
基于偏折路由的双环片上网络*
2021-04-06 10:48:18齐星云赖明澈常俊胜董德尊
计算机工程与科学 2021年3期
齐星云,戴 艺,赖明澈,常俊胜,董德尊
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
随着集成电路工艺的不断进步,片上多处理器芯片CMP(Chip-Multi-Processor)中集成了多个处理器核。为了实现多个处理器核之间的高速数据通信,片上网络NoC(Network on Chip)应运而生。单个芯片上集成的处理器核数目从1个增长到数十甚至数百个,片上网络的拓扑结构也出现了Mesh、Torus和Crossbar等多种形态,同时也出现了一些商业化的片上网络结构[1,2]。
然而,随着网络规模的增大和逻辑设计复杂度的增加,当前大规模片上网络设计面临的一个重要问题就是硬件资源消耗过大,局部布线密度过高。这是因为,在基于Crossbar的片上网络中,任意一对输入端口和输出端口之间都具有独立的数据通路,因此内部数据通路随着端口数目的增加成平方增长;而且一般需要经过多级交换才能实现输入端口到输出端口的数据转发,所以导致大量的数据总线和控制总线互相交叉。同时,为了避免各端口之间的竞争访问,Crossbar中设计了大量的数据缓存,用来暂存竞争失败、暂时不能继续传输的数据。当网络端口数目较多且内部数据总线较宽时,在芯片内部进行后端布局布线时,大量的存储器占用了芯片的硅片面积,而且大量的全局长线占用了有限的全局布线通道,使得芯片局部出现严重的布线拥塞,影响布线的顺利进行以及后端时序的收敛。同时,过于复杂的逻辑设计,使得路由器内部报文处理流水线变长,报文延时增大。尽管工艺的进步可以在一定程度上提高时钟频率,但随着工艺尺寸的不断变小以及摩尔定律的逐渐失效,提高频率的困难度逐渐增加,对性能的改进也微乎其微。以上问题正逐渐成为困扰NoC设计的关键因素,已经不能简单地通过提高实现工艺,使用高性能库单元来解决了。
另一方面,我们注意到在实际的互连网络中,特别是在CMP系统中,片上网络主要承担各处理器核之间的Cache一致性协议报文的传输,其网络流量的特点是报文粒度较小,网络负载较低,但对报文延时特性要求较高[3]。但是,芯片中除了片上网络之外,还有多核处理器会占用大量的硅片面积,这就要求片上网络不能占用太多硬件资源。在这种情况下,研究人员在设计CMP系统的片上网络时,不需要特别强调网络的高吞吐率,而是需要一种资源占用少、设计简单、硬件资源消耗少、延时低的片上网络来满足要求。这些约束条件要求研究人员给出一种新的片上网络设计方案,来从根本上解决这些问题。
当前的NoC设计中使用交叉开关进行多个端口之间的数据交换。当多个输入端口的报文在竞争同一个输出端口时,需要将竞争失败的端口报文缓存起来,所以在NoC中不可避免地需要大量存储器,用来缓存数据报文。经统计,NoC大部分芯片面积被存储器占据,这样使得后端布线更加困难,而且增加了芯片的功耗和生产成本。
