
基于长短时记忆网络的电商大数据同一性标定*
2021-04-06 10:48:18刘亚波吴秋轩
计算机工程与科学 2021年3期
刘亚波,吴秋轩
(杭州电子科技大学自动化学院,浙江 杭州 310018)
1 引言
在政府采购电子化的趋势下,发挥基于机器学习的大数据分析优势,对电商大数据进行同一性标定,即在政府采购海量电商大数据中找出同一种商品,对提升政府采购决策水平和效率具有重要意义[1]。同一性标定问题实质上是一个短文本相似度计算问题,但在有些实际应用场合,对标定准确率和标定速度均有较高要求。
在短文本相似度计算方面,Ho等[2]基于离散小波变换将文本转换成DNA序列,利用欧几里得距离计算已序列化文本之间的相似度。但是,文本向量化解释性不强,Yao等[3]提出了基于改进长短时记忆网络LSTM(Long Short-Term Memory)的短文本相似度计算方法,并通过其实现的归一算法来避免梯度消失。仅通过余弦距离计算相似度无泛化能力,马慧芳等[4]通过加权计算将不同词项内外共现距离相关度与强类别特征相融合用于计算短文本相似度,但考虑的语义和语境信息有限。Wu等[5]将基于BTM(Biterm Topic Model)主题建模并采用JS(Jensen-Shannon)散度计算文本相似度和基于词表征全局向量GloVe(Global Vectors for word representation)词向量建模并用改进词重WMD(Word Mover’ Distance)衡量文本相似度进行线性融合,作为距离函数实现K-means聚类,该方法在微博短文本上具有良好表现,但建模过程与计算相对复杂。Flisar等[6]基于DBpedia Spotlight框架来识别短文本中的相关概念进而实现短文本分类,但提取大量不相关特征降低了以相似度计算来实现分类任务的性能。Yang等[7]通过组合语料库中单词对的全局权重和在自身短文本中的局部权重来计算短文本相似度,对于全局和局部共现少的短文本,其样本利用率低。Lee等[8]将词嵌入模型运用于保险分析,提取索赔短文本描述特征,经词嵌入模型处理后进行相似度计算进而分类,具有良好的效果,但面对较长文本描述以及一词多义时有一定障碍。García-Méndez等[9]为实现个人银行交易文本描述分类,经分词、除去停词等预处理,基于Jaccard距离计算的文本相似度结果来减少训练样本,进而使用SVM实现分类,相似度计算方法准确率低,而且训练样本数量大时SVM训练速度慢。Maurya等[10]为降低不同发票文本描述处理成本和时间,针对在线反馈的格式不同但内容相同的文本描述,基于相似性进行排名,而针对不同内容文本描述,采用分类相似度计算,由于反馈次数多,导致并未显著降低整体时间成本。
本文考虑到以上工作的不足,提出了一种电商大数据同一性标定新模型。该模型由文本分词、重要性排序和相似度计算等3个子模型串联组成,充分结合了级联结构和深度循环神经网络的优势。与传统的同一性标定相比,本文模型在重要性排序和相似度计算子模型中采用LSTM[11]作为分类器,不存在单独的特征提取过程。另外,在模型中引入了分词优化、GloVe词向量[12]、二分查找和词序列语义校验等技术,确保了面对易混淆商品时能标定出同一商品,提升了标定速度、准确率和泛化能力。
