
基于大数据的元模型及数据保障研究
2021-04-02 04:57张月圆
粘接 2021年3期
张月圆
(内蒙古电力营销服务与运营管理中心,呼和浩特 010020)
现代企业对于业务时效性的要求不断提高,一些业务甚至要做到实时响应。随着时代的发展,传统的由上至下的数据仓库只能做到对数据的快速响应,而无法对业务做出快速响应,因此有必要对传统的数据仓库模式进行革新,创建起一套分层式、分布式的数据仓库架构,能够同时对数据和业务做出快速响应。此外,为了实现数据的规范化管理,提高数据的使用质量,需要将异构的、分散的数据列入统一的标准数据库中,在此基础上建立起规范实用的数据仓库。本文分析了某化工类科技数据库,其中存储了不同格式的文本数据,包括XML、EXCEL 等,整体的数据存储量庞大,由于数据结构和数据存储方式存在显著差异,导致数据库无法对业务变更进行适应,最终影响了集成后数据的质量。受到数据异构性的影响,高度集成的数据库正面临数据缺失、数据冗余、数据重复、数据格式紊乱、数据不统一等多重问题。基于此,本文创建了一种基于云计算的元数据管理与数据集成系统,引用ETL抽取技术,实现数据的提取、转换及加载。
1 基于大数据的元数据管理整体架构
在大数据时代,各种类型的数据量激增,由此造成了数据价值密度低的问题,这对于数据处理速度提出了更高要求,才能满足现实中的数据应用需求。着眼于化工类科技数据的管理问题,本文建立起基于大数据的元数据管理架构,展示如下图1:
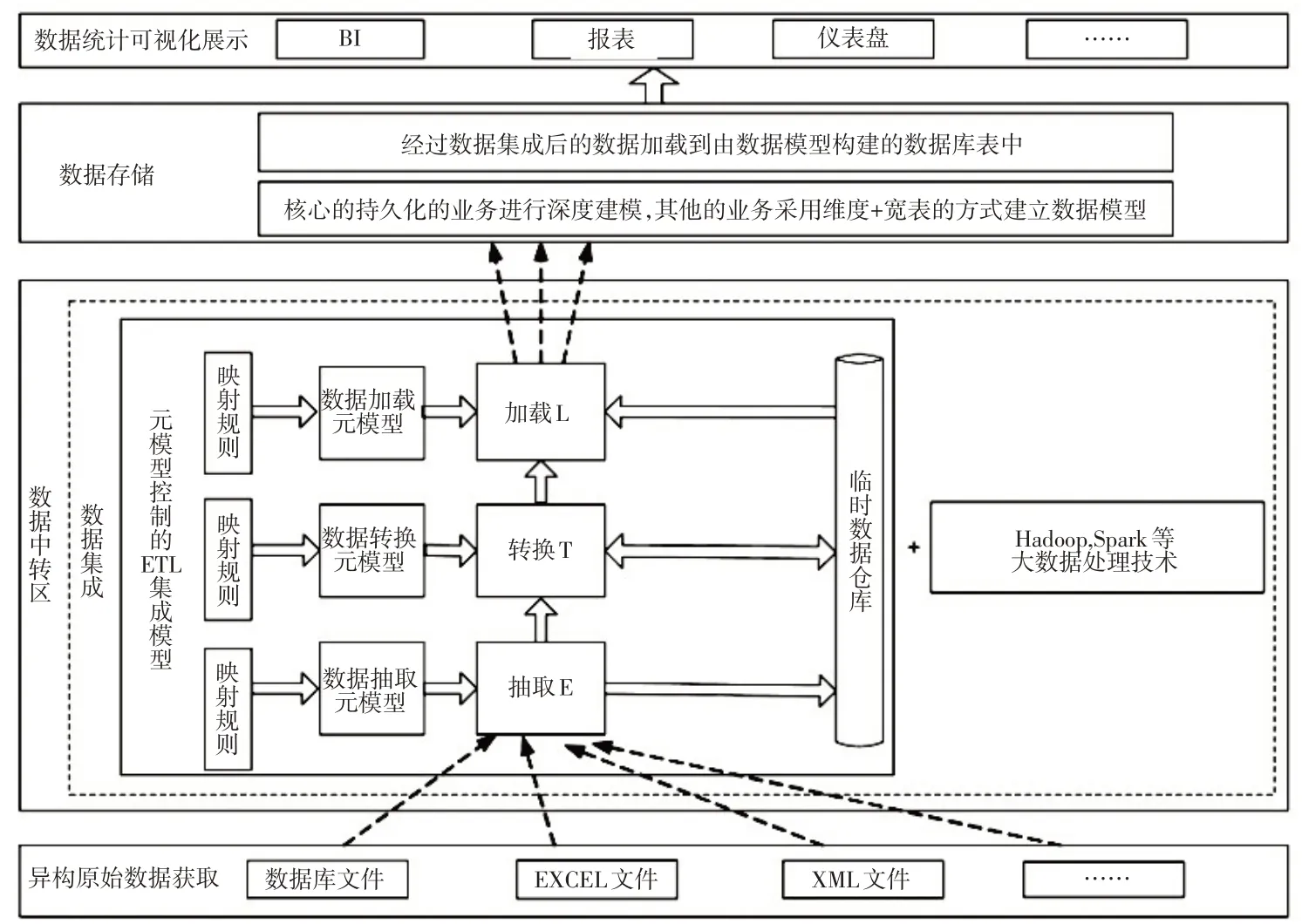
