
分布式深度学习通信架构的性能分析*
2021-04-06 10:48:20张立志冉浙江赖志权
计算机工程与科学 2021年3期
张立志,冉浙江,赖志权,刘 锋
(国防科技大学计算机学院并行与分布处理国防科技重点实验室,湖南 长沙 410073)
1 引言
最近几年,分布式深度学习在语音识别[1,2]、 图像识别[3,4]、自然语言处理[5,6]和机器翻译等领域都取得了丰硕的成果。分布式深度学习在多节点上并行运行深度学习任务的能力,能够有效应对海量数据和超大神经网络模型的挑战,高效地训练出可用的模型,对人工智能的发展有极大的推动作用,因此对分布式深度学习加速大数据、大模型训练的研究是目前人工智能领域的主流方向之一。
大规模的深度学习任务往往要充分利用“大数据”并且有效训练“大模型”,但是随着海量数据和庞大模型规模的发展,训练数据的容量和模型参数的规模已经超出单节点的处理能力[7],逐渐成为深度学习发展的瓶颈。目前,更主流的解决方案是使用多机器、多GPU进行分布式深度学习的训练,即通过将大数据集和大规模深度学习问题分解到多台机器和设备上并行地处理这些问题。这种方案同时利用多个工作节点,采用分布式技术来执行训练任务,提高了深度学习模型的训练效率,减少了训练时间。为了提供所需的计算能力,通常需要几十甚至上百个GPU,在这个背景下,涌现出许多新的软硬件技术,包括GPU的兴起和大规模计算机集群的广泛使用。然而,当GPU节点数量增多时,协调GPU之间的通信也是一个复杂的问题。当只有2个GPU和几兆字节的参数时,GPU通信的方式影响较小;但是当模型有几十亿个参数时,就会占用千兆字节的空间,并且还要同时协调几十个GPU,可能会带来巨大的开销,成为分布式训练性能提升的瓶颈,此时GPU之间的通信机制就非常重要。
本文利用天河GPU集群的硬件条件实现和部署带宽优化架构Ring Allreduce和传统的参数服务器PS(Parameter Server)架构,基于这2个架构和经典的数据集训练典型图像分类神经网络AlexNet和ResNet-50,获取模型训练效率的结果,分析Ring Allreduce架构和PS架构相比在单个GPU性能和整体架构可扩展性上的差异,实验结果表明Ring Allreduce可以有效加快大规模数据集的训练。
2 背景
2.1 相关工作
在深度学习的背景下,大多数人专注于对网络模型的探索,AlexNet在卷积神经网络中首次使用了局部响应归一化等技术,提高了模型训练的速度和精度,减少了过拟合[8]。ResNet在输出和输入之间引入了一种快捷连接,当网络加深时,梯度在传播过程中不会消失。因此,当使用ResNet网络进行特征提取时,网络的深度可以大大增加[9]。目前对于网络模型的优化已经达到了很高的水准,但是在模型的训练速度上还有很大的提升空间。一些学者关注在单个机器上进行优化,训练较小的模型,但是这并不能解决海量数据带来的问题。还有许多学者探索了通过并行优化来扩展机器学习的算法[10,11]。大部分研究集中在分布式梯度计算上,忽略了对通信问题的探索。
