
基于3D可扩展PE阵列CNN加速器的设计*
2021-04-06 10:48:18苏梓培陈弟虎
计算机工程与科学 2021年3期
苏梓培,杨 鑫,陈弟虎,粟 涛
(中山大学电子与信息工程学院,广东 广州 510275)
1 引言
随着科技的日益发展,人们开始着重于对人工智能的研究。在计算机视觉领域,卷积神经网络CNN运用十分广泛,且在各种各样的应用中遍地开花。CNN模型的数据量不断增大,精确度不断提高,同时带来的是模型的复杂化,计算量的剧增。而在一些特别的移动端的应用需求(如无人驾驶)中,对于数据量巨大的CNN网络,需要十分快速的前馈计算来满足需求,因此研究CNN加速器显得十分必要。
现在有许多研究CNN加速器的工作,而随着CNN的发展,层数越来越多,数据量越来越大,卷积操作越来越复杂,使得神经网络的计算无法简单地映射到直接对应的硬件上,要考虑到各种硬件部件的复用。运算的基本单位为一个 PE(Processing Element),而不同的 PE 也对应着不同的架构:有的PE是一个乘加器,如文献[1,2],通过 PE 间数据传输进行数据复用;有的 PE 是多个乘加器与加法树的组合,如文献[3,4];也有的 PE 除了乘加器,还包括数据传输与 FIFO,如文献[5,6]。
但是,不同的应用场景对加速器的具体需求不一样。应用的场景不同,硬件资源约束不同,使用网络也不同,因此需要能够快速寻找并快速设计性能较优的CNN加速器。且现有移动端所使用的网络层数偏中。而MobileNet中提出的深度可分离卷积的运用也越来越多,因此需要适配DW(Depthwise)/PW(Pointwise)/CONV(Convolution)的加速器架构。文献[7,8]设计了专门用于深度可分离卷积的神经网络,但这些神经网络不能兼容经典的卷积。
针对上述问题,本文提出了一个基于3D可扩展PE阵列的CNN加速器,能够很好地根据不同的网络和硬件资源进行适配,并根据约束找到最优的3D-PE每一维的PE数量。该加速器支持CONV、DW CONV(Depthwise Convolution)和PW CONV(Pointwise Convolution)功能,支持目前常见的移动端网络,如yolo-tiny、mobile-net等。最后使用该加速器构建了一个实时的目标检测系统。
2 3D可扩展PE阵列介绍
在CNN神经网络中卷积运算的运算量巨大,因此需要进行并行运算。现有的嵌入式移动端的CNN加速主要采用2D的PE阵列进行并行加速,即没有并行运算通道的运算,只对其中一个通道的宽与高的像素运算进行并行化。
2D的PE阵列对大的特征图能够很好地进行并行加速,并且能得到很好的性能。但是,2D的加速存在上限,如果网络的特征图的尺寸(宽/高)比较小,但是通道数比较多,在2D上会存在PE的浪费,而不能很好地利用这些PE对其他通道进行并行运算。
本文提出3D可扩展PE阵列,如图1所示,PE 阵列分为3个维度,分别是PE的宽X、PE的高Y和PE的通道数C,分别对应特征图的宽、高和输入通道数。可扩展的意思是可以根据现场应用的约束,定义其3个维度上的PE数量参数。
