
基于可逆卷积神经网络的图像超分辨率重建方法
2021-04-06 09:09朱泓宇
林业机械与木工设备 2021年3期
朱泓宇,谢 超
(南京林业大学机械电子工程学院,江苏 南京 210037)
随着数字图像在生产、生活中的应用越来越广泛,图像的增强尤其是图像分辨率的提升,越来越受到人们的重视。图像的超分辨率技术,可以将一张低分辨率的图像转换为高分辨率图像,同时尽可能避免图像放大过程中带来的模糊问题,提升图像的清晰度。如今,这一技术已经在医学影像、安防监控等领域有着非常广泛的运用。
在过去的几年中,人们采用稀疏表示[1]、流形学习等方法进行图像的超分辨率重建,这些方法相较于像素的插值有着十分显著的提升。随着人工智能、深度学习的迅猛发展,近年来涌现出大量基于卷积神经网络的图像超分辨率方法。这些方法通常采用一个低分辨率图像作为网络的输入值,将高分辨率图像作为输出值,采用卷积神经网络来学习两张图片的映射关系。例如Dong等于2016年提出的SRCNN方法[2],首次将卷积神经网络用于图像的超分辨率中。由于浅层神经网络无法学习出对应的关系,为了取得更好的性能,研究者们采用更深的网络进行学习,并引入了如残差结构、注意力机制、对抗生成网络等诸多方法。此类方法相较于传统的机器学习方法,提升效果明显,超分辨率的视觉效果与性能更加优秀。然而,由于超分辨率是一个病态的问题,一张低分辨率图像可以对应出无数张高分辨率图像,以上方法难以准确补充高分辨率图像原有的细节,因此会出现图像锯齿、双重边缘等问题。
Ardizzone 等[3]提出了基于可逆神经网络的图像复原模型,将图像下采样与上采样这一对逆过程相结合,并将下采样图像损失的信息约束在一个正态分布之中。上述方法在图像的指定比例复原中性能表现取得了很好的效果,然而这种方法需要提前预知高清的原尺寸图像,否则将无法复原图像,这显然与超分辨率任务的本质相违背。有鉴于此,本文将基于这一方法与其模型,提出一种改进的图像超分辨率算法模型。
1 可逆神经网络结构与原理
Xiao等[4]提出的IRN网络模型,利用可逆神经网络将输入的原尺寸图像x生成一个缩小尺寸的图像y与一个隐式变量z,并使得z服从一个高斯分布。由于z的分布已知,因此在图片的传输过程中可以丢弃z,如需复原出高分辨率的大尺寸图像,只需要将y与在此高斯分布中随机采样获得的z输入可逆网络即可。可逆神经网络原理如图1所示。
图1中,u1和u2是由输入u分割而成的两部分,u1和u2可经由以下变换得到v1和v2:
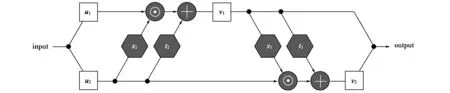
图1 可逆神经网络正向原理
v1=u1e exp(s2(u2))+t2(u2),
v2=u2e exp(s1(v1))+t1(v1)
(1)
而给定输出v,可以将v分割成v1和v2,得到上式的可逆过程,如图2所示。