在分布式深度学习训练中要实现多机协作就必须要通信。通信的内容主要是参数或参数的更新,以实现全局信息共享;通信的步调可以是同步或者异步;通信的拓扑架构有树形、星形、环形和中心式等方式,用以确定哪些节点之间需要进行通信。传统的参数服务器架构(PS)把工作节点和模型存储节点在逻辑上区分开来,参数服务器和工作节点之间进行交互,各工作节点之间的交互过程被隔离开,可以获得较高的容错性。模型参数可以划分到多个参数服务器上存储,能够维护较大的模型。基于Hadoop和Spark的分布式深度学习训练架构采用的是迭代式MapReduce架构[12,13],Map操作完成数据分发和并行处理,Reduce操作完成数据的全局同步和聚合,这样能够保持迭代之间的状态,并且执行策略也更加优化。但是,MapReduce架构中运算节点和模型存储节点没有很好地逻辑隔离,因此只能支持同步通信模式。而且MapReduce对于中间数据处理的灵活性和效率比较低,在有大量中间数据生成的迭代式机器学习任务中效率低下。另一种实现分布式机器学习的方法是消息通信接口(MPI),该方法主要使用AllReduce算法来同步信息。这种传统的规约运算是星型AllReduce架构的算法基础,在并行计算的过程中会受到带宽瓶颈的制约。分布式机器学习中基本的模型聚合方法主要是加和、平均等,这些可以使用AllReduce的算法实现有效的处理。传统的基于AllReduce算法实现的架构对于同步的并行训练有重要作用,也是现在很多深度学习分布式训练中实现通信功能的基础。百度的DeepSpeech系统[14]和Uber的Horovod[15]基于AllReduce算法实现了Ring Allreduce的架构,可以避免星型Allreduce和PS架构造成的通信瓶颈问题。
PS和Ring Allreduce是2种广泛应用的分布式深度学习训练架构,这2种架构自提出以来就得到了分布式机器学习领域的普遍重视。现在很多分布式训练的架构都是基于这两者实现的,TensorFlow、PyTorch和MXNet等都把PS和Ring Allreduce作为主要的分布式训练架构。
传统PS分布式训练架构中GPU之间的通信方式为:多个GPU分别发送数据到主GPU,然后分别从主GPU接收数据[16]。当GPU数量增加时,通信数据量超过单个GPU带宽,会造成通信瓶颈,影响分布式深度学习的可扩展性。Ring Allreduce架构中每个节点只与相邻的2个节点通信,不需要中心主GPU节点,所有节点都参与计算和存储[17]。PS模型同步架构的通信成本随架构中的GPU数量线性增长。但是,Ring Allreduce架构中通信成本是恒定的,与系统中的GPU的数量无关,整体性能提升与GPU数量的增加成正比。
2.2 数据并行和模型并行