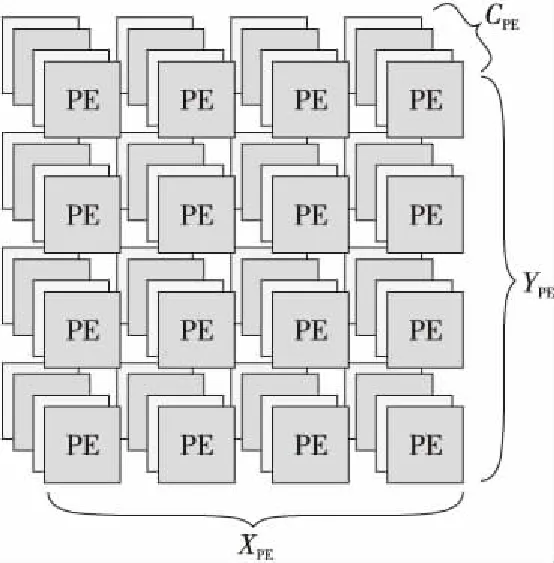
Figure 1 3D-PE array
本文设计的3D-PE阵列中,每个PE对应一个通道的一个像素点的输出,在3×3 CONV与3×3 DW CONV中,每个PE负责执行9次乘加运算;在1×1 PW CONV 与全连接层中,每个PE负责执行1次乘加运算。
在1×1 PW CONV模式与全连接层的模式下,PE阵列的运算方式如图2所示。例子中使用了2×2×2的PE阵列,灰色部分代表已经运算完成的特征图部分,3D-PE先向右滑动窗口,当过了右边界之后,就切换到下一行进行运算。
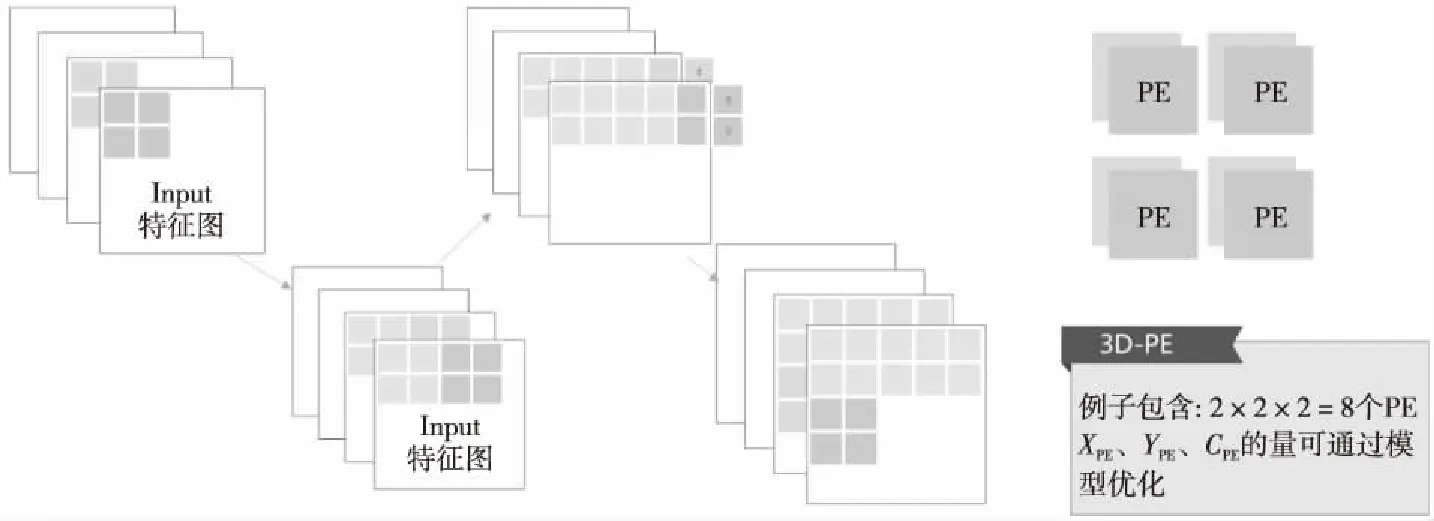
Figure 2 Sample diagram of 3D-PE array running 1×1 convolution
在CONV(3×3)模式与DW CONV模式下,3D-PE阵列的运作方式如图3所示,每个PE表示一个输出神经元,3×3卷积过程中,需要9个周期输入9个数据,9个周期之后则同时得到个数与PE数量相同的输出值。图3中灰色部分为输入缓存,只加载新数值,用过的2列数值可以复用。

Figure 3 Sample diagram of 3D-PE array running 3×3 convolution
PE的数量根据应用场景的不同而有不同的约束,包括芯片面积约束和芯片功耗约束。很显然,PE的数量越多,必定得到的并行度越高,得到的性能也越高,但是与此同时也会带来面积功耗的增加,因此PE数量的选择是根据应用场景进行折衷考虑得到的。因此,PE利用率则成为了其中一个关键的因素。越高的PE利用率,则可以在同样的PE数量下得到更优的性能,在同样的性能下使用更少的硬件。本文提出3D可扩展PE阵列,意在在约束PE数量的情况下,比起2D的阵列,能够提高利用率,获得更好的性能;同时能够应对不同应用场景的约束,得到不同约束下的3个最优参数。
2.1 模型建立
在加速器的运算过程中,PE数量有限,并行程度有限。本文加速器采用的是3D的PE阵列,在3个维度进行并行。为了评判其具体性能,建立了相关数学模型,针对不同的运算层,有不同的计算量与并行方式。
不同的运算层,每次使用PE阵列需要的周期数不一样,3×3卷积需要9个周期进行乘加运算,而1×1的PW CONV和全连接层则只需要1个周期便可得到结果,而深度可分离卷积输入通道与输出通道一一对应。把需要使用PE阵列的次数与每次使用所需要的周期数相乘,得到每一层需要的周期数。把整个网络需要的周期数累加起来,就可以得到该网络运行需要的周期数,其计算方式如式(1)~式(5)所示:
(1)
(2)
(3)
(4)
(5)
其中,XPE表示PE阵列的宽,YPE表示PE阵列的高,CPE表示PE阵列的通道数,w表示特征图的宽,h表示特征图的高,Cin表示特征图的通道数,Cyclei表示第i层运算的周期数。
通过以上运算得到网络运行所需要的周期数,就可以从侧面了解网络运行的性能,因此就可以据此评判参数的优劣。当CPE为1时,就等同于使用的是2D-PE阵列。