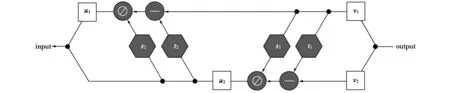
图2 可逆神经网络逆向原理
公式如下:
u2=(v2-(t1(v1))e exp(-s1(v1)),
u1=(v1-t2(u2))e exp(-s2(u2))
(2)
图像在缩小的过程中会丢失高频信息,在放大的过程中需要补充这些丢失掉的信息,因此可以近似认为是一个可逆的过程。
Xiao等采用了此网络结构设计的图像尺寸变换算法模型,可以将高分辨率图像输入此模型正向运算生成低分辨率图像,通过此神经网络模型的可逆过程,恢复出高分辨率图像。相较于原尺寸图像,高分辨率图像并没有丢失过多的细节,达到了很好的效果。
2 残差网络结构与原理
本文提出的深度神经网络结构,主要由残差网络结构组成。残差网络的提出,源于研究者对深层神经网络的研究,由微软研究院的何凯明等提出[5]。在加深神经网络模型的过程中人们发现网络出现了退化的情况,这使得研究者们采用恒等映射的思想来思考此问题,将浅层网络的参数迁移至深层网络,深层网络在最差的情况下仍可以和浅层网络保持相同的效果。然而,随着网络的加深,参数量变大,情况更加复杂,求解器难以拟合同等的函数。
当网络退化时,浅层网络能比深层网络达到更佳的效果,因此如果将浅层网络的特征直接传递到更深层,那就可以缓解深层网络的退化问题。由此,研究者提出了残差学习的方法,网络采用“shortcut”进行连接以传递上层的特征。残差学习模型示意图如图3所示。
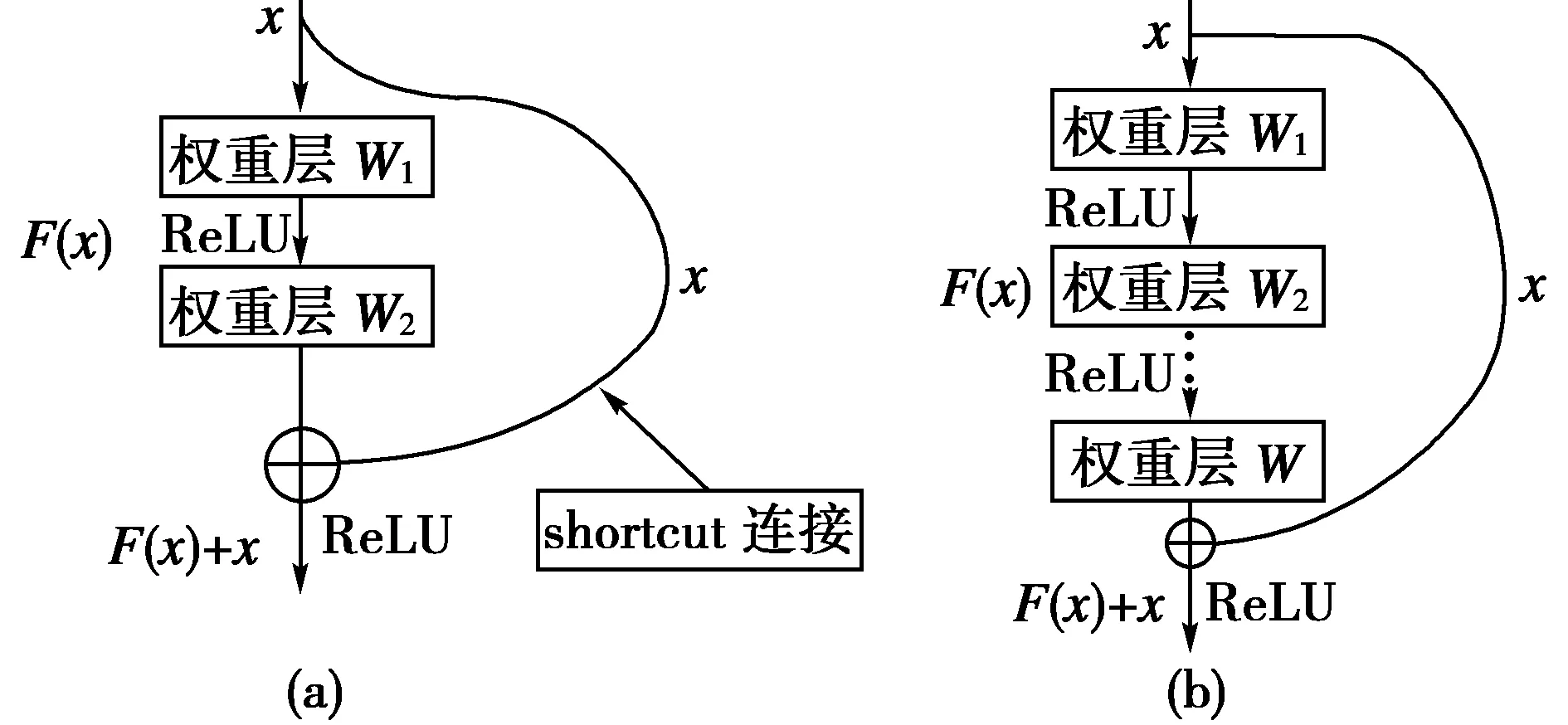
图3 残差学习模型示意图
该模型可以表示为:
y=F(x,[Wi])+x
(3)
式中:x与y分别为残差网络块的输入、输出值,F(x,[Wi])为残差块的计算表达式。
在图3(a)图中共有两个层,其中第一层的输入为x,若忽略偏差影响,则输出为F(1)=ReLU(W1x),其中上标(1)代表神经网络的第一层。那么,图3中(a)图的残差映射为F=W2F(1)=W2ReLU(W1x)。在与原输入值x相加并执行激活函数后,可以看出F(x)=y-x,当F(x)=0时,得到y=x,这就实现了文中所展示的恒等映射的思路,而网络训练过程中,学习F(x)=0的复杂程度远小于学习y=x。在图3中,输入x直接与前向神经网络的计算值相加,称为shortcut连接。shortcut连接相当于一个恒等映射,没有增加额外的参数,避免了计算复杂度的增加。
在残差网络中,残差映射函数F(x)不是固定的,可以根据情况灵活设计不同层数的网络对不同的目标进行拟合。研究者们通过试验,发现34层残差网络的性能和准确率远远高于仅有18层的残差网络。因此,本文设计的神经网络通过采用残差网络模型,在加深网络的同时,尽可能减小网络加深导致图像退化的程度。
