
基于强化语义的中文广告文本识别技术研究
2021-04-06 10:13邓叶勋赵建强李文瑞欧荣安
计算机技术与发展 2021年3期
赵 伟,邓叶勋,赵建强,3*,李文瑞,韩 冰,欧荣安
(1.广州市刑事科学技术研究所,广东 广州 510030;2.厦门市美亚柏科信息股份有限公司,福建 厦门 361008;3.西安电子科技大学,陕西 西安 710071)
0 引 言
随着互联网,特别是移动互联网的快速普及和移动智能终端的快速发展,互联网用户持续增长,人们习惯于通过互联网获取信息、发表观点,进行社会交往、网络购物等。与此同时,网络也成为各类广告推广的重要媒介,各类广告文本数据夹杂充斥在各类网络平台中。然而,由于广告监管、法律法规和从业人员素质问题,虚假违法广告在门户网站、移动客户端和新媒体账户等互联网媒介中屡禁不止[1],严重污染网络空间,危害人民群众财产安全。要在海量互联网数据中及时发现识别各类违规广告信息,及时管控处理,是网络监管部门面临的技术挑战。面对海量互联网数据中的广告文本识别,必须充分发挥人工智能技术的优势,利用自然语言处理技术,结合文本语义分析技术,自动高效识别违规文本广告内容,为有效打击网络广告犯罪行为,营造良好的互联网广告秩序提供有力技术支撑。
1 相关工作
文本分类技术是自然语言处理研究中应用最广泛的研究方向。针对文本类广告识别,早期方法主要是基于白名单与黑名单、规则过滤等技术[2]。张知临等人[3]使用黑白名单的方法识别网络文本广告,黑名单存储网络违规广告网站的网站名称、禁用词等预定义字段,该方法在特定领域下准确率高,速度快,但缺点也明显,灵活性差,严重受限黑名单质量,对黑名单之外的广告无法有效识别。郭慧芳等人[4]提出构建违规词汇库的关键字匹配方法进行网络文本广告识别,该方法简单、高效,使用广泛。
近年来,利用机器学习方法进行文本分类的思路也应用到文本广告分析中。如朴素贝叶斯[5]、支持向量机[6]和K-近邻算法[7]等统计方法在文本分类中都有良好的表现。林雪等人[8]提出基于语义特征的文本过滤方法,在此基础上进行机器学习建模,取得了较好的效果。但基于传统机器学习的方法,必须依赖人工构建广告文本的特征工程,建模过程费时费力,判别准确性也存在上限,并不能满足特定环境下的分类要求。随着神经网络技术的发展,涌现出一批利用深度神经网络处理文本分类任务的研究。Kim等人[9]采用预训练词向量,使用卷积神经网络进行文本分类,取得了很好的效果。Bojanowski等人[10]提出一种快速文本分类器fastText模型,模型简单高效同时也具有较强的特征学习能力。Miyamoto等人[11]提出利用LSTM(long short-term memory)网络的记忆能力且适合处理序列数据的特点,通过构建混合模型进行文本分类,效果显著。