2.2 性能分析
本节首先分析PE数量不断增加时2D-PE阵列的CNN加速器的性能提高情况。当PE数量增加时,选取2D的最优参数XPE与YPE进行计算,采用mobile-net-v1网络,分别对上限为256与1 024个PE数量进行测量,计算结果如图4所示。GOPS与PE数量的关系如图4a所示。随着PE数量的增加,的确可以带来性能的提高,但是存在边际效益递减的情况:当PE数量增加到一定值后,继续增加PE带来的性能提升幅度下降。图4b表示的是GOPS/PE与PE数量的关系。从图4b中可以看出,前面增加PE令GOPS/PE呈现波动性的特征,表示增加PE的数量仍能保持提高性能的优势,但是后面继续增加PE的数量只会让GOPS/PE逐渐下降。图4中2D的PE阵列加速,在PE数量增加到一定程度后,将会出现更多的PE浪费。就mobile-net-v1而言,PE数量到达60左右后就出现了明显的增长停滞。

Figure 4 Statistical graph of the marginal effect of total PE number on 2D-PE array
因此,本文设计引入了3D-PE阵列,使PE阵列的并行度能够更加灵活,且不会像2D-PE阵列一样快速到达瓶颈。与上述2D-PE进行同样的操作,对mobile-net-v1进行测量,计算结果如图5所示。从图5a可以看出,增加PE数量,GOPS的提升几乎是线性的,即使PE数量到了1 024个依然可以线性增长,这说明3D-PE阵列可以跨越2D-PE阵列的瓶颈,进行卷积操作的加速运算时性能能够更优。图5b中可以看出,GOPS/PE在震荡,原因是存在一些更优的3D参数组合,存在一定的震荡范围。

Figure 5 Statistical graph of the marginal effect of total PE number on 3D-PE array
然而即使是PE数量相同,3个维度不同的参数也会有很明显的性能差别。当PE数量相同,XPE、YPE、CPE3个并行参数不同时,性能差距也会很大,如图6所示高谷与低谷相差甚远。因此,通过模型可以计算出在同样的PE数量条件下,可以得到更优性能的3D的并行参数。

Figure 6 Performance difference caused by three different parameters of 3D-PE
如上所述,使用3D-PE阵列可以更好地利用PE,可以更加灵活地配置PE阵列在3个维度上的并行度。因此,相比2D阵列,本文设计引入的3D-PE阵列存在其优势。
3 CNN加速器硬件实现
3.1 整体结构
本文CNN加速器的整体架构如图7所示。其核心思路是,整个加速器由一个中央控制器Controller进行控制,通过中央控制器控制每个子模块的工作模式和状态。加速器设置有2个数据Buffer,在一层运算中分别作为Input Buffer和Output Buffer,而他们的功能是复用的,即在一层运算中,若数据可以完全被存放进Buffer中,那么进入下一层运算前,就不需要重新把数据输出到内存,也不再需要从内存中导入数据,这样就可以减少CNN加速器访存时间。

