
基于堆叠模型的司法短文本多标签分类
2021-04-06 10:53闻英友孔为民
计算机技术与发展 2021年3期
何 涛,陈 剑,闻英友,孔为民
(1.东北大学 东软研究院,辽宁 沈阳 110169;2.定陶区人民检察院,山东 菏泽 274100)
0 引 言
随着国内司法业务信息化的发展,司法领域产生了巨量的文本数据,目前办案人员主要依靠手工分析案件卷宗、提取案件要素的工作方式,效率低下,已无法满足智慧司法的客观需要。如何在海量司法文书数据中自动抽取出有价值的信息,具有巨大的社会意义和商业价值。一种可行的方式是将司法文书进行细粒度分割,生成短文本子集,并通过深度学习等智能化方法对短文本进行多标签分类,将案件要素抽取出来呈现给办案人员。高效地将大规模司法短文本数据进行正确的归类,是智慧司法系统的基本任务,也是其他司法过程的基础。
近年来,随着计算能力和深度学习算法的快速发展,深度学习在人工智能的多个领域都取得了显著的进展。通过使用非线性网络结构实现复杂的函数表达,并在特征表达时使用分布式特征输入,使深度学习凭借强大的特征学习能力,在自然语言处理领域取得令人瞩目的成绩。
Arevian[1]使用真实世界中的文本对循环神经网络进行训练,完成文本分类。Chen等人[2]采用扩展短文本特征的方式派生特定粒度的暗含主题,并在在多个主题粒度上,利用多主题来更精确的进行短文本建模。Fu等人[3]使用卷积神经网络对司法文书进行分类,达到了比传统的基于Logistic回归和支持向量机更好的效果。Kim[4]提出的TextCNN模型在文本分类方面取得了很好的效果,使得该模型成为CNN在自然语言处理中应用最广泛的模型。Kalchbrenner等[5]提出了动态的k-max pooling机制,使得文本特征提取能力进一步增强。Lei等[6]在标准卷积层使用基于张量的词间操作代替串接词向量的线性运算。Zhang等人[7]使用N-Gram模型扩展短文本,通过词语之间的相似度阈值判定文本的分类。陈钊等人[8]使用情感词典识别构成二值特征作为外部辅助特征,提高了CNN模型的处理能力。Shi等人[9]提出了卷积循环神经网络,在处理序列对象时比传统神经网络模型具有一些优点。Vaswani等人[10]提出基于多头自注意力机制的Transformer模型,大大提高了文本特征提取能力,为序列标注任务提出新的解决方法。Yang等[11]在LSTM模型运用Attention机制进行文本级分类,取得了较好的分类效果。Xiao等人[12]提出结合卷积神经网络和循环神经网络的方式提取文本特征,结合了两种神经网络的特点。Hassan等人[13]针对卷积神经网络在捕获文本特征长期依赖问题时需要多层网络,提出联合CNN和RNN网络模型。Yin等人[14]提出一个更为细化的卷积神经网络ATTCONV,该算法使用注意力机制扩展了卷积运算的上下文范围。2018年10月底,Google公布BERT(bidirectional encoder representation from transformers)[15]预训练模型在11项NLP任务中刷新纪录,引起业界的广泛关注。
然而,现有的方法应用于司法短文本多标签分类时,还存在分类准确率不高的问题,主要原因是提取文本特征的方式仍然过于单一。为此,该文提出了一种基于深度学习堆叠模型的多标签分类方法,融合了Transformer、卷积神经网络、循环神经网络等各种深度学习算法的优势,解决了提取特征角度单一的问题,进一步提升了短文本多标签分类性能。
1 短文本分类堆叠模型