针对上述问题,本文提出了一种基于偏折路由的双环片上网络结构。其思路是,尽量简化路由器逻辑设计和网络结点之间的连接,用规则的环形布线代替以往的交叉互连来进行路由器之间的互连。同时,为了避免单个环网造成的性能低下,本文给出了一种双环结构,2个并行的环网同时工作,以提高网络的带宽。实验结果表明,这种双环网络结构能够很好地满足当前中等规模片上网络的通信需求。
2 相关背景和研究现状
2.1 片上网络拓扑结构
自从Dally等[4]在21世纪初提出了片上网络的概念后,片上网络技术得到了迅猛的发展。在这些片上网络中,二维Mesh网络[5]是一种典型的结构,它通过将m×n个结点组织成m行n列的网格结构来实现片上结点间的数据通信。例如,Intel 的单芯片微处理器TeraFLOPS[6]内包含80 个核,通过一个8×10 的Mesh结构[7]互连在一起。另外一种典型的片上网络结构是Torus[5],与Mesh结构相比,它增加了每一维上头尾之间的连接,将Mesh中每一维的直线链路变成了环形链路。YARC(Yet Another Router Chip)[24]结构也是一种典型的路由器结构,它将片上网络分解成多个瓦片(Tile),每个Tile对应1个网络端口,在布局上,Tile排列成行列结构,Tile之间通过行列总线相连。这种交换结构避免了片内交换时的布线拥塞,当网络端口数目较多时也能实现无阻塞的高性能数据交换。同时,随着3D堆叠技术的成熟,3D NoC结构也迅速发展[9,10]。在先进的制造工艺基础上,采用TSV(Through Silicon Via)技术能够在硅片上制造出具有多层电路的3D芯片[11],从而较为容易地将3D Mesh和3D Torus结构映射到实际的电路中[9,12]。
报文在传统的NoC中路由时,每经过一个路由结点都需要进行接收、缓存、路由计算、端口分配和仲裁以及报文重新发送等过程。随着芯片集成度的不断提高和CMP中处理器核数目的增加,芯片密度迅速增大,布线困难大大提升,系统功耗快速增长,采用Mesh、Torus或YARC这种传统互连结构的片上网络,逐渐面临着设计复杂、功耗过高和硬件资源消耗过大等问题[6,8,10,13]。这迫使研究人员寻求一种低复杂度的设计方案,这时环形网络结构又一次被提了出来。
2.2 环形网络
环形网络是一种简单的网络拓扑结构,环上的每个结点只与其邻居结点通信。最开始,由于性能的原因,环形网络结构只用于小规模处理器之间的简单互连和组网。为了解决环网规模增大时网络带宽过低的问题,许多学者提出了层次式环网结构[14,15]。在这种层次式环网中,多个局部子环通过路由结点连接到全局环网上,并以这种形式扩展出多级层次结构。这样的层次式环形网络将局部网络流量限制在局部环网上,减少了网络带宽消耗,提高了网络性能。为了进一步提高环形网络的性能,一些环形网络的变形结构不断涌现出来。Spidergon网络结构[16]在环形网络的基础上增加了环上对面结点之间的直连通路,以较小的硬件代价缩短了网络直径。