Figure 7 Schematic diagram of the overall architecture of the CNN accelerator
同时设置了一个权值Buffer,因为权值文件是比较大的,也不能完全存放在芯片上,因此会在每层运算期间对内存中的权值进行访问,而暂时缓存的Buffer就是权值Buffer。由于本设置采用了权值全复用的策略,权值被送入计算单元阵列之后就可以被完全复用,因此可以在权值Buffer中释放掉其空间,设计为FIFO的形式。采用权值Buffer可以把访问权值的时间隐藏在计算时间当中。
由于计算模块中采用了3D-PE阵列的形式,数据是并行进入阵列的,而且不同的卷积操作中,数据进入时序与方式会有些许差别,因此在Buffer和计算模块中间插入了负责协调和重排序以及缓存数据的模块,作为Buffer和计算模块之间的一个缓冲。

Figure 8 CNN accelerator pipeline design
在该系统框架中,若一层的数据可以被一个Buffer缓存起来,那么在2层之间就完全不需要进行数据的load和store操作,只需要从内存中载入该层所需的权值,这样就能减少访存时间,只需要访存必要的输入特征图和输出的最终结果,大大减少了整个CNN的运行时间。
接下来具体介绍加速器的数据通路和流水线设计。本文的CNN加速器采用了类似中央处理器的组织架构,把控制器类比为指令发射模块,将控制信号与数据一起在流水线上进行流水,可以保证每个模块的控制信号的正确运行。流水线设置为从数据Input Buffer中取数值,到最后运算结束存回Output Buffer这一数据通路。整体的流水线设计如图8所示。
整条流水线可以分为以下几个步骤:取数据、重排序、计算、重排序和存数据。
(1)取数据:流水线执行的最开端,是Controller发出“指令”,向Data Buffer申请访问,根据当前运行层,BufferA、BufferB中的一个为Input Buffer,另一个为Output Buffer。从Input Buffer的每个bank中取出一个数据,发送到重排序模块。
(2)重排序:此时Controller发出的指令也沿着流水线到达了重排序(Gather)模块,该模块对送入计算阵列之前的数据进行重排序。除了从Buffer读到的数据以外,还有数据复用的不需要重新从Buffer访问的数据。因此,需要对从Buffer读取的数据和在同一模块中复用的之前的数据进行统一规整,得到重排序后的数据。之后再把排序好的数据发送到计算阵列模块进行后续运算。
(3)计算:计算所需要的数据已经经过了Gather模块排序,只需要对数据进行运算即可。而计算阵列在计算过程中,不同的卷积运算层会有不同的计算模式,根据不同的计算模式,对数据通路进行控制,这个会在后续章节进行详细描述。计算模块包括卷积、全连接、池化和激活等操作。某些运算模式中(比如3×3 CONV),计算的过程还需要加部分和,这个部分和产生于之前计算模块的输出,部分和存储在Output Buffer,当计算模块需要部分和时会读取Output Buffer中的数据。