本文在进行分布式深度学习通信架构性能分析中使用的神经网络模型规模不是主要限制因素,但数据集却相当大,Facebook[18]和Berkeley[19]等大规模数据集的分布式训练方法采用的是数据并行[20,21],这种并行训练方法更高效。如图1所示,对整个数据集进行划分,不同节点用分配到的数据更新本地模型。在同步更新模式下,首先在每个节点上分别计算不同批次数据的梯度,之后对所有节点上的梯度求平均值,最后使用平均后的梯度更新每个节点中的模型参数。

Figure 1 Data parallelism
模型并行是指将机器学习模型切分成若干子模型,每个节点负责一个子模型的计算,节点之间存在依赖关系,工作节点之间需要相互等待信息完成计算;为保证子模型的联系和依赖,相邻的2个工作节点需要同时存储子模型中的部分重复参数,这会造成数据的冗余,在模型参数没有达到超大规模级别时,模型并行比数据并行低效。而且现在的机器内存普遍增加,足够加载整个神经网络模型,神经网络的复杂度不是性能的主要瓶颈。因此,大多数分布式机器学习采用的是数据并行。
2.3 分布式深度学习的基本过程
从整个数据处理过程来看,并行分布式深度学习主要包括划分训练数据、分配训练任务、分配训练资源和整合分布式训练结果,以实现训练速度和训练精度的完美平衡。其基本过程如图2所示,可以分为4个步骤:数据和模型划分[22]、单机优化[23]、节点之间的通信[24]以及数据和模型汇总[25]。
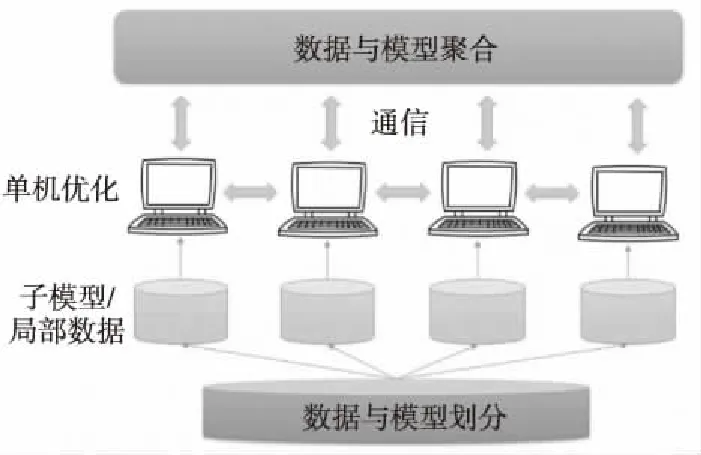
Figure 2 Process of distributed deep learning
3 分布式深度学习通信架构
3.1 参数服务器架构
PS架构主要由2个部分组成:参数服务器PS节点和工作(worker)节点,其整体架构如图3所示。PS节点中的灰色方块表示全局参数,worker节点中的黑色方块表示模型参数副本。在PS架构中,PS节点维持一个全局的共享参数,共同完成所有参数的更新。每个工作节点被分配部分数据和处理任务,负责处理本地的训练任务。工作节点之间没有通信,只通过客户端接口与PS节点进行通信,从PS节点获取最新的模型参数,并且将本地产生的模型更新发送到PS节点。PS节点必须从所有工作节点接收参数,并将更新后的参数发送到工作节点[26]。
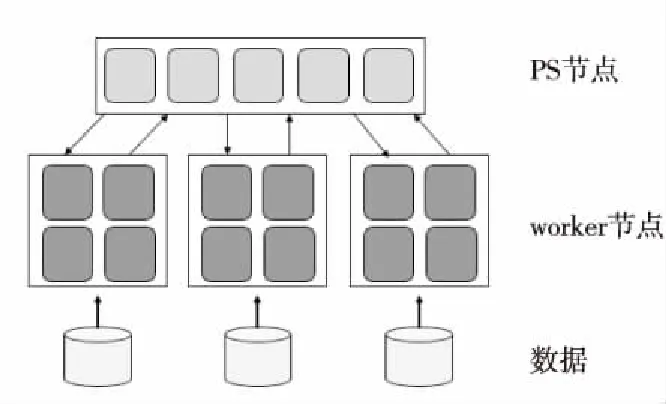
Figure 3 PS architecture
假设工作节点数量为N,每个节点中的数据量为K,PS节点从所有N个工作节点接收数据,总共接收到的数据量为K*N。在梯度聚合之后,PS节点需要把数据发送给所有N个工作节点,数据量也是K*N。则整个过程数据的传输次数为2*N次,传输的数据量为2*N*K。
3.2 Ring Allreduce架构
Ring Allreduce架构是一种基于环形拓扑实现的通信架构,图4展示了这种架构的总体工作流程,其中Rank表示每个GPU所属的进程号,梯度同时在Rank之间传递。Ring Allreduce架构中每个机器都是一个工作节点,并且在逻辑上呈环状布局。该架构舍弃了中心参数聚合节点,使数据在节点间环形流动。在分布式深度学习过程中,可采用后向传播法来计算梯度,后面层的梯度先计算,前面层的梯度后计算。Ring Allreduce架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。
