
网络爬虫实时控制器的设计与实现
2021-04-01 08:14李健张克亮
现代计算机 2021年5期
李健,张克亮
(信息工程大学洛阳校区,洛阳471003)
0 引言
网络爬虫不仅作为搜索引擎的关键组件,而且在其他领域也有广泛应用[1]。借助网络爬虫,语言学家可以下载大量文本以研究语言现象,销售人员可以搜集产品的价格和销量以分析市场行情,领域爱好者能够将某个网站或栏目的内容收藏到本地,AI研究者能够采集各类数据作为机器学习的素材。
国内外众多机构和个人开发了多款爬虫工具软件,如Nutch、Heritrix、SOUP、ParseHub、GooSeeker、八爪鱼、火车头等;常用的爬虫框架包括WebCollector、Nutch、WebMagic、Heritrix、Scrapy和PySpider等[2-4]。这些爬虫软件和框架在很大程度上便利了人们对网络数据的获取,但还具有某些局限性:有的功能相对单一,使用方式受限,可定制化程度不够;有的安装配置繁琐,框架结构复杂,使用门槛较高;有的采用封闭式框架,不提供开源代码,难以进行二次开发;有的抓取速度慢,解析和抽取能力弱,性能表现不佳。总之,基于现有框架快速开发个性化爬虫仍然具有一定难度。因此,为开发者提供一个轻量级、模块化、免费开源、高效易用的网络爬虫框架十分重要。
1 爬虫框架设计
1.1 爬虫工作原理
网络爬虫(Web Crawler)是按照一定规则自动获取Web信息资源的计算机程序[5]。“爬虫”是一种形象的比喻,有时也被称为网络蜘蛛(Web Spider)或网络机器人(Web Robot)。网络爬虫主要是面向Web的,这是由Web资源的开放性和丰富性所决定的。网络爬虫通常会对Web原始数据进行二次抽取,以提高目标数据的结构化程度和价值密度。爬虫的规则一方面是指爬虫所采用的搜索策略(如深度优先、广度优先等),另一方面是指爬虫要遵循的行业规范(如Robot协议)。
根据数据采集的范围和精度不同,网络爬虫可分为“漫爬型”和“垂直型”。前者用于搜索引擎的广泛采集,也被称通用爬虫;后者用于领域数据的精准采集,也被称聚焦爬虫。通用爬虫对网页中所有超链接进行无差别搜索,得到一棵完整的生成树;聚焦爬虫则按照一定条件进行筛选,得到一棵被剪枝的生成树。聚焦爬虫面向特定主题和应用,是行业人员获取领域数据的重要工具,也是文本关注的对象。网络爬虫的必要技术包括:Web访问、信息抽取、数据存储、爬虫控制等,其基本工作流程如图1所示。
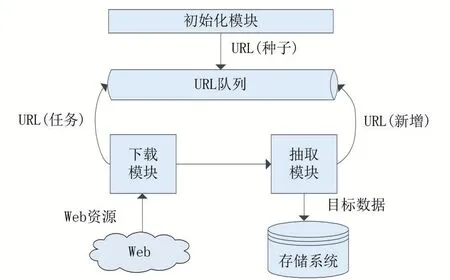
图1爬虫基本工作流程