本文的研究意义体现于:(1)尝试构建3级级联网络模型,利用长短时记忆网络特性,提高同一性标定的准确率。(2)采用GloVe词向量技术进行每一级循环网络模型的优化训练,提高训练样本利用率。(3)引入二分查找和词序列语义校验等技术,提高模型的标定速度和泛化能力。
2 同一性标定模型构建
2.1 模型整体架构
本文提出一种基于LSTM的同一性标定模型。该模型分为3个子模型:分词子模型、LSTM重要性排序子模型(LSTM importance sub-model)和LSTM相似度计算子模型(LSTM similarity sub-model),整体结构如图1所示。

Figure 1 Structure of the identity calibration model based on LSTM
供货商更新的商品B能否上架到政府采购平台,取决于平台下历史库中是否存在商品A,其具体参数与B一模一样,若不相同则B无法上架。商品B的文本描述被分词子模型处理成词序列,通过LSTM重要性排序子模型筛选出B的重要词序列。同时,商品A也完成了上述操作步骤,商品A和B的重要词序列输入到LSTM相似度计算子模型,输出A和B的相似程度,根据阈值来标定二者是否为同一商品,进而决定B能否上架。
2.2 分词子模型构建
分词处理是本文同一性标定模型研究的基础,它会直接影响文本向量化,影响模型训练进而决定模型输出结果。现语料库规格庞大,人工进行分词处理效率低下。为统一规范分词,在语言技术平台LTP(Language Technology Platform)[13]基础上构建分词子模型来完成此预处理过程。
主要思路如下:(1)将商品的文本描述分割成关键词;(2)根据实际需求构建一个强制词典;(3)从词典生成正则表达式,基于模糊匹配算法快速查找切分后的词;(4)如果不同词以组合形式存在于强制词典中,则将词进行合并,否则跳过处理下一个商品。分词子模型的优势在于能将错误分割的词进行合并,并保证同一文本多个不能拆分的词也能正确合并。
表1仅展示了笔记本电脑、单反相机、复印机这3类商品的标题和LTP以及本文分词模型的分词结果。对“联想(Lenovo)小新Pro13.3英寸全面屏超轻薄笔记本电脑(标压锐龙R5-3550H 16G 512G 2.5K QHD 100%sRGB)银”这条笔记本电脑商品标题而言,“小新Pro”显然要比“小”和“新”这2个单独的词更符合分词要求,而且本文分词子模型将“Pro13.3”和“英寸”这种不太合理的分词转换成“小新Pro”和“13.3英寸”。对单反相机和复印机这2类商品标题来说,将“单反”和“相机”组合成的“单反相机”和“多”与“功能”合并成的“多功能”等关键词更有表征能力。综上,本文分词子模型使各类商品的分词结果更能准确表征商品信息,为后续LTSM重要性排序和相似度计算子模型研究提供良好的实验数据。
2.3 LSTM重要性排序子模型构建
2.3.1 LSTM简介
对商品文本描述而言,词或短语顺序不同,整个语义也会随之改变。循环神经网络RNN(Recurrent Neural Network)[14]能够很好地处理此类序列信息。但是,RNN只有短期记忆,没有长期记忆。深度学习专家Schmidhuber提出了LSTM,专门用于解决RNN的长期依赖问题。因而本文基于LSTM来构建重要性排序和相似度计算子模型。
2.3.2 GloVe词向量化技术