图1 元数据管理整体架构Fig.1 Overall architecture of metadata management
根据上图1,元数据管理架构包含4 个层次,即异构原始数据获取、数据中转区、数据存储以及数据统计可视化展示。构建数据仓库的初衷是为了提高数据质量,在应用中表现出“面向主题、高度集成”的特征,并且二者之间具有内在逻辑,即数据集成是为了更好地实现主题查询,可视化的查询及分析结果能够更好地指导决策。
把ETL流程细分为小粒度的执行区间,能够显著改善异构数据集成后的数据质量。基于该思想,本文在抽取、转换、加载阶段建立对应的元模型。其中,利用ETL 模型对数据集成过程中的不同阶段进行处理,实现了数据抽取、数据转换、数据加载的独立运作;在引用映射机制以后,在数据抽取过程中打破源数据的异构性,为后续的数据集成操作创造条件,有利于实现批量处理的目的。利用Hadoop分布式处理技术进行数据处理,采用分布式的处理方式替换集中式的处理方式,不仅大幅提高了数据处理效率,而且显著缩减了资源耗费。在持久化业务数据模型的支撑下,在标准化的数据存储结构下,可以对集成后有价值的数据进行快速分析。采取分层管理的策略,数据仓库以分步作业的方式进行运作,各层拥有简明的处理逻辑。
2 元模型结构的设计和映射规则描述
在ETL流程中增加了抽取元模型、转换元模型和加载元模型,三个模型应用共同的元数据,抽取环节、转换环节、加载环节之间存在关联。
2.1 抽取元模型
在对元数据进行抽取过程中,包含多种不同类型的表格。因此,基于以上的分析认为,将元模型的多数据源抽取逻辑设计为如图2所示。