提出的堆叠模型整体架构如图1所示。
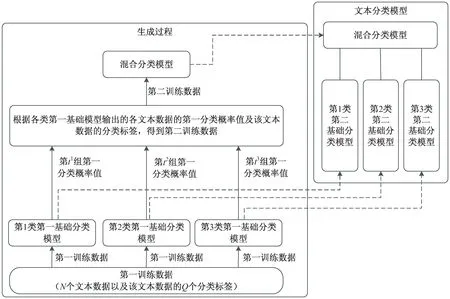
图1 短文本分类堆叠模型整体架构

这种模型的优势在于,首先分别使用3种不同类型的深度学习网络从不同角度提取文本特征,其次将不同模型的输出结果以多标签概率值进行融合,可以获得比分类结果更加丰富的信息。第一基础分类模型与第二基础分类模型使用相同的结构、相同的训练参数,只是使用了不同的训练数据,应用在不同的过程中。
为验证该方法的有效性,第一层分类模型分别使用BERT预训练模型、单通道TextCNN模型、Bi-GRU模型,混合分类模型使用自定义的包含两个隐藏层的深度神经网络。
1.1 BERT预训练模型
BERT预训练模型是在多层Transformer编码器的基础上实现的。Transformer编码器作为文本特征提取器,其特征提取能力远远大于RNN和CNN模型,这也是BERT模型的核心优势所在。
Transformer是一个完全依赖自注意力来计算输入和输出的表示,而不使用序列对齐的递归神经网络或卷积神经网络的转换模型。自注意力的计算方法如下:需要从编码器的每个输入向量中创建三个向量,一个Query向量、一个Key向量和一个Value向量。这些向量是通过将词嵌入向量与3个训练后的矩阵Wq、Wk、Wv相乘得到的,维度默认为64。为了便于计算,将三个向量分别合并成矩阵,得到自注意力层的计算公式:
(1)
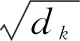
在Transformer的基础上,BERT使用Masked LM来进行无监督预训练。一个深度双向模型,要比单向的“左-右”模型,或者浅层融合“左-右”和“右-左”的模型更高效。为了解决双向训练中每个词在多次上下文可以间接看见自己的问题,BERT采用随机遮掩一定百分比的输入token,然后通过预测被遮掩的token进行训练。
1.2 单通道TextCNN模型
TextCNN使用双通道,引入通道的目的是希望防止过拟合,可以在不同的通道中使用不同方式的词向量嵌入方式,达到在小数据集合获得比单通道更好的性能。其实直接使用正则化效果更好,该文使用单通道的TextCNN模型,其结构如图2所示。

图2 TextCNN模型结构
整个模型由四部分构成:输入层、卷积层、池化层、全连接层。TextCNN模型的输入层需要输入一个定长的文本序列,通过分析语料集样本指定一个输入序列的长度L,比L短的样本序列需要填充,比L长的序列需要截取。对于词向量的表示使用预训练好的word2vec作为输入。
在自然语言处理领域,因为在词向量上滑动提取特征没有意义,所以每个卷积核在整个句子长度上进行一维滑动,即卷积核的宽度与词向量的维度等宽,高度与步长可以自定义。通常,在TextCNN模型中使用多个不同尺寸的卷积核。卷积核的高度,可以理解为局部词序的长度,窗口值是需要设置的超参数,一般选取2~6之间的值。
在卷积层保留了特征的位置信息,为了保证特征的位置信息在池化层不被丢失,TexCNN模型选用k-max pooling池化方法。相比于最大池化方法,k-max pooling针对每个卷积核都保留前k个最大值,并且保留这些值出现的顺序,即按照文本中的位置顺序来排列这k个最大值,对于文本分类精度提升有很大作用。卷积层与池化层的核心作用就是特征提取,从定长文本序列中利用局部词序信息,提取初级的特征,并组合初级的特征为高级特征。
1.3 Bi-GRU层
GRU单元保持了LSTM的效果,同时又使结构更加简单。GRU只剩下更新门和重置门两个门限。更新门用于控制前一时刻的状态信息被带入到当前状态的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门用于控制忽略前一时刻的状态信息的程度,值越小说明忽略得越多。GRU单元结构如图3所示,GRU单元的计算公式为:
(2)
(3)
(4)
(5)
其中,Wxz、Wxr、Wxg是每一层连接到输入向量xg的权重矩阵,Whz、Whr、Whg是每一层连接到前一个短期状态h(t-1)的权重矩阵。

图3 GRU单元结构
在处理文本分类问题时,神经网络模型不仅要关注上文信息,同样也要关注下文信息,将前向GRU和后向GRU结合起来,使得每一个训练序列向前和向后分别是两个循环神经网络,而且这两个网络连接着同一个输出层,这便是Bi-GRU的优点。
1.4 多标签分类概率融合
针对训练集,使用5折交叉验证方法,首先将训练数据随机分割成5个不同的子集,每个子集称为一个折叠。使用第一层文本分类模型对数据进行5次训练和评估,每次使用4个折叠进行训练,使用另外一个折叠进行评估,评估的结果为每个类别的多标签概率值,而不是分类结果。目前的堆叠模型,初级学习器都是输出分类结果,让混合器在此数据上进行投票,多标签概率值数据远比分类结果值包含更加丰富的信息。
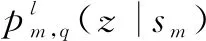
(6)

