
基于改进Self-Attention的股价趋势预测
2021-04-06 10:13郑树挺徐菲菲
计算机技术与发展 2021年3期
郑树挺,徐菲菲
(上海电力大学 计算机科学与技术学院,上海 200000)
0 引 言
金融市场被认为是世界经济的核心,每天交易额巨大,对市场未来行为的预测对投资者来说具有重要的价值,包括股票市场、货币汇率[1]、原油价格[2]、商品价格和比特币[3]等加密货币。由于市场的动态和嘈杂的行为,市场预测也是一项非常具有挑战性的任务,吸引了较多学者的关注。
对股票市场的预测是一个非常具有挑战性的问题,影响股票市场价格有很多因素,如公司新闻和业绩、行业表现、投资者情绪、社交媒体情绪和经济因素,用于预测的特征更是多种多样:价格数据,历史数据的技术指标,与个股有关的其他市场价格波动,货币汇率,油价等。自动提取特征并进行准确的市场预测受到了较多学者的关注。
现有的金融市场分析方法一般分为两大类,一是基本面分析,另一个是技术分析。
在技术分析中,目标市场的历史数据和其他一些技术指标均是预测的重要因素。根据有效市场假设[4],股票价格可以反映出它们的所有信息。技术分析通过分析以前的价格数据和技术指标预测市场价格的未来趋势。而基本面分析研究证券投资的内在价值,可以通过获取相关资产(主要是股票或交易所交易基金)的财务报表的详细信息来实现,如现金流量、增长率、贴现因子、每年折扣和资本化率等,以深入了解公司的未来发展前途。基本面分析通常用于决定应选择哪种股票进行交易。
已经有多种机器学习技术广泛应用于金融市场的预测,并取得了一定的效果,其中神经网络和支持向量机(support vector machine,SVM)[5-7]使用的最多,例如,赵澄[8]使用SVM来预测金融新闻对股票市场的影响。此外,随机森林[9]、遗传算法[10-13]、集成学习[14-15]等技术也已成功应用于从原始金融数据中提取特征并基于特征进行预测[16-17]。
深度学习(deep learning)[18-19]是一类适合自动特征提取和预测的方法,在许多领域如机器视觉、自然语言处理以及语音信号处理,深度学习方法能够从原始数据或更简单的特征逐渐构建有用的复杂特征。由于股票市场的行为是复杂的、非线性的,而且股票数据具有噪声,提取出准确的特征以进行预测面临着巨大的挑战。研究者尝试了多种深度学习算法用于预测股票市场,如:深层多层感知器(MLP)[20]、Restricted Boltzmann Machine(RBM)[21-22]、Long Short-Term Memory(LSTM)[23-25]、Auto-Encoder(AE)[26]和Convolutional Neural Network(CNN)。
Periso & Honchar[27]将CNN用于股票分析中,根据收盘价的历史数据进行预测,由于忽略了技术指标等其他可能的信息数据,预测的准确率并不高。Gunduz[28]将每个样本的相关技术指标送入CNN中,提高了预测的准确率。Ding[29]通过对上市公司发出的公告进行事件提取来进行预测股价走向;Nguyen[30]、刘斌[31]则是基于社交媒体情绪分析的主题建模,然后用于股票市场预测。基于文本信息处理的方法虽然取得了一定的效果,但因为目前自然语言处理技术中语义理解方面仍然是一个难题,所以有一定的局限。
总体来说,现有的机器学习应用于股票预测主要分为两类方法。第一类包括通过增强预测模型来提高预测性能的算法,而第二类算法侧重于改进基于预测的输入特征。虽然现有的研究取得了一些成果,但预测的准确率有待进一步的提升。该文通过改进Self-Attention结构,分别对日线数据、分时线数据以及筹码结构进行编码并融合信息。实验结果表明,所提方法能够有效提升股票未来走势的判断准确率并提高投资收益率。
1 相关研究
循环神经网络(RNN)已经被证实适合处理时间序列数据,图1所示为RNN的结构。