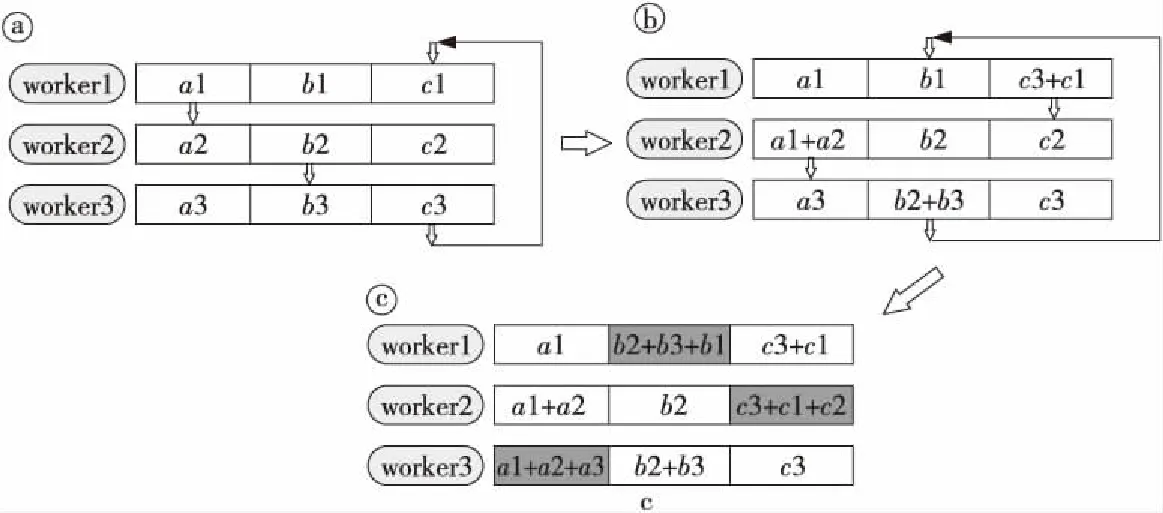
Figure 5 Data transmission and calculation in Scatter-Reduce stage
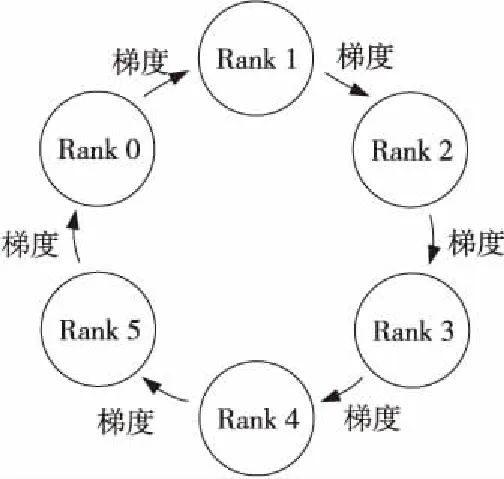
Figure 4 The topological architecture of Ring Allreduce
Ring Allreduce架构的工作流程分为2个阶段,分别是Scatter-Reduce和Allgather。Scatter-Reduce阶段完成数据的分发和并行处理,各个工作节点将交换数据,最后每个节点上会有部分最终结果;Allgather阶段完成数据的全局同步和规约,每个工作节点交换包含的部分最终结果,使所有节点都有完整的最终结果。
(1)Scatter-Reduce阶段:假设此过程的目标是求和,系统中有N个工作节点,每个节点都有同样包含K个元素的数组,在Scatter-Reduce的最后阶段每个节点都应该有一个包含原始数组和的并且尺寸大小相同的数组。如图5步骤ⓐ所示,首先每个节点将本地数组分为N块,其中N是Ring Allreduce架构中工作节点的数量。然后在步骤ⓑ中,第1次迭代发送和接收完成后,每个节点上有1个块被累加,该块是由2个节点的同样位置的块组成的和。这种数据传递方式一直持续到Scatter- Reduce阶段结束,每个节点上都有1个块包含部分最终结果,如步骤ⓒ中深色块所示,该块是所有节点对应位置块的和。
(2)Allgather阶段:每个工作节点交换包含最终结果的块,使得所有节点获得全部的最终结果。Allgather阶段包含N-1次数据发送和接收,不同的是,Allgather阶段不需要累加接收到的值,而是用接收到的数值代替原来块中的数值。第1次迭代完成后,每个节点有2个包含最终结果的块。在接下来的迭代中,会继续这个过程直到结束,最终每个节点都会包含全部数组加和的结果。图6展示了整个Allgather过程,可以看到所有数据传输和中间结果的值。
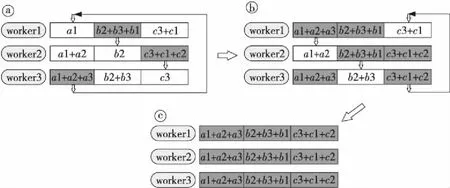
Figure 6 Data transmission in Allgather stage
整个Ring Allreduce工作过程中,在Scatter-Reduce阶段每个工作节点同时发送和接收数据,每次发送和接收的数据大小为K/N个,传输N-1次;在Allgather阶段每个节点也是发送并且接收K/N个数据N-1次。所以,每个节点传输数据的总次数为2*(N-1)次,数据总量为2*K*(N-1)/N,由于所有节点的数据传输同时进行,当整个系统的数据传输量为2*K*(N-1)时,单个节点传输的数据量只有:
T=2*K*(N-1)/N
(1)