Cubic Ring结构[17]则在Torus网络某一维度上保留一条完整的环形链路,并去掉该维度上其他所有的环形链路,即删掉Torus网络中某一维上的某些链路,只在该维上保留少量链路,这样可以用较小的硬件代价获得相对较好的网络性能。随着光互连技术和硅基光器件逐渐走向应用,片上光互连网络中也经常采用环形网络结构[18,19]。传统的环形网络虽然具有结构简单的优点,但是容易产生死锁,并且在路由过程中每一个中间结点都要消耗一定的输入缓存,这不仅带来排队延时和硬件开销,而且还增加了网络的复杂度和芯片功耗。
2.3 偏折路由
偏折路由(Deflection Routing)[3,20]是到达路由器的多个报文竞争同一个链路资源时使用的一种冲突解决方法。其思想是在多个报文竞争使用同一个输出端口而发生冲突时,通过适当的仲裁算法,使得其中一个报文竞争成功并有权使用该端口,而其他报文从路由器的其他端口送出,在网络上绕道传输,并按照路由算法重新选择下一条链路。采用这种偏折路由,当报文竞争端口失败时,不需要进行缓存排队,而只需要选择另外一个端口继续在网络中传输即可。卡内基·梅隆大学的研究者提出的CHIPPER(Cheap-Interconnect Partially Permuting Router)路由器[21,22]就是一个典型的基于偏折路由算法实现的片上网络路由器,该路由器通过偏折路由消除了路由器内部的数据缓存,简化了路由器设计,降低了功耗。文献[13,23-25]研究了片上网络的无缓存偏折路由问题。在文献[24,25]中,当冲突产生时,需要将报文丢弃,这带来了一定的复杂性。
3 双环片上网络结构
3.1 拓扑结构
本文将偏折路由思想与环形网络结构相结合,提出了一种基于偏折路由的双环片上网络结构。在这种结构中,每个路由器(router)由网络接口输入输出逻辑(ni_in/ni_out)和路由仲裁单元(router_arb)模块组成。每个处理单元PE(Processing Element)通过ni与一个路由器相连,多个路由器之间采用2个同向的环形网络(ni0/ni1)连接起来。图1给出了由4个结点组成的双环片上网络。
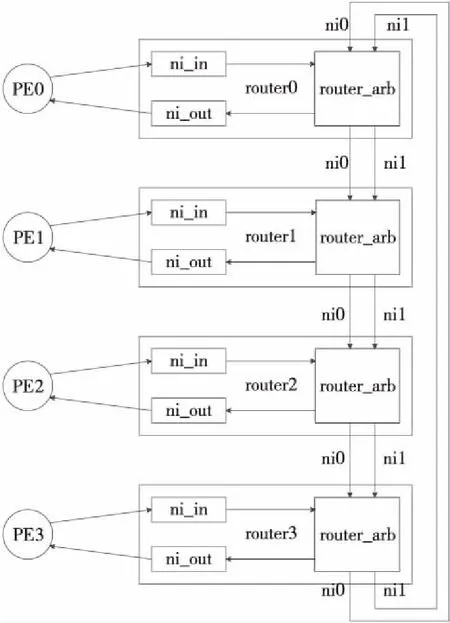
Figure 1 4×4 bi-ring NoC
在基于偏折路由的双环片上网络结构中,网络流量划分成4个虚通道VC(Virtual Channel),各VC之间相互独立,分时使用实际的物理链路。ni_in中包含一个4 VC的输入buffer,用来缓存由PE送来的报文。ni_in按照公平轮转的策略,从4个VC的数据buffer中仲裁出1个VC的报文,送给router_arb。router_arb除了与ni_in和ni_out之间的接口之外,还具有另外2个输入端口和输出端口,分别连接到2个环形网络上。由ni_in送来的报文根据环网链路的状态,使用路由算法选择从哪个网络端口发出报文。报文按照0-1-2-3的顺序在4个路由器上依次传输。如果报文到达目的结点,并且目的结点的ni_out端口空闲,则被对应的路由器吸收并送到目的PE;否则继续在网络链路上传输,直至下一次到达目的结点。
