
基于TF-IDF算法的分层搜索引擎设计∗
2021-04-04 07:48
计算机与数字工程 2021年3期
(江苏科技大学电子信息学院 镇江 212003)
1 引言
目前,在互联网上搜集、提取、处理信息的最常用的方式是使用搜索引擎[1]。随着互联网上信息量的迅速增加,以及信息组织方式变得愈加散列和多样性,要求搜索引擎算法必须更加的高效准确[2]。
为此,各国学者对其进行了大量研究,提出了许多搜索引擎算法与框架。如基于分类目录、文本检索的方法[3];使用基于网页被访问概率的PageR⁃ank算法[4];通过网页被链接的数量和质量来确定搜索结果的排序权重的Hilltop算法[5]等。
本文提出了一种基于词语频率-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)算法的分层搜索引擎设计方案。该方案分为两个阶段。在第一阶段,利用网络爬虫技术爬取网络词条,并构造一个语料库粗燥集;在第二阶段,则基于TF-IDF算法在本地对语料库进行精确高效搜索,得到与待搜索语句最相近的结果。实验中,将该搜索引擎应用于百度百科[6]的有关词条。整个搜索过程显示在基于Flask框架构建的本地Web上,能够提供给用户良好的搜索输入环境与搜索结果显示区域,点击搜索结果可以进入详细显示页面。
2 TF-IDF算法
在信息检索中,TF-IDF算法是一种采用词语加权方案的数字统计方法,旨在反映单词对集合或语料库中文档的重要性[7]。它通常用作搜索信息检索、文本挖掘和用户建模的加权因子。TF-IDF值与单词在文档中出现的次数成比例地增加,并且被包含该单词的语料库中的文档数量抵消,这有助于调整某些单词通常更频繁出现的实际情况[8]。
搜索引擎可使用TF-IDF加权方案或其变体作为在给定用户查询的情况下对文档的相关性进行评分以及排序。TF-IDF可以成功地用于各种主题领域的停用词过滤,包括文本摘要和分类。通过对每个查询项的TF-IDF求和来计算最简单的排名函数,许多更复杂的排名函数是这个简单模型的变体[9]。
2.1 TF-IDF的定义
通常,TF-IDF可表示为统计量词语频率和逆文档频率的乘积形式。这两个统计量有多种计算方式来确定其数值。
2.1.1 词语频率TF
对于词语频率,最简单的选择是使用文档中出现词语的原始计数[10]。例如,若词语t在文档d中出现tft,d次,那么即可定义词频tf(t,d)=tft,d。其他的定义方案如下:
1)布尔频率。

2)根据文件长度调整的词语频率。

3)对数缩放频率。

4)为防止因文档d过长导致的偏差使用的带偏置的词语频率。

2.1.2 逆文档频率IDF
逆文档频率衡量单词提供的信息量,可以用来度量一个词语的普遍重要性[11]。某一特定词语在语料库中的IDF,可以使用文件的总数除以语料库中词语出现的文档的个数的对数来表示,即:
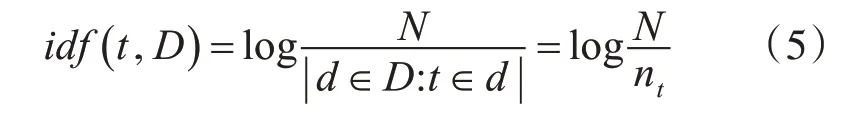
其中,t为某一特定词语,D为语料库整体,d为某一文件,N为语料库中的文档总数,N=|D|,nt=|d∈D:t∈d|为语料库D中词语t出现的文档的个数。
同样IDF也有多种的定义方案,如:
1)一元定义。idf(t,D)=1即词语t再语料库D中必定出现了
2)平滑的逆文档频率。