由式(1)可知,在Ring Allreduce架构中,当工作节点数量增加时,单个节点数据传输量近似为2*K,与系统中节点数量无关。
3.3 Ring Allreduce和PS关键特点对比
总的来说,Ring Allreduce和PS的关键特点对比如表1所示。其中N是节点数量,K是每个节点的数据量。Ring Allreduce是环形拓扑架构,每个节点的数据传输量随着工作节点的增加近似保持不变,因此通信量并不会随着节点增加而增加,可扩展性较好。但是,由于只支持同步的并行方式,当有节点出现故障时会影响整个的训练过程,因此容错性较差。PS是中心式的拓扑架构,其数据传输量随着节点的增加线性增长,受传输带宽的限制,可扩展性较差,但是PS支持异步通信的方式,可以不受慢速或故障节点限制,因此容错率较高。
综上所述,Ring Allreduce架构比传统的参数服务器架构更有效,通过在所有节点上分发计算和通信,消除了通信的瓶颈,有助于分布式深度学习在大规模集群上的应用。
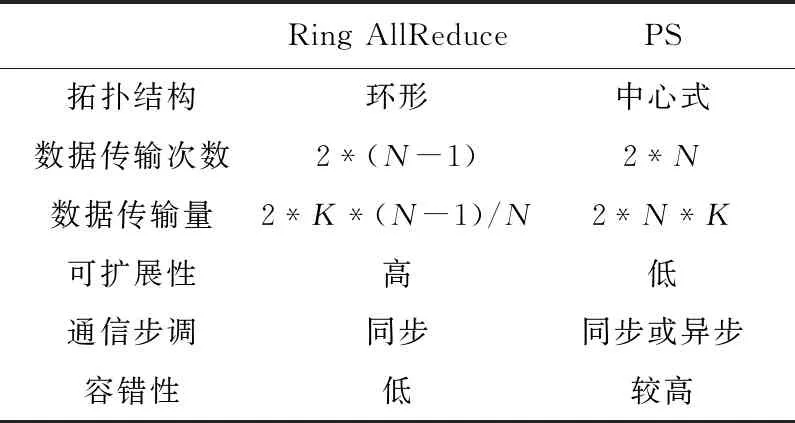
Table 1 Key features comparison between Ring Allreduce and PS
4 实验设置
4.1 实验环境
本文实验利用天河机集群的计算资源,在集群上部署分布式计算架构,统一调度和管理GPU。集群硬件环境的具体信息如表2所示。

Table 2 Hardware environment
实验中安装的软件和分布式深度学习框架如表3所示。

Table 3 Software environment
4.2 PS框架部署
实现PS对比测试架构,进行分布式深度学习训练,需要将TensorFlow中Cluster、Job和Task定义的计算集群映射到硬件上。Cluster、Job和Task基本功能如图7所示,其中Task是进程,属于特定的作业,一般一个GPU节点对应一个Task[27]。Job划分为PS Job和worker Job,PS Job用于完成参数的存储、管理和更新工作;worker Job用来执行操作。Cluster 集群系统是PS和worker的集合,包含任务运行的完整设置。
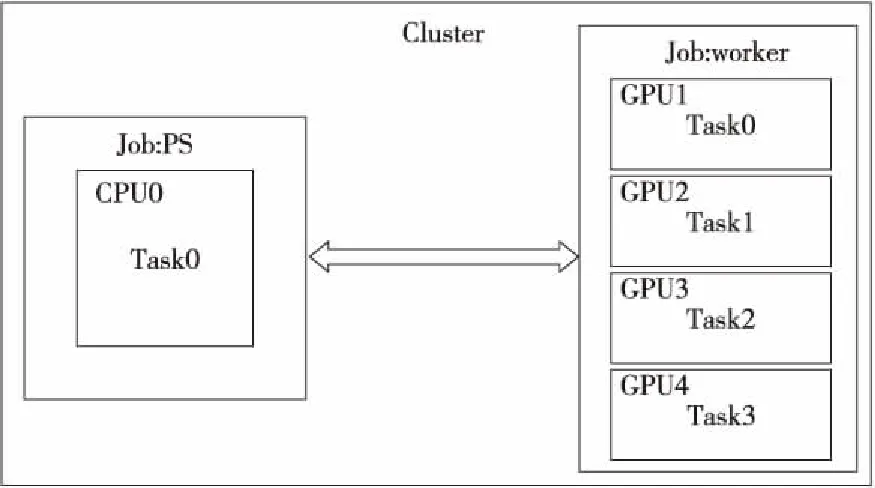
Figure 7 Schematic diagram of PS architecture cluster implemented by TensorFlow
4.3 Ring Allreduce分布式深度学习框架的部署
Ring Allreduce架构可以高效管理、调度大量的设备和节点,极大减少通信负载并且可扩展到更多的节点。其中Horovod是对Ring Allreduce架构的有效实现。
Horovod是一个开源的高性能深度学习分布式训练架构[15]。Horovod能够运行在TensorFlow环境实现底层的通信。Horovod实现的框架如图8所示,在数据并行方式下,每一个基于TensorFlow实现的模型从数据集中取得一份数据,计算完成后通过底层Horovod进行通信,更新全局模型。