图1 RNN结构示意图
令s
s
(1)
其中,f一般是非线性的激活函数,如sigmoid或tanh。RNN通过Backpropagation Through Time (BPTT)算法更新参数,然而缺陷是无法处理序列长度过大的数据,因为会带来梯度消失或梯度爆炸的问题。当然,目前已经提出多种方法解决这个问题,如LSTM、GRU。
LSTM与GRU在结构上很相像,在Transformer出现之前是处理时间序列问题的主流算法,如图2所示为一个LSTM cell的网络结构。
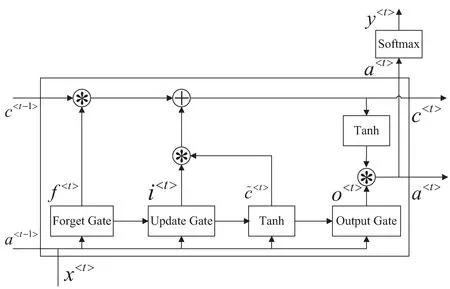
图2 LSTM结构示意图
具体来说,在LSTM循环单元中包含三个门(gate),Forget gate决定要扔掉哪些信息,计算公式见式(2):
f
(2)
Updating gate决定要增加哪些新的信息,计算公式见式(3):
i
(3)
Forget gate和Updating gate一起决定了“长记忆”c
(4)

(5)
Output gate决定了“短记忆”a
o
(6)
a
(7)
可以看出,在实际使用时,几个门值不仅仅取决于a
Transformer[32]是谷歌在2017年发布的一个全新的网络结构,Transformer本质上就是一个Attention结构,它能够直接获取全局的信息,而不像RNN需要逐步递归才能获得全局信息,也不像CNN只能获取局部信息,并且其能够进行并行运算,要比RNN快很多倍。Transformer中一个重要的结构是Multi-Head Attention,计算公式见式(8),其中headi的计算公式见式(9):
MultiHead(Q,K,V)=Concat(head1,head2,…,
headh)Wo
(8)
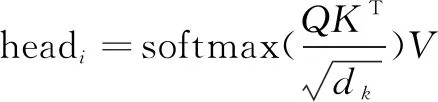
(9)
这里的Multi-Head的含义是,每个Transformer结构会由多层结构完全一样,但权重矩阵不同的Attention组成,也就是Self-Attention结构。这么做的目的是为了防止模型只关注到一部分特征,却忽略了其他特征,所以增加模型的厚度,让模型拥有多层结构相同但是权重不同的Attention,每一个head都关注到不同的特征,那么模型整体就会关注到更多的特征。
2 基于改进Self-Attention的股票预测
2.1 数据获取
实验采用的数据将是从2018年1月1日到2019年10月31号、上证50成份股中的股票数据。数据获取途径均是从网络上爬取下载获得,从沪股通官网获取到每日上证股票的港资持股量以及所占个股比例,从上海证券交易所官网获取到每日个股的融资余额、融资买入额以及融资偿还额,其他的分别是从“同花顺”、“东方财富”等网站获取。Input0包括K线数据,例如:开盘价、收盘价、最高价、最低价、日成交量、日成交额、换手率、MA5、MA10、MA20、MA30、市盈率、市净率等,以及个股的沪股通数据、融资融券数据、资金流向数据(小、中、大、特大单的买入卖出量以及买入卖出额,以及净流入量和净流入额)等;Inpu1包括分时线数据,包含分时价格和分时成交量;Input2包括筹码结构信息。
2.2 时序数据处理
因为获取到的K线数据是未复权的,所以从2019年10月31号开始向前复权。将所有跟成交量有关的数据的单位统一转换成“手”(1手等于100股),将所有跟金额有关的数据的单位统一转换成“万元”。下载的沪股通数据包括总持股数量和总持股占比,由前后两日的总持股数量计算出单日沪股通成交量,再计算出沪股通当日净成交量的占比。下载的融资融券数据包括融资余额和融券余额,分别计算出当日融资余额和融券余额占当日成交额的占比。小、中、大、特大单的买入卖出量以及买入卖出额,以及净流入量和净流入额也相应转换成当日成交量或成交额的占比。
对部分特征进行归一化处理,如成交量、成交额、流通股本等。对所有股票数据进行处理,生成时间序列数据(模型的Input0、Input1),维度为(L,M,N),其中M表示样本数,N表示总特征数,L表示序列长度,也就是已知的前L天的数据,即L天的数据为一组特征,用前L天的数据来预测后一天涨幅。将时间序列数据的特征数分为两个输入分别对应于模型的两个输入Input0和Input1。
“涨幅”为用来训练的标签,定义为:(当日收盘价-昨日收盘价)/昨日收盘价;“涨幅正负”为用来验证准确率和精度的标签。这边设定当涨幅为正时,则判定该股票的趋势为涨(label:1);当涨幅不为正时,则判定该股票的趋势为跌(label:0)。
对数据集进行划分,其中训练集数据的时间段为2018.01.01~2019.08.31,测试集数据的时间段为 2019.09.01~2019.10.31。分别对训练集和测试集的涨跌分布进行了统计分析,发现训练集和测试集的涨跌分布有一定的差异性,证明了改进的模型在后续的实验中具有一定的泛化性。
2.3 融合多源数据
在股票交易操作上,一般短线操作都会实时关注个股的分时线走势。在之前的一些研究中,利用机器学习预测股票一般都只关注了个股的日K线走势及数据,而忽略了每日的分时线数据及其他一些数据。每日的分时线数据隐藏了大量的交易信息,例如可以看出大资金的流入流出,对于个股未来趋势的预测提供了大量有用的信息。
改进的模型基于Self-Attention架构,解码器采用全连接层,在编码器端合并了日线数据(Input0)、分时线数据(Input1)以及筹码结构数据(Input2),如图3所示。分时线数据编码器采用Multi-Head Attention和Feed Forward堆叠而成,有N层;日线数据编码器也由N层堆叠而成,前N-1层结构一样,但不共享参数,最后一层通过对分时线数据编码器输出做Multi-head Attention输出o1,对自身做Multi-head Attention输出o0;筹码结构编码器采用全连接层,输出o2。融合三个输出o并进行解码,计算公式见式(10)、(11)、(12):
m=σ(Wm·[o0,o1]+bm)
(10)
n=m⊙o0+(1-m)o1
(11)
o=Concat(n,o2)
(12)