首先将种子URL放入任务队列,然后循环检测队列是否为空,若不为空则取出下一个URL进行数据下载,若为空则结束爬虫任务。Web资源下载完成后,对其进行目标数据抽取和扩展链接过滤,目标数据存入存储系统,扩展链接添加到任务队列。在URL不断出列的同时又有新的URL补充进来,这样就实现了自动采集。为了避免重复采集,我们通常借助一个Visited数组来记录那些已被访问的URL。
1.2 框架总体结构
面向个性化需求的轻量级爬虫框架应当采用模块化设计,能够下载各类网络资源,并支持异步下载、编码检测、提交表单、压缩传输、使用代理等机制;能够解析和抽取HTML、XML、JSON等多种数据;能够提供灵活的爬虫控制方式,内置常用搜索算法;能够管理和分配线程资源和代理资源,支持分布式部署。根据上述需求,我们设计了如图2所示的爬虫框架,主要组件包括:控制器、下载器、解析器、线程池、代理池等、分布式部署器和智能化工具包。
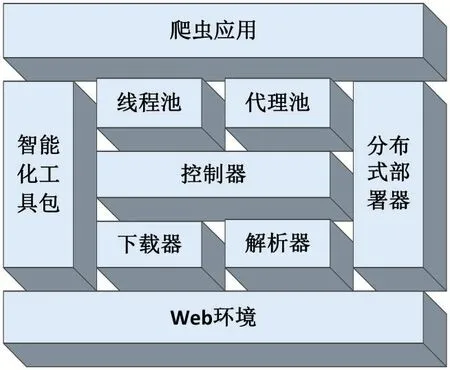
图2轻量级爬虫框架
框架中的“智能化工具包”通过人机交互技术实现可视化模板配置,使用户不必掌握Web专业知识就能完成模板配置,从而降低爬虫使用门槛[6]。通过智能抽取技术实现对网页内容(如正文、日期、目录等)的自动抽取,进一步减少配置工作量。通过主题模型计算网页内容的相关度,从而提高主题爬虫的采集精度[7]。
1.3 框架应用模式
通常情况下,框架中的控制器、解析器、下载器为必选组件,其余为可选组件,用户可根据需要进行组装。爬虫框架的基本应用模式如图3所示。
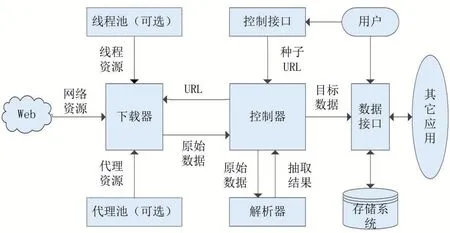
图3爬虫框架应用模式
引用爬虫框架后,开发者只需几行代码即可完成对简单任务的爬取;对于较复杂的任务,亦可通过参数化定制或二次开发来实现。当需要规划新的爬虫路线时,开发者通常只须重写控制器的相关方法,从而最大程度复用框架功能。
2 简单爬虫控制器
2.1 控制器设计
作为爬虫框架的核心部件,控制器的设计尤其重要。它对外提供操作接口,对内控制整个爬虫的运行过程。简单爬虫控制器的组成结构如图4所示。
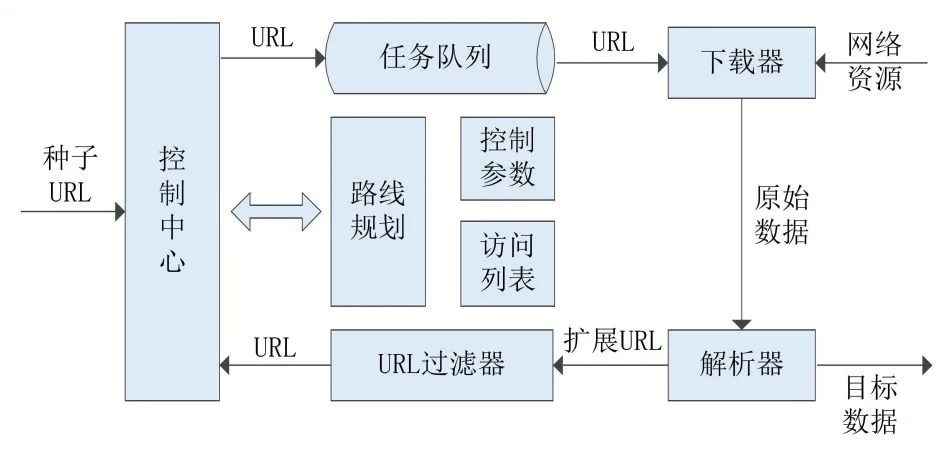
图4简单爬虫控制器
爬虫控制器的具体功能包括:①提供数据接口:接
收用户输入的种子URL,并将结果返回;②控制爬行路线:按照一定策略(深度优先、广度优先等)进行网页爬取;③维护访问列表:对于已经访问过的URL不再重复访问;④设置过滤条件:对于扩展URL进行条件过滤;⑤控制任务总量:设置最大采集数量、最大搜索层数等。
2.2控制器实现


上述代码通过实现了对“洛阳政府网站”的站内爬取:首先,创建一个BFSController对象;其次,限定最大采集任务量为100个页面;再次,通过设置URL过滤器要求扩展链接中必须包含“ly.gov.cn”字符串,从而保证“站内搜索”;最后,将网站首页(http://www.ly.gov.cn/)作为起始种子开启爬虫任务。执行上述代码,运行结果如图5所示。