(4)重排序与存储数据:最后,从计算模块中计算出来的数值,看需要是否进行池化和激活操作,之后再经过一次重排序,得到与Output Buffer的多个bank相对应的数据排序,然后将重排序后的数据进行存储,作为部分和或者该层的输出。
3.2 PE结构
首先描述PE的基本结构,如图9所示。PE阵列存在3个数据级,分别是Input REG输入寄存器级、MAC PE计算阵列级和Output REG输出寄存器级。
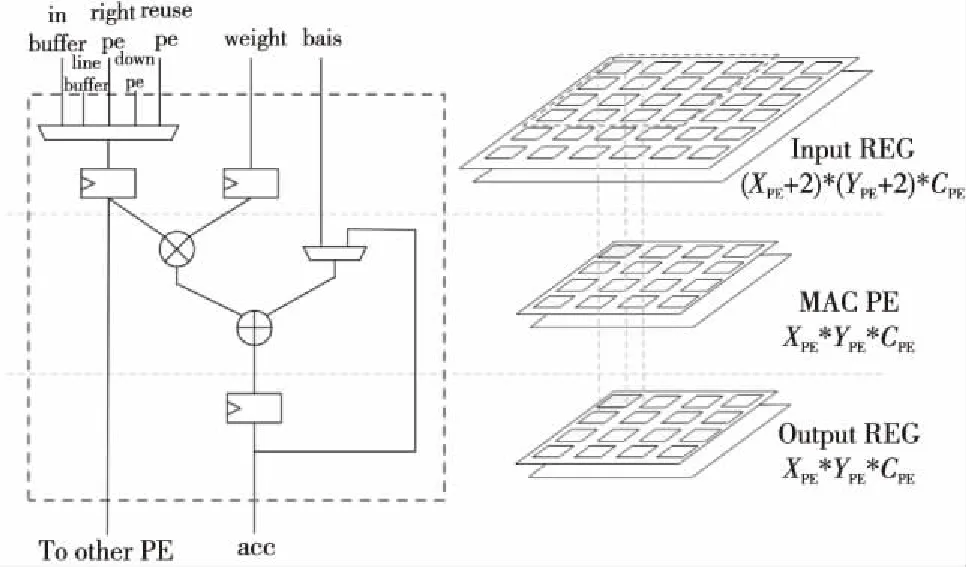
Figure 9 Schematic diagram of PE structure
Input REG输入寄存器级为计算前的数据缓存,存放着即将要计算的数据。Input REG的个数比PE的个数要多,在计算3×3卷积的时候,需要多出2行2列的数据来进行缓存。于是这些数据在Input REG级里进行流动,且进行复用。
考虑数据复用的情况,整个PE阵列之间具有很强的数据复用性,因此在输入数据的寄存器前面,有对数据复用进行选择的多路选择器。正如本文前面所提到的,PE的数据复用分为PE阵列内的复用与PE阵列运算间的复用。PE阵列内的复用,数据来源可以是其右面PE的寄存器,也可以是其左下PE的寄存器。而PE阵列运算间的复用,数据来源可以是line_buffer,上一次运算中没完全利用的最右端缓存的数据。当然,数据来源还可以是无法进行复用时,从Input Buffer中读取的数据。
因此,PE的输入数据来源共有5个,同时PE的输入数据寄存器同时要对其值进行输出,以供其他PE进行数据复用。PE所处在PE阵列的位置不同,其具体的部分结构也不一样,体现为输入的多选器不同。不是所有的PE都需要5个输入来源。每个PE都需要的输入来源为:Input Buffer、右边PE的数据复用、左下面PE的数据复用。最上面2行PE还需要增加line-buffer作为输入来源。最左2列PE需要增加上一次的最右两侧的PE数据作为数据来源。
MAC PE计算阵列级,主体为一个乘加器,在乘法器前面均有寄存器对输入数据与输入权值进行寄存。乘法的输入一个是输入的数据,另一个是输入的权值,加法器的输入分别是乘法器的输出,以及偏置与部分和的2选1。经过乘加器运算后的输出保存到输出寄存器中。
Output REG输出寄存器级,存放经过MAC计算得出的数值。由于全连接层、3×3卷积、1×1卷积都需要把通道间的数值进行累加,且输出只有一个通道,但是,3×3深度可分离卷积同时得到多个输出通道的数据,因此本文加速器设置了多通道输出寄存器。但是,当运算的不是深度可分离卷积时,数值会采用第1个通道的输出寄存器作为缓存。第1个通道的输出寄存器前有一个选择器,选择经过通道间加法树或者第1通道的PE输出。而其他的输出寄存器则对应每个MAC通道的输出,作为深度可分离卷积时的输出寄存。