图2 抽取元模型流程Fig.2 Extraction metamodel process
2.2 转换元模型
如下图3展示了元数据转换流程,即利用数据表字段关联表实现抽取。元模型抽取后,数据表描述表与抽取后数据字段描述表的关联,继而确定抽取数据范围,并将数据用于转换。目标库中的表字段与源数据库抽取后的表字段在字段属性、存储格式等方面存在差异,举例来说,在源数据库中,利用存储数据“01、02”来表示人员性别“男、女”,而在目标库中,则利用存储数据“1、2”来表示人员性别“男、女”;在源数据库中,利用“aa、ab”来表示单位类型“企业、高校”,而在目标库中,则利用“AA、AB”来表示“企业、高校”。对此,在数据转换过程中需要引用映射转换机制,其实现过程是:利用数据转换关联表调取数据转换函数描述表中的数据转换函数,基于数据转换映射规则实现数据转换,利用转换关联表把数据字段信息转录于转换后数据字段描述表和转换后数据表描述表之中,以供数据加载之需。

图3 元数据转换流程Fig.3 Metadata conversion process
2.3 加载元模型
加载元模型的过程如图4 所示。通过图4 的接在,如增加了字段,则表明加载成功,如没有则表示加载不成功。

图4 元数据加载Fig.4 Metadata load
2.4 映射规则的定义与描述
结合科技资源管理数据库的特征,首先确立库级映射、表级映射、字段级映射等3层映射规则,然后在此基础上设定映射关系R=( )S,A,U,其中,S、A依次表示源库模型和目标库模型下的各个实例组合,U表示<S,A>内部存在的算法公司、逻辑规则等。
1)库级映射:Ra表示目标库,Rs表示源库,设定二者之间存在对应关系Lr。
2)表级映射:Ta表示目标库中的数据表,Ts表示源数据库中的数据表,设定二者之间存在对应关系Lt。
3)字段级映射:X表示源表Ts中的字段集合,Y表示目标表Ta中的字段集合,并且X 字段集合中的字段xk基于特定规则f而对应于Y 字段集合中的字段yl,这种对应关系表示为f(xk,yl)。
结合上述科技资源的属性,然后再明确函数f在映射过程中的规则:
1)清洗函数的映射规则为:删除Ts源表中xi字段中的无用字段;
2)字段类型转换函数映射规则。在确定字段级别之间映射关系后,针对不同表中yi与xi的字段类型差异,需对字段的类型进行转换。
3)字段存储格式转换函数映射规则:在明确字段级映射关系之后,考虑到Ta目标表中yj字段集合的字段存储格式与Ts源表中xi段集合的字段存储格式存在差异,因此有必要转换字段存储格式。
映射规则反映了不同数据之间的映射关系,并以元数据的形式进行存储。举例来说,要想集成一批数据,首先要设定映射规则,然后匹配于存储在元数据库中的映射模板,若二者一致,即可继续推进,若二者不一致,需要解析后再存储。由此,针对映射规则的定义,其本质是对元数据进行修订描述的过程。下图5展示了映射规则元模型的构造,具体包括:映射规则信息表、函数参数信息表、库级映射信息表、字段与映射规则关系表、表级映射信息表、清洗转换函数信息表、字段级映射信息表,它们囊括了设定映射规则所需的各种信息,同时也包含了映射转换函数的相关信息。

图5 映射规则架构Fig.5 Mapping rule architecture
3 试验验证
化工科技类资源管理数据的类型多样,涉及任务书、申报书等,不仅整体的数据体量庞大,而且不同数据采用了不同的存储格式,为了更好地服务于科技资源管理数据集成业务,需要构造元模型并确立库、表、字段映射关系,同时遵循统一规范进行数据存储。考虑到源数据的异构性,必须对源数据执行数据清洗、字段格式转换、字段类型转换等处理,从而为数据集成做好准备。旨在检验基于元模型控制的ETL模型以及相应映射规则对于改善集成数据质量的效果,本节将之与ETL 集成模型进行对比,并从完整性、有用性、准确性、时效性等4个方面对数据质量进行评估。下图6展示了不同模型在清洗阶段的数据有用率,根据结果看出,基于元模型的ETL抽取得到的数据有用率要明显高于传统的ETL抽取方式。

图6 数据有用性对比图Fig.6 Comparison of data usefulness
从理论上来讲,本文研究工作足以批量构建ETL流程,有能力对海量数据进行批量处理,从而更好地满足大数据环境下的应用需求。为了对此进行检验,通过实验方法测试了元模型控制的ETL 模型在10MB、100MB、200MB、500MB 数据量下的集成效率,并与传统ETL集成模型进行比对。
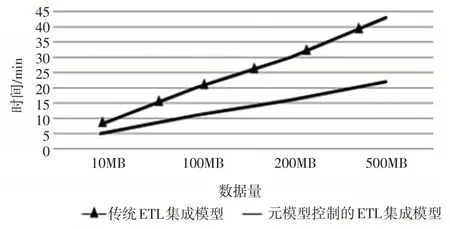
图7 集成效率对比Fig.7 Comparison of integration efficiency
4 结语
基于传统的ETL模型,文章在原框架下创新性地新增了元模型,同时界定了相应的映射规则,这不仅达成了数据集成功能,而且显著改善了集成后的数据质量,加快了数据的抽取转换速度。另外,构造的元数据工具和映射规则解析器,能够为批量构建ETL流程提供支撑,这不仅解放了人力,而且适应于大数据处理业务。由于笔者学识有限,本文研究尚有值得深化之处,比如,数据仓库架构在其他领域的应用,元数据模型工具的改进等。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17
小学教学研究(2022年5期)2022-04-28
自然资源信息化(2019年4期)2019-03-29
中国洗涤用品工业(2017年2期)2017-04-16
电子制作(2016年15期)2017-01-15
山东工业技术(2016年15期)2016-12-01
电信科学(2016年11期)2016-11-23
通信电源技术(2016年6期)2016-04-20
中国教育信息化(2015年10期)2015-08-23
图书馆建设(2015年10期)2015-02-13