3)逆文档频率的最大值。
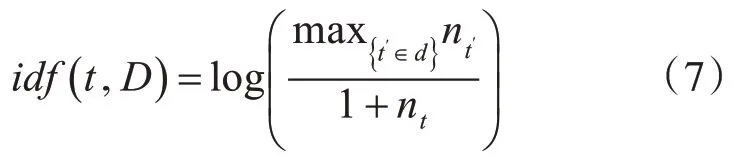
4)概率逆文档频率。

2.1.3 词语频率-逆文档频率TF-IDF
TF-IDF定义为tf(t,d)词语频率和idf(t,D)
逆文档频率两个统计量的乘积,即:
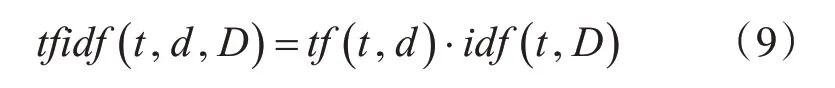
当词语t在给定的文档d中出现的频率愈高,则tf(t,d)值愈大;当词语t在语料库集中出现频率越小,则idf(t,D)值愈大;此时TF-IDF的权重越大,词语t更能代表文档d。反之,则相反。TF-IDF这个权重因此可以区别出其余普通的词语[12]。
并且idf(t,D)的log中的值往往大于等于1,因此tfidf(t,d,D)的值大于等于0。词语出现的文档数越多,idf(t,D)的log中的值越接近1,则tfidf(t,d,D)的越接近0,表示该词语t对于区分文档的作用越小。
在得到GMC的估计量后,我们还需要确定带宽。带宽的选择可以采用Sain等(1994)提出的方法,该方法可以通过R软件的“ks”包实现,也可以采用交叉验证法来选择。由于E(Y|X)=minl(x)(Y-l(X))2,E(X|Y)=minl(Y)(X-l(Y))2我们可以选择h使得h满足
本文在计算tf(t,d)和idf(t,D)时,分别选取式(2)和式(5),则:

2.2 TF-IDF的计算
假设一个语料库,它包含两个文档。两个文档的各个单词以及其在各文档中出现的次数,如表1所示。
计算词语“apple”的TF-IDF的步骤如下:
词语“apple”的tf为“apple”在各个文档中出现的频率。词语“apple”都仅出现一次,但文档1有5个单词,而文档2有7个单词,所以“apple”在文档2中的tf值较小。
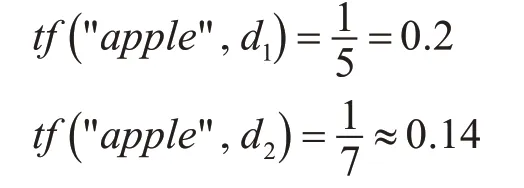
一个语料库中的某个单词的idf值一样的,它由有该单词的文档频率决定。在本例中,两个文档均含有“apple”,所以:0。
因此“apple”在两文档的TF-IDF值均为0,即这个词在所有文件中都没有提供很多信息。

而相反“melon”词语有着更多的信息。因为它仅在文档2中出现了3次。它的tfidf值计算如下:
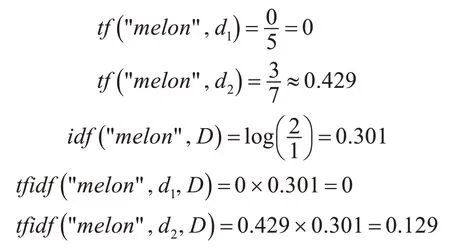
因此词语“melon”与文档2的匹配程度更高。
3 程序设计框架
该程序框架可分为三个部分:爬虫框架、flask框架以及TF-IDF计算。爬虫框架负责对全网词条获取进行初步搜索,如百度百科的所有词条,形成粗糙集(语料库),并保存以实现下一步精确的搜索;flask框架用于设置本地Web,作为显示与人机交互界面;TF-IDF计算部分用于计算用于输入的语句与语料库的匹配程度(即该语句出现在某文档的条件概率),并返回最相似的若干个词条,通过flask在本地文本上显示。