考虑到无法直接输入原始文本到神经网络,此子模型采用词表征全局向量GloVe实现文本向量化,实现步骤如下所示:
(1)建立共现矩阵X,矩阵中的Xij表示当前商品词序列中的第i个词与上下文词序列中的第j个词在特定大小的上下文窗口内共同出现的次数。
(2)词向量和共现矩阵之间的近似关系可以用式(1)表示:
(1)
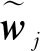
(3)为使词向量wi,wj与共现次数Xij具有良好的一致性,即词向量蕴含共现次数信息,针对上述的词向量表达式构造损失函数,目的在于迭代训练使二者尽可能接近:
(2)
其中,V表示词序列中词的个数。
此损失函数只是在最基本的均方损失的基础上增加了一个权重函数f(Xij),采用了如式(3)所示的权重分段函数:
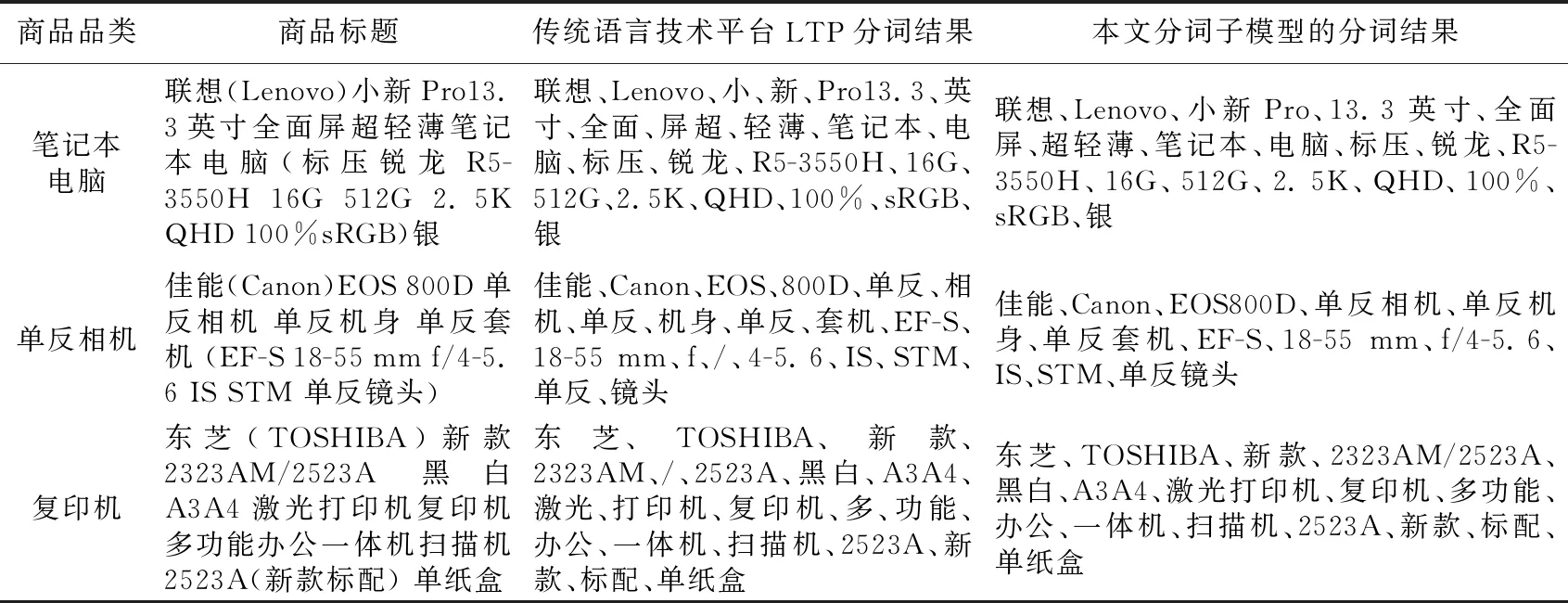
Table 1 Comparison of word segmentation sub-model results
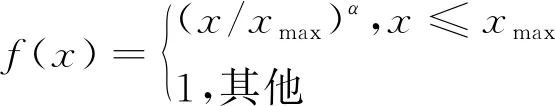
(3)
其中,α=0.75,xmax=100。当词序列中词i与词j的共现次数Xij小于最大共现次数xmax时,f(Xij)递增;当Xij大于xmax时,f(Xij)=1,不再变化,即保证词序列中同时出现次数多的单词的权重大于很少同时出现的单词,且权重也不会过大。
2.3.3 在子模型中引入GloVe词向量
将商品的文本描述被分词子模型处理成的词序列作为LSTM重要性排序子模型的输入。图2是LSTM重要性排序子模型的结构,商品词序列中的wordi均被转换成GloVe词向量,以LSTM构建的分类器预测该词是词序列中重要词的概率。
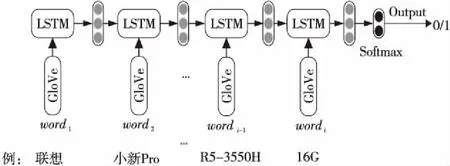
Figure 2 Structure of LSTM importance ranking sub-model
针对标题如“联想(Lenovo)小新Pro13.3英寸全面屏超轻薄笔记本电脑(标压锐龙R5-3550H 16G 512G 2.5K QHD 100%sRGB)银”的商品,利用LSTM重要性排序子模型筛选出其重要词序列的步骤如下所示:首先将分词子模型处理得到的商品词序列中的词全转换成GloVe词向量;然后获得词序列中每一个词的重要程度,例如针对“16G”一词,依次输入从词序列开始到当前所有词的向量,将其共同建模到同一数组,此数组充分包含该词及其全部上文语义信息,能有效提高重要词预测的准确率,并由Softmax层输出“16G”为重要词的概率,其它词的处理方式类似;接下来通过概率对所有词重要程度排序,根据事先设定的阈值,便可筛选出此商品中的重要性大的词;最后将该商品的重要词序列输出到LSTM相似度计算子模型。
2.4 LSTM相似度计算子模型构建
2.4.1 LSTM相似度计算子模型概述
由LSTM重要性排序子模型得到了商品的重要词序列后,只需对不同商品重要词序列进行相似度计算,便可在电商大数据中标定出同一种商品。LSTM相似度计算子模型的结构如图3所示。
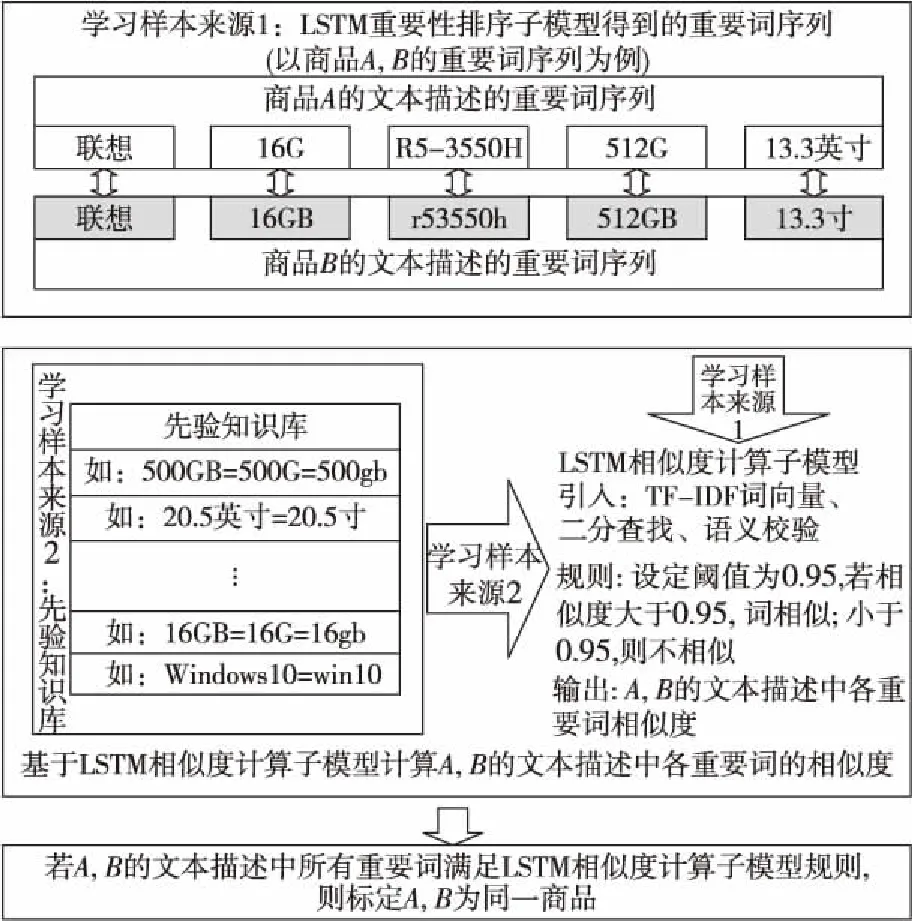
Figure 3 Structure of LSTM similarity calculation sub-model