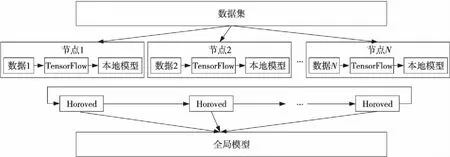
Figure 8 Implementation of Ring Allreduce based on Horovod
Horovod是使用MPI进行通信,允许MPI在集群中创建进程并访问资源。MPI是消息传递接口,是一个可用于进程间通信的函数库[28,29]。如图9所示,MPI启动所有进程并为每个进程分配Rank(Rank是Horovod框架中每个进程的编号,0号为主进程,负责保存检查点和广播全局变量等)后,Horovod在相邻的GPU节点之间建立通信链路,并将所有GPU节点在逻辑上按环状组织,完成 Ring Allreduce集群通信架构的创建。每个GPU对应一个本地的Rank,并将其添加到TensorFlow设备列表中,组成并行工作的多个进程。
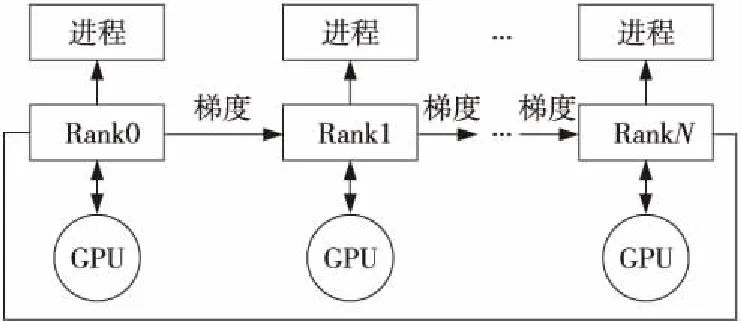
Figure 9 Diagram of MPI start process assigning Rank and binding GPUs
4.4 数据集
本文使用图像领域中的经典数据集Image- Net[30]、Cifar-10和Cifar-100[31]进行实验,3个数据集的具体参数如表4所示。
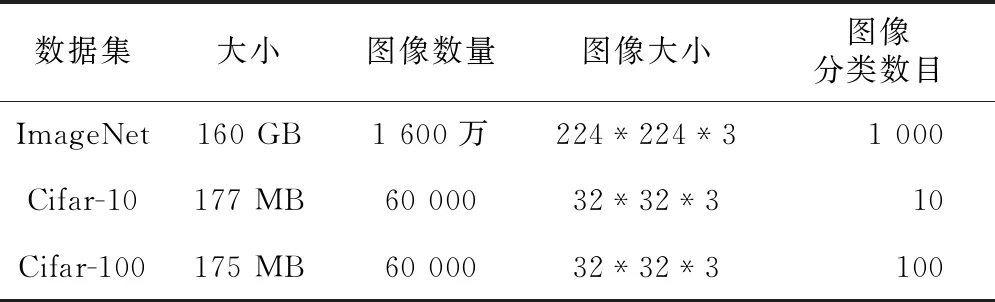
Table 4 Description of three datasets used in the experiment
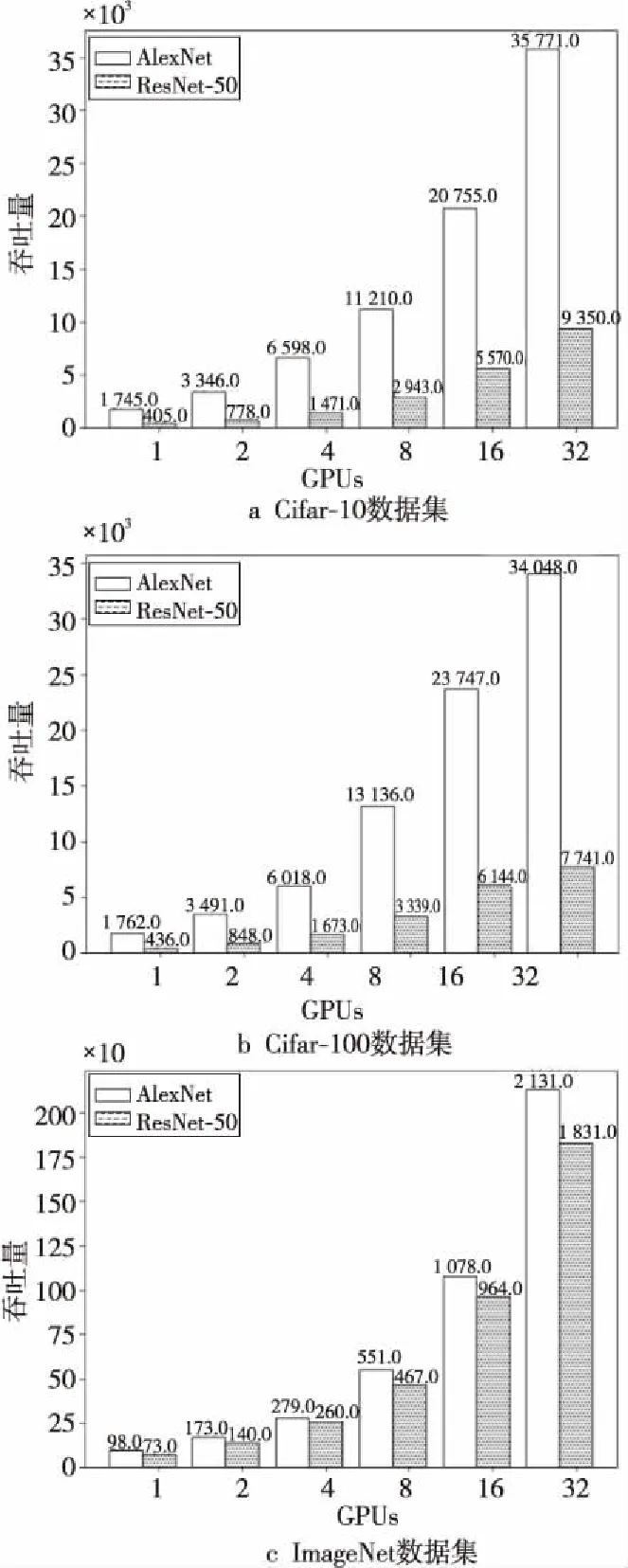
Figure 10 Throughput of training data on PS architecture
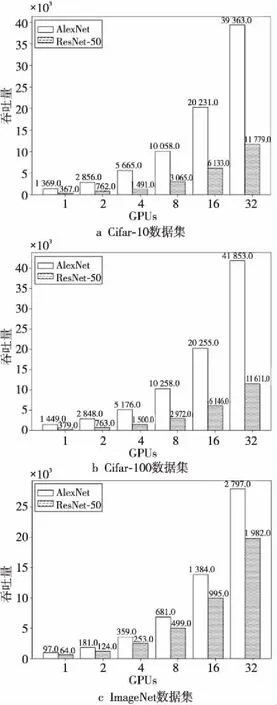
Figure 11 Throughput of training data on Ring Allreduce architecture
5 实验评估
5.1 Parameter Server架构上的实验结果
图10是在PS架构上使用Cifar-10、Cifar-100和ImageNet训练模型的实验结果,展示了训练AlexNet和ResNet-50过程中,训练数据的吞吐量,PS架构的设置中使用了1个PS节点,PS节点和worker节点处于同步参数更新模式。当GPU数量为1~8时,随着GPU数量的线性增加,图像的吞吐量也是线性增加的。当GPU数量在8~32时,处理图像的吞吐量不再与GPU数量的增加成线性关系,其增大倍数小于GPU的增大倍数。
5.2 Ring Allreduce架构上的实验结果