3 网络结构设计
设计一个神经网络,学习双三次降采样图像y′到可逆网络生成的低分辨率图像y的映射,然后通过从高斯分布中随机采样一个特定大小的矩阵z,将y和z输入多个可逆神经网络块,进而得到图像的高分辨率重建结果。
经过观察可得,由于双三次降采样得到的图像和可逆神经网络降采样得到的图像具有极大的相似性,前半部分神经网络采用残差结构设计,shortcut连接可以极大程度地传播两张图像的相等之处,而中间层的计算则可以拟合两张图像的相异之处。首先进行的是图像预处理,将图像转化为YCbCr空间后,像素值的范围由[0,255]减小至[0,1],以便输入网络进行后续的训练。第一层为3×3卷积层,输入通道数为1,输出通道数为64,上升通道数以便学习图像更多的细节。后面为连续18层输入,输出均为64通道的卷积层,设计深层网络的目的是为了尽可能准确地拟合双三次下采样图像与目标图像之间的映射关系。最后是一个3×3卷积层,输入通道数与输出通道数分别为64与1,将特征提取为单通道特征图。最后是残差部分,将输入网络的图像与输出图像相加,输出最终的结果。
设计的网络结构如图4所示。
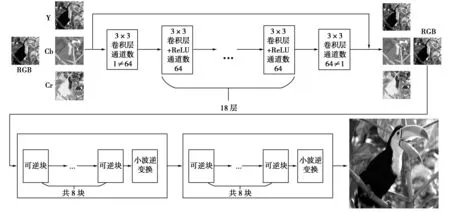
图4 网络结构
4 网络训练
4.1 数据预处理
试验采用DIV2K数据集进行神经网络的训练。训练集根据DIV2K训练集的800张Ground Truth图像,双三次下采样得到尺寸缩小四倍的低分辨率图像。标签图像由可逆神经网络生成,将高分辨率图像输入可逆神经网络进行降采样,得到低分辨率图像。在输入网络时,每组图像取其中对应部位41×41大小的小图进行训练。每组图像随机进行旋转90°~270°,并随机进行翻转,以此在减少硬盘空间占用的基础上进行数据增强。
4.2 网络训练
本网络训练过程,由特征提取、非线性映射、残差相加组成。特征提取操作需要从低分辨率图像y和对应的高分辨率图像x中提取特征信息,获取从低分辨率图像到高分辨率图像的增量,然后将每组增量表示为高维向量。通过一组卷积核对低分辨率图像进行卷积,记F1(x)为特征提取操作的输出,则两者关系为:
(4)
式中:W1为卷积核权重值;B1为卷积核的偏移值。W1的维度为3×3×3,第一维表示图像的通道数,第二和第三维表示图像的高度和宽度。
为了使深度神经网络中的高维向量更好地向后映射,防止网络加深可能导致的梯度消失,本文采用ReLU激活函数作为残差块中的激活层[6-8]。
本文提出的残差网络结构,通过使用三个相同结构的神经网络,学习图像Y、Cb、Cr三个通道从双三次降采样图像到由可逆神经网络降采样得到的图像端到端映射,从而改变图像中的部分细节,进行图像之间的转化。并通过指定学习率的优化器不断降低两种降采样图像之间的损失。
4.3 网络参数的调整及设定