将多个交叉验证产生的多标签概率值进行融合,对于单个样本来说,相当于将该样本产生的三个多标签概率值向量进行拼接,拼接后的数据作为下一层分类器的输入数据,标记仍然使用原来的label。对任意输入样本m,新数据标签集表示为:〈sm;Pm;x1,x2,…,xQ〉 。
其中,Pm为经过3个分类器的概率联合,表示为:

(7)
经过DNN混合器得到:Pm→Lm,Lm表示最终计算出的多标签分类结果。
1.5 DNN混合器
混合器采用自定义的深度神经网络,输入是基础分类模型计算的联合多标签概率值,输出为样本的多标签分类,其网络结构包含两个隐藏层,每个隐藏层256个神经元,采用He初始化方法;Dropout设置为0.5,使用ReLU激活函数。
2 实验结果分析
为了验证所提多标签分类模型的有效性,使用中国裁判文书网公开的裁判文书,以从长文本中抽取案件要素为例,比较该模型与常用模型在分类性能上的差别。
2.1 标注语料
本实验搜集到中国裁判文书网公开的裁判文书10万余份。为实现对文本进行分割并分类,需要定义复杂的短文本类别标签集,针对不同的犯罪类型,标签集包含的内容也各不相同。以盗窃罪为例,需要定义的类别有:盗窃时间点、盗窃工具、手段方法、公然窃取、秘密窃取、入户扒窃、造成其他损害、被盗物品价值、失窃者损失后果、处理情况、是否返还、如何到案、强制措施、认罪认罚情况、上诉抗诉等共15类标签。由于目前并没有公开的司法文书标注语料库可供使用,因此从语料库中选取盗窃类型且内容较为详实的2 900份文书进行标注,所有的标注工作均由经过专业培训的人员手工标注完成。尽管不排除主观因素对多标签标注边界的影响,但总体而言标注质量较高,非常适合用于模型的训练。
标注工作完成后,短文本样本的表示方式为: 〈sm,x1,x2,…,xQ〉,其中sm为输入第m个的文本序列,xi为是否属于标签i的示性函数,如果xi=1,表示sm属于分类i,否则xi=0。
2.2 样本分布
盗窃案件各要素标签样本分布如表1所示。

表1 盗窃案标签样本分布
从数据集中随机抽取三部分作为训练集、验证集、测试集,文书数量比例约为4∶1∶1。第一基础分类模型主要用于获取所有样本的多标签概率分布矩阵,每次使用80%的训练集数据进行训练。第二基础分类模型,则使用全部的训练集数据重新训练3个第一层分类器,在原来分配的验证集上获取最佳模型。混合器使用多标签概率矩阵进行训练,在训练第二基础分类模型后,使用同一个混合器。两个过程分布完成以后,在最终在测试集上得到整个堆叠模型的性能指标。
2.3 结果对比
在机器学习中评估模型的性能通常使用精度P、召回率R、F1分数三个指标,计算公式分别为:
Pi=TPi/(TPi+FPi)
(8)
Ri=TPi/(TPi+FNi)
(9)
Fi=2Pi×Ri/(Pi+Ri)
(10)
其中,TP表示真正类的数量,FP表示假正类的数量,FN表示假负类的数量。由公式可知,P表示精度,R表示召回率,F1分数是精度和召回率的谐波平均值,只有当召回率和精度都很高时,才能获得较高的F1分数。为了证明提出的模型在性能方面的优越性,在相同数据集上,分别与TextCNN、BiGRU、BERT等几个模型进行比较,比较结果如表2所示。

表2 不同模型在测试集上分类性能
从统计数据可以看出,堆叠模型综合计算BERT、TextCNN、BiGRU等强模型输出的分类概率值,在F1分数上获得进一步的提升,F1分数的加权平均值达到87.2%,比性能最好的BERT模型提高了3个百分点。
3 结束语
为提高短文本多标签分类性能,提出一种融合深度学习与堆叠模型的短文本多标签分类方法,该方法采取多层分类器结构,使用BERT、TextCNN、Bi-GRU等差异化较大、准确性较高的强分类器作为第一层学习模型,生成的多标签概率矩阵用来训练第二层的混合器。
实验表明,该方法优于目前主流的几种短文本多标签分类模型,在性能上得到了进一步的提升。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
新高考·高一数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
上海师范大学学报·自然科学版(2019年5期)2019-12-13
软件(2017年6期)2017-09-23
高中生学习·高三版(2016年9期)2016-05-14