表1 文档1与文档2中所含单词及其计数
3.1 爬虫框架
本文爬取语料库以爬取百度百科为例解释爬虫框架原理。本文使用的爬虫框架使用requests库爬取网页html信息,使用bs4库解析网页并定位到需要的内容[13]。同时使用随机用户代理(User Agent,UA)的方法避免被反爬虫;使用正则表达式辅助定位信息等。在爬取时,需考虑到网页出现的各种特殊情况,如出现多义词时,需先定位该页面各义项的二级网络链接,定位到相应的词条进行爬取,并自动跳过不存在网页。
网络爬虫的流程如图1所示。
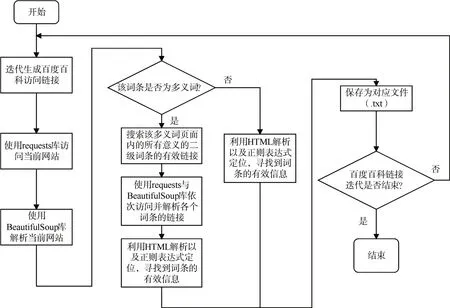
图1 本文所使用的爬虫框架流程
3.2 flask框架
本文提出的基于TF-IDF的搜索引擎框架的人机交互整体是通过flask构建本地网站来实现的,flask框架构建的系统通常由前端和后端两个部分构成[14]。前端为通过html语言设计的网站模板,用于设计网站的构成(包括用户输入与结果输出显示)。当用于输入带搜索的语句后,前端会发送获取数据的请求给Flask app,而Flask app从后端获取到数据,再通过route将数据返回给前端,通过模板设定好的参数,将处理后的数据显示出来。
其中,Flask app接受到相应的数据请求以后,分析数据请求信息,并确定请求来源之后,会调用程序中数据处理的函数完成相应的计算(即TF-IDF值的计算)。其流程如图2所示。

图2 本文使用的flask框架流程
3.3 TF-IDF计算
首先数据处理函数从Flask app后端获取到用户输入的语句,并将语句基于结巴(jieba)中文分词[15]分成对应的各个词语;继而根据式(2)、式(5)和式(10)计算各个词语在语料库D(事先由爬虫框架爬取得到)中的tfidf值,然后将其相加得到该条用户输入的语句的tfidf值。在这里需引入停止词的概念,即若分得的单词为特定的一组单词时,如“的”等对区分语料库无作用的单词等时,不计算其tfidf值。最后,该数据处理函数将计算出的语料库中对应tfidf值最大的若干个文档返回给Flask app前端,作为用户搜索的结果输出。其流程如图3所示。
4 实验结果与分析
为验证该系统的搜索效率与准确度,在百度百科网站上进行了实验和结果分析。实验平台为笔记本电脑一台,CPU使用i5-8400,主频2.8GHz,最大睿频4GHz,内存使用8GDDR4,使用有线校园网,网速为10M/s。

图3 本文使用的计算tfidf值函数流程
4.1 爬虫爬取结果
百度百科的各个词条链接为“https://baike.bai⁃du.com/view/”后接不同的index序号即可,例如百度百科的词条链接为“https://baike.baidu.com/view/1”,界面如图4所示,其中标注区域为爬虫需爬取部分。

图4 网站index=1及所需爬取内容
不过如前文所述,有些词条为多义词,需搜索当前页面下的所有二级词条的链接,进行二次搜索,如“https://baike.baidu.com/view/7”。同时有些index对应网站为空网站,需识别并跳过,如“https://baike.baidu.com/view/3”,两种特殊情况如图5所示。
因此考虑到所有情况,使用该爬虫框架爬取能够迅速准确地爬取百度百科的各个词条信息,爬取结果与保存文件格式如图6所示。
如图所示,该爬虫程序能够准确地爬取各个词条,并且能够区分出有效网页与多义词的特殊情况,大大提高了爬取速度。保存文件的第一行为该词条名称,第二行至倒数第二行为词条解释,最后一行为百科词条所在URL地址。