通过一组给定的双三次降采样图像{xi}i=1→n和IRN降采样图像{yi}i=1→n,训练神经网络学习两组低分辨率图像之间的映射,从而将输入图像实现超分辨率的效果。为了使网络更加逼近两者之间的映射,需要对网络的参数进行不断调整。本文采用平均方差(MSE)损失函数计算损失,使用随机梯度下降(SGD)优化器进行参数优化,不断降低输出结果与可逆神经网络降采样结果之间的差异。本文的批量大小设置为64,即网络每次迭代时输入64组对应图像。
5 试验结果与分析
5.1 试验环境配置
处理器为 Intel i9—9900K,神经网络框架为 PyTorch 1.4,CUDA 版本为 CUDA 10.0,GPU 为英伟达GTX 2080TI,内存容量为32 G。
5.2 图像超分辨率评价
本文采用主观评价法与客观评价法两种主流评价方法,对图像超分辨率效果进行评估。客观评价法主要采用峰值信噪比PSNR[9]和结构相似性SSIM[10]两种指标。
使用测试集对本文的超分辨率方法进行测试,并将图像转换至YCbCr通道,计算Y通道的PSNR值,结果见表1。
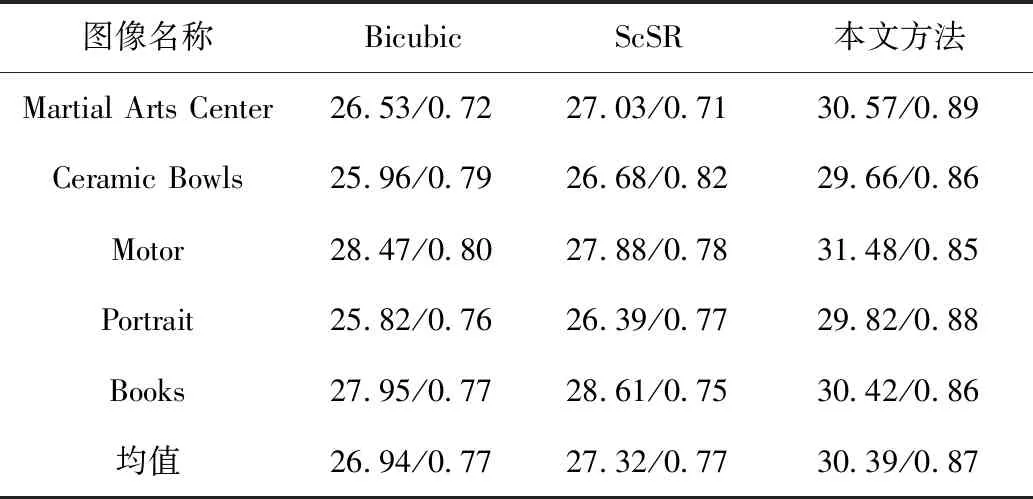
表1 测试集PSNR/SSIM结果
其中几幅图片的测试结果如图5~7所示。

图5 Martial Arts Center测试效果
从上述试验结果可以看出,本文提出的基于可逆神经网络的图像超分辨率方法,相较于双三次插值、ScSR等传统方法,主观、客观评价都取得了更好的效果。

图6 Ceramic Bowls测试效果

图7 Motor测试效果
6 结束语
本文提出了一种基于可逆神经网络的图像超分辨率算法模型,该模型基于可逆图像缩放网络的预训练模型,学习不同下采样得来的低分辨率图像之间的映射,从而达到图像超分辨率的目的。采用残差网络模型,避免了随着网络加深图像训练过程中的退化。在指定的测试集中,本方法达到了较好的效果。本文提出的方法仍有很大的提升空间,依旧可以采用例如修改网络层数、采用注意力模块、引入对抗网络机制等方法提升图像拟合的效果,从而提升超分辨率的效果,更好地恢复低分辨率图像损失的细节,这有待于后续的研究。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
健康体检与管理(2021年10期)2021-01-03
北京航空航天大学学报(2020年10期)2020-11-14
计算机应用(2020年7期)2020-08-06
雷达学报(2020年3期)2020-07-13
北京航空航天大学学报(2019年9期)2019-10-26
艺术科技(2018年2期)2018-07-23
发明与创新·中学生(2017年1期)2017-01-20
太空探索(2016年3期)2016-07-12