Ring Allreduce架构上用Cifar-10、Cifar-100和ImageNet训练模型的实验结果如图11所示。由于AlexNet网络层数比ResNet-50的少很多,因此在处理同样的数据集时,AlexNet模型的图像处理速度要明显大于ResNet-50的速度。ImageNet中的图像大小是Cifar-10/Cifar-100中的图像大小的50倍左右,因此处理ImageNet图像的速度明显比处理Cifar-10和Cifar-100图像的速度要慢。从实验数据可以看出,随着GPU数量的成倍增加,在不同模型下,每秒处理的图像数也在不断增加,基本上与GPU数量的增加成正比。
5.3 GPU性能
图12展示了在Ring Allreduce和PS架构上处理Cifar-10、Cifar-100和ImageNet数据集时单个GPU的性能。由实验数据可以看出,随着GPU数量的增加,PS架构中单个GPU的性能逐渐下降,而在Ring Allreduce架构中单个GPU的性能没有明显变化,维持在一个稳定水平。但是,在GPU数量较少时,PS架构中单个GPU的性能要优于Ring Allreduce中单个GPU的性能,这是由于实验中使用的PS架构将一个CPU当作PS节点,将GPU当作工作节点,在工作节点较少时,PS和工作节点间的通信不是影响性能的瓶颈,而CPU和GPU的组合能够带来性能上的提升。
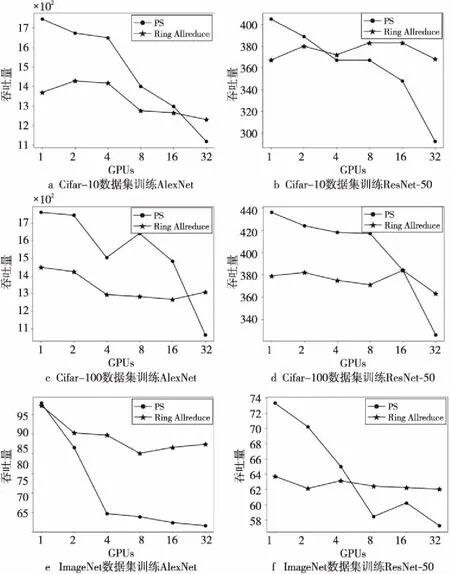
Figure 12 Single GPU changes throughput on Ring Allreduce and PS architecture
5.4 PS和Ring Allreduce架构可扩展性对比
实验结果分析采用GPU加倍时模型训练速度的增加倍数来显示架构的可扩展性。图13展示了与理想加速效果相比,Ring Allreduce和PS架构的加速比。使用32个GPU时,Ring Allreduce的加速比最高可达31,而PS架构的加速比最高只有24。理想情况下增加的GPU性能不会有损失,扩展效率是100%。表5分析了在Ring Allreduce和PS架构下,使用AlexNet和ResNet-50模型处理Cifar-10、Cifar-100和ImageNet数据集的可扩展性,其中Ring Allreduce架构的可扩展性最高达到97.2%,而PS架构的可扩展性最高只有78%。
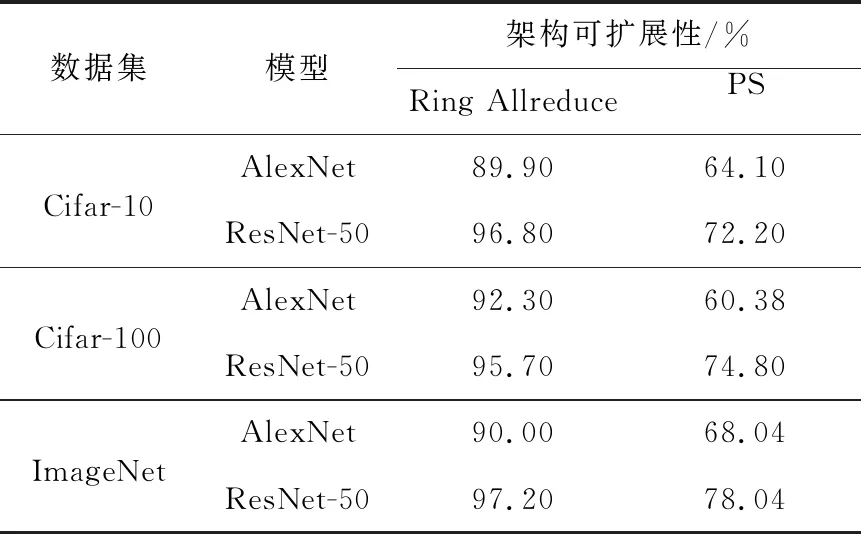
Table 5 Scalability of Ring Allreduce and PS architecture
5.5 实验结果分析
多组实验结果表明,Ring Allreduce架构在实验研究的几个项目上比传统的PS架构更有优势。在深度学习分布式训练中使用的GPU数量较多时,Ring Allreduce架构中单个GPU的性能明显优于PS架构中的GPU的;Ring Allreduce的可扩展性更好,能支持更多的GPU并行计算而不损失性能。