图5 两种特殊情况
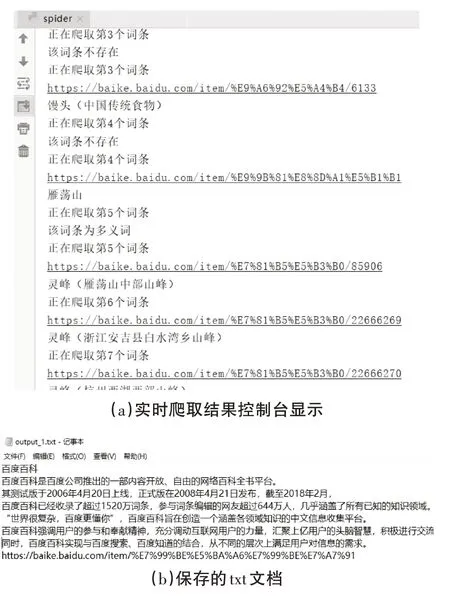
图6 爬取结果
在本文实验条件下,经过多次实验该爬虫爬取速度如表2所示,平均爬取速度约692条/分钟。
4.2 基于TF-IDF的搜索引擎运行
在应用爬虫爬取信息,构成词条语料库后,可以由TF-IDF算法进行第二阶段的精确搜索,系统设计的搜索引擎界面如图7所示。

表2 爬虫的爬取速度
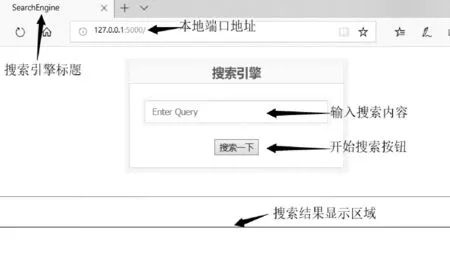
图7 搜索引擎输入界面
以搜索“百度”为例,其结果如图8、图9所示。
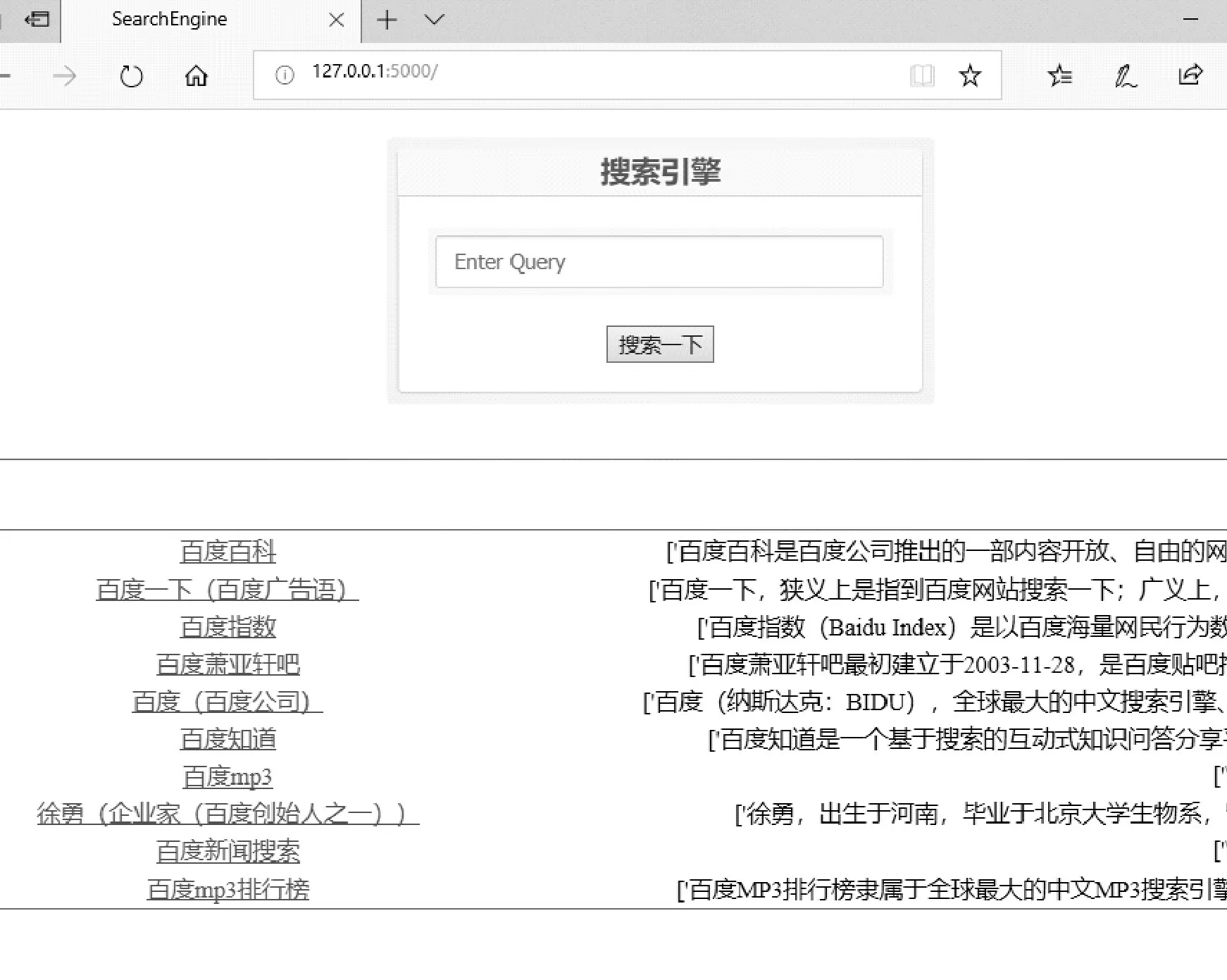
图8 搜索引擎查询结果界面