自然语言分析处理任务中,文本的表示方法影响到文本语义的表示和文本特征的抽取。因此,针对文本词和字的表示方法,研究者提出了不同的预训练语言模型。一种预训练语言模型是基于上下文词嵌入方式,如Word2vec[12]、GloVe[13]、CoVe[14]和ELMo[15],词嵌入表征被用做主任务的附加特征使用。另一种预训练模型是基于句子级嵌入,Howard等人[16]提出一种通用域语言模型ULMFiT,能够实现像计算机视觉领域的迁移学习方式,并用于任意NLP任务。使用大量未标记数据进行无监督预训练获取的语言模型在学习通用语言表征方面性能出色,如预训练模型OpenAI-GPT[17](generative pre-training)和Bert[18]。Bert是具有双向Transformer[19]结构的编码器,使用掩膜语言(masked LM)模型和邻句预测(next sentence prediction)两种方法捕捉字符级和句子级别特征。在GLUE排行榜中,Bert刷新了11项NLP任务新纪录,自然语言处理自此也进入了预训练模型大规模应用新阶段。
在深入研究社交语料中广告文本的特点规律基础上,利用深度神经网络的强大特征表示能力,充分利用预训练语言模型的优势,提出一种基于语义强化的广告文本识别方法CARES(Chinese text recognition based on enhanced semantic)。主要创新为:
(1)融合使用字符级和词汇级不同层次语义表征,更全面实现广告文本特征的表示;
(2)利用Bert模型高层特征包含更丰富的语义信息,使用卷积网络对高层特征筛选,获取文本中更加突出的高维特征;
(3)利用LSTM网络提取句子中的关键语义信息,采用注意力机制强化句子词汇级特征,减小无关噪声干扰,提升模型分类的精度。
2 基于强化语义的中文广告识别模型CAR-ES
2.1 文本预处理
文本预处理能有效避免无效特殊符号、非法字符等对分类结果的影响。本模型文本输入前预处理操作包括:
(1)文本清洗:清除待分析文本中包含的各类缺失值、空白、特殊符号和非法字符。
(2)去停用词:停用词指的是诸如代词、介词、连接词等不包含或包含极少语义的词,一般在文本中多次出现,但实际语义价值不大。文本预处理利用停用词表过滤去除掉文本中包含的各类停用词。
(3)变形词替换:在广告文本中由于表达的多元化和多样化,各类变形词频繁出现,增加了广告识别的难度。该文采用特殊符号替换和同音近型替换的策略,替换掉待分析文本中各类同音异形等变形词。
2.2 模型设计
该文提出的基于强化语义的中文广告文本识别模型结构如图1所示,基于深度神经网络架构的模型主要包括输入层、特征抽取层、特征融合层、输出层。
2.2.1 输入层
输入层接收广告文本输入,并对文本数据集做预处理,划分成字符级和词汇级粒度单元,供特征抽取层提取特征。
2.2.2 特征抽取层
该层包括字符级特征抽取和词汇级特征抽取两个模块。Word2vec能够将词汇映射到低维、稠密向量,表示词语的一个潜在特征,捕获有价值的句法和语义特性,但是词和向量是一对一的静态关系,无法解决一词多义问题。Bert结构相比以Word2vec为代表的嵌入表征方法,最突出的特性是可以动态建模一词多义现象。因此,在特征抽取层中同时采用Bert进行字符级特征表示,有效弥补Word2vec表示的不足。
2.2.2.1 字符级特征抽取
基于预训练Bert实现特征抽取,使用CNN模型进一步对特征做高层抽象。