图3 改进的Self-Attention模型
3 实验与分析
3.1 评估指标
在训练阶段,做的是回归任务,即预测股票涨跌的幅度,损失函数用的是均方根误差(root mean squared error,RMSE),计算公式见式(13):

(13)

根据样本的真实结果和模型预测结果,将样本分为四类:
TP(true positive),样本是正样本并且模型预测结果也是正样本的个数;
FN(false negative),样本是正样本但模型预测结果是负样本的个数;
FP(false positive),样本是负样本但模型预测结果是正样本的个数;
TN(true negative),样本是负样本并且模型预测结果也是负样本的个数。
评价模型性能使用以下2个指标:准确率 (Accuracy)和精确率(Precision)。

(14)

(15)
3.2 实验配置
实验硬件配置为CPU:AMD-3700X,内存:32 G,GPU:RTX-2070。操作系统为UBUNTU 18.04,Python版本为3.7.3,深度学习框架采用Pytorch。优化器选择Adam,学习率为1e-4,使用256的小批量大小。
3.3 不同长度的时间序列数据效果对比
为了测试不同长度L的历史数据对实验结果的影响,使用改进的Self-Attention模型测试了不同L对预测准确率的影响,实验结果见图4。

图4 不同长度L对结果的影响
3.4 模型效果
在测试集数据上,使用相同步骤的预处理步骤(这边使用的历史数据长度L为30),在不同的模型上进行测试得出的数据,如表1所示。可以发现,RMSE降低了不少。图5展示了改进的Self-Attention模型在部分个股上的预测结果。