当有报文从路由器的某个输入端口到达时,路由器首先判断报文的目的结点是否为本地结点。如果目的结点不是本地结点,则沿着报文在环网中传输的方向,从对应的输出端口将报文送出。如果有且只有1个输入端口有报文到达,其目的结点为本地结点,并且本地ni_out允许接收报文,则将此报文通过ni_out送给本地处理结点;否则,采用偏折路由,使此报文沿着传输方向从路由器的输出端口上送出,继续在网络中传输,直到下一次到达目的结点。如果2个输入端口都有报文到达,且其目的结点均为本地处理结点,则首先按照路由算法选出某一个端口的报文,使其竞争端口成功;然后再按照前面的方法,决定是将其通过ni_out送给处理单元,还是通过偏折路由使其沿着网络继续传输。
3.2 路由算法
在基于偏折路由的双环片上网络结构中,每个路由器各有2个输入端口和2个输出端口与环网相连。为了简化路由算法,本文规定在双环片上网络中,ni0网络的优先级高于ni1网络的优先级;如果网络上有报文到达目的结点,当ni0网络中有报文时,则优先将ni0上的报文送到目的结点的ni_out端口;当ni0网络中没有报文时,则将ni1网络中的报文送给ni_out。
当PE有报文需要发送到网络中时,路由器首先检测2个输出端口所对应的网络链路是否空闲。如果都空闲,或者只有ni0端口空闲,则将报文送到ni0网络中;如果只有ni1端口空闲,则将报文送到ni1网络中;如果所有端口都忙,则PE中的报文继续在结点中排队等待,直到网络中有空闲端口出现。
本文采用类似Verilog的语法对该路由算法进行描述,具体的双环片上网络路由算法如算法1所示。
算法1双环片上网络路由算法
定义ni0_in_pkt,ni1_in_pkt,ni0_out_pkt,ni1_out_pkt分别为每个路由器上ni0和ni1端口输入和输出的报文;ni_in_pkt和ni_out_pkt分别为ni_in和ni_out端口上的报文;vld(pkt)表示报文pkt是否有效;ad(pkt)表示报文pkt当前到达的结点是否为目的结点。
ifni_outis idle
if(vld(ni0_in_pkt) &ad(ni0_in_pkt))
ni_out_pkt=ni0_in_pkt;
ni0_out_pkt=0;
ni1_out_pkt=ni1_in_pkt;
elseif(vld(ni1_in_pkt) &ad(ni1_in_pkt))
ni_out_pkt=ni1_in_pkt;
ni0_out_pkt=ni0_in_pkt;
ni1_out_pkt=0;
else
ni0_out_pkt=ni0_in_pkt;
ni1_out_pkt=ni1_in_pkt;
else//ni_outis NOT idle
ni0_out_pkt=ni0_in_pkt;
ni1_out_pkt=ni1_in_pkt;
ifvld(ni_in_pkt)