Bert由双向Transformer组件构成,以字符序列作为输入,整个语义信息会在堆栈中不断由底层向上流动,通过联合调节所有层中的上下文来预先训练深度双向表示。经大规模语料预训练后的Bert可以通过外接一个额外的输出层进行微调,适用于广泛任务的模型构建,无需针对具体任务做大幅度架构调整。Google开源了两种不同规模Bert模型,该文选用基础版Bert_BASE作为广告文本分类任务的微调模型进行改进优化。
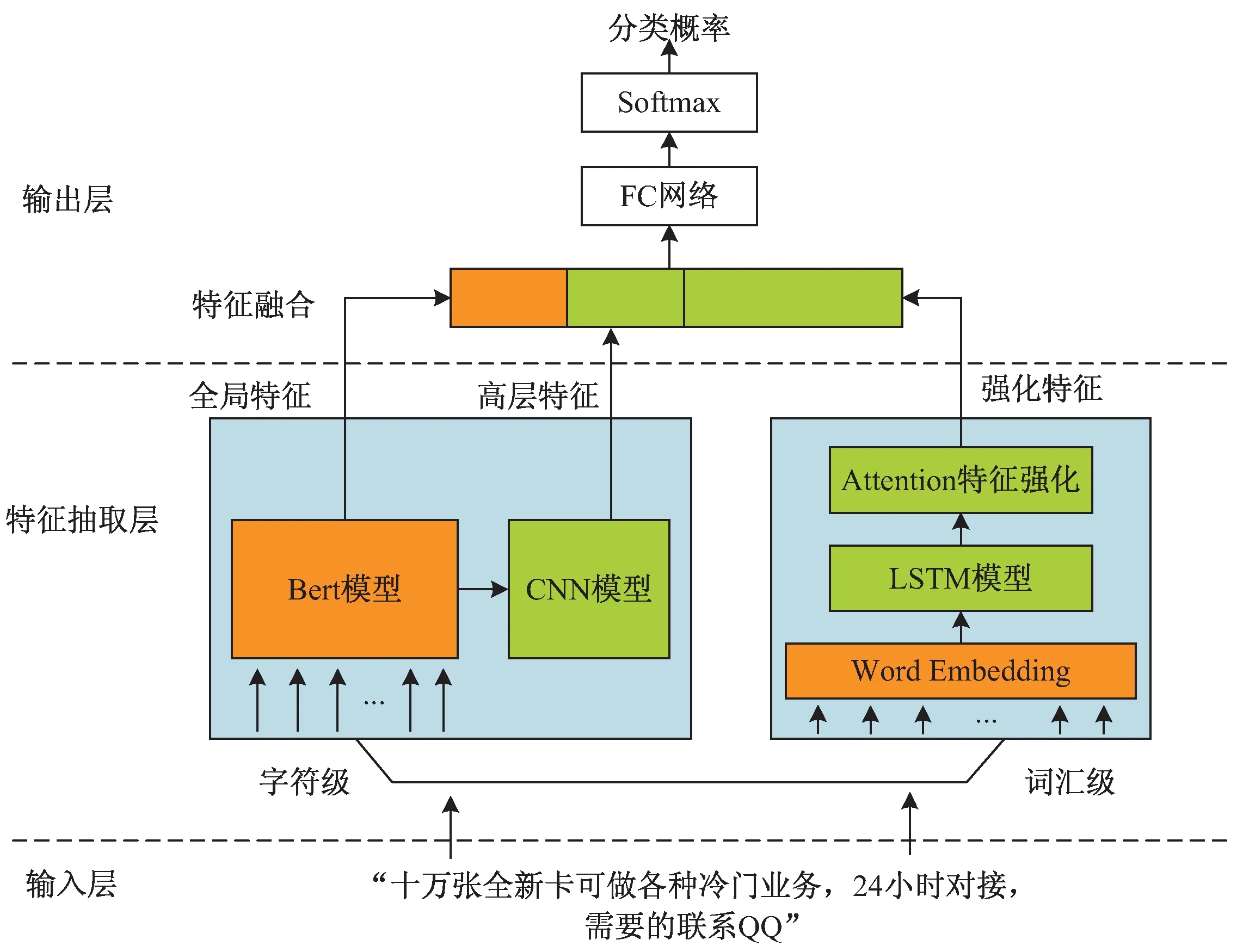
图1 文本分类模型
将模型输入文本定义为x,表示具有m个字符长度的文本序列:
x={[CLS],x1,…,xm,[SEP]}
(1)
在Bert中,将序列第一个token作为句子级分类嵌入特征,使用[CLS]标识,对应的最终隐藏状态则被用于分类,而对于非分类任务则忽略该部分。同时,为能够将句子打包成独立序列,使用标识符[SEP]用于区分。当前任务中均以单句作为输入,并不判定前后句的相关性,因此在序列x中均以[SEP]结尾。
获取文本的上下文表征b∈d:
b=BERT(x)
(2)
其中,d是Bert模型分类标志位[CLS]的特征维度。
Bert中每一层Transformer的输出都能够被选取为有效特征供下一级表征器使用,该文选取Bert最后三层Layer12、Layer11、Layer10的内部隐藏层第一状态位作为卷积网络的输入矩阵:N∈3×d,其中,d是隐藏层状态维度。选取16个滤波器Filter,大小为3×4,步长为1,对矩阵M在对应维度方向上做卷积操作,用以提取状态位的3-Gram特征,通过卷积操作后便可得到16个特征向量。为对特征进一步提取,降低计算的复杂度,最后使用max-pooling方式进行池化,即可得到高层卷积结果特征c∈p:
c=Conve2D(N)
(3)
其中,p是卷积网络输出的特征维度,此处为16。
2.2.2.2 词汇级特征抽取
基于LSTM网络提取全局语义,采用Attention机制对语义做特征强化。使用开源工具Word2vec获取文本词向量表示,通过查表操作对本任务中的词做初始化,而未出现词汇选取[-0.1,0.1]的区间做随机初始化。
设文本经预处理后的长度为n,得到词汇级文本序列w:
w={w1,w2,…,xn}
(4)
经过分布式表示模型生成的词向量表示v:
v={v1,v2,…,vn}
(5)
使用LSTM网络从上下文中挖掘隐含状态特征。
H={h1,h2,…,hn},其中h∈q表示词汇级隐含特征向量,维度为q,GRU单元在t时刻更新过程如下:
vt=σ(Wrvt+Urht-1+br)
(6)
zt=σ(Wzvt+Uzht-1+bz)
(7)
hc=tanh(Whvt+Uh(rt·ht-1)+bh)
(8)
ht=(1-zt)·ht-1+zt·hc
(9)
其中,σ为激活函数,Wr、Wz、Wh、Ur、Uz、Uh为权重矩阵,br、bz、bh为偏置值,·表示向量点积运算。ht为t时刻GRU单元的输出。为了充分利用上下文信息,使用双向特征作为最终的LSTM结构输出:
(10)
(11)
(12)