LSTM相似度计算子模型的学习样本,一部分来源于LSTM重要性排序子模型的输出,另一部分来源已有的先验知识。商品A、B的文本描述重要词序列相似度计算步骤如下所示:
步骤1商品A、B的文本描述中重要词数分别为na,nb,则最短序列长度n=min(na,nb);
步骤2对商品A、B的文本描述中重要词依次进行相似度计算,将重要词对输入到LSTM分类器,分类器输出该词对相似的概率,进行计算的次数为M=na×nb;
步骤3若M次计算中有m1次LSTM分类器输出概率大于或者等于事先设定的阈值,则商品A、B的文本描述中有m1对重要词相似。若m1≥n,则可标定商品A、B为同一种商品。
经实验发现,采用词袋模型BOW(Bag Of Words)向量化重要词序列,效果最为理想。由于BOW未考虑每个词在序列中的重要程度,因此引入词频-逆文档频率TF-IDF(Term Frequency-Inverse Document Frequency)计算词序列中每个词的权重大小。词序列总数为N,词序列d中的词t的TF-IDF权重估算公式如式(4)所示:
(4)
其中,tf(t,d)为词t在词序列d中的频次,而df(d,t)为包含词t的词序列d的数量。
2.4.2 在子模型中引入词序列语义校验
虽然TF-IDF能弥补BOW未考虑词序列中各词的重要程度的不足,但对形如“ABBC”和“BBAC”这种二元词组,其TF-IDF词向量是相同的,导致LSTM相似度计算子模型的计算结果也相同,这是因为TF-IDF并未考虑词序列中各词的语义信息。
针对TF-IDF上述不足,本文引入了词序列语义校验。在向量化的词序列后面加上一位语义校验位,其作用在于判断需要进行相似度计算的二元词组的语义是否一致。语义校验结果如表2所示,形如“ABBC”和“BBAC”这种二元词组虽然词向量相同,其语义检验位却为“False”。若作为学习样本,此二元词组被判定为负样本。形如“ABBC”和“ABC”这种二元词组词向量不相同,语义校验位为“True”,作为学习样本,根据先验知识和电商大数据同一性标定任务需求,此二元词组被判定为正样本。

Table 2 Results of word sequence semantic verification
2.4.3 在子模型中引入二分法查找
政府采购平台的历史库和供货商更新库中商品数量巨大,同一性标定计算量大。为提升在海量商品数据中标定出同一种商品的速度,本文在LSTM相似度计算子模型中引入了二分法查找。
假设供货商更新库中的商品均能在政采平台的历史库中标定出来,利用二分法查找,则历史库中某一商品平均成功的查找次数为库中所有商品查找次数和与查找概率的乘积,如式(5)所示:
(5)
其中,n表示商品总数,h表示当前商品的查找次数。Pi表示商品i的查找概率,Ci表示商品i的查找次数。
当查找次数最大时,即h=log2n+1,二分查找的时间复杂度为T(n)=O(lgn)。若不采用二分法查找,其计算时间复杂度为T(n)=O(n),二者相比可见二分查找法大幅降低了LSTM相似度计算子模型的计算时间复杂度。特别需要指出的是,此二分法查找法是针对政府采购平台的历史库和供货商更新库中所有的商品,因此当商品总数量n巨大时,提升的查找速度是非常可观的。
3 学习样本制备及模型训练
3.1 电商大数据采集与整理