if(~vld(ni0_out_pkt))
ni0_out_pkt=ni_in_pkt;
elseif(~vld(ni1_out_pkt))
ni1_out_pkt=ni_in_pkt;
采用这样的思路,整个路由器的设计将非常简单,只在与处理单元PE的接口处(ni_in)有一个小的缓存队列,用来暂存由于链路忙而无法及时发出的数据。报文在网络中路由时,若不能被目的结点接收,则一直在网络中传输而不需要进行缓存。这样极大地减少了芯片中的存储器,去掉了对报文缓存排队的管理,降低了设计复杂度和硬件开销。
3.3 路由算法分析
首先,算法1中的路由算法是无死锁的。这个结论比较明显。因为网络中死锁形成的条件是有报文占据着缓存,同时又在等待网络下一跳链路上的缓存,互相等待缓存资源,形成一个资源相关的环,就会发生死锁。在本文提出的基于偏折路由的双环片上网络中,路由器中没有缓存,报文不会在路由器上存储,即不会形成互相等待缓存资源的情形,报文在未到达目的结点之前将一直在环形网络上持续传输,因此不会产生死锁。
其次,该路由算法是无活锁的。在处理单元(PE)允许接收到达的报文时,如果网络发生活锁,即意味着有报文在网络中一直传输而始终不能到达目的结点。而在本文提出的网络中不会存在这种情况。因为,对于双环片上网络中ni0链路上的某个报文,经过有限跳步数肯定可以到达目的结点,此时如果PE允许接收报文,则该报文必定会从ni0链路上送给PE,从而空出ni0链路;由于双环片上网络中结点数是有限个,则在有限时间内,网络中所有ni0链路上的报文都会被PE接收,从而空出ni0链路;此时,如果ni1链路上有报文,则在有限时间内也会被PE接收。即网络中某个报文,无论在ni0链路上,还是在ni1链路上,最终肯定会在有限时间内被PE接收,因此不存在某个报文一直在网络中传输而不被接收的情形,因此该路由算法是无活锁的。
4 性能评估
为了对网络性能进行精确的仿真,本文使用硬件描述语言Verilog对上述基于偏折路由的双环片上网络进行了RTL建模和实现,并用Cadence的NC Verilog模拟器进行功能模拟和周期精确的性能仿真,仿真时间为10 000 000个时钟周期。作为对比,基于标准的YARC结构实现了一个同样规模的片上网络结构,文献[8,26]证明了YARC结构在均衡流量模型下可获得100%吞吐率。在这2种网络中,报文宽度为256 bit,实现了4个虚通道,每个虚通道输入buffer的深度为32。
4.1 报文延时
本文统计了8×8的环形结构和YARC结构在不同的网络负载下,报文从源结点到达目的结点所需要的传输延时,如图2所示。从图2中可以发现,在网络负载较小的时候,环形结构的延时与YARC结构的延时相当;而当网络负载逐渐增大时,环形网络的延时超过了YARC结构的延时。这时因为,当网络负载较小时,网络链路基本处于空闲状态,报文很少由于发生冲突而进行偏折路由。当网络负载较大时,环形网络中由于结点接收带宽受限,许多报文因竞争端口失败而发生偏折路由,导致在网络中绕路,造成平均延时增大。还发现环形结构和YARC结构分别在网络负载为0.4和0.9时产生了一个拐点,这个拐点后延时迅速增加。这是因为当网络负载增大到一定程度之后,由端结点送来的报文会在输入缓存中排队,报文的传输总延时会随着队列深度的增加而增大。