接下来说明PE阵列运算间的数据复用,如图10所示,PE阵列计算完一个单元后,往后滑窗时也同时有数据的复用,以及一排运算完成后,切换到下一排时,也需要对行进行数据复用。正如图10所示,输入寄存器缓存的最右2列可以复用给下一次的最左2列,同时,最下面2行的数据要保存到line-buffer中。在运算到下一排时,前2行的数据则从line-buffer中读取。这样可以防止同一个数据需要在大的Input Buffer中读取,降低了片上Buffer结构的复杂性,访问Input Buffer的地址也变得连续,而且减少了反复访问Input Buffer的功耗。
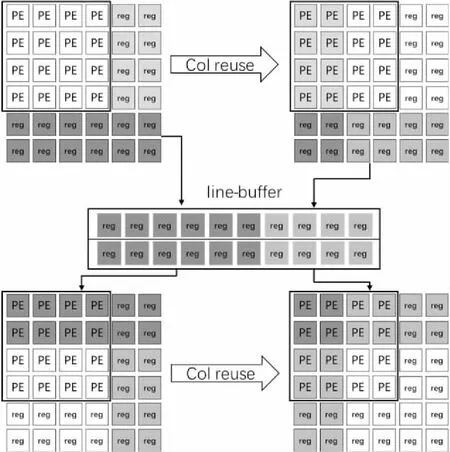
Figure 10 CNN accelerator pipeline design
4 CNN加速器实验与结果分析
对本文加速器进行mobile-net-v1、yolo-v2网络仿真,并测试其运算性能。该加速器的时钟运行频率为100 MHz。性能效率的计算公式如式(6)所示,表示的是真实性能/理论峰值性能。
(6)
其中,GOPSreal表示真实测得的GOPS,PEnumber表示PE的数量,f表示加速器的工作频率。
本文加速器PE与DSP数量对等,一个DSP运算一个乘加运算,因此OP为2。得到实验结果如表1所示。
从表1中得知,这2个网络都有一个共同的特性,当PE数量增加时,GOPS可以得到明显的提升,但是GOPS/PE与性能效率在下降。原因是PE数量增多了,有时候导致的空余PE会更多,也就是PE的利用率会下降,导致该性能参数下降。
而在性能上,不同的网络也出现了不同的小趋势。在PE数量偏少时,mobile-net-v1的性能比yolo-v2-tiny的要好,而PE数量偏多时,则是反过来,yolo-v2-tiny的性能比mobile-net-v1的更好。
而数据有一个不寻常的点,在PE数量为1 024时,yolo-v2-tiny的性能效率不但没有下降,反而上升了。原因是3D-PE并行有3个维度的参数,PE数量是3个维度的总乘积,因此存在某些更优组合,而1 024个PE恰恰为更优的组合。
总体而言,随着PE数量的增加,性能能够得到提高,而PE的利用率会下降,这也是很直观的结果。因此,本文加速器的优势就体现出来了,能够根据现实的需求进行PE数量的选择,从而可以得到更优性能的加速器。
本文CNN加速器与文献[1,7-11]中的研究进行性能对比,具体结果如表2所示。在与相关文献进行比较的过程中,性能效率的计算方法是假设一个DSP一周期贡献2个操作(本文加速器),使用同样的方法对比,可以得到针对DSP资源消耗所产生的性能效率,因此对于相关文献也假设一个DSP产生2个操作,因此该参数可以作为对DSP占用效率评估的重要参数。
在几乎相同的DSP使用情况下,本文加速器的GOPS达到了中等水平,但是性能效率更高,且灵活性更强。灵活性从2个角度进行体现:(1)可以自由选择不同的PE数量,选择3个不同维度上的并行;(2)既可以运行普通的卷积,也可以运行深度可分离卷积用于移动端设备。