从前面的实验结果可以很容易看出,Ring Allreduce架构在所有模型上都有较好的扩展性。因为Ring Allreduce是一种带宽优化架构,这是其良好扩展性基础的作用。PS架构受到带宽的限制,GPU需要花费较多的时间和资源用于通信,计算所占时间相对较少,导致GPU利用率降低。当PS架构中GPU数据越来越多时,通信的代价会更高,整个训练性能的提升会越来越慢,而不是线性增长。Ring Allreduce架构中梯度通信占用GPU的资源较少,GPU资源被更多地用于模型计算,因此GPU利用率更高,GPU数量的增加不会影响到其带宽,其计算性能提升与GPU数量的增加成线性关系,因而Ring Allreduce架构的可扩展性更高。
从实验结果还可以看出,对于同样的通信架构,训练ResNet-50的加速比要普遍高于训练AlexNet的加速比。这是因为ResNet-50相比于AlexNet有更多的卷积层和计算量,ResNet-50计算和通信占比高,根据阿姆达尔定律[32]可知,其分布并行的加速比上限更高。由于深度神经网络属于计算密集型网络,其计算量占比大,参数量相对较少,因此通信占比相对较少,使用2种分布式训练方法都可以取得一定的加速效果。但是,由于深层神经网络参数量会更大,需要进行通信的数据更多,采用PS架构会更快到达带宽的性能瓶颈,使其加速比和Ring Allreduce架构的加速比差别更大。
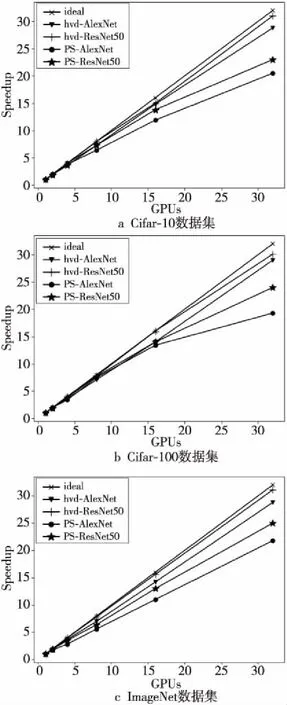
Figure 13 Ring Allreduce and PS architecture model tranining time speedup
6 结束语
本文针对集中式的PS和去中心化的Ring Allreduce通信架构进行了性能分析,并且在大型GPU集群上部署了PS架构,实现了基于Horovod的Ring Allreduce架构。此外,还对比了训练AlexNet和ResNet-50模型时,Ring Allreduce和PS架构中单个GPU的图像处理速度和整体的可扩展性。实验结果表明,Ring Allreduce架构的最大扩展效率为97.2%,而PS架构的最大扩展效率仅为78%。通过对2个通信架构的性能分析可知,基于Ring Allreduce的集群通信架构可以用来进行大规模深度学习训练,能够有效地利用集群中GPU的资源,并且保持高效的可扩展性。
猜你喜欢
计算机应用研究(2024年12期)2024-12-30 00:00:00
成都信息工程大学学报(2022年4期)2022-11-18 07:31:10
汽车工程(2021年12期)2021-03-08 02:34:30
能源(2017年10期)2017-12-20 05:54:07
汽车零部件(2017年3期)2017-07-12 17:03:58
能源(2017年5期)2017-07-06 09:25:54
电信科学(2017年6期)2017-07-01 15:45:17
自动化博览(2017年2期)2017-06-05 11:40:39
现代工业经济和信息化(2016年12期)2016-05-17 05:38:00
雷达与对抗(2015年3期)2015-12-09 02:38:50