图9 搜索结果详细信息
根据TF-IDF算法的计算原理,计算函数从Flask app后端获取用户输入的语句,按照图3的计算流程得到与之最匹配的若干文档并予以显示。图7和图8给出了使用html语言构建的本地网站模板效果(搜索引擎界面)。
实验结果表明,该搜索引擎能够做到在语料库中准确地搜索出与输入语句最匹配的文档。并且点击每个搜素结果,可以进一步调出详细信息。
表3给出TF-IDF算法的搜索速度实验结果。搜索词条的时间一般不超过1s,能够满足用户迅速准确地搜索到相关内容的要求。
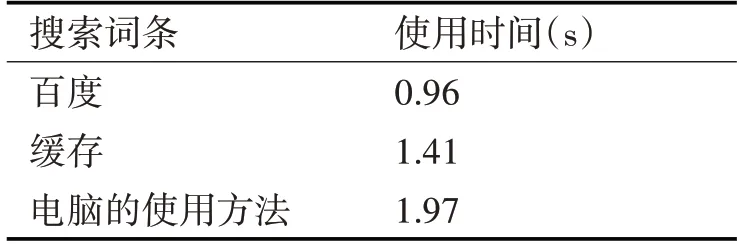
表3 搜索引擎的搜索速度
5 结语
本文设计了一种基于TF-IDF算法的分层搜索引擎。首先,利用网络爬虫爬取网络词条并构造语料库粗糙集,然后基于TF-IDF算法在语料库中实现相关信息的精确检索。该搜索引擎的GUI显示界面运用Flask框架构建本地Web页面,界面清晰易维护。该设计方案在利用网络爬虫爬取信息时,能够安全快速地覆盖网络各个节点,构造较为完备的语料库粗燥集;TF-IDF算法则保证了二次深层搜索的精确度;整个搜索过程具有较高的效率,能够满足实时性的要求。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
计算机与网络(2022年2期)2022-03-17
现代信息科技(2021年21期)2021-05-07
疯狂英语·新阅版(2020年11期)2020-12-21
电脑知识与技术·经验技巧(2020年3期)2020-05-07
智能计算机与应用(2018年5期)2018-10-20
电脑知识与技术·经验技巧(2018年1期)2018-05-30
科学导报·学术论坛(2013年5期)2013-06-26
微型计算机·Geek(2009年1期)2009-12-15