电商网站具有不定时更新的特点,同时不同网站之间也存在差异,基于Python编写的商品信息获取程序,能避免网站差异性,定时获取商品信息,从而保证商品信息实时性。本文一共获取了笔记本电脑、单反相机和复印机这3种品类共8.5万条商品标题和商品详细参数,因而拥有了一定规模的电商领域语料库。本文对商品的文本描述进行了去除无用标点符号等文本预处理,以方便在此基础上进行模型的研究和实验。
3.2 学习样本制备
3.2.1 LSTM重要性排序子模型样本制备
商品原始数据主要来源于商品信息获取程序。将分词子模型处理后得到的商品词序列,作为LSTM重要性排序子模型学习样本,根据先验知识和对商品的深入了解,将最能表征此商品的词标注为重要;大部分商品均包含的或不具表征能力的词等标注为不重要。
2.2节提及的3类商品标题分词处理得到的词序列的标注结果如表3所示,其中样本标签为1表示重要,样本标签为0表示不重要。“笔记本电脑”是笔记本电脑类中的通用词,因而不重要;“EOS 800D”是单反相机类中一特定商品的型号,故重要;而“新款标配”不具有表征复印机的能力,所以也不重要。
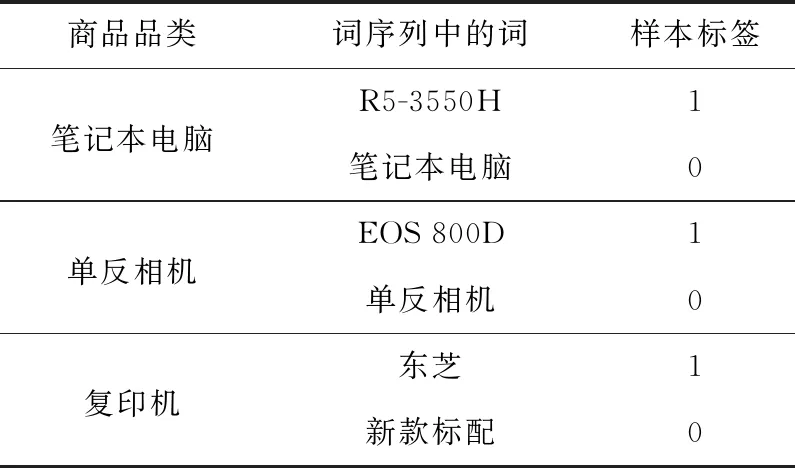
Table 3 Product segmentation
3.2.2 LSTM相似度计算子模型样本制备
LSTM相似度计算子模型的学习样本一部分来源于先验知识库,另外一部分是LSTM重要性排序子模型输出组成的重要词二元组。构建此子模型的学习样本库的方式如表4所示,其中Label为1代表相似,Label为0代表不相似。
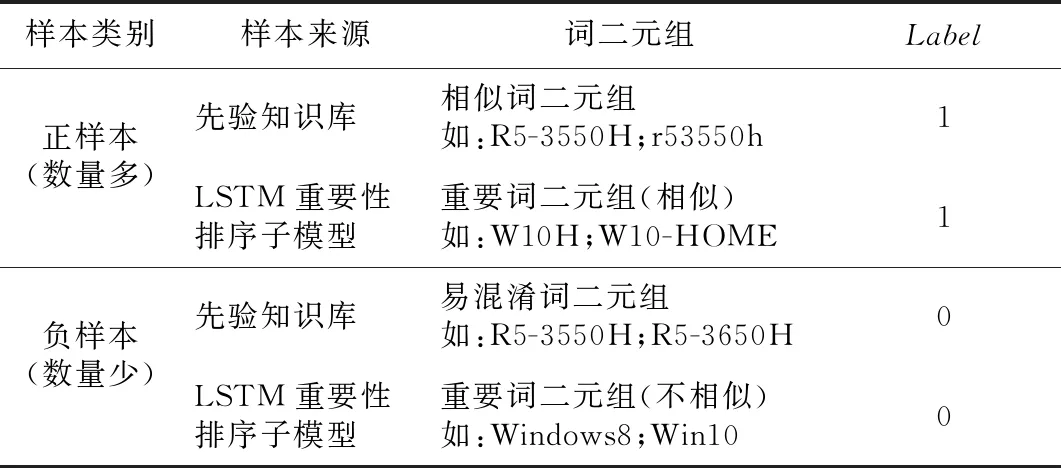
Table 4 Building LSTM similarity calculation sub-model learning sample library
正样本包括先验知识库中的相似词二元组和LSTM重要性排序子模型输出的相似重要词二元组,多是一些型号、操作系统和品牌等重要词的简写或者别称等,这些二元词组的格式全然不相同且涉及种数繁多,因此本文采用监督学习来代替费时费力的人工判定方式。负样本包括先验知识库中的易混淆词二元组和LSTM重要性排序子模型输出的不相似重要词二元组,主要是同一系列下编号很相似的型号,如“R5-3550H”和“R5-3650H”;写法大致统一却不相同的操作系统,如“Windows8”和“Win10”等传统方法难以区分开的二元组。
3.3 同一性标定模型训练策略
考虑到基于LSTM的同一性标定模型包含了2个用法不同的神经网络模型,样本库的量大而且还需要补充新样本,完全靠本机训练测试,过于耗时。本文采用如图4所示的训练测试策略。小型学习样本库采用本地训练测试,大型样本库采用华为云训练和本机测试。
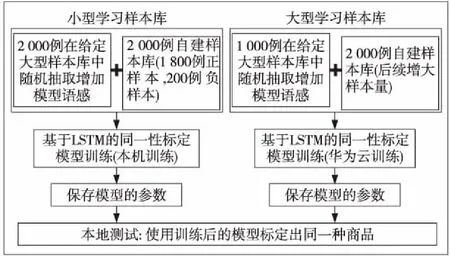
Figure 4 Two training methods of identity calibration model based on LSTM
3.3.1 LSTM重要性排序子模型训练
LSTM重要性排序子模型采用监督学习训练方式,所用的正负样本的比例为3∶1,采用3万条正样本和1万条负样本进行优化训练LSTM。所有的词序列样本均被表征成GloVe词向量。此外,设定的目标函数为二元交叉熵BCE(Binary Cross Entropy)函数,表达式如式(6)所示:
lg(1-pk)]
(6)
其中,yk和pk分别表示第k个样本对应的标签和被预测成正样本的概率;m表示每次训练迭代样例个数;激活函数全部采用ReLU激活函数[15],对应的表达式如式(7)所示:
f(z)=max(0,z)
(7)
ReLU可由f(z)=lg(1+ez)逼近,ReLU激活函数用于LSTM处理自然语言问题取得了良好效果。另外学习率从0.01开始下降,每训练100次降为原来的1/10。由于训练数据数量较大,训练的迭代次数设为100次。最后训练验证集的准确率(Accuracy)曲线和损失(Loss)曲线如图5所示。在LSTM重要性排序子模型训练次数达到20次时,重要性排序准确率逐步上升,准确率在0.991~0.993波动;损失曲线在20次左右波动范围缩小,虽未饱和但也在可接受范围之内。
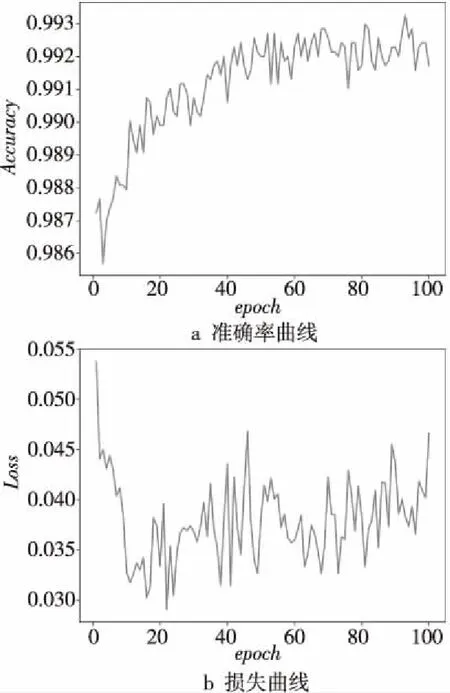
Figure 5 Training results curve of LSTM importance ranking sub-model
3.3.2 LSTM相似度计算子模型训练
LSTM相似度计算子模型的训练同样采用监督学习方式,并且目标函数和激活函数均与重要性排序子模型一样。此模型的输入张量维度高于前者,因此训练的各参变量有所改变,此模型还利用了带有语义校验位的IF-IDF词向量来表征样本词序列。用正负样本比例为3∶1的学习样本训练LSTM相似度计算子模型,训练的迭代次数(epoch)为100次。最后训练验证集的准确率Accuracy曲线和损失Loss曲线如图6所示。
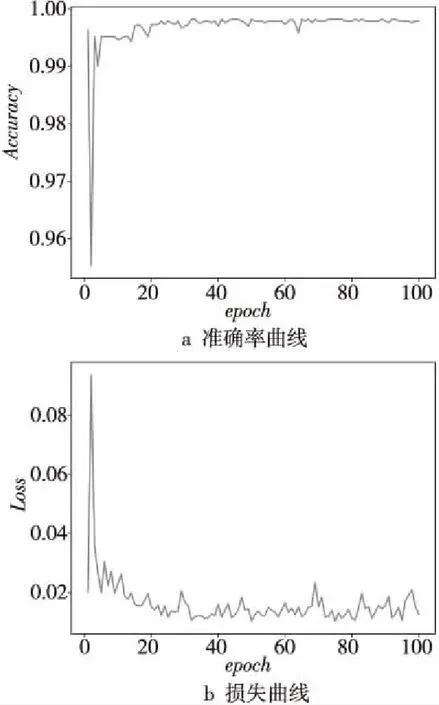
Figure 6 Training results curve of LSTM similarity calculation sub-model
由图6可知:训练次数在达到100次时,LSTM相似度计算子模型准确率曲线趋近饱和,此刻准确率达到最大值;损失曲线在100次左右就基本只在0.01~0.02小幅度波动。
4 实验结果及分析
为了验证本文基于LSTM同一性标定模型在电商大数据上的性能,特设置2组实验进行测试分析。第1组为2个子模型与传统模型的对比实验;第2组实验在测试集上验证本文模型的性能。实验在GPU 1.2 GHz、显存12 GB的华为云服务器上进行训练,在CPU 2.4 GHz、内存8 GB的Windows 10专业版64位操作系统的个人计算机上进行测试,深度学习框架为Keras+TensorFlow,软件编程环境为Python 3.6.6。
4.1 实验1:子模型与传统模型对比实验
本实验的目的是测试和展现本文的同一性标定模型与传统模型相比在标定准确率、速度和泛化能力方面的提升。测试数据来自不同电商网站上获取的商品标题与详细参数。实验分别给出LSTM重要性排序子模型和传统模型的准确率对比结果,LSTM相似度计算子模型与传统模型相比,其准确率、标定速度和LSTM相似度计算子模型泛化能力的提升等。