其中,⊕表示前向和后向输出的对应元素相加操作。
之后,将Attention机制用于动态捕获与特定文本类别相关的词汇信息:
M=tanh(L)
(13)
α=softmax(wTM)
(14)
r=LαT
(15)
其中,L∈q×n,w是参数向量,由不同时间序列ht构成,α是注意力权重分布,r表示词汇级增强特征表示向量。
2.2.3 特征融合层
该文采用Early Fusion特征拼接策略,对全局特征、高层特征和强化特征进行特征融合,待拼接特征包括3个模块:
Bert模型全局特征:b;
CNN网络抽取的高层特征:c;
Attention机制的强化LSTM特征:r。
融合特征f∈d+p+q:
f=[b;c;r]
(16)
2.2.4 输出层
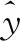

(17)
其中,W∈C×(d+p+q)表示非线性变换权重矩阵,b∈C表示非线性变换的偏移量,C表示文本类别数。经softmax归一化后,使用argmax计算概率值最大的文本类别标签。
3 实验设置
3.1 实验数据
该文研究的问题在国内目前没有找到公开的数据集,所以,基于已有研发项目从微博、微信及QQ等社交平台上收集各类聊天短文本和社交短文本数据,经过团队人工标注最终形成46 000条中文社交短文本样本,采用分层抽样划分训练集和测试集,数据样本分布如表1所示。

表1 广告数据集样本分布
数据集样本类别示例如图2所示。

图2 广告数据集样本示例
3.2 实验设计
为充分验证提出的识别方法的有效性,选择广泛应用于文本分类的深度学习算法作为基准模型:
(1)参考文献[11]提出的WcLSTM循环神经网络分类模型;
(2)参考文献[9]提出的TextCNN卷积神经网络分类模型;
(3)基于Bert基线的Bert-BASE文本分类模型;
(4)采用该文提出的CARES文本分类模型。
3.3 实验配置
实验算法采用Tensorflow1.15框架实现,硬件执行环境配置为:Intel(R) Xeon(R) CPU E5-2677W v4 @3.00GHz处理器、128 GB内存、64位Ubuntu16.04操作系统、NVIDIA GTX1080显卡。
在WC-LSTM和TextCNN基线系统中,使用jieba工具对文本进行分词,映射成300维的Word2vec词向量[12],最大文本长度120个词,batch size大小维64,epoch大小8,学习率1e-5。Bert-BASE系统中使用chinese_L-12_H-768_A-12,最大文本长度512个字符,batch size大小5,epoch大小10,学习率5e-5。
3.4 实验结果
3.4.1 对比实验
实验结果是多次实验数据的平均值,不同模型在测试数据集上的表现如表2所示。

表2 实验结果 %