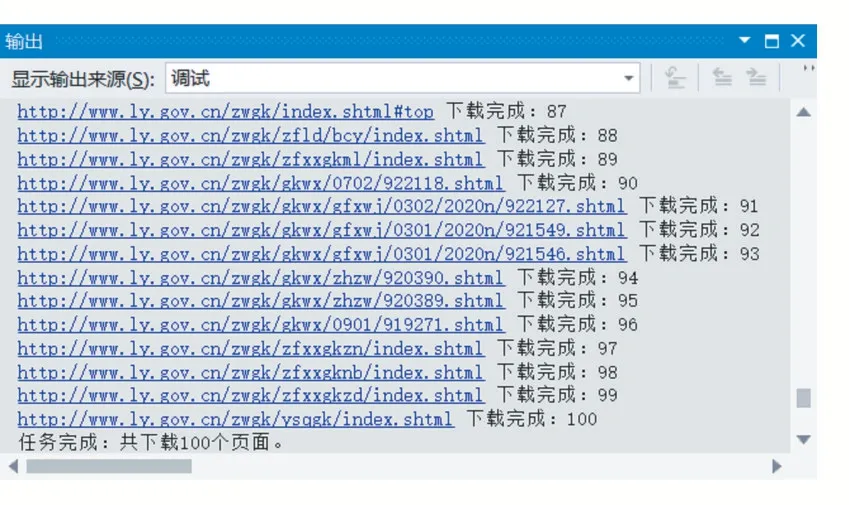
图5爬虫运行结果
3 实时爬虫控制器
此前的爬虫控制器要等任务全部完成后才能返回结果,这并不符合实际需求。由于爬虫在开放的网络环境中运行,任何意外情况都可能发生,例如断网、停电、死机、误操作、服务器故障等。若爬虫程序在结果返回之前就异常退出或无法继续运行,那么此前的工作也就变成徒劳。当采集任务量很大时,即使采集过程没有遇到异常情况,爬虫控制器也不可能一次性返回所有结果,这就需要对下载内容进行实时保存。
3.1 控制器设计
根据上述分析,我们对控制器提出以下改进:①采集结果不再等任务全部完成后一并返回,而是每下载一个任务就触发回调机制(回调方法由用户指定,可进行实时保存或进一步抽取)。②可以保存当前任务场景(Save),也可以从已保存的场景中恢复任务并继续执行(Restore)。③由用户设置一个自动保存数量(M),爬虫每采集M个任务就自动保存一次任务场景;即使有异常情况发生,需要重新下载的任务最多也不会超过M个。改进后的爬虫控制器具有一定的实时处理能力,我们称之为“实时爬虫控制器”(如图6所示)。
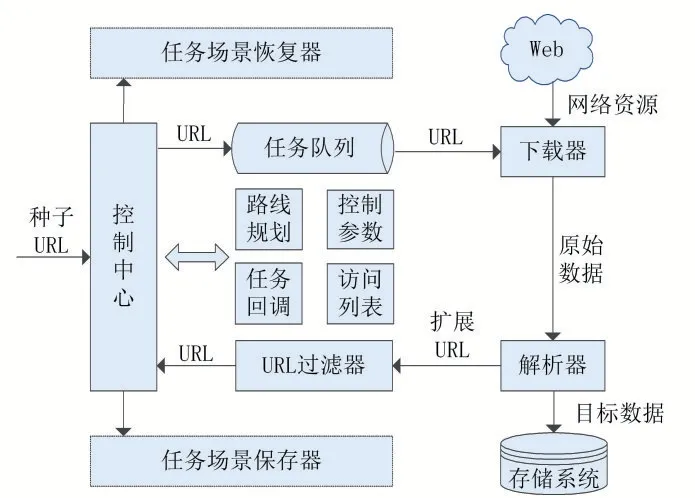
图6实时爬虫控制器
3.2 控制器实现



图7爬虫任务存放目录
4 结语
笔者在项目实践中发现:Web新技术层出不穷,网页结构千差万别,业务数据多种多样,采集目标各不相同。面对个性化的数据采集需求,没有哪一款网络爬虫能包打天下。在已有爬虫框架的基础上进行二次开发,是一种高效可行的方法。实验结果表明:本文所提出的轻量级爬虫框架是功能完备的,所设计的实时爬虫控制器是高效易用的。在控制器的实现过程中也涉及到了下载器和解析器,但由于篇幅所限文中未能详细介绍。若需要完整的实现代码,可通过电子邮箱联系作者。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
舰船科学技术(2022年11期)2022-07-15
中国自行车(2022年3期)2022-06-30
小资CHIC!ELEGANCE(2022年1期)2022-01-11
现代信息科技(2021年21期)2021-05-07
网络空间安全(2019年8期)2019-03-18
现代职业教育·职业培训(2019年12期)2019-02-03
智能计算机与应用(2018年5期)2018-10-20
电脑知识与技术·经验技巧(2018年1期)2018-05-30
电子技术与软件工程(2018年11期)2018-02-25