在LSTM重要性排序子模型与传统模型对比实验中,将此子模型与RNN模型(RNN model)和未采用GloVe词向量的LSTM基本模型(简称为No GloVe model)的准确率进行比较,结果如图7a所示。类似地,在LSTM相似度计算子模型与传统模型对比实验中,与单LSTM相似度计算模型(single LSTM model)和未带有语义校验位LSTM相似度计算子模型(简称为no Parity model)的准确率对如图7b所示。

Figure 7 Accuracy comparison of the two sub-models and the traditional models
LSTM相似度计算子模型与传统未带有语义校验位的子模型泛化能力对比如表5所示,LSTM相似度计算子模型与未引入二分法查找子模型的标定速度对比如表6所示。
由图7a知,在处理不同网站上书写格式不统一的商品词序列时,本文LSTM重要性排序子模型的准确率远高于RNN模型和未采用GloVe词向量的基础LSTM模型的准确率。由图7b可知,本文LSTM相似度计算子模型的准确率远高于单LSTM相似度计算模型的准确率。未加入语义校验位的子模型准确率虽然略低于LSTM相似度计

Table 5 Comparison of generalization ability between LSTM similarity sub-model and traditional model
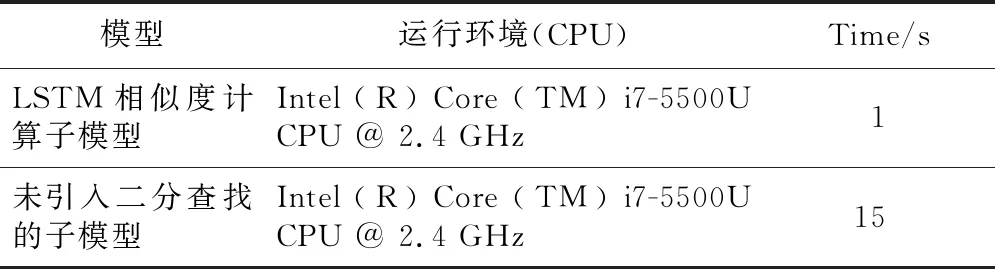
Table 6 Comparison of model calibration speed before and after introducing binary search
算子模型的准确率,但是由表5可知,未加入语义校验位的子模型会将形如“R5-3550H”与“R3-5550H”的词二元组误判为相似,这是因为其并未考虑语义,识别不出二者实际上表示不同的型号。而本文的LSTM相似度计算子模型考虑了语义,不会出现上述误判。
由表6可见,未引入二分法查找的子模型,计算出一对商品词序列中所有词组成的词二元组相似度需要15 s,而引入二分法查找之后只需要1 s。LSTM相似度计算子模型在计算速度上有明显的提升,因而本文提出的基于LSTM同一性标定模型在电商大数据中标定出同一种商品的速度也会随之提高。
4.2 实验2:模型性能测试
为进一步验证本文模型性能,分别测试了LSTM重要性排序子模型和LSTM相似度计算子模型在测试集上的表现,测试结果如图8所示。其中LSTM重要性排序子模型测试集由8 918种商品文本描述经分词处理成的词序列组成,重要性子模型能够正确筛选8 751种商品文本描述中的重要词,误判的只有167种,预测结果与人工标注相同的有4 029对,准确率达到了97%。

Figure 8 Performance of the proposed models on test sets
现对政府采购平台的历史库中抽出的77条笔记本电脑数据,和供货商更新库取出的90条笔记本电脑数据组成的6 930例艰难样本进行同一性标定。所谓艰难样本是指同一品牌系列下型号只有微小差异而且配置参数非常接近的商品,或者是具体参数相同文本描述完全不一致的商品等,对艰难样本的同一性标定难度比一般样本要大。表7展示是以笔记本电脑商品为例,6 930例艰难样本中的某一例正样本和负样本,其中标签为1代表同一种商品,标签为0代表非同一种商品。