Figure 2 Delay comparison of bi-ring NoC and YARC network
4.2 网络吞吐率
本文分析了8×8规模下2个网络所有结点的平均吞吐率,如图3所示。对于YARC结构,随着网络负载的增加,其吞吐率呈线性增长。这是因为在Crossbar中,各个端口之间的交换都是无阻塞的,任意2个端口之间都有独享的数据交换通路。而在环形结构中,当网络负载较小时,其吞吐率随着网络负载的增加而线性增长;而当网络负载较大时,其吞吐率几乎不再增加,进入一个平稳状态。这是因为当网络负载增加到一定程度后,网络链路达到饱和状态,持续增加的报文只能在输入缓存中排队,无法直接进入网络。
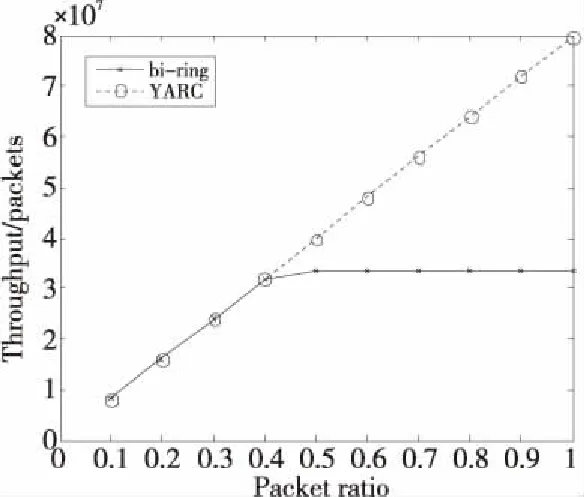
Figure 3 Throughput comparison of bi-ring NoC and YARC network
4.3 延时与距离之间的关系
为了分析报文在环形网络结构中,由于发生偏折路对网络延时造成的影响,本文统计了在不同网络负载下,报文的传输延时与环网中源结点到目的结点的距离之间的关系,如图4所示。源结点与目的结点之间的距离是指在环网中报文从源结点传输到目的结点所需要最少的跳步数。本文分析了环形网络在8×8规模下成功路由的报文的跳步数与结点距离之间的比值,该值基本分布在2~3,这说明在环形网络中,报文的传输延时比理想的最短延时稍大,这是由于偏折路由造成的。在网络负载较大时,偏折路由会导致报文在网络里绕路,使得传输延迟增加。同时可以看出,当网络负载较小时,该比值随着负载的增加而增大;当网络负载较大时,该比值基本维持在一个稳定的值。这说明随着网络负载的增大,报文冲突会加剧,造成实际延时增加。
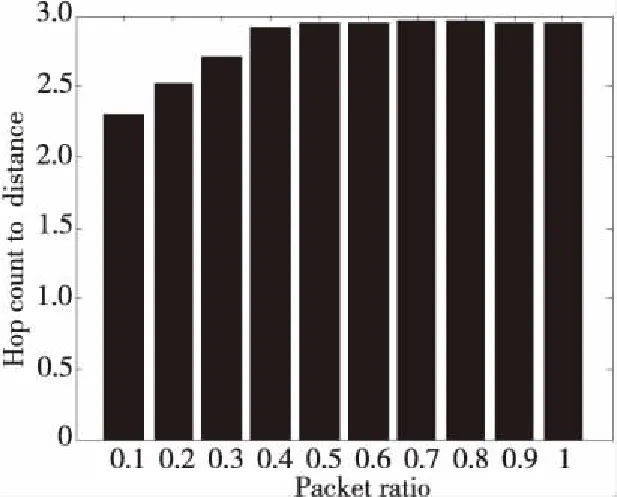
Figure 4 Relationship of hop count and distance in bi-ring NoC
前文只分析了8×8规模下网络的性能特征,下面将对不同网络规模下的延时和吞吐率等网络性能进行对比分析。
4.4 不同网络规模下双环片上网络结构的延时
本文比较了4×4,8×8和16×16 3种不同网络规模下双环片上网络结构的报文平均延时,如图5所示。可以看出,网络规模越大,报文平均延时也越长。这是容易理解的,因为网络规模越大,意味着源结点和目的结点之间的最短距离也将增加,这必然导致延时增加。同时也发现在网络负载增大时,这3种网络都存在一个延时迅速上升的拐点。如前所述,这是由于从这个时刻开始,报文逐渐在输入缓存中排队造成的。网络规模越大,随着网络负载的增加,其拐点越早到达。当网络规模为4×4时,网络负载在0.7以下其性能较好;当网络规模为16×16时,网络负载增加到0.3时,网络就已经基本达到性能极限了。如果还要继续提高网络负载,就只有增加网络传输带宽才能满足性能要求。