图5 改进的Self-Attention预测值
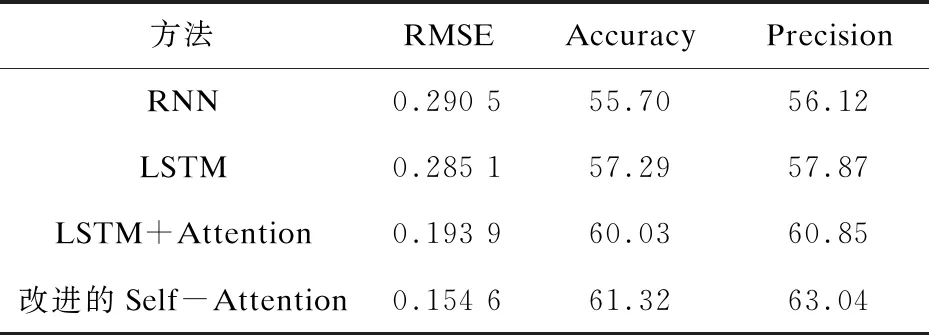
表1 算法性能对比
3.5 个股预测及投资收益
通过模型对测试数据进行预测买卖点以及收益率,选取股票“浦发银行”作为操作说明。因为该模型是通过前L天(这里L取30)的数据预测后一天的涨幅,所以当预测的涨幅大于等于1%的时候,模型提示买入;预测的涨幅小于等于-1%的时候,模型提示卖出;当预测的涨幅在-1%到1%之间的时候,模型提示不操作。图6展示了预测模型对买点和卖点的判断,图中提示的买卖时间点是每日的刚开盘时间(即9:30)。假设采取的策略是:当未持有该股票时,提示买入的时候,买入100股的股票;当持有该股时,提示买入的时候,不进行买卖操作;当提示卖出的时候,卖出持有该个股的所有股票,如果不持有该个股的股票则不进行买卖操作;既没有提示买入也没有提示卖出的时候,则不进行买卖操作。根据图6,在“20190904”日刚开盘的时候以11.4的价格买入100股,在“20190905”日的时候虽然提示买入,当已经持有该股票,所以不进行操作,直到在“20190916”日刚开盘的时候以11.99的价格卖出100股,收益率是(11.99-11.4)/11.4=0.051 7,所以在“20190613”卖出的操作中收益率为0.051 7,其他的卖点收益计算类似。只有当进行卖出操作的时候收益率才会变化,图7展示了三只股票在测试数据上的收益率变化。图8展示了同期上证50指数的投资收益率以及采用模型预测的上证50个股平均收益率。可以发现,改进Self-Attention模型可以提高投资收益率。

图6 浦发银行K线及买卖提示图

图7 部分个股投资收益变化曲线

图8 同期投资收益变化
4 结束语
该文提出一种基于Self-Attention模型的金融时间序列预测模型,使用该模型预测中国证券市场上证50成分股,通过实验验证了模型的准确率和精确率:模型的预测准确率为61.32%,对正样本的预测精确率为63.04%,这说明了改进的模型可以有效预测股票趋势。在与其他模型的对比中效果更优。由图8可知,通过模型的预测买卖点进行股票买卖操作,在测试数据上的投资收益率为6.562%,而同期上证50指数的收益率3.260%,收益率提高了101.28%。所以改进的模型可以有效辅助投资并取得一定的收益,这表明该模型在股价趋势预测上具有一定的有效性和实用性。
由于中国股市的散户占比大,市场容易受到情绪波动的影响,因此下一步将结合对股民情绪的分析以增加模型的准确率。
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
领导决策信息(2018年16期)2018-09-27
高中生学习·高二版(2017年9期)2017-10-25
数学学习与研究(2017年3期)2017-03-09
考试周刊(2016年44期)2016-06-21
计算技术与自动化(2014年1期)2014-12-12
新高考·高一物理(2014年4期)2014-09-17