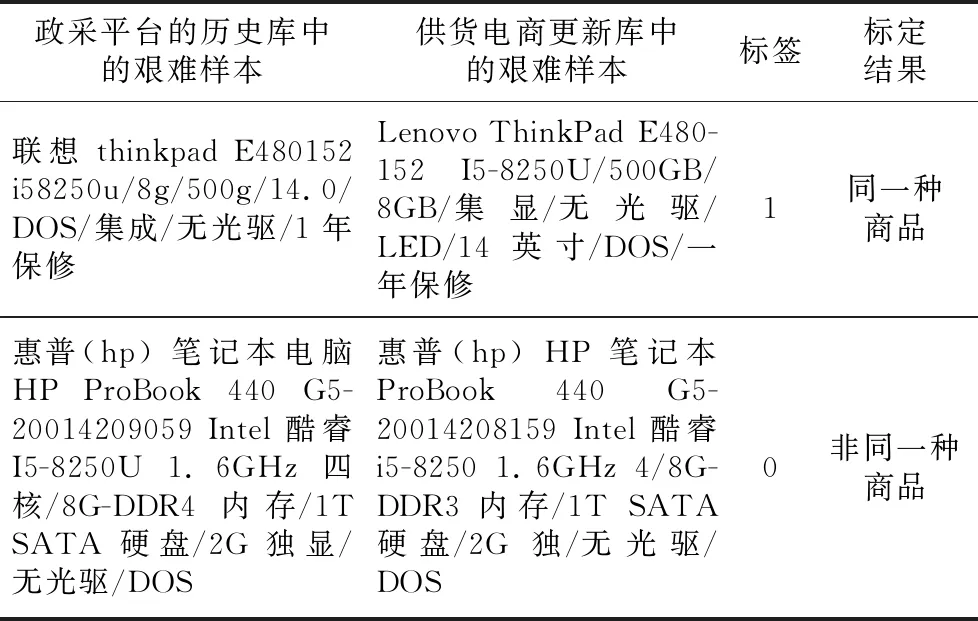
Table 7 Examples of hard samples for laptops
表7中正样本其实是同一种商品,但这对商品文本描述不相同,它们字符串排列顺序不一致,字符串长度不相同,字母大小写不统一,同一参数的格式不统一(包括缩写、简写、人为可接受的误写、中文或英文表达但语义相同、由先验知识才可判定)。如“联想”与“Lenovo”和“1年保修”与“一年保修”语义一致,“14.0”与“14英寸”代表同一屏幕尺寸,“集成”与“集显”代表集成显卡,“I5-8250U”与“i58250u”代表同一CPU型号。负样本不是同一种商品,但这对商品文本描述很相近,主机型号“ 440 G5-20014209059”与“ 440 G5-20014208159”只有细微差异,内存容量虽然都是8 GB但类型不相同,分别为“DDR4”和“DDR3”,“I5-8250U”和“I5-8250”虽然只有微小区别,但根据先验知识二者的CPU型号并不相同。采用人为标定这些易混淆的艰难样本也具有一定难度,但本文模型能正确标定。从图8可以看出,本文模型(Identity calibration model)标定正确的艰难商品共有6 798例。
5 结束语
针对政府采购平台品类繁杂且书写格式无统一规范的电商大数据,本文提出了一种基于长短时记忆网络(LSTM)的同一性标定新模型。该模型将深度学习循环神经网络与级联思想相结合,逐级进行分词处理、重要性排序和相似度计算来标定出同一种商品。通过理论分析和实验得到如下结论:(1)本模型采用二分法查找后,标定速度有一定的提升;(2)词序列转换成GloVe词向量后,样本利用率提高;(3)加入语义校验后,标定泛化能力增强;(4)本模型对于政府采购平台上笔记本电脑这一类商品的同一性标定具有较高的准确率;(5)本模型对于笔记本电脑这一类商品的艰难样本标定准确率达98%。
下一步将会把此模型运用于复印机和单反相机等品类商品的同一性标定,以增强模型处理不同商品的通用性。另一方面拟利用哈希查找、双向编码器表征量BERT(Bidirectional Encoder Representations from Transformers)[16]文本向量化等,进一步提高模型的准确率、标定速度、样本利用率和泛化能力等。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
汽车维修与保养(2020年11期)2020-06-09 05:42:16
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
智富时代(2019年6期)2019-07-24 10:33:16
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
儿童绘本(2018年5期)2018-04-12 16:45:32
中国惯性技术学报(2017年1期)2017-06-09 08:15:14
高中生·天天向上(2016年9期)2016-11-22 09:10:34
光学精密工程(2016年3期)2016-11-07 09:03:34
西安建筑科技大学学报(自然科学版)(2014年6期)2014-11-10 02:35:38