Table 1 Performance changes of mobile-net-v1 and yolo-v2-tiny with the growth of PE number
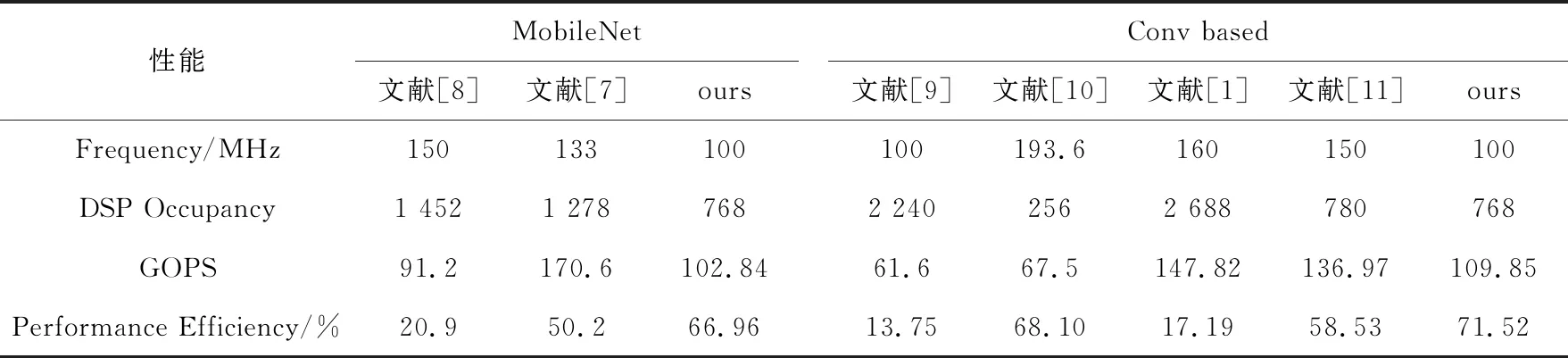
Table 2 Performance comparison between ours and others classical eonvolution accelerator
综上所述,本文CNN加速器在GOPS性能下降的情况下,可以达到更高的性能效率和更大的灵活性。
文献[12]提出了一个CNN加速器的便捷设计工具,可以优化各方面参数,其参数的优化与本文相似,但其硬件模板使用的是高级语言进行高层次综合得到的RTL电路,而本文直接对RTL级硬件电路进行设计。且该文献并没有考虑现有移动端上热门的深度可分离卷积。
最后对该CNN加速器采用XILINX的ZC706 FPGA开发板进行验证。运行yolo-lite实时目标检测的效果如图11所示,卷积神经网络运行性能达到53.65 fps。

Figure 11 Target detection effect
5 结束语
本文分析了现有CNN加速器的一些缺陷,并以此为切入点,提出了3D可扩展PE阵列的概念,本文CNN加速器可以针对不同的网络和不同的硬件资源约束对3D可扩展PE阵列进行配置。CNN加速器在512个PE下运行yolo-v2-tiny达到76.52 GOPS、74.72%的性能效率,在512个PE下运行mobile-net-v1达到78.05 GOPS、76.22%的性能效率。该性能处于CNN加速器的中上水平,其优势体现在具有一定的灵活性和兼容性,最后将其运用在了实际的实时目标检测系统当中。
本文加速器提出了3D可扩展PE阵列,对于不同的硬件约束、不同的现实网络运用需求,都可以很好地适配上。对于移动端嵌入式系统,CNN加速器不能太大,运行的网络也比较轻量级,选择使用本文CNN加速器十分适合。本文CNN加速器提出的3D可扩展PE阵列,对以后能够发展出更多的CNN加速器架构,提供了一定的开拓性和创新性。
猜你喜欢
故事作文·高年级(2024年5期)2024-06-04 23:39:22
高中数理化(2024年8期)2024-04-24 16:58:14
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
少先队活动(2021年6期)2021-07-22 08:44:24
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
计算机应用(2020年5期)2020-06-07 07:06:44
单片机与嵌入式系统应用(2017年7期)2017-07-31 21:57:23
自动化学报(2017年7期)2017-04-18 13:41:02
少年博览·小学低年级(2016年5期)2016-05-14 11:59:03
网络安全与数据管理(2011年24期)2011-08-08 02:31:52