从表2中发现,与基线模型相比较,CARES模型在4项指标中都取得了最好的成绩。其中,与WcLSTM相比在准确率、召回率、精度和F1值上分别提升2.12%、2.07%、2.23%、1.54%,提升最多,这表明Bert模型的微调能更丰富地表示文本语义关系,注意力机制能够对文本语义起到强化作用,有助于提升文本分类性能。与Bert-BASE相比,CARES模型在四项指标上分别提升了0.63%,0.53%,0.69%,0.61%,表明字符级语义、词汇级语义能从不同层次表现广告文本的语义特点,特征融合后具有更丰富的语义特性。
从表2发现,以Bert为基础的文本分类模型各项指标都超过97%,说明Bert相比传统的特征表征器能更好地表示短文本语义信息,在中文短文本分类问题上有很好的分析能力。比较TextCNN,CARES和WcLSTM网络,发现TextCNN模型的分类效果不及CARES模型,但好于WcLSTM模型,这说明卷积神经网络的特征抽取能力优势明显,进一步证明该文对Bert高层语义特征抽取的合理性和必要性。
3.4.2 实验分析
提出的CARES融合模型在准确率、精准度、召回率和F1值均优于基准文本分类模型,主要是因为:
(1)在循环神经网络中,LSTM对文本向量处理的局限性在于以链状结构组成阵列时,对短文本的深层特征挖掘能力不够强。Bert模型以Transformer为组件,以多头注意力机制的转换器作为基础,天生具备处理短文本优势,而广告数据多以短文本的形式出现。因此,Transformer抽取器能够捕获各种复杂的语义交互信息,能从不同角度关注到句子中的依赖关系。
(2)在卷积网络模型中,CNN主要用于语言特征抽取,受到卷积核数量和长度的限制,对语境的特征抽取能力不及Transformer丰富和完整。此外,CNN全局池化操作会丢失部分结构信息,很难发现文本中的转折关系等复杂模式,导致模型无法表达文本上下文更深刻的语义。
(3)Bert中每一层Transformer的输出都可以作为句子或文档特征向量为其他模块提供输入,很大程度会影响模型的精度。在结构设计上,该文依托Bert优势,使用卷积网络对其最后3层特征进一步做抽取,采用Attention机制对语义做特征强化,融合全局特征、高层特征和强化特征实现广告文本分类,能有效捕捉文本不同层级、不同维度的重要特征,有效提升广告文本的识别性能。
4 结束语
互联网广告文本的智能发现识别是实现广告合法合规监测的关键技术,模型不仅能甄别聊天内容中各类恶意和垃圾广告,还能够降低虚假欺诈广告带来的安全风险,对营造安全清朗的网络环境意义重大。该文以互联网社交平台中的聊天文本数据为研究对象,利用预训练Bert模型,强化语义特征,融合多层次文本特征,有针对性地提出一种中文广告文本识别的方法,在人工收集标注的聊天文本数据集上,CARES方法获得了97.73%的正确率,97.75%的F1值,对比基线方法,广告识别分类性能达到最优。
社交聊天文本中使用的短文本往往包含大量的噪声数据,如:不规则表示、错别字、同形字等,该文提出的方法没有有效解决这些问题带来的性能影响,在后续的研究中,将继续探索优化方案,让模型进一步具备噪音容忍的能力,进一步提升识别性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
少儿科学周刊·少年版(2015年3期)2015-07-07
长江学术(2015年1期)2015-02-27
