv3模型,ResNet50以及ResNet50-d是本文最终方法ResNet50-d-DCN的中间模型。表1展示了在数据测试集上检测的基本情况,表2展示了评价指标结果。

表1 各模型检测效果统计结果
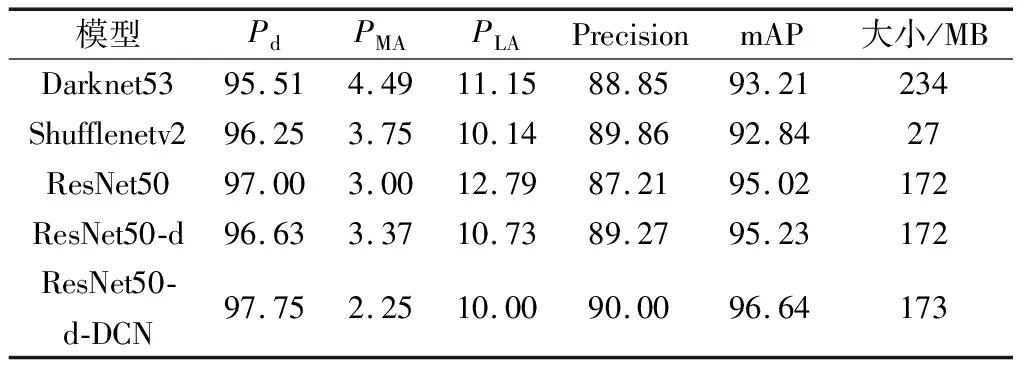
表2 SSDD数据集检测结果评价指标
表1中TP(true positives)为正确检测数目,FN(false negatives)为漏检数目,FP(false positives)为虚警数目,GT(ground truth)为真实数目。
表2中Pd为检测概率,PMA为漏检概率,PFA为虚警概率,Recall为召回率,Precision为精确度,MAP(mean average precision)为平均精度。
此处采用的MAP为积分形式:

(13)
式中,P(R)指的是精度-召回率曲线。由于此处只有舰船一种检测目标,不需要对各类别AP求平均,因此MAP=AP。
2.4 实验分析
从表1中可以看出,本文改进算法在SSDD测试集中,共有125张图像,267个舰船目标,正确检测出261个目标,漏检6个目标,虚警29个目标;而原YOLOv3模型正确检测出255个目标,漏检12个目标,虚警32个目标。
从表2中可以清楚地看出,一方面,相较于采用Darknet53的原YOLOv3模型,本文使用的算法ResNet50-d-DCN在SSDD测试集上mAP提高至96.64%,模型大小降低至172 MB;另一方面,同样可以清楚地看到,通过ShuffleNetv2轻量化设计的模型在检测效果上稍微下降了些,但考虑到模型大小仅为27 MB,对比于大小为234 MB的原YOLOv3模型,其可实现移动端嵌入式的使用。
对比Darknet53与ResNet50的模型可以发现,参数量较多的Darknet53检测效果反而比ResNet50的效果差,这与光学图像中检测的结果是截然相反的。一方面考虑到可能是数据集划分以及训练集目标过少的原因,使得参数量大的模型难以更好的训练;另一方面,考虑到SAR图像本身的特性以及图像中所包含的有用信息,光学图像检测方法运用于SAR图像中应该适当地降低参数,避免重复以及无用的特征提取,这也是本文接下来的主要研究内容。
为了进一步验证算法的有效性,本文额外使用了中国科学院空天信息研究院王超研究员团队公开的SAR图像船舶检测数据集[26](SAR-Ship-Dataset)进行检测效果的验证,部分检测结果如图7所示。
图7(a)展示了近海岸多目标检测情况,图7(b)展示了远海多目标检测效果,图7(c)展示了复杂背景下舰船目标检测情况,而图7(d)展示了多尺度目标检测效果。从图7(c)中可以看出,本文算法具有很好的抗干扰特性,在复杂背景情况下依旧能正确识别舰船目标;从图7(d)中可以看出,本文方法即使在舰船目标与背景不成比例情况下,对于小目标检测效果依旧非常好。
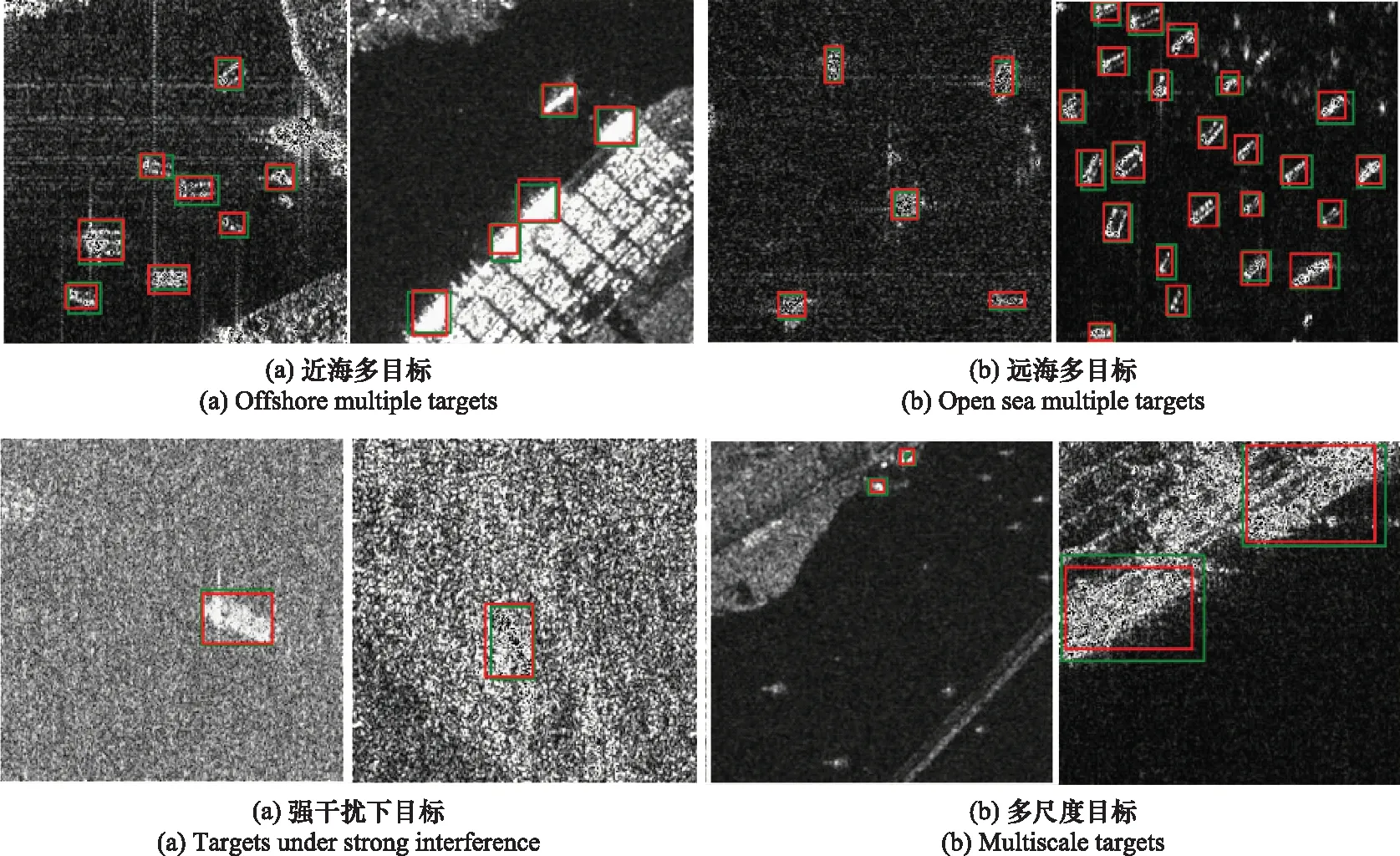
图7 基于本文方案的SAR-Ship-Dataset检测结果
图8显示了本文ResNet50-d-DCN算法在两个测试集检测中的漏检与虚警情况,图8(a)为SSDD数据集,图8(b)为SAR-Ship-Dataset数据集,对于近海岸目标和岛屿等目标存在着识别问题。

图8 虚警与漏检情况
分析原因可知:一方面,近海岸目标背景过于复杂,且目标和远海目标数据类型不均衡,对检测训练造成一定的影响;另一方面,部分岛屿与舰船目标具有相似的特征,神经网络无法忽略部分相似岛屿是不是舰船目标,对置信度阈值的设置会导致识别的最终不同结果:过低的阈值导致虚警,而过高的阈值导致漏检。
3 结束语
本文基于深度学习的方法提出用于SAR图像舰船检测的改进型YOLOv3模型,不同于常规卷积的方法,采用了可依据舰船形状与尺寸自适应采样的可变形卷积等方法。经SSDD数据集验证,相比较于原YOLOv3模型,在检测效果方面,有效地降低了虚警概率和漏检概率,提高了检测精度;在模型大小方面,基于ShuffleNetv2的思想,对原YOLOv3进行轻量化设计,该模型大小仅为27 MB,对于未来网络的轻量化研究具有重要的意义。
本文的下一步工作,将考虑如何在非直接迁移光学图像检测方法的前提下,将轻量化与精度统一起来,在有效提取目标特征的同时保持模型的轻便结构。进一步探讨小样本学习情况下,如何基于有限的数据集提升SAR图像舰船检测的效果并使其具有良好的泛化能力。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
北京航空航天大学学报(2021年9期)2021-11-02
舰船科学技术(2021年12期)2021-03-29
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
舰船科学技术(2016年1期)2016-02-27
噪声与振动控制(2015年4期)2015-01-01
电视技术(2014年19期)2014-03-11