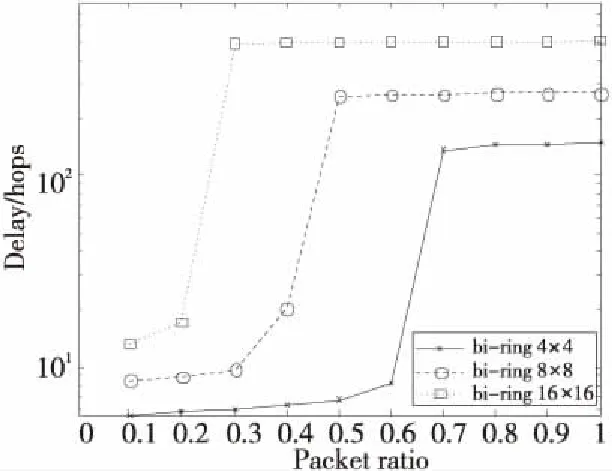
Figure 5 Delay of bi-ring NoC in different network scales
4.5 不同网络规模下环形结构的吞吐率
类似地,本文也比较了不同网络规模下双环结构上每个结点的平均吞吐率,如图6所示。在网络规模较小时,这3种网络中结点的平均吞吐率都随着网络负载的增加而增大。当网络负载增加到一定程度后,由于受到网络总带宽的限制,其吞吐率进入一个相对稳定的状态,不再继续增加。其中,由于16×16规模对网络带宽的需求更大,因此最早达到拐点而进入稳定状态。4×4规模对网络带宽的需求较小,因此最后达到稳定。
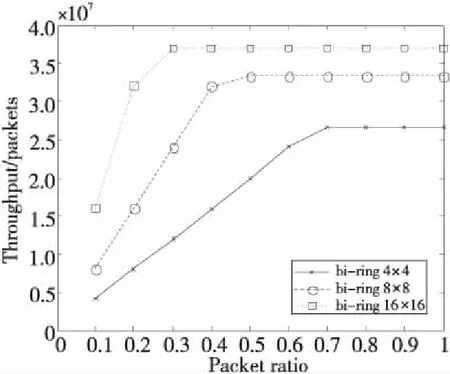
Figure 6 Throughput of bi-ring NoC under different network scale
5 硬件开销
本文分别使用FPGA和ASIC实现来对本文提出的基于偏折路由的双环片上网络进行硬件实现评估。为了进行对比,按照同样的设置和工艺参数对基于YARC结构的Crossbar片上网络进行了综合。2种网络都使用16×16的网络规模,报文宽度256 bit,4个虚通道,每个虚通道的输入buffer深度为32。
5.1 FPGA实现资源评估
在FPGA评估实现时,使用XILINX XC7V2000T- FHG1761-2芯片,采用Vivado 2018.3综合实现工具对2种设计分别进行了综合和布局布线,结果如表1和表2所示。
本文从查找表LUT、触发器FF、块BRAM 3方面对FPGA实现资源进行评估。由表1和表2可以看出,采用同样的FPGA芯片,在同样网络规模下,本文提出的基于偏折路由的双环片上网络与标准的YARC网络占用的硬件资源差别较大。本文提出的实现方案所占用的FPGA资源大约是YARC结构实现方案的11%~13%。
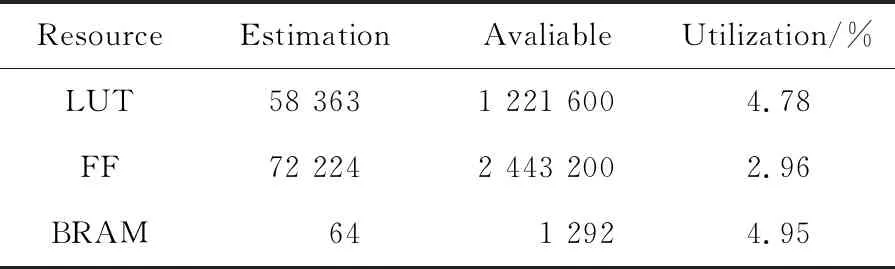
Table 1 Hardware resource evalution of bi-ring NoC based on FPGA
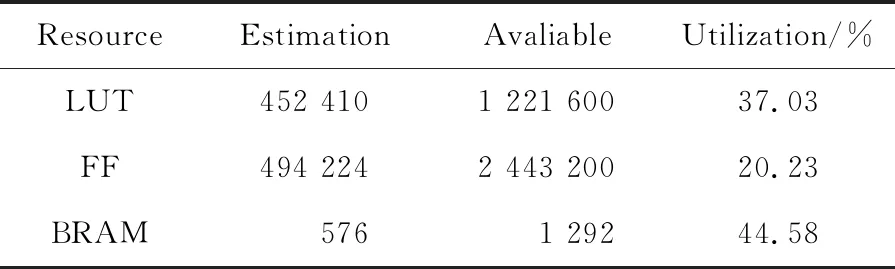
Table 2 Hardware resource evalution of YARC network based on FPGA
5.2 ASIC实现资源评估
在ASIC实现中,本文采用了TSMC 28 nm工艺,频率为800 MHz,使用Synopsys的Design Compiler H-2013.03-SP4进行逻辑综合。其结果如表3所示(面积单位为mm2)。
首先,从表3中可以看出,在ASIC实现方式中,RAM所占的面积(Macro/Black Box Area部分)在总面积中的比例最大,达到了75%左右。而本文提出的基于偏折路由的双环片上网络,相比YARC等其他片上网络,最重要的就是减少了路由器内部数据缓存的使用,因此显著降低了硬件开销。
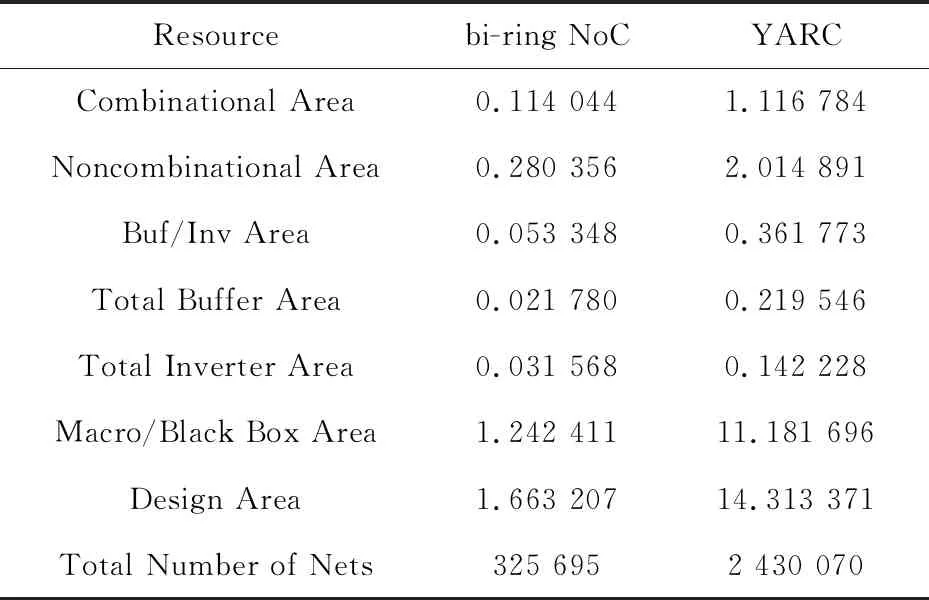
Table 3 Hardware resource evalution based on ASIC
其次,从表3可以看出,双环片上网络消耗的硬件资源明显少于YARC结构的。从设计所占用的总面积来看,双环结构的面积仅为YARC结构面积的11.6%。这主要是由2方面原因造成的:一是在双环片上网络中,在每个端口上只有一个输入缓存,而在YARC结构中,报文在由源端口路由到目的端口时,需要顺序经过3个不同缓存队列,这些缓存占用了相当一部分芯片面积;二是在YARC结构中,为每一对输入和输出端口之间都设计了独享的数据通路,这虽然提高了高负载情形下的网络传输性能,但其代价是消耗了大量的硬件逻辑。
从表3中还可以看出,双环片上网络中消耗的连线资源大约是YARC结构中消耗的连线资源的13.3%。在YARC结构中,这些连线资源主要用在瓦片内部多个Crossbar之间的数据通路上,而在双环结构中,这些连线资源主要集中在路由器之间较为规则的数据通路上。大量的连线资源在占用了芯片面积、增加了设计复杂性的同时,将会导致后端布线难以完成,给后端实现增加难度。
6 结束语
为了简化小到中等规模片上网络的设计,在尽量保持网络性能的同时减少硬件资源消耗,本文提出了一种基于偏折路由的双环片上网络结构。在这种网络结构下,路由器的设计非常简单,除了在与处理结点之间有一个输入缓存之外,没有其它缓存队列,减少了报文的缓存排队和端口仲裁,对于端口的竞争访问通过偏折路由来解决。研究结果表明,在8×8(16×16)网络规模下,当网络负载小于40%(30%)时,这种双环片上网络结构具有很好的延时和吞吐率特性。同时,本文提出的这种双环片上网络的芯片面积只有其他典型片上网络结构(YARC)芯片面积的11.6%,而且降低了设计复杂度,提高了芯片实现效率。即在网络负载较小时,采用本文提出的基于偏折路由的双环片上网络,可以在仅仅消耗大约11.6%的硬件资源的情况下,得到与通常片上网络大致相同的通信性能。这为在SoC芯片中节省面积,降低功耗,并集成更多的计算和处理单元提供了一种可能的途径。
猜你喜欢
数学物理学报(2018年1期)2018-03-26 08:16:42
公民与法治(2016年24期)2016-05-17 04:21:53
电源技术(2016年2期)2016-02-27 09:05:12
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
化工进展(2015年6期)2015-11-13 00:27:25
中国医疗美容(2015年5期)2015-02-03 03:01:43
电子设计工程(2014年12期)2014-02-27 11:58:23